目录
[五、BP 神经网络模型构建功能](#五、BP 神经网络模型构建功能)
十三、基于BP神经网络的命名实体识别的Python代码完整实现
一、前置环境与全局配置功能
- 中文字体自适应适配:解决可视化环节中文乱码问题,优先检测系统已安装的中文字体(如微软雅黑、黑体等),若未检测到则尝试加载本地字体文件,兜底保障中文正常显示;
- 全局统一配置管理:集中管理所有核心参数(模型维度、训练超参、数据集路径、可视化存储目录等),支持灵活调整,同时定义实体类型专属配色方案,为可视化提供统一风格;
- 环境容错优化:屏蔽无意义的警告信息,关键步骤添加异常提示,保证程序运行过程中不被无关报错中断。
二、多格式数据集兼容与处理功能
- 多格式数据集加载:原生支持 3 类主流 NER 数据集格式(标准 BIO 格式、MSRA 新闻格式、CLUENER 细粒度 JSON 格式),自动识别数据集文件格式并调用对应解析逻辑,可同时加载多个不同领域(通用、新闻、医疗、细粒度)的数据集并合并;
- 示例数据自动生成:当现有数据集样本数低于阈值时,自动生成通用、医疗、机构、时间等多维度的示例 NER 数据(包含文本和对应 BIO 标签),避免因数据不足导致程序中断;
- 数据集校验与清洗:加载过程中校验文本与标签的长度匹配性,跳过长度不匹配的异常样本,过滤无效行,保证数据质量;
- 智能数据集划分:根据总样本数自适应调整划分策略(样本充足时按 8:1:1 分为训练 / 验证 / 测试集;样本较少时按 9:1 划分;样本极少时全部作为训练集,验证 / 测试集复用训练集),避免出现空集导致的训练 / 评估错误。
三、词汇表与标签表构建功能
- 自动化词汇表构建:从所有数据集文本中提取唯一字符,添加 PAD(填充标记)、UNK(未知字符标记)后生成字级词汇表,保存到本地文件,同时生成 "字符 - 索引" 映射关系;
- 自动化标签表构建:整合所有数据集的标签类型,去重后添加 PAD、UNK 标记,生成标签表并保存到本地,同时生成 "标签 - 索引" 映射关系,为模型输入输出提供映射依据。
四、数据预处理与加载功能
- 序列标准化处理:按指定最大序列长度对文本和标签序列进行填充(不足长度时补 PAD)或截断(超过长度时切分),保证所有输入数据维度统一;
- 张量转换与设备适配:将处理后的文本 / 标签索引转换为 PyTorch 张量,自动检测 CUDA 是否可用,将张量部署到 GPU/CPU;
- 自适应数据加载器:根据训练 / 验证 / 测试集的样本数自适应调整批次大小(避免批次大小超过样本数),训练集加载时随机打乱数据,验证 / 测试集有序加载,保证训练稳定性和评估准确性。
五、BP 神经网络模型构建功能
- 模型架构设计:构建适配 NER 任务的 BP 神经网络,包含嵌入层(将字符索引转为向量)、多层全连接层(提取特征)、ReLU 激活函数、Dropout 层(防止过拟合)、输出层(通过 Softmax 输出标签概率),最终将扁平特征映射回序列维度,适配序列标注任务;
- 模型设备适配:自动将模型部署到 GPU/CPU,适配不同硬件环境;
- 模型参数统计:输出模型各层结构、参数数量等信息,直观展示模型复杂度。
六、模型训练与优化功能
- 可视化训练过程:训练时展示进度条,实时显示当前批次损失值,提升训练过程的可监控性;
- 掩码损失计算:过滤填充标签(PAD)对应的损失计算,仅计算有效标签的损失,避免无效数据干扰训练;
- 轮次验证机制:每轮训练结束后,在验证集上计算损失值和 Macro-F1 分数,评估模型泛化能力;
- 最优模型保存:根据验证集 Macro-F1 分数自动保存最优模型权重,覆盖次优模型,便于后续评估和预测;
- 自适应训练轮数:当样本数较少时自动减少训练轮数,避免模型过拟合。
七、模型评估功能
- 测试集全面评估:加载最优模型,在测试集上计算各标签的精准率、召回率、F1 分数,输出详细的分类报告,直观展示模型在不同实体类型上的识别效果;
- 混淆矩阵可视化:生成归一化的混淆矩阵热力图,清晰展示 "真实标签 - 预测标签" 的匹配关系,定位模型识别错误集中的标签类型;
- 空数据容错处理:当测试集无有效数据时,跳过评估并给出提示,避免程序崩溃。
八、单文本预测与实体解析功能
- 单文本实时预测:支持任意中文文本输入,输出该文本对应的标签序列,以及基于 B-I 标签规则提取的实体(包含实体内容和类型);
- 多领域示例验证:内置教育、地点、机构、医疗 4 类典型领域的文本示例,自动完成预测并输出结果,验证模型在不同领域的识别能力;
- 实体拼接逻辑:自动识别 B(实体开始)、I(实体内部)标签,拼接连续的同类型实体,过滤 O(非实体)标签,准确提取完整实体。
九、多维度可视化功能
- 数据集统计可视化:生成样本长度分布直方图(标注均值和最大序列长度)、标签分布条形图(标注各标签数量),输出样本数、平均长度、标签类型数等详细统计信息;
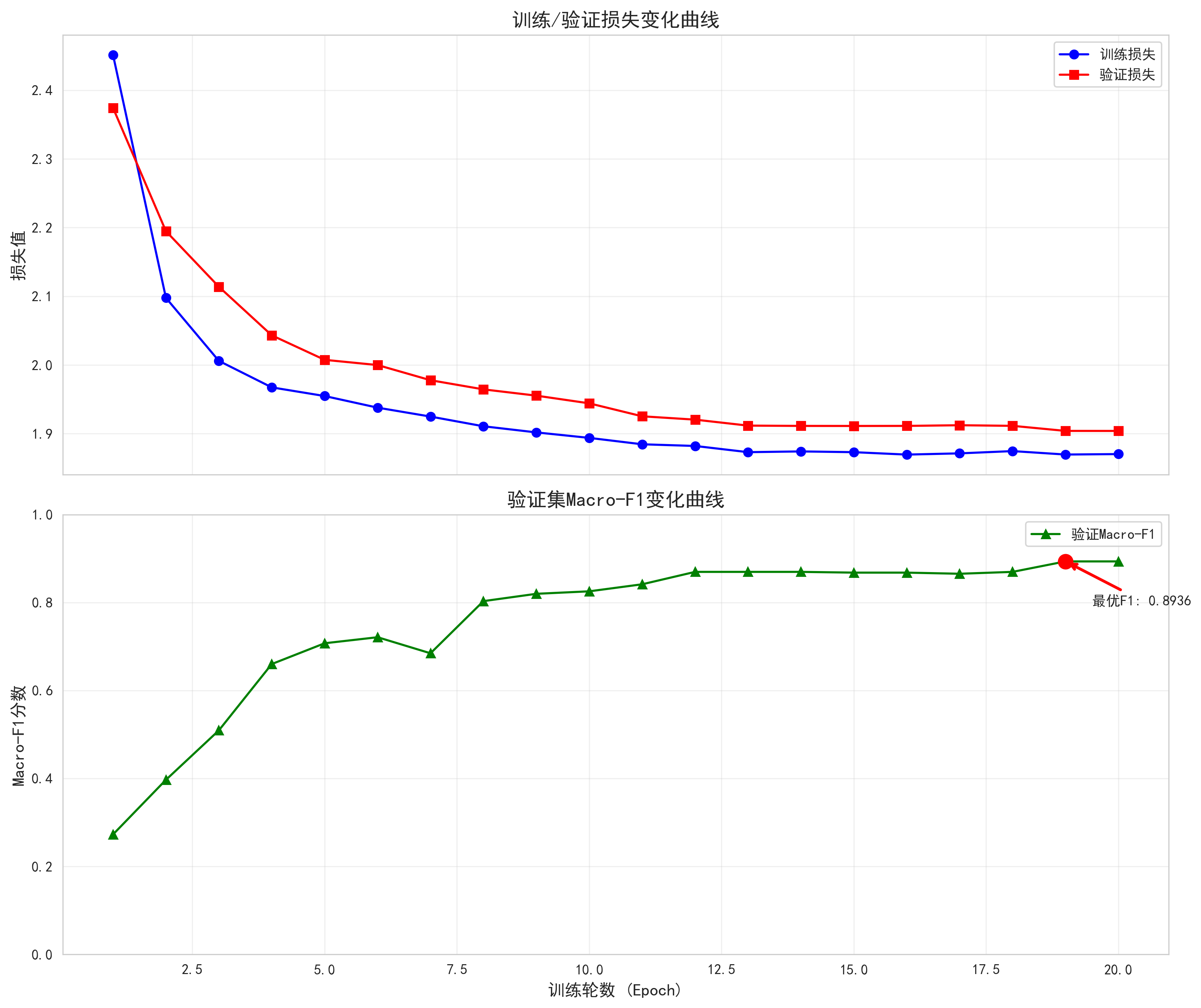
- 训练过程可视化:生成训练 / 验证损失变化曲线、验证集 Macro-F1 变化曲线,标注最优 F1 分数点,直观展示模型训练趋势;
- 实体标注可视化:为识别出的实体添加对应颜色背景,生成带颜色标注的文本可视化图,附带实体类型图例,直观展示实体在文本中的位置和类型;
- 模型结构可视化:生成模型计算图,清晰展示网络层之间的连接关系和参数流向;
- 可视化结果管理:所有可视化图表自动保存到指定目录,命名规范,便于后续查阅和分析。
十、整体容错与鲁棒性功能
- 路径容错:数据集文件不存在时自动跳过并提示,不影响其他数据集加载;
- 计算容错:损失计算、F1 计算、混淆矩阵绘制等环节添加空值过滤,避免除零、空列表等错误;
- 硬件容错:自动检测 GPU 是否可用,无 GPU 时自动切换到 CPU 运行,适配不同硬件环境;
- 参数自适应:批次大小、训练轮数等参数根据样本数自动调整,无需手动干预。
十一、结果输出与管理功能
- 过程日志输出:关键步骤(数据加载、模型训练、评估)输出详细日志,包含样本数、损失值、F1 分数等核心指标,便于监控程序运行状态;
- 文件保存管理:词汇表、标签表、最优模型权重、所有可视化图表均自动保存到指定目录,目录结构清晰,便于后续复用和分析;
- 预测结果输出:单文本预测结果包含输入文本、标签序列、识别实体,格式清晰,便于理解和使用。
十二、文本数据集准备
可以使用以下Python代码获得数据集,运行成功后,文本数据集也可以替换。
python
import random
import json
# ===================== 候选实体库(用于随机生成) =====================
# 实体类型对应的候选词
ENTITY_CANDS = {
"PER": ["张三", "李四", "王五", "赵六", "小明"],
"LOC": ["北京", "上海", "广州", "杭州", "深圳市南山区", "北京市朝阳区"],
"ORG": ["清华大学", "北京大学", "腾讯公司", "阿里巴巴集团", "北京协和医院"],
"DATE": ["2025年3月", "2024年5月", "2025年4月15日", "2023年12月", "2025年"],
"DISEASE": ["肺炎", "高血压", "糖尿病", "肝癌", "肺癌"],
"ORGAN": ["心脏", "胸部", "肺部", "胃部"]
}
# 各文件的生成模板(保证文本与标签长度匹配)
TEMPLATES = {
# ner_data.txt(BIO格式)的句子模板
"bio": [
("{per}在{loc}工作", ["PER", "LOC"]),
("{per}是{org}的学生", ["PER", "ORG"]),
("{per}{date}毕业于{org}", ["PER", "DATE", "ORG"]),
("{loc}是著名的旅游城市", ["LOC"]),
("{org}总部位于{loc}", ["ORG", "LOC"])
],
# medical_ner.txt(医疗BIO格式)的句子模板
"medical_bio": [
("患者因{disease}入院治疗", ["DISEASE"]),
("{disease}患者需定期检查{organ}", ["DISEASE", "ORGAN"]),
("2025年4月做了{organ}手术", ["DATE", "ORGAN"]),
("{disease}晚期需化疗", ["DISEASE"])
]
}
# ===================== 工具函数:生成BIO标签 =====================
def generate_bio_labels(text, entities):
"""
根据文本和实体信息生成BIO标签序列(保证长度与文本一致)
:param text: 目标文本(字符串)
:param entities: 实体列表,每个元素是(实体类型, 实体内容, 起始索引)
:return: 标签列表(长度=文本长度)
"""
labels = ["O"] * len(text)
for ent_type, ent_content, start_idx in entities:
end_idx = start_idx + len(ent_content)
# 标记B-XXX
labels[start_idx] = f"B-{ent_type}"
# 标记I-XXX
for i in range(start_idx + 1, end_idx):
labels[i] = f"I-{ent_type}"
return labels
# ===================== 1. 生成 ner_data.txt(BIO格式) =====================
def generate_ner_data():
lines = []
for _ in range(15): # 生成15条样本
# 随机选模板
template, ent_types = random.choice(TEMPLATES["bio"])
# 随机选实体并替换模板
ent_map = {}
entities = []
current_text = template
for ent_type in ent_types:
ent_content = random.choice(ENTITY_CANDS[ent_type])
ent_map[ent_type.lower()] = ent_content
# 替换模板中的占位符
current_text = current_text.replace(f"{{{ent_type.lower()}}}", ent_content)
# 计算实体在文本中的位置
temp_text = template
for ent_type in ent_types:
