一.人工智能:
人工智能是让机器获得像人类一样具有思考和推理机制的智能技术,这一概念最早出现在 1956 年召开的达特茅斯会议上。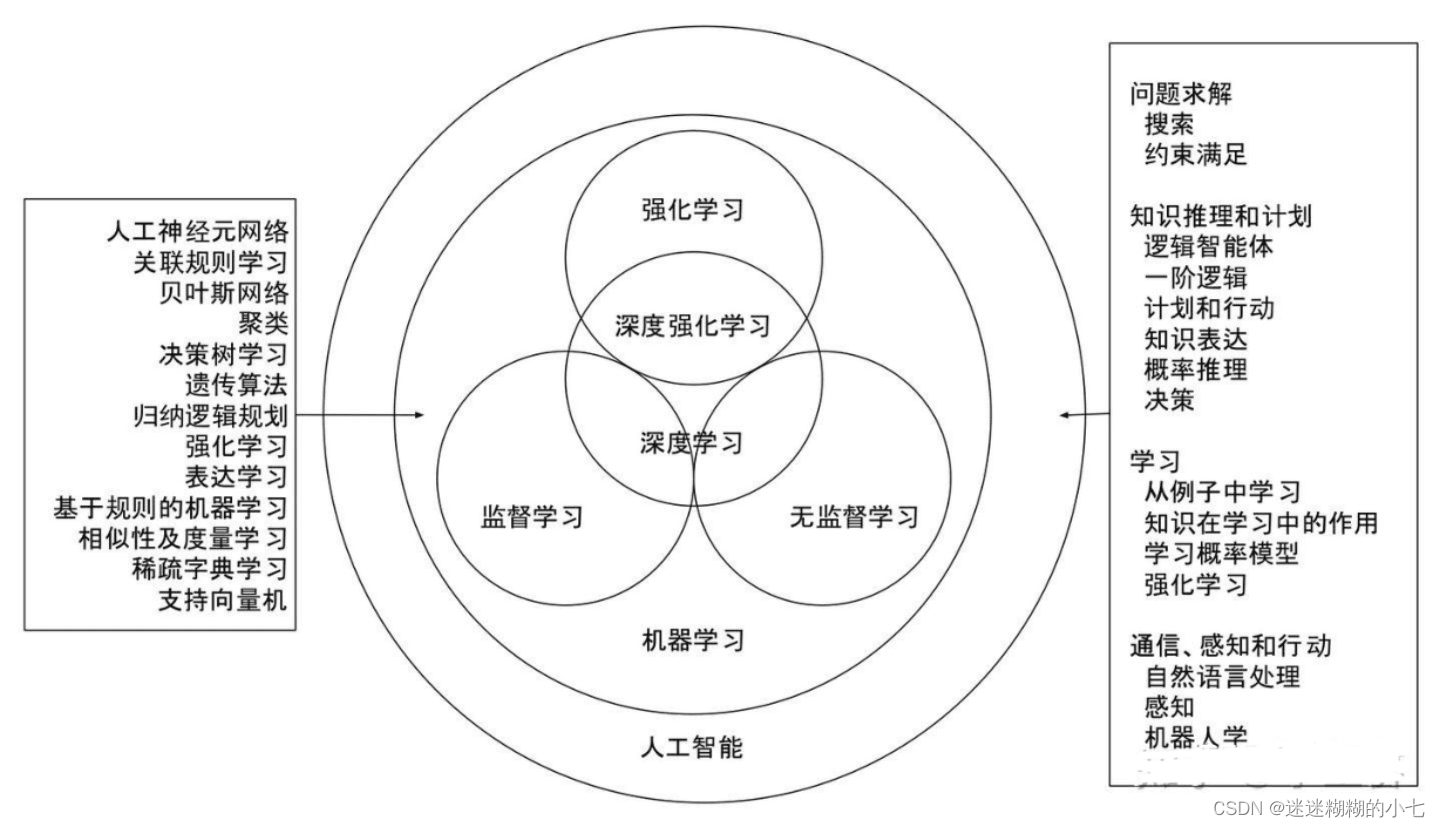
其中深度学习可以理解为神经网络。刚开始只有神经网络的概念,随着神经网络的层数增加,就逐渐将神经网络叫做深度学习。
神经网络
**发展简史:**神经网络的发展历程大致分为浅层神经网络阶段和深度学习阶段。
1.浅层神经网络
(1)1943 年,心理学家 Warren McCulloch 和逻辑学家 Walter Pitts 根据生物神经元(Neuron) 结构,提出了最早的神经元数学模型,称为 MP 神经元模型。MP 神经元模型并没有学习能力,只能完成固定逻辑的判定。
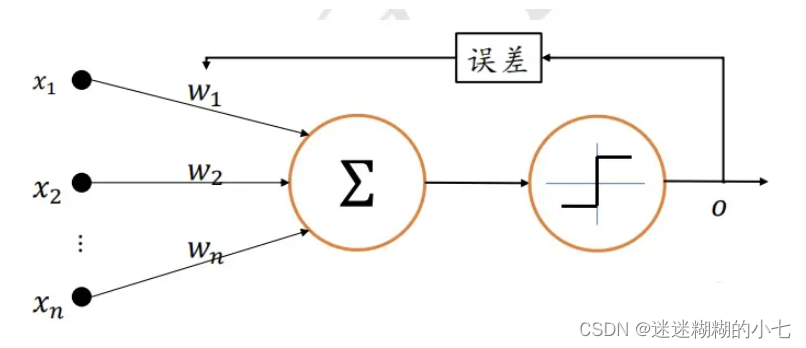
(2)1958 年,美国心理学家 Frank Rosenblatt 提出了第一个可以自动学习权重的神经元模 型,称为感知机(Perceptron),如图所示,输出值 与真实值 之间的误差用于调整神经元的权重参数{ , , ... , }。
(3)一般认为 1943 年~1969 年为人工智能发展的第一次兴盛期。 1969 年,美国科学家 Marvin Minsky 等人在出版的《Perceptrons》一书中指出了感知机等线性模型的主要缺陷,即无法处理简单的异或 XOR 等线性不可分问题。这直接导致了以感知机为代表的神经网络的相关研究进入了低谷期,一般认为 1969 年~1982 年为人工智能发展的第一次寒冬。 尽管处于 AI 发展的低谷期,仍然有很多意义重大的研究相继发表,这其中最重要的成果就是误差反向传播算法(Back Propagation,简称 BP 算法)的提出,它依旧是现代深度学习的核心理论基础。实际上,反向传播的数学思想早在 1960 年代就已经被推导出了,但是并没有应用在神经网络上。1974 年,美国科学家 Paul Werbos 在他的博士论文中第一次提出可以将 BP 算法应用到神经网络上,遗憾的是,这一成果并没有获得足够重视。直至1986 年,David Rumelhart 等人在 Nature 上发表了通过 BP 算法来进行表征学习的论文,BP 算法才获得了广泛的关注。