ent_content = ent_map[ent_type.lower()]
# 找到实体在当前文本中的起始索引
start_idx = temp_text.find(f"{{{ent_type.lower()}}}")
# 替换占位符,更新temp_text以便后续计算
temp_text = temp_text.replace(f"{{{ent_type.lower()}}}", ent_content)
# 记录实体信息
entities.append((ent_type, ent_content, start_idx))
# 生成BIO标签
labels = generate_bio_labels(current_text, entities)
# 拼接成BIO格式行(文本\t标签序列)
line = f"{current_text}\t{' '.join(labels)}"
lines.append(line)
# 写入文件
with open("ner_data.txt", "w", encoding="utf-8") as f:
f.write("\n".join(lines))
print("已生成 ner_data.txt")
# ===================== 2. 生成 msra_ner.txt(MSRA格式:字\t标签,空行分隔句子) =====================
def generate_msra_ner():
lines = []
# 先从ner_data.txt中读取样本(或直接生成)
# 这里复用ner_data的样本,拆分成字+标签
with open("ner_data.txt", "r", encoding="utf-8") as f:
bio_lines = [line.strip() for line in f if line.strip()]
for bio_line in bio_lines[:10]: # 取前10个样本
text, label_str = bio_line.split("\t")
labels = label_str.split()
# 每个字对应一行(字\t标签)
for char, label in zip(text, labels):
lines.append(f"{char}\t{label}")
# 空行分隔句子
lines.append("")
# 写入文件
with open("msra_ner.txt", "w", encoding="utf-8") as f:
f.write("\n".join(lines).strip()) # 去掉末尾空行
print("已生成 msra_ner.txt")
# ===================== 3. 生成 cluener_ner.txt(JSON行格式) =====================
def generate_cluener_ner():
lines = []
# 复用ner_data的样本,转换为CLUENER格式
with open("ner_data.txt", "r", encoding="utf-8") as f:
bio_lines = [line.strip() for line in f if line.strip()]
for bio_line in bio_lines[:8]: # 取前8个样本
text, label_str = bio_line.split("\t")
labels = label_str.split()
# 提取实体信息(转换为CLUENER的label格式)
cluener_label = {}
current_ent = None
current_type = None
start_idx = -1
for idx, (char, label) in enumerate(zip(text, labels)):
if label.startswith("B-"):
# 结束上一个实体
if current_ent is not None:
ent_type = current_type
ent_name = current_ent
if ent_type not in cluener_label:
cluener_label[ent_type] = {}
cluener_label[ent_type][ent_name] = {"start_idx": start_idx, "end_idx": idx}
# 开始新实体
current_type = label.split("-")[1]
current_ent = char
start_idx = idx
elif label.startswith("I-") and current_ent is not None:
# 拼接实体
current_ent += char
else:
# 结束当前实体
if current_ent is not None:
ent_type = current_type
ent_name = current_ent
if ent_type not in cluener_label:
cluener_label[ent_type] = {}
cluener_label[ent_type][ent_name] = {"start_idx": start_idx, "end_idx": idx}
current_ent = None
current_type = None
# 处理最后一个实体
if current_ent is not None:
ent_type = current_type
ent_name = current_ent
if ent_type not in cluener_label:
cluener_label[ent_type] = {}
cluener_label[ent_type][ent_name] = {"start_idx": start_idx, "end_idx": len(text)}
# 构造JSON对象
cluener_json = json.dumps({
"text": text,
"label": cluener_label
}, ensure_ascii=False)
lines.append(cluener_json)
# 写入文件
with open("cluener_ner.txt", "w", encoding="utf-8") as f:
f.write("\n".join(lines))
print("已生成 cluener_ner.txt")
# ===================== 4. 生成 medical_ner.txt(医疗BIO格式) =====================
def generate_medical_ner():
lines = []
for _ in range(10): # 生成10条医疗样本
# 随机选医疗模板
template, ent_types = random.choice(TEMPLATES["medical_bio"])
# 随机选实体并替换模板
ent_map = {}
entities = []
current_text = template
for ent_type in ent_types:
ent_content = random.choice(ENTITY_CANDS[ent_type])
ent_map[ent_type.lower()] = ent_content
# 替换模板中的占位符
current_text = current_text.replace(f"{{{ent_type.lower()}}}", ent_content)
# 计算实体在文本中的位置
temp_text = template
for ent_type in ent_types:
ent_content = ent_map[ent_type.lower()]
# 找到实体在当前文本中的起始索引
start_idx = temp_text.find(f"{{{ent_type.lower()}}}")
# 替换占位符,更新temp_text以便后续计算
temp_text = temp_text.replace(f"{{{ent_type.lower()}}}", ent_content)
# 记录实体信息
entities.append((ent_type, ent_content, start_idx))
# 生成BIO标签
labels = generate_bio_labels(current_text, entities)
# 拼接成BIO格式行
line = f"{current_text}\t{' '.join(labels)}"
lines.append(line)
# 写入文件
with open("medical_ner.txt", "w", encoding="utf-8") as f:
f.write("\n".join(lines))
print("已生成 medical_ner.txt")
# ===================== 执行生成 =====================
if __name__ == "__main__":
generate_ner_data()
generate_msra_ner()
generate_cluener_ner()
generate_medical_ner()
print("所有数据集文件生成完成!")程序运行结果展示:

ner_data.txt
bash
北京是著名的旅游城市 B-LOC I-LOC O O O O O O O O
赵六在北京市朝阳区工作 B-PER I-PER O B-LOC I-LOC I-LOC I-LOC I-LOC I-LOC O O
广州是著名的旅游城市 B-LOC I-LOC O O O O O O O O
杭州是著名的旅游城市 B-LOC I-LOC O O O O O O O O
王五是阿里巴巴集团的学生 B-PER I-PER O B-ORG I-ORG I-ORG I-ORG I-ORG I-ORG O O O
张三是清华大学的学生 B-PER I-PER O B-ORG I-ORG I-ORG I-ORG O O O
北京是著名的旅游城市 B-LOC I-LOC O O O O O O O O
张三2024年5月毕业于北京大学 B-PER I-PER B-DATE I-DATE I-DATE I-DATE I-DATE I-DATE I-DATE O O O B-ORG I-ORG I-ORG I-ORG
清华大学总部位于深圳市南山区 B-ORG I-ORG I-ORG I-ORG O O O O B-LOC I-LOC I-LOC I-LOC I-LOC I-LOC
张三2023年12月毕业于清华大学 B-PER I-PER B-DATE I-DATE I-DATE I-DATE I-DATE I-DATE I-DATE I-DATE O O O B-ORG I-ORG I-ORG I-ORG
杭州是著名的旅游城市 B-LOC I-LOC O O O O O O O O
张三在深圳市南山区工作 B-PER I-PER O B-LOC I-LOC I-LOC I-LOC I-LOC I-LOC O O
北京是著名的旅游城市 B-LOC I-LOC O O O O O O O O
王五2025年4月15日毕业于北京协和医院 B-PER I-PER B-DATE I-DATE I-DATE I-DATE I-DATE I-DATE I-DATE I-DATE I-DATE I-DATE O O O B-ORG I-ORG I-ORG I-ORG I-ORG I-ORG
张三在广州工作 B-PER I-PER O B-LOC I-LOC O Omsra_ner.txt
bash
北 B-LOC
京 I-LOC
是 O
著 O
名 O
的 O
旅 O
游 O
城 O
市 O
赵 B-PER
六 I-PER
在 O
北 B-LOC
京 I-LOC
市 I-LOC
朝 I-LOC
阳 I-LOC
区 I-LOC
工 O
作 O
广 B-LOC
州 I-LOC
是 O
著 O
名 O
的 O
旅 O
游 O
城 O
市 O
杭 B-LOC
州 I-LOC
是 O
著 O
名 O
的 O
旅 O
游 O
城 O
市 O
王 B-PER
五 I-PER
是 O
阿 B-ORG
里 I-ORG
巴 I-ORG
巴 I-ORG
集 I-ORG
团 I-ORG
的 O
学 O
生 O
张 B-PER
三 I-PER
是 O
清 B-ORG
华 I-ORG
大 I-ORG
学 I-ORG
的 O
学 O
生 O
北 B-LOC
京 I-LOC
是 O
著 O
名 O
的 O
旅 O
游 O
城 O
市 O
张 B-PER
三 I-PER
2 B-DATE
0 I-DATE
2 I-DATE
4 I-DATE
年 I-DATE
5 I-DATE
月 I-DATE
毕 O
业 O
于 O
北 B-ORG
京 I-ORG
大 I-ORG
学 I-ORG
清 B-ORG
华 I-ORG
大 I-ORG
学 I-ORG
总 O
部 O
位 O
于 O
深 B-LOC
圳 I-LOC
市 I-LOC
南 I-LOC
山 I-LOC
区 I-LOC
张 B-PER
三 I-PER
2 B-DATE
0 I-DATE
2 I-DATE
3 I-DATE
年 I-DATE
1 I-DATE
2 I-DATE
月 I-DATE
毕 O
业 O
于 O
清 B-ORG
华 I-ORG
大 I-ORG
学 I-ORG北 B-LOC
京 I-LOC
是 O
著 O
名 O
的 O
旅 O
游 O
城 O
市 O
赵 B-PER
六 I-PER
在 O
北 B-LOC
京 I-LOC
市 I-LOC
朝 I-LOC
阳 I-LOC
区 I-LOC
工 O
作 O
广 B-LOC
州 I-LOC
是 O
著 O
名 O
的 O
旅 O
游 O
城 O
市 O
杭 B-LOC
州 I-LOC
是 O
著 O
名 O
的 O
旅 O
游 O
城 O
市 O
王 B-PER
五 I-PER
是 O
阿 B-ORG
里 I-ORG
巴 I-ORG
巴 I-ORG
集 I-ORG
团 I-ORG
的 O
学 O
生 O
张 B-PER
三 I-PER
是 O
清 B-ORG
华 I-ORG
大 I-ORG
学 I-ORG
的 O
学 O
生 O
北 B-LOC
京 I-LOC
是 O
著 O
名 O
的 O
旅 O
游 O
城 O
市 O
张 B-PER
三 I-PER
2 B-DATE
0 I-DATE
2 I-DATE
4 I-DATE
年 I-DATE
5 I-DATE
月 I-DATE
毕 O
业 O
于 O
北 B-ORG
京 I-ORG
大 I-ORG
学 I-ORG
清 B-ORG
华 I-ORG
大 I-ORG
学 I-ORG
总 O
部 O
位 O
于 O
深 B-LOC
圳 I-LOC
市 I-LOC
南 I-LOC
山 I-LOC
区 I-LOC
张 B-PER
三 I-PER
2 B-DATE
0 I-DATE
2 I-DATE
3 I-DATE
年 I-DATE
1 I-DATE
2 I-DATE
月 I-DATE
毕 O
业 O
于 O
清 B-ORG
华 I-ORG
大 I-ORG
学 I-ORGcluener_ner.txt
bash
{"text": "北京是著名的旅游城市", "label": {"LOC": {"北京": {"start_idx": 0, "end_idx": 2}}}}
{"text": "赵六在北京市朝阳区工作", "label": {"PER": {"赵六": {"start_idx": 0, "end_idx": 2}}, "LOC": {"北京市朝阳区": {"start_idx": 3, "end_idx": 9}}}}
{"text": "广州是著名的旅游城市", "label": {"LOC": {"广州": {"start_idx": 0, "end_idx": 2}}}}
{"text": "杭州是著名的旅游城市", "label": {"LOC": {"杭州": {"start_idx": 0, "end_idx": 2}}}}
{"text": "王五是阿里巴巴集团的学生", "label": {"PER": {"王五": {"start_idx": 0, "end_idx": 2}}, "ORG": {"阿里巴巴集团": {"start_idx": 3, "end_idx": 9}}}}
{"text": "张三是清华大学的学生", "label": {"PER": {"张三": {"start_idx": 0, "end_idx": 2}}, "ORG": {"清华大学": {"start_idx": 3, "end_idx": 7}}}}
{"text": "北京是著名的旅游城市", "label": {"LOC": {"北京": {"start_idx": 0, "end_idx": 2}}}}
{"text": "张三2024年5月毕业于北京大学", "label": {"PER": {"张三": {"start_idx": 0, "end_idx": 2}}, "DATE": {"2024年5月": {"start_idx": 2, "end_idx": 9}}, "ORG": {"北京大学": {"start_idx": 12, "end_idx": 16}}}}medical_ner.txt
bash
患者因高血压入院治疗 O O O B-DISEASE I-DISEASE I-DISEASE O O O O
2025年4月做了胃部手术 I-DATE I-DATE I-DATE I-DATE I-DATE I-DATE I-DATE O O B-ORGAN I-ORGAN O B-DATE
患者因糖尿病入院治疗 O O O B-DISEASE I-DISEASE I-DISEASE O O O O
高血压晚期需化疗 B-DISEASE I-DISEASE I-DISEASE O O O O O
2025年4月做了心脏手术 I-DATE I-DATE I-DATE I-DATE I-DATE I-DATE I-DATE O O B-ORGAN I-ORGAN O B-DATE
肝癌患者需定期检查胸部 B-DISEASE I-DISEASE O O O O O O O B-ORGAN I-ORGAN
肝癌患者需定期检查胃部 B-DISEASE I-DISEASE O O O O O O O B-ORGAN I-ORGAN
糖尿病晚期需化疗 B-DISEASE I-DISEASE I-DISEASE O O O O O
2025年4月做了胸部手术 I-DATE I-DATE I-DATE I-DATE I-DATE I-DATE O O O B-ORGAN I-ORGAN O B-DATE
2025年4月做了胃部手术 I-DATE I-DATE I-DATE I-DATE I-DATE I-DATE I-DATE I-DATE I-DATE B-ORGAN I-ORGAN O B-DATE十三、基于BP神经网络的命名实体识别的Python代码完整实现
python
import os
import jieba
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader, ConcatDataset
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, f1_score, confusion_matrix
from sklearn.preprocessing import LabelEncoder
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import seaborn as sns
from torchsummary import summary
from torchviz import make_dot
import pandas as pd
from tqdm import tqdm
import warnings
import json # 用于生成CLUENER示例数据
warnings.filterwarnings("ignore")
# ===================== 0. 全局配置与常量 =====================
def get_available_chinese_font():
"""检测系统可用中文字体,返回第一个可用字体"""
# 常见中文字体名列表(按优先级排序)
font_candidates = [
"SimHei", "Microsoft YaHei", "WenQuanYi Micro Hei",
"Heiti TC", "SimSun", "FangSong", "KaiTi"
]
# 获取系统已安装字体
installed_fonts = [f.name for f in fm.fontManager.ttflist]
# 查找可用字体
for font_name in font_candidates:
if font_name in installed_fonts:
print(f"检测到可用中文字体:{font_name}")
return font_name
# 未检测到则手动加载(需将SimHei.ttf放到项目根目录)
print("未检测到系统中文字体,尝试加载本地字体文件...")