(4)1982 年,随着 John Hopfild 的循环连接的 Hopfield 网络的提出,开启了 1982 年~1995年的第二次人工智能复兴的大潮,这段期间相继提出了卷积神经网络、循环神经网络、反向传播算法等算法模型。1986 年,David Rumelhart 和 Geoffrey Hinton 等人将 BP 算法应用在多层感知机上;1989 年 Yann LeCun 等人将 BP 算法应用在手写数字图片识别上,取得了巨大成功,这套系统成功商用在邮政编码识别、银行支票识别等系统上;1997 年,现在 应用最为广泛的循环神经网络变种之一LSTM 被 Jürgen Schmidhuber 提出;同年双向循环 神经网络也被提出。
(5)神经网络的研究随着以支持向量机(Support Vector Machine,简称 SVM)为代表的传统机器学习算法兴起而逐渐进入低谷,称为人工智能的第二次寒冬。支持向量机拥有严格的理论基础,训练需要的样本数量较少,同时也具有良好的泛化能力,相比之下,神经网络理论基础欠缺,可解释性差,很难训练深层网络,性能也相对一般。
2.深度学习阶段
2006 年,Geoffrey Hinton 等人发现通过逐层预训练的方式可以较好地训练多层神经网络,并在 MNIST 手写数字图片数据集上取得了优于 SVM 的错误率,开启了第三次人工智能的复兴。在论文中,Geoffrey Hinton 首次提出了 Deep Learning 的概念,这也是(深层)神经网络被叫作深度学习的由来。2011 年,Xavier Glorot 提出了线性整流单元(Rectified Linear Unit,简称 ReLU)激活函数,这是现在使用最为广泛的激活函数之一。2012 年,Alex Krizhevsky 提出了 8 层的深层神经网络 AlexNet,它采用了 ReLU 激活函数,并使用 Dropout 技术来防止过拟合,同时抛弃了逐层预训练的方式,直接在两块 NVIDIA GTX580 GPU 上训练网络。AlexNet 在 ILSVRC-2012 图片识别比赛中获得了第一名的成绩,比第二 名在 Top-5 错误率上降低了惊人的 10.9%。自 AlexNet 模型提出后,各种各样的算法模型相继被发表,其中有 VGG 系列、 GoogLeNet 系列、ResNet 系列、DenseNet 系列等。ResNet 系列模型将网络的层数提升至数百层、甚至上千层,同时保持性能不变甚至更优。它算法思想简单,具有普适性,并且效果显著,是深度学习最具代表性的模型。