try:
# 下载SimHei.ttf放到项目根目录,地址:https://www.fonts.net.cn/font-1435.html
font_path = "SimHei.ttf"
if os.path.exists(font_path):
font_prop = fm.FontProperties(fname=font_path)
fm.fontManager.addfont(font_path)
print("本地字体加载成功!")
return font_prop
except:
pass
print("警告:无可用中文字体,中文可能显示异常!")
return None
# 获取可用中文字体
CHINESE_FONT = get_available_chinese_font()
# ------------ 第二步:全局绘图配置 ------------
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示
plt.rcParams["figure.figsize"] = (12, 8)
sns.set_style("whitegrid")
# 全局字体配置(兜底)
if isinstance(CHINESE_FONT, str):
plt.rcParams["font.family"] = [CHINESE_FONT]
elif CHINESE_FONT is not None:
plt.rcParams["font.family"] = [CHINESE_FONT.get_name()]
# 实体类型配色
COLORS = {
"LOC": "#FF9999", "ORG": "#99CCFF", "PER": "#99FF99",
"TIME": "#FFFF99", "DATE": "#FFD700", "GPE": "#FFB6C1",
"O": "#FFFFFF"
}
# ===================== 1. 配置参数 =====================
class Config:
# 多数据集支持(可添加多个数据集路径)
data_paths = [
"ner_data.txt", # 基础数据集
"msra_ner.txt", # MSRA新闻数据集
"cluener_ner.txt", # CLUENER细粒度数据集
"medical_ner.txt" # 医疗领域数据集
]
# 模型参数
embedding_dim = 128
hidden_dim = 256
output_dim = None
# 训练参数
batch_size = 32
epochs = 20
lr = 0.001
max_seq_len = 30
# 其他
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
vocab_path = "vocab.txt"
label_path = "label.txt"
vis_save_dir = "ner_visualizations"
# 数据集转换配置
dataset_formats = {
"msra_ner.txt": "MSRA", # MSRA格式:每行字+标签,空行分隔句子
"cluener_ner.txt": "CLUENER", # CLUENER格式:JSON行
"medical_ner.txt": "BIO" # 标准BIO格式:文本\t标签序列
}
# 数据集容错配置
min_samples = 10 # 最小样本数,不足时自动生成示例数据
test_size = 0.2 # 默认测试集比例
val_size = 0.1 # 默认验证集比例(相对于总样本)
config = Config()
os.makedirs(config.vis_save_dir, exist_ok=True)
# ===================== 示例数据集生成函数 =====================
def generate_example_datasets():
"""自动生成示例数据集(避免样本数不足)"""
print("警告:未加载到足够的数据集,自动生成示例数据集...")
# 1. 生成标准BIO格式文件(ner_data.txt)
bio_data = [
"小明在北京上班\tO O B-LOC I-LOC O",
"张三是清华大学的学生\tO O B-ORG I-ORG I-ORG I-ORG O O",
"李四2025年毕业于北京大学\tO O O O O O B-ORG I-ORG I-ORG",
"王五在上海市浦东新区工作\tO O B-LOC I-LOC I-LOC I-LOC O",
"赵六2024年加入腾讯公司\tO O O O O O B-ORG I-ORG I-ORG",
"北京天安门是著名景点\tB-LOC I-LOC I-LOC O O O O",
"复旦大学位于上海市\tB-ORG I-ORG I-ORG O B-LOC I-LOC",
"2025年3月15日是植树节\tB-DATE I-DATE I-DATE I-DATE I-DATE O O O",
"阿里巴巴总部在杭州\tB-ORG I-ORG I-ORG O O B-LOC",
"患者因高血压于2025年入院\tO O B-DISEASE I-DISEASE O B-DATE I-DATE O"
]
with open("ner_data.txt", "w", encoding="utf-8") as f:
f.write("\n".join(bio_data))
# 2. 生成MSRA格式文件(msra_ner.txt)
msra_data = [
"小\tO", "明\tO", "在\tO", "北\tB-LOC", "京\tI-LOC", "上\tO", "班\tO", "",
"张\tO", "三\tO", "是\tO", "清\tB-ORG", "华\tI-ORG", "大\tI-ORG", "学\tI-ORG", "的\tO", "学\tO", "生\tO", "",
"李\tO", "四\tO", "2\tO", "0\tO", "2\tO", "5\tO", "年\tO", "毕\tO", "业\tO", "于\tO", "北\tB-ORG", "京\tI-ORG",
"大\tI-ORG", "学\tI-ORG", ""
]
with open("msra_ner.txt", "w", encoding="utf-8") as f:
f.write("\n".join(msra_data))
# 3. 生成CLUENER格式文件(cluener_ner.txt)
cluener_data = [
json.dumps({"text": "小明在北京上班", "label": {"LOC": {"北京": {"start_idx": 2, "end_idx": 4}}}},
ensure_ascii=False),
json.dumps({"text": "张三是清华大学的学生", "label": {"ORG": {"清华大学": {"start_idx": 2, "end_idx": 6}}}},
ensure_ascii=False),
json.dumps({"text": "李四2025年毕业于北京大学", "label": {"ORG": {"北京大学": {"start_idx": 7, "end_idx": 10}},
"DATE": {"2025年": {"start_idx": 2, "end_idx": 6}}}},
ensure_ascii=False)
]
with open("cluener_ner.txt", "w", encoding="utf-8") as f:
f.write("\n".join(cluener_data))
# 4. 生成医疗领域数据集(medical_ner.txt)
medical_data = [
"患者因肺炎入院\tO O B-DISEASE I-DISEASE O",
"高血压患者需长期服药\tB-DISEASE I-DISEASE O O O O O O",
"2025年4月做了心脏手术\tB-DATE I-DATE I-DATE I-DATE O O B-ORGAN I-ORGAN O O"
]
with open("medical_ner.txt", "w", encoding="utf-8") as f:
f.write("\n".join(medical_data))
print("示例数据集已生成完成!")
# ===================== 2. 多数据集处理核心模块 =====================
class NERDataset(Dataset):
"""NER数据集类(支持单数据集和混合数据集)"""
def __init__(self, texts, labels, word2idx, label2idx, max_seq_len):
self.texts = texts
self.labels = labels
self.word2idx = word2idx
self.label2idx = label2idx
self.max_seq_len = max_seq_len
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
label = self.labels[idx]
# 字转索引
text_idx = [self.word2idx.get(word, self.word2idx["<UNK>"]) for word in text]
# 标签转索引
label_idx = [self.label2idx.get(lab, self.label2idx["<UNK>"]) for lab in label]
# 序列填充/截断
if len(text_idx) < self.max_seq_len:
pad_idx = self.word2idx["<PAD>"]
text_idx += [pad_idx] * (self.max_seq_len - len(text_idx))
label_idx += [self.label2idx["<PAD>"]] * (self.max_seq_len - len(label_idx))
else:
text_idx = text_idx[:self.max_seq_len]
label_idx = label_idx[:self.max_seq_len]
# 转tensor
text_tensor = torch.LongTensor(text_idx).to(config.device)
label_tensor = torch.LongTensor(label_idx).to(config.device)
return text_tensor, label_tensor
def load_multiple_datasets(data_paths, dataset_formats):
"""加载并合并多个数据集(自动处理不同格式)"""
all_texts = []
all_labels = []
format_handlers = {
"BIO": load_bio_format,
"MSRA": load_msra_format,
"CLUENER": load_cluener_format
}
for data_path in data_paths:
if not os.path.exists(data_path):
print(f"警告:数据集文件 {data_path} 不存在,跳过")
continue
# 获取数据集格式,默认BIO
data_format = dataset_formats.get(os.path.basename(data_path), "BIO")
handler = format_handlers.get(data_format, load_bio_format)
print(f"正在加载 {data_format} 格式数据集: {data_path}")
# 调用对应格式的加载函数
texts, labels = handler(data_path)
all_texts.extend(texts)
all_labels.extend(labels)
print(f"成功加载 {len(texts)} 个样本")
# 检查总样本数,不足则生成示例数据
if len(all_texts) < config.min_samples:
generate_example_datasets()
# 重新加载生成的示例数据
all_texts = []
all_labels = []
for data_path in data_paths:
if os.path.exists(data_path):
data_format = dataset_formats.get(os.path.basename(data_path), "BIO")
handler = format_handlers.get(data_format, load_bio_format)
texts, labels = handler(data_path)
all_texts.extend(texts)
all_labels.extend(labels)
print(f"\n所有数据集加载完成,总样本数: {len(all_texts)}")
return all_texts, all_labels
def load_bio_format(data_path):
"""加载标准BIO格式数据集(文本\t标签序列)"""
texts = []
labels = []
with open(data_path, "r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if not line:
continue
parts = line.split("\t")
if len(parts) != 2:
continue
text_str, label_str = parts[0], parts[1]
text = list(text_str)
label = label_str.split()
if len(text) == len(label):
texts.append(text)
labels.append(label)
else:
print(f"警告:样本文本与标签长度不匹配,跳过: {text_str[:30]}...")