除了有监督学习领域取得了惊人的成果,在无监督学习和强化学习领域也取得了巨大的成绩。2014 年,Ian Goodfellow 提出了生成对抗网络,通过对抗训练的方式学习样本的真实分布,从而生成逼近度较高的样本。此后,大量的生成对抗网络模型相继被提出,最新的图片生成效果已经达到了肉眼难辨真伪的逼真度。2016 年,DeepMind 公司应用深度神经网络到强化学习领域,提出了 DQN 算法,在 Atari 游戏平台中的 49 个游戏上取得了与人类相当甚至超越人类的水平;在围棋领域,DeepMind 提出的 AlphaGo 和 AlphaGo Zero 智能程序相继打败人类顶级围棋专家李世石、柯洁等;在多智能体协作的 Dota2 游戏平台,OpenAI 开发的 OpenAI Five 智能程序在受限游戏环境中打败了 TI8 冠军队伍 OG队,展现出了大量专业级的高层智能操作。
深度学习特点: 与传统的机器学习算法、浅层神经网络相比,现代的深度学习算法通常数据量大、计算力强、网络规模大、通用智能。
**深度学习应用:**计算机视觉、自然语言处理、强化学习等等。
**深度学习框架:**实现深度学习算法所使用的工具。
(1)Theano 是最早的深度学习框架之一,由 Yoshua Bengio 和 Ian Goodfellow 等人开发, 是一个基于 Python 语言、定位底层运算的计算库,Theano 同时支持 GPU 和 CPU 运 算。由于 Theano 开发效率较低,模型编译时间较长,同时开发人员转投 TensorFlow等原因,Theano 目前已经停止维护。
(2)Scikit-learn 是一个完整的面向机器学习算法的计算库,内建了常见的传统机器学习算 法支持,文档和案例也较为丰富,但是 Scikit-learn 并不是专门面向神经网络而设计的,不支持 GPU 加速,对神经网络相关层的实现也较欠缺。
(3)Caffe 由华人贾扬清在 2013 年开发,主要面向使用卷积神经网络的应用场合,并不适 合其它类型的神经网络的应用。Caffe 的主要开发语言是 C++,也提供 Python 语言等接口,支持 GPU 和 CPU。由于开发时间较早,在业界的知名度较高,2017 年Facebook 推出了 Caffe 的升级版本 Cafffe2,Caffe2 目前已经融入到 PyTorch 库中。