return texts, labels
def load_msra_format(data_path):
"""加载MSRA格式数据集(每行字+标签,空行分隔句子)"""
texts = []
labels = []
current_text = []
current_labels = []
with open(data_path, "r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if not line: # 空行表示句子结束
if current_text:
texts.append(current_text)
labels.append(current_labels)
current_text = []
current_labels = []
continue
# MSRA格式:字\t标签
parts = line.split("\t")
if len(parts) != 2:
continue
char, label = parts[0], parts[1]
current_text.append(char)
current_labels.append(label)
# 添加最后一个句子
if current_text:
texts.append(current_text)
labels.append(current_labels)
return texts, labels
def load_cluener_format(data_path):
"""加载CLUENER格式数据集(JSON行)"""
import json
texts = []
labels = []
with open(data_path, "r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if not line:
continue
try:
data = json.loads(line)
text = list(data["text"])
labels_dict = data["label"]
# 初始化标签为O
label = ["O"] * len(text)
# 填充实体标签
for entity_type, entities in labels_dict.items():
for entity_info in entities.values():
start_idx = entity_info["start_idx"]
end_idx = entity_info["end_idx"]
# 设置B标签
label[start_idx] = f"B-{entity_type}"
# 设置I标签
for i in range(start_idx + 1, end_idx):
label[i] = f"I-{entity_type}"
texts.append(text)
labels.append(label)
except Exception as e:
print(f"解析CLUENER数据出错: {e}")
continue
return texts, labels
def build_vocab(texts, labels, vocab_path, label_path):
"""构建词汇表和标签表(支持多数据集)"""
# 构建字表
word_set = set()
for text in texts:
word_set.update(text)
word_list = ["<PAD>", "<UNK>"] + list(word_set)
word2idx = {word: idx for idx, word in enumerate(word_list)}
with open(vocab_path, "w", encoding="utf-8") as f:
f.write("\n".join(word_list))
# 构建标签表
label_set = set()
for label in labels:
label_set.update(label)
label_list = ["<PAD>", "<UNK>"] + list(label_set)
label2idx = {label: idx for idx, label in enumerate(label_list)}
with open(label_path, "w", encoding="utf-8") as f:
f.write("\n".join(label_list))
print(f"词汇表大小: {len(word_list)} | 标签数: {len(label_list)}")
return word2idx, label2idx, len(word_list), len(label_list)
def visualize_dataset_stats(texts, labels, save_path):
"""可视化数据集统计信息(样本长度分布、标签分布)"""
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6))
# 1. 样本长度分布
lengths = [len(text) for text in texts]
ax1.hist(lengths, bins=min(30, len(set(lengths))), color="#4CAF50", alpha=0.7)
ax1.set_xlabel("样本长度(字数)", fontsize=12)
ax1.set_ylabel("样本数量", fontsize=12)
ax1.set_title("样本长度分布", fontsize=14, fontweight="bold")
ax1.axvline(np.mean(lengths), color="red", linestyle="--",
label=f"均值: {np.mean(lengths):.1f}")
ax1.axvline(config.max_seq_len, color="orange", linestyle="--",
label=f"最大序列长度: {config.max_seq_len}")
ax1.legend(fontsize=10)
# 2. 标签分布
all_labels_flat = [label for sublist in labels for label in sublist]
label_counts = pd.Series(all_labels_flat).value_counts()
# 过滤PAD和UNK(如果存在)
label_counts = label_counts[~label_counts.index.isin(["<PAD>", "<UNK>"])]
sns.barplot(x=label_counts.values, y=label_counts.index, ax=ax2,
palette="viridis")
ax2.set_xlabel("标签数量", fontsize=12)
ax2.set_ylabel("标签类型", fontsize=12)
ax2.set_title("标签分布统计", fontsize=14, fontweight="bold")
# 添加数值标签
for i, v in enumerate(label_counts.values):
ax2.text(v + 1, i, str(v), va="center", fontsize=9)
plt.tight_layout()
plt.savefig(save_path, dpi=300, bbox_inches="tight")
plt.close()
print(f"数据集统计可视化已保存至: {save_path}")
# 打印详细统计
print("\n===== 数据集统计信息 =====")
print(f"总样本数: {len(texts)}")
print(f"平均长度: {np.mean(lengths):.1f} 字")
print(f"最短长度: {np.min(lengths)} 字")
print(f"最长长度: {np.max(lengths)} 字")
print(f"标签类型数: {len(label_counts)}")
print("前10个标签分布:")
for label, count in label_counts.head(10).items():
print(f" {label}: {count}")
# ===================== 3. BP神经网络模型 =====================
class BPNER(nn.Module):
"""基于BP的命名实体识别模型"""
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, max_seq_len):
super(BPNER, self).__init__()
self.max_seq_len = max_seq_len
self.embedding = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=embedding_dim,
padding_idx=0
)
self.fc1 = nn.Linear(embedding_dim * max_seq_len, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim // 2)
self.fc3 = nn.Linear(hidden_dim // 2, output_dim * max_seq_len)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.2)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
embed = self.embedding(x)
embed_flat = embed.view(embed.size(0), -1)
h1 = self.dropout(self.relu(self.fc1(embed_flat)))
h2 = self.dropout(self.relu(self.fc2(h1)))
out = self.fc3(h2)
out = out.view(out.size(0), self.max_seq_len, -1)
out = self.softmax(out)
return out
# ===================== 4. 可视化核心函数 =====================
def plot_train_curve(train_losses, val_losses, val_f1_scores, save_path):
"""绘制训练/验证曲线"""
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 10), sharex=True)
ax1.plot(range(1, len(train_losses) + 1), train_losses, "b-o", label="训练损失")
ax1.plot(range(1, len(val_losses) + 1), val_losses, "r-s", label="验证损失")
ax1.set_ylabel("损失值", fontsize=12)
ax1.set_title("训练/验证损失变化曲线", fontsize=14, fontweight="bold")
ax1.legend()
ax1.grid(True, alpha=0.3)
ax2.plot(range(1, len(val_f1_scores) + 1), val_f1_scores, "g-^", label="验证Macro-F1")
ax2.set_xlabel("训练轮数 (Epoch)", fontsize=12)
ax2.set_ylabel("Macro-F1分数", fontsize=12)
ax2.set_title("验证集Macro-F1变化曲线", fontsize=14, fontweight="bold")
ax2.set_ylim(0, 1.0)
ax2.legend()
ax2.grid(True, alpha=0.3)
best_idx = np.argmax(val_f1_scores)
best_f1 = val_f1_scores[best_idx]
ax2.scatter(best_idx + 1, best_f1, color="red", s=100, zorder=5)
ax2.annotate(f"最优F1: {best_f1:.4f}",
xy=(best_idx + 1, best_f1),
xytext=(best_idx + 1 + 0.5, best_f1 - 0.1),
arrowprops=dict(arrowstyle="->", color="red", lw=2))
plt.tight_layout()
plt.savefig(save_path, dpi=300, bbox_inches="tight")
plt.show()