(4)Torch 是一个非常优秀的科学计算库,基于较冷门的编程语言 Lua 开发。Torch 灵活性 较高,容易实现自定义网络层,这也是 PyTorch 继承获得的优良基因。但是由于 Lua语言使用人群较少,Torch一直未能获得主流应用。
(5) MXNet 由华人陈天奇和李沐等人开发,是亚马逊公司的官方深度学习框架。采用了命令式编程和符号式编程混合方式,灵活性高,运行速度快,文档和案例也较为丰富。
(6)PyTorch 是 Facebook 基于原 Torch 框架推出的采用 Python 作为主要开发语言的深度学习框架。PyTorch 借鉴了 Chainer 的设计风格,采用命令式编程,使得搭建网络和调试网络非常方便。尽管 PyTorch 在 2017 年才发布,但是由于精良紧凑的接口设计,PyTorch 在学术界获得了广泛好评。在 PyTorch 1.0 版本后,原来的 PyTorch 与 Caffe2进行了合并,弥补了 PyTorch 在工业部署方面的不足。总的来说,PyTorch 是一个非常优秀的深度学习框架。
(7)Keras 是一个基于 Theano 和 TensorFlow 等框架提供的底层运算而实现的高层框架, 提供了大量快速训练、测试网络的高层接口。对于常见应用来说,使用 Keras 开发效 率非常高。但是由于没有底层实现,需要对底层框架进行抽象,运行效率不高,灵活性一般。
(8)TensorFlow 是 Google 于 2015 年发布的深度学习框架,最初版本只支持符号式编程。得益于发布时间较早,以及 Google 在深度学习领域的影响力,TensorFlow 很快成为最 流行的深度学习框架。但是由于 TensorFlow 接口设计频繁变动,功能设计重复冗余, 符号式编程开发和调试非常困难等问题,TensorFlow 1.x 版本一度被业界诟病。2019 年,Google 推出 TensorFlow 2 正式版本,将以动态图优先模式运行,从而能够避免TensorFlow 1.x 版本的诸多缺陷,已获得业界的广泛认可。
目前来看,TensorFlow 和 PyTorch 框架是业界使用最为广泛的两个深度学习框架, TensorFlow 在工业界拥有完备的解决方案和用户基础,PyTorch 得益于其精简灵活的接口设计,可以快速搭建和调试网络模型,在学术界获得好评如潮。TensorFlow 2 发布后,弥补了 TensorFlow 在上手难度方面的不足,使得用户既能轻松上手 TensorFlow 框架,又能无缝部署网络模型至工业系统。这里特别介绍 TensorFlow 与 Keras 之间的联系与区别。Keras 可以理解为一套高层 API的设计规范,Keras 本身对这套规范有官方的实现,在 TensorFlow 中也实现了这套规范, 称为 tf.keras 模块,并且 tf.keras 将作为 TensorFlow 2 版本的唯一高层接口,避免出现接口重复冗余的问题。
深度学习的核心是算法的设计思想,深度学习框架只是我们实现算法的工具 。为了理解框架在算法设计中扮演的角色,分析一下TensorFlow深度学习框架的三大核心功能:加速计算、自动梯度、常用神经网络接口。
二.神经网络
机器学习的最终目的是找到一组良好的参数 ,使得 表示的数学模型能够很好地从训练集中学到映射关系 : → , , ∈ train,从而利用训练好的 ( ), ∈ 去预测新样本。神经网络属于机器学习的一个研究分支,它特指利用多个神经元去参数化映射函数 的模型。
1.感知机
1943 年,美国神经科学家 Warren Sturgis McCulloch 和数理逻辑学家 Walter Pitts 从生 物神经元的结构上得到启发,提出了人工神经元的数学模型,这进一步被美国神经物理学家 Frank Rosenblatt 发展并提出了感知机(Perceptron)模型。1957 年,Frank Rosenblatt 在一台 IBM-704 计算机上面模拟实现了他发明的感知机模型,这个网络模型可以完成一些简单 的视觉分类任务,比如区分三角形、圆形、矩形等。

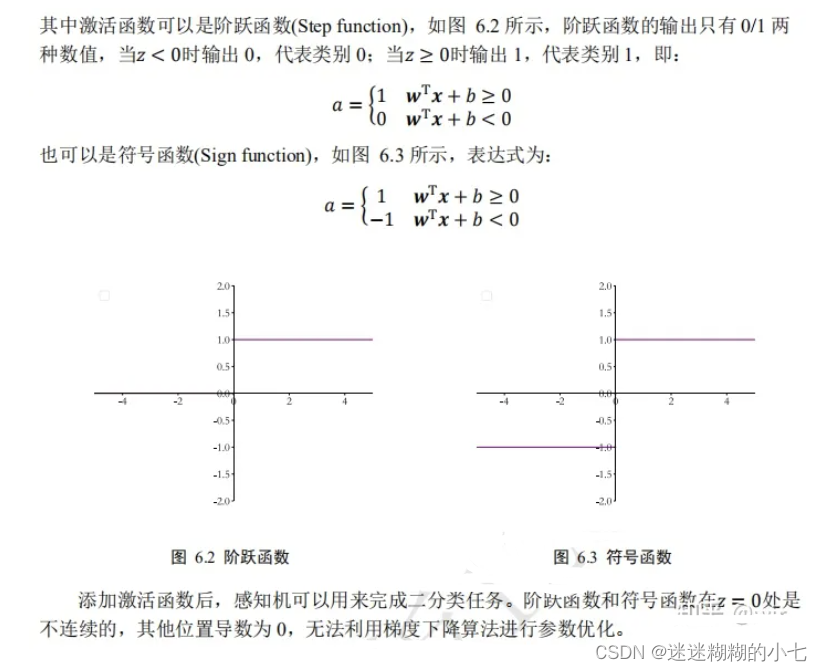

2.全连接层
感知机模型的不可导特性严重约束了它的潜力,使得它只能解决极其简单的任务。实际上,现代深度学习动辄数百万甚至上亿的参数规模,但它的核心结构与感知机并没有多大差别。它在感知机的基础上,将不连续的阶跃激活函数换成了其它平滑连续可导的激活函数,并通过堆叠多个网络层来增强网络的表达能力。