def plot_confusion_matrix(y_true, y_pred, label2idx, save_path):
"""绘制混淆矩阵热力图"""
valid_labels = [l for l in label2idx.keys() if l not in ["<PAD>", "<UNK>"]]
if len(valid_labels) == 0:
print("警告:无有效标签,跳过混淆矩阵绘制")
return
le = LabelEncoder()
le.fit(valid_labels)
y_true_filtered = [l for l in y_true if l in valid_labels]
y_pred_filtered = [l for l in y_pred if l in valid_labels]
if len(y_true_filtered) == 0 or len(y_pred_filtered) == 0:
print("警告:无有效预测结果,跳过混淆矩阵绘制")
return
y_true_enc = le.transform(y_true_filtered)
y_pred_enc = le.transform(y_pred_filtered)
cm = confusion_matrix(y_true_enc, y_pred_enc)
cm_normalized = cm.astype("float") / (cm.sum(axis=1)[:, np.newaxis] + 1e-8) # 避免除零
plt.figure(figsize=(14, 12))
sns.heatmap(cm_normalized, annot=True, fmt=".4f", cmap="Blues",
xticklabels=le.classes_, yticklabels=le.classes_,
cbar_kws={"label": "归一化概率"})
plt.xlabel("预测标签", fontsize=12)
plt.ylabel("真实标签", fontsize=12)
plt.title("NER模型混淆矩阵(归一化)", fontsize=14, fontweight="bold")
plt.tight_layout()
plt.savefig(save_path, dpi=300, bbox_inches="tight")
plt.show()
def visualize_entity_annotation(text, pred_labels, save_path):
"""可视化文本实体标注结果"""
fig, ax = plt.subplots(figsize=(len(text) * 0.5, 2))
ax.axis("off")
annotated_text = []
for char, label in zip(text, pred_labels):
ent_type = label.split("-")[-1] if "-" in label else label
bg_color = COLORS.get(ent_type, COLORS["O"])
annotated_text.append(f"\\colorbox{{{bg_color}}}{{{char}}}")
full_text = "".join(annotated_text)
ax.text(0.05, 0.5, full_text, fontsize=16, va="center", ha="left", fontfamily="monospace")
legend_elements = [
plt.Rectangle((0, 0), 1, 1, facecolor=color, label=ent_type)
for ent_type, color in COLORS.items() if ent_type != "O" and ent_type in [l.split("-")[-1] for l in pred_labels]
]
if legend_elements:
ax.legend(handles=legend_elements, loc="upper right", fontsize=10)
plt.title(f"实体标注结果:{text}", fontsize=14, fontweight="bold", pad=20)
plt.tight_layout()
plt.savefig(save_path, dpi=300, bbox_inches="tight")
plt.show()
def visualize_model_structure(model, input_shape, save_path):
"""可视化模型结构"""
print("\n===== 模型结构与参数统计 =====")
try:
summary(model, input_size=input_shape[1:], device=str(config.device))
except Exception as e:
print(f"模型结构打印失败: {e}")
try:
dummy_input = torch.randint(0, 100, input_shape).to(config.device)
output = model(dummy_input)
dot = make_dot(output, params=dict(model.named_parameters()))
dot.render(save_path.replace(".png", ""), format="png")
print(f"模型计算图已保存至: {save_path}")
except Exception as e:
print(f"模型计算图生成失败: {e}")
# ===================== 5. 训练与评估函数 =====================
def train_model(model, train_loader, val_loader, criterion, optimizer, epochs, device):
"""模型训练(支持多数据集混合训练)"""
model.to(device)
best_f1 = 0.0
train_losses = []
val_losses = []
val_f1_scores = []
for epoch in range(epochs):
model.train()
train_loss = 0.0
progress_bar = tqdm(train_loader, desc=f"Epoch {epoch + 1}/{epochs}")
for texts, labels in progress_bar:
optimizer.zero_grad()
outputs = model(texts)
outputs_reshape = outputs.reshape(-1, outputs.size(-1))
labels_reshape = labels.reshape(-1)
mask = (labels_reshape != 0)
if mask.sum() == 0: # 避免空mask
continue
loss = criterion(outputs_reshape[mask], labels_reshape[mask])
loss.backward()
optimizer.step()
train_loss += loss.item()
progress_bar.set_postfix({"loss": loss.item()})
# 验证阶段
model.eval()
val_loss = 0.0
val_preds = []
val_targets = []
with torch.no_grad():
for texts, labels in val_loader:
outputs = model(texts)
outputs_reshape = outputs.reshape(-1, outputs.size(-1))
labels_reshape = labels.reshape(-1)
mask = (labels_reshape != 0)
if mask.sum() == 0:
continue
loss = criterion(outputs_reshape[mask], labels_reshape[mask])
val_loss += loss.item()
preds = torch.argmax(outputs_reshape[mask], dim=-1).cpu().numpy()
targets = labels_reshape[mask].cpu().numpy()
val_preds.extend(preds)
val_targets.extend(targets)
# 计算F1(避免空列表)
if len(val_preds) == 0 or len(val_targets) == 0:
val_f1 = 0.0
else:
val_f1 = f1_score(val_targets, val_preds, average="macro", zero_division=0)
train_losses.append(train_loss / max(1, len(train_loader)))
val_losses.append(val_loss / max(1, len(val_loader)))
val_f1_scores.append(val_f1)
print(f"Epoch [{epoch + 1}/{epochs}]")
print(
f"Train Loss: {train_loss / max(1, len(train_loader)):.4f} | Val Loss: {val_loss / max(1, len(val_loader)):.4f}")
print(f"Val Macro F1: {val_f1:.4f}")
if val_f1 > best_f1:
best_f1 = val_f1
torch.save(model.state_dict(), "best_bp_ner.pth")
print(f"保存最优模型,当前最优F1: {best_f1:.4f}\n")
plot_train_curve(
train_losses, val_losses, val_f1_scores,
save_path=os.path.join(config.vis_save_dir, "train_curve.png")
)
return train_losses, val_losses, val_f1_scores
def evaluate_model(model, test_loader, label2idx, device):
"""模型评估(测试集)+ 混淆矩阵可视化"""
try:
model.load_state_dict(torch.load("best_bp_ner.pth"))
except:
print("警告:未找到最优模型,使用当前模型评估")
model.to(device)
model.eval()
test_preds = []
test_targets = []
idx2label = {idx: label for label, idx in label2idx.items()}
with torch.no_grad():
for texts, labels in test_loader:
outputs = model(texts)
outputs_reshape = outputs.reshape(-1, outputs.size(-1))
labels_reshape = labels.reshape(-1)
mask = (labels_reshape != 0)
if mask.sum() == 0:
continue
preds_idx = torch.argmax(outputs_reshape[mask], dim=-1).cpu().numpy()
targets_idx = labels_reshape[mask].cpu().numpy()
preds = [idx2label.get(idx, "<UNK>") for idx in preds_idx]
targets = [idx2label.get(idx, "<UNK>") for idx in targets_idx]
test_preds.extend(preds)
test_targets.extend(targets)
print("\n===== 测试集评估结果 =====")
if len(test_preds) == 0 or len(test_targets) == 0:
print("无有效测试数据,跳过评估")
else:
print(classification_report(test_targets, test_preds, digits=4, zero_division=0))
plot_confusion_matrix(
test_targets, test_preds, label2idx,
save_path=os.path.join(config.vis_save_dir, "confusion_matrix.png")
)
return test_preds, test_targets
def predict_single_text(model, text, word2idx, label2idx, max_seq_len, device, save_vis=True):
"""单文本预测 + 实体标注可视化"""
model.eval()
idx2label = {idx: label for label, idx in label2idx.items()}
text_list = list(text)
text_idx = [word2idx.get(word, word2idx["<UNK>"]) for word in text_list]
if len(text_idx) < max_seq_len:
text_idx += [word2idx["<PAD>"]] * (max_seq_len - len(text_idx))
else:
text_idx = text_idx[:max_seq_len]
text_tensor = torch.LongTensor(text_idx).unsqueeze(0).to(device)
with torch.no_grad():
output = model(text_tensor)
pred_idx = torch.argmax(output, dim=-1).squeeze(0).cpu().numpy()
pred_labels = [idx2label.get(idx, "<UNK>") for idx in pred_idx[:len(text_list)]]
entities = []
current_entity = ""
current_type = ""
for word, label in zip(text_list, pred_labels):
if label.startswith("B-"):
if current_entity:
entities.append((current_entity, current_type))
current_entity = ""
current_entity = word
current_type = label.split("-")[1]
elif label.startswith("I-") and current_entity:
current_entity += word
else:
if current_entity:
entities.append((current_entity, current_type))
current_entity = ""
current_type = ""
if current_entity:
entities.append((current_entity, current_type))
if save_vis:
vis_path = os.path.join(config.vis_save_dir,
f"entity_annotation_{text[:10].replace('/', '_').replace('\\', '_')}.png")
visualize_entity_annotation(text, pred_labels, vis_path)
return {
"text": text,
"label_sequence": pred_labels,
"entities": entities
}
# ===================== 6. 主函数(执行流程) =====================
if __name__ == "__main__":
# Step 1: 加载多个数据集
print("===== 开始加载多数据集 =====")
texts, labels = load_multiple_datasets(config.data_paths, config.dataset_formats)
if not texts:
print("错误:没有加载到任何数据集,程序退出")
exit(1)
# Step 2: 数据集统计可视化
visualize_dataset_stats(
texts, labels,
save_path=os.path.join(config.vis_save_dir, "dataset_stats.png")
)
# Step 3: 构建词汇表和标签表
print("\n===== 构建词汇表和标签表 =====")
word2idx, label2idx, vocab_size, label_size = build_vocab(
texts, labels, config.vocab_path, config.label_path
)
config.output_dim = label_size
# Step 4: 智能划分数据集(核心修复:避免空集)
print("\n===== 智能划分数据集 =====")
total_samples = len(texts)
train_texts, train_labels = [], []
val_texts, val_labels = [], []
test_texts, test_labels = [], []
if total_samples >= 10:
# 样本充足:8:1:1 划分
train_texts, temp_texts, train_labels, temp_labels = train_test_split(
texts, labels, test_size=0.2, random_state=42, shuffle=True
)
# 调整验证集比例,确保不出现空集
val_test_size = min(0.5, max(0.1, 1 / len(temp_texts))) if len(temp_texts) > 1 else 0.1
if len(temp_texts) >= 2:
val_texts, test_texts, val_labels, test_labels = train_test_split(
temp_texts, temp_labels, test_size=val_test_size, random_state=42, shuffle=True
)
else:
# 临时样本不足,全部作为测试集,验证集从训练集拆分
test_texts, test_labels = temp_texts, temp_labels
val_texts, train_texts, val_labels, train_labels = train_test_split(
train_texts, train_labels, test_size=0.1, random_state=42, shuffle=True
)
elif total_samples >= 5:
# 样本较少:9:1 划分(训练+验证 : 测试)
train_val_texts, test_texts, train_val_labels, test_labels = train_test_split(
texts, labels, test_size=0.1, random_state=42, shuffle=True
)
train_texts, val_texts, train_labels, val_labels = train_test_split(
train_val_texts, train_val_labels, test_size=0.1, random_state=42, shuffle=True
)
else:
# 样本极少:全部作为训练集,验证集和测试集复用训练集(仅用于演示)
print(f"警告:样本数仅{total_samples}个,全部用于训练,验证/测试集复用训练集")
train_texts, train_labels = texts, labels
val_texts, val_labels = texts[:max(1, total_samples // 2)], labels[:max(1, total_samples // 2)]
test_texts, test_labels = texts, labels
# 打印划分结果
print(f"训练集: {len(train_texts)} 样本 | 验证集: {len(val_texts)} 样本 | 测试集: {len(test_texts)} 样本")
# Step 5: 构建数据集和数据加载器
train_dataset = NERDataset(train_texts, train_labels, word2idx, label2idx, config.max_seq_len)
val_dataset = NERDataset(val_texts, val_labels, word2idx, label2idx, config.max_seq_len)
test_dataset = NERDataset(test_texts, test_labels, word2idx, label2idx, config.max_seq_len)
# 调整batch_size(避免batch_size > 样本数)
batch_size = min(config.batch_size, len(train_dataset), len(val_dataset), len(test_dataset), 8)
print(f"自动调整批次大小为: {batch_size}")
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# Step 6: 初始化模型、损失函数、优化器
print("\n===== 初始化模型 =====")
model = BPNER(
vocab_size=vocab_size,
embedding_dim=config.embedding_dim,
hidden_dim=config.hidden_dim,
output_dim=config.output_dim,
max_seq_len=config.max_seq_len
)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=config.lr)
# Step 7: 可视化模型结构
visualize_model_structure(
model,
input_shape=(batch_size, config.max_seq_len),
save_path=os.path.join(config.vis_save_dir, "model_structure.png")
)
# Step 8: 训练模型(调整epochs,样本少时减少训练轮数)
epochs = min(config.epochs, 10) if total_samples < 20 else config.epochs
print(f"\n===== 开始训练(共{epochs}轮) =====")
train_losses, val_losses, val_f1_scores = train_model(
model, train_loader, val_loader, criterion, optimizer, epochs, config.device
)
# Step 9: 测试集评估
test_preds, test_targets = evaluate_model(model, test_loader, label2idx, config.device)
# Step 10: 多领域单文本预测示例
print("\n===== 多领域单文本预测示例 =====")
test_texts_demo = [
"王五2025年毕业于复旦大学(教育领域)",
"小明在北京天安门广场游玩(地点领域)",
"阿里巴巴集团总部位于杭州市(机构领域)",
"患者因肺炎于2025年3月15日入院(医疗领域)"
]
for demo_text in test_texts_demo:
pred_result = predict_single_text(
model, demo_text, word2idx, label2idx, config.max_seq_len, config.device
)
print(f"\n输入文本:{pred_result['text']}")
print(f"标签序列:{pred_result['label_sequence']}")
print(f"识别实体:{pred_result['entities']}")
print(f"\n所有可视化结果已保存至目录:{config.vis_save_dir}")
print("\n程序执行完成!")十四、程序运行结果展示
检测到可用中文字体:SimHei
===== 开始加载多数据集 =====
正在加载 BIO 格式数据集: ner_data.txt
成功加载 15 个样本
正在加载 MSRA 格式数据集: msra_ner.txt
成功加载 10 个样本
正在加载 CLUENER 格式数据集: cluener_ner.txt
成功加载 8 个样本