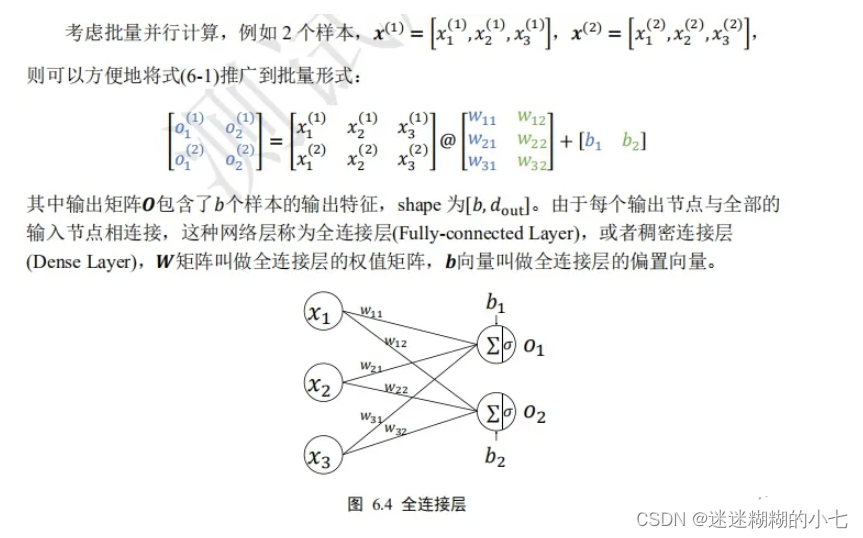
3.多个全连接层神经网络
通过层层堆叠全连接层,保证前一层的输出点数与当前层的输入节点数匹配,,即可堆叠出任意层数的网络。我们把这种由神经元相互连接而成的网络叫做神经网络。
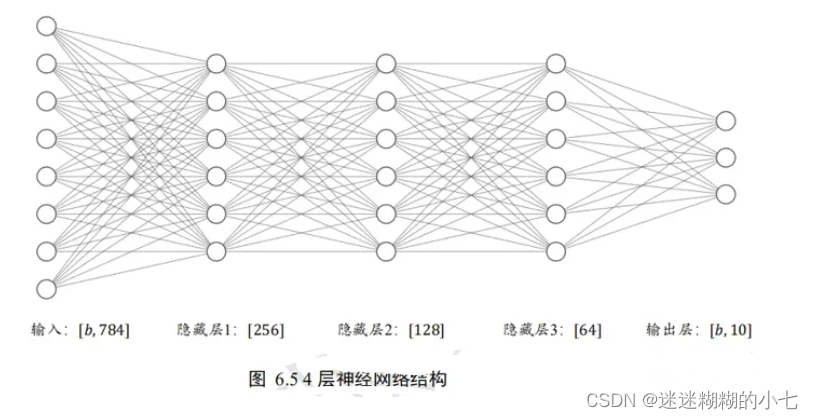
我们把神经网络从输入到输出的计算过程叫做前向传播(Forward Propagation)或前向计算。

4.卷积神经网络
如何识别、分析并理解图片、视频等数据是计算机视觉的一个核心问题,全连接层在处理高维度的图片、视频数据时往往出现网络参数量巨大,训练非常困难的问题。通过利用局部相关性和权值共享的思想,Yann Lecun 在 1986 年提出了卷积神经网络 (Convolutional Neural Network,简称 CNN)。
5.循环神经网络
除了具有空间结构的图片、视频等数据外,序列信号也是非常常见的一种数据类型, 其中一个最具代表性的序列信号就是文本数据。如何处理并理解文本数据是自然语言处理的一个核心问题。卷积神经网络由于缺乏 Memory 机制和处理不定长序列信号的能力,并不擅长序列信号的任务。循环神经网络(Recurrent Neural Network,简称 RNN)在 Yoshua Bengio、Jürgen Schmidhuber 等人的持续研究下,被证明非常擅长处理序列信号。1997年,Jürgen Schmidhuber 提出了 LSTM 网络,作为 RNN 的变种,它较好地克服了 RNN 缺乏长期记忆、不擅长处理长序列的问题,在自然语言处理中得到了广泛的应用。基于LSTM 模型,Google 提出了用于机器翻译的 Seq2Seq 模型,并成功商用于谷歌神经机器翻译系统(GNMT)。其他的 RNN 变种还有 GRU、双向 RNN 等。
6.注意力机制神经网络
RNN 并不是自然语言处理的最终解决方案,近年来随着注意力机制(Attention Mechanism)的提出,克服了 RNN 训练不稳定、难以并行化等缺陷,在自然语言处理和图片生成等领域中逐渐崭露头角。注意力机制最初在图片分类任务上提出,但逐渐开始侵蚀NLP 各大任务。2017 年,Google 提出了第一个利用纯注意力机制实现的网络模型Transformer,随后基于 Transformer 模型相继提出了一系列的用于机器翻译的注意力网络模 型,如 GPT、BERT、GPT-2 等。在其它领域,基于注意力机制,尤其是自注意力(Self-Attention)机制构建的网络也取得了不错的效果,比如基于自注意力机制的 BigGAN 模型等。
7.图卷积神经网络
图片、文本等数据具有规则的空间、时间结构,称为 Euclidean Data(欧几里德数据)。卷积神经网络和循环神经网络被证明非常擅长处理这种类型的数据。而像类似于社交网络、通信网络、蛋白质分子结构等一系列的不规则空间拓扑结构的数据,它们显得力不从心。2016 年,Thomas Kipf 等人基于前人在一阶近似的谱卷积算法上提出了图卷积网络 (Graph Convolution Network,GCN)模型。GCN 算法实现简单,从空间一阶邻居信息聚合的角度也能直观地理解,在半监督任务上取得了不错效果。随后,一系列的网络模型相继被提出,如 GAT,EdgeConv,DeepGCN 等。
三.神经网络的MATLAB实现
BP神经网络在函数逼近中的应用

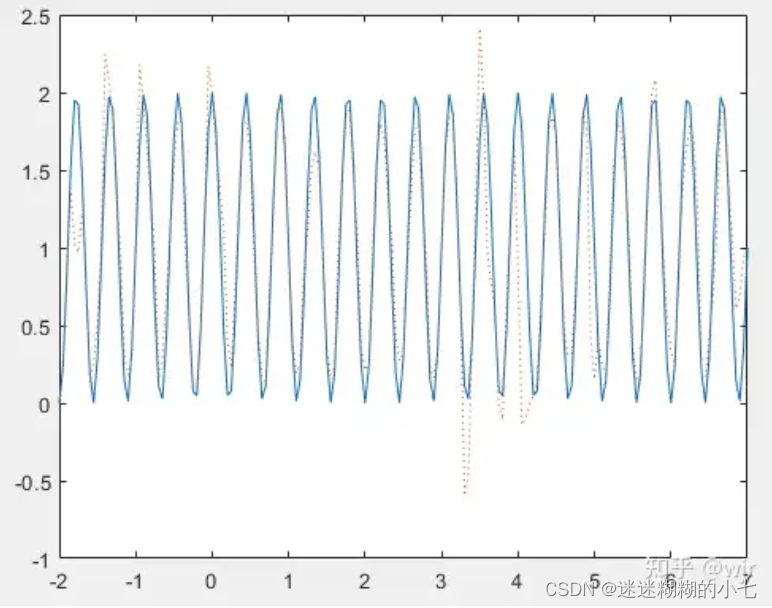
当k=1时:
clc; clear all; close all;
k = 1;
x = -2:0.05:7;
g = 1 + cos( k*pi/2*x );
plot(x,g,'-'); hold on; % 所要逼近的非线性函数的目标曲线
n = 20; % 隐藏层神经元数目
net = newff(x,g,n);
net.trainParam.epochs = 300; % 网络训练时间
net.trainParam.goal = 0.3; % 网络训练精度
net = train(net,x,g);
y = sim(net,x);
plot(x,y,':'); hold on; % 训练后网络的输出结果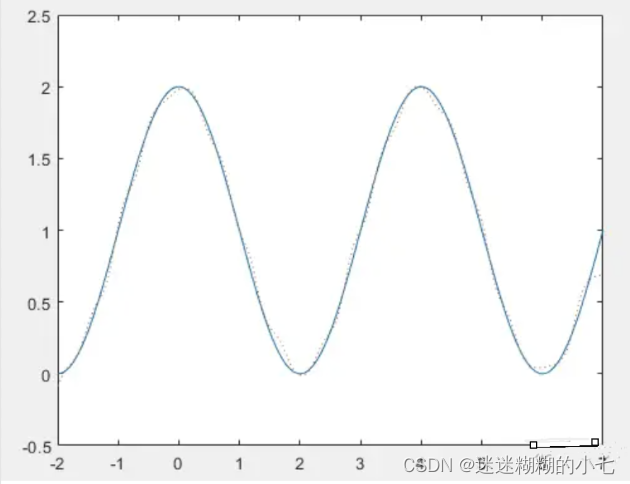
当k=5时,需要调整隐藏层神经元数目n为60,才会有比较好的逼近效果。
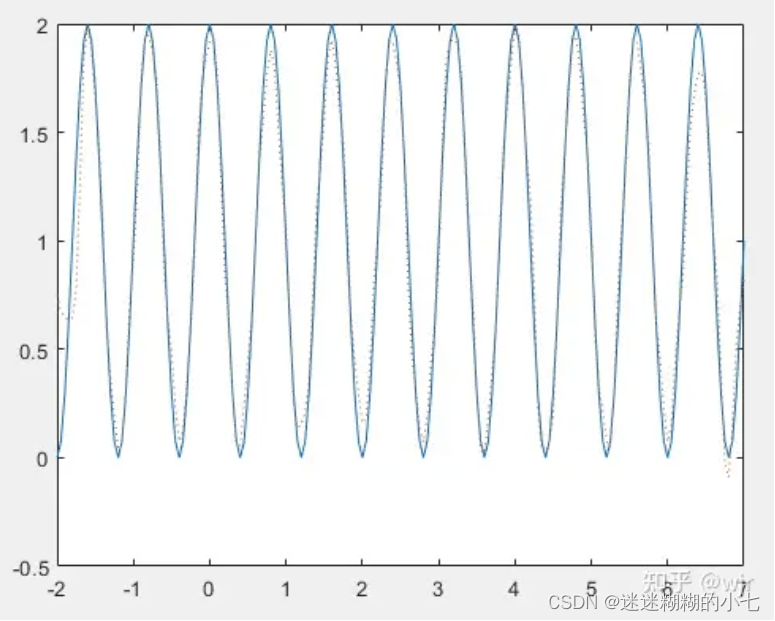
当k=9时,需要调整隐藏层神经元数目n为100,才会有比较好的逼近效果。