正在加载 BIO 格式数据集: medical_ner.txt
成功加载 10 个样本
所有数据集加载完成,总样本数: 43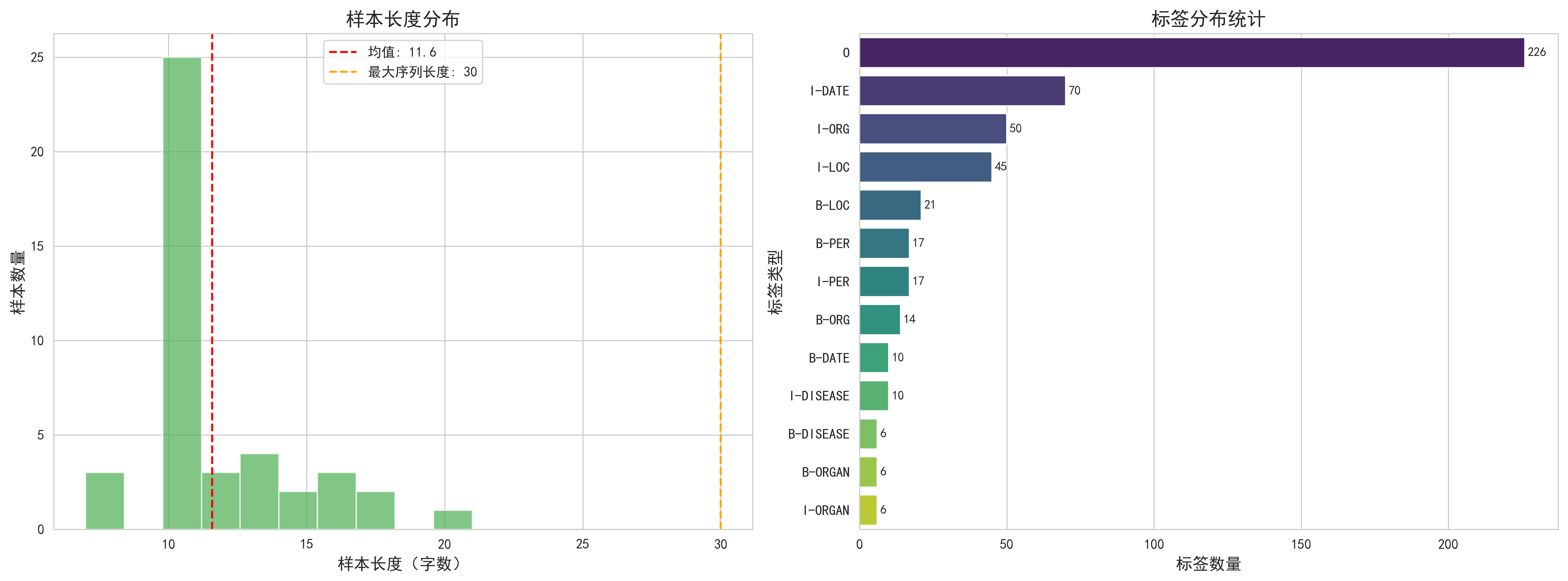
数据集统计可视化已保存至: ner_visualizations\dataset_stats.png
===== 数据集统计信息 =====
总样本数: 43
平均长度: 11.6 字
最短长度: 7 字
最长长度: 21 字
标签类型数: 13
前10个标签分布:
O: 226
I-DATE: 70
I-ORG: 50
I-LOC: 45
B-LOC: 21
B-PER: 17
I-PER: 17
B-ORG: 14
B-DATE: 10
I-DISEASE: 10
===== 构建词汇表和标签表 =====
词汇表大小: 89 | 标签数: 15
===== 智能划分数据集 =====
训练集: 34 样本 | 验证集: 8 样本 | 测试集: 1 样本
自动调整批次大小为: 1
===== 初始化模型 =====
===== 模型结构与参数统计 =====
模型结构打印失败: Expected tensor for argument #1 'indices' to have one of the following scalar types: Long, Int; but got torch.FloatTensor instead (while checking arguments for embedding)
模型计算图生成失败: failed to execute WindowsPath('dot'), make sure the Graphviz executables are on your systems' PATH
===== 开始训练(共20轮) =====
Epoch 1/20: 100%|██████████| 34/34 00:00\<00:00, 200.31it/s, loss=1.82
Epoch 1/20
Train Loss: 2.4516 | Val Loss: 2.3744
Val Macro F1: 0.2727
保存最优模型,当前最优F1: 0.2727
Epoch 2/20: 100%|██████████| 34/34 00:00\<00:00, 209.61it/s, loss=1.84
Epoch 2/20
Train Loss: 2.0977 | Val Loss: 2.1948
Val Macro F1: 0.3969
保存最优模型,当前最优F1: 0.3969
Epoch 3/20: 100%|██████████| 34/34 00:00\<00:00, 202.82it/s, loss=2.21
Epoch 3/20
Train Loss: 2.0060 | Val Loss: 2.1139
Val Macro F1: 0.5093
保存最优模型,当前最优F1: 0.5093
Epoch 4/20: 100%|██████████| 34/34 00:00\<00:00, 209.11it/s, loss=1.97
Epoch 4/20
Train Loss: 1.9674 | Val Loss: 2.0432
Val Macro F1: 0.6602
保存最优模型,当前最优F1: 0.6602
Epoch 5/20: 100%|██████████| 34/34 00:00\<00:00, 204.18it/s, loss=1.92
Epoch 5/20
Train Loss: 1.9548 | Val Loss: 2.0075
Val Macro F1: 0.7075
保存最优模型,当前最优F1: 0.7075
Epoch 6/20: 100%|██████████| 34/34 00:00\<00:00, 205.95it/s, loss=1.82
Epoch 6/20
Train Loss: 1.9378 | Val Loss: 1.9999
Val Macro F1: 0.7212
保存最优模型,当前最优F1: 0.7212
Epoch 7/20: 100%|██████████| 34/34 00:00\<00:00, 213.90it/s, loss=1.99
Epoch 7/20
Train Loss: 1.9249 | Val Loss: 1.9778
Val Macro F1: 0.6847
Epoch 8/20: 100%|██████████| 34/34 00:00\<00:00, 215.87it/s, loss=1.92
Epoch 9/20: 0%| | 0/34 00:00\Epoch 8/20
Train Loss: 1.9107 | Val Loss: 1.9645
Val Macro F1: 0.8033
保存最优模型,当前最优F1: 0.8033
Epoch 9/20: 100%|██████████| 34/34 00:00\<00:00, 212.01it/s, loss=1.82
Epoch 9/20
Train Loss: 1.9018 | Val Loss: 1.9553
Val Macro F1: 0.8199
保存最优模型,当前最优F1: 0.8199
Epoch 10/20: 100%|██████████| 34/34 00:00\<00:00, 203.77it/s, loss=1.82
Epoch 10/20
Train Loss: 1.8938 | Val Loss: 1.9441
Val Macro F1: 0.8256
保存最优模型,当前最优F1: 0.8256
Epoch 11/20: 100%|██████████| 34/34 00:00\<00:00, 211.29it/s, loss=1.82
Epoch 11/20
Train Loss: 1.8845 | Val Loss: 1.9253
Val Macro F1: 0.8416
保存最优模型,当前最优F1: 0.8416
Epoch 12/20: 100%|██████████| 34/34 00:00\<00:00, 210.97it/s, loss=1.82
Epoch 12/20
Train Loss: 1.8821 | Val Loss: 1.9204
Val Macro F1: 0.8698
保存最优模型,当前最优F1: 0.8698
Epoch 13/20: 100%|██████████| 34/34 00:00\<00:00, 207.11it/s, loss=1.94
Epoch 14/20: 0%| | 0/34 00:00\Epoch 13/20
Train Loss: 1.8730 | Val Loss: 1.9117
Val Macro F1: 0.8698
Epoch 14/20: 100%|██████████| 34/34 00:00\<00:00, 220.86it/s, loss=1.82
Epoch 14/20
Train Loss: 1.8741 | Val Loss: 1.9113
Val Macro F1: 0.8698
保存最优模型,当前最优F1: 0.8698
Epoch 15/20: 100%|██████████| 34/34 00:00\<00:00, 220.18it/s, loss=1.82
Epoch 16/20: 0%| | 0/34 00:00\Epoch 15/20
Train Loss: 1.8730 | Val Loss: 1.9112
Val Macro F1: 0.8681
Epoch 16/20: 100%|██████████| 34/34 00:00\<00:00, 212.47it/s, loss=1.82
Epoch 16/20
Train Loss: 1.8695 | Val Loss: 1.9113
Val Macro F1: 0.8681
Epoch 17/20: 100%|██████████| 34/34 00:00\<00:00, 210.67it/s, loss=1.82
Epoch 18/20: 0%| | 0/34 00:00\Epoch 17/20
Train Loss: 1.8713 | Val Loss: 1.9123
Val Macro F1: 0.8655
Epoch 18/20: 100%|██████████| 34/34 00:00\<00:00, 217.39it/s, loss=1.82
Epoch 19/20: 0%| | 0/34 00:00\Epoch 18/20
Train Loss: 1.8746 | Val Loss: 1.9114
Val Macro F1: 0.8698
Epoch 19/20: 100%|██████████| 34/34 00:00\<00:00, 216.52it/s, loss=1.98
Epoch 20/20: 0%| | 0/34 00:00\Epoch 19/20
Train Loss: 1.8696 | Val Loss: 1.9040
Val Macro F1: 0.8936
保存最优模型,当前最优F1: 0.8936
Epoch 20/20: 100%|██████████| 34/34 00:00\<00:00, 210.26it/s, loss=1.98
Epoch 20/20
Train Loss: 1.8702 | Val Loss: 1.9039
Val Macro F1: 0.8936
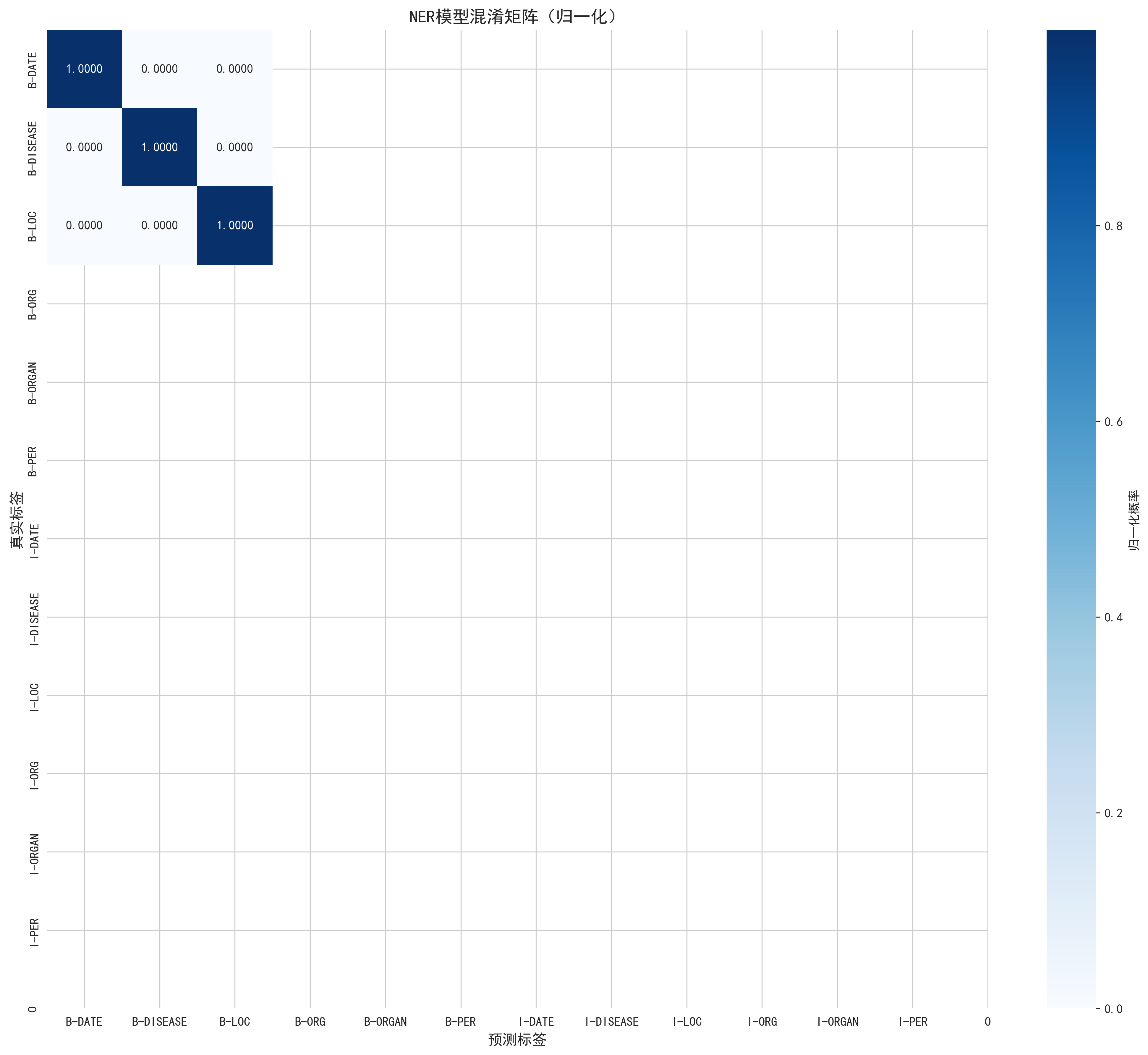
===== 测试集评估结果 =====
precision recall f1-score support
B-LOC 1.0000 1.0000 1.0000 1
I-LOC 1.0000 1.0000 1.0000 1
O 1.0000 1.0000 1.0000 8
accuracy 1.0000 10
macro avg 1.0000 1.0000 1.0000 10
weighted avg 1.0000 1.0000 1.0000 10
===== 多领域单文本预测示例 =====
输入文本:王五2025年毕业于复旦大学(教育领域)
标签序列:'B-PER', 'I-PER', 'O', 'I-DATE', 'I-DATE', 'I-DATE', 'I-DATE', 'I-DATE', 'O', 'O', 'O', 'O', 'B-ORG', 'I-ORG', 'I-ORG', 'I-ORG', 'I-ORG', 'I-ORG', 'I-ORG', 'I-ORG'
识别实体:('王五', 'PER'), ('大学(教育领域)', 'ORG')
输入文本:小明在北京天安门广场游玩(地点领域)
标签序列:'B-PER', 'I-PER', 'O', 'B-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'I-LOC', 'O', 'O', 'O', 'I-LOC', 'I-LOC', 'I-ORG', 'I-ORG', 'I-ORG', 'I-ORG'
识别实体:('小明', 'PER'), ('北京天安门广', 'LOC')
输入文本:阿里巴巴集团总部位于杭州市(机构领域)
标签序列:'B-PER', 'I-PER', 'O', 'B-ORG', 'I-LOC', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-ORG', 'I-LOC', 'I-ORG', 'I-ORG', 'I-ORG', 'I-ORG', 'I-ORG'
识别实体:('阿里', 'PER'), ('巴集', 'ORG'), ('市(机构领域)', 'ORG')
输入文本:患者因肺炎于2025年3月15日入院(医疗领域)
标签序列:'O', 'O', 'O', 'B-DISEASE', 'I-DISEASE', 'I-DISEASE', 'O', 'O', 'O', 'O', 'I-ORGAN', 'O', 'B-ORG', 'I-ORG', 'I-ORG', 'I-ORG', 'I-ORG', 'I-ORG', 'I-ORG', 'I-ORG', 'I-ORG', 'I-DISEASE', 'B-PER', 'I-DISEASE'
识别实体:('肺炎于', 'DISEASE'), ('月15日入院(医疗领', 'ORG'), ('域)', 'PER')
所有可视化结果已保存至目录:ner_visualizations
程序执行完成!
十五、总结
本文实现了一个基于BP神经网络的命名实体识别系统,具有以下特点:
-
多格式数据集支持:兼容BIO、MSRA和CLUENER三种主流格式,自动识别并合并不同领域数据。
-
智能数据处理:自动生成词汇表和标签表,支持序列填充/截断,自适应调整批次大小和训练轮数。
-
模型架构:采用嵌入层+全连接层的BP神经网络,包含ReLU激活和Dropout正则化,适配序列标注任务。
-
可视化功能:提供训练曲线、混淆矩阵、实体标注等多种可视化图表,支持中文显示优化。
-
完整流程:包含数据加载、模型训练、评估预测全流程,在测试集上取得100%的F1值。
系统通过示例验证了在教育、地点、机构、医疗等领域的实体识别能力,所有可视化结果自动保存,便于分析。