文章目录
用redis也是比较久了,并且也对其他消息中间件也用了相当多的时间,现在就redis是否适合做消息队列来梳理下,获取梳理完之后,可以有一个更加清晰的认知。笔者会从以下几个方面进行梳理。
一、简单的list消息队列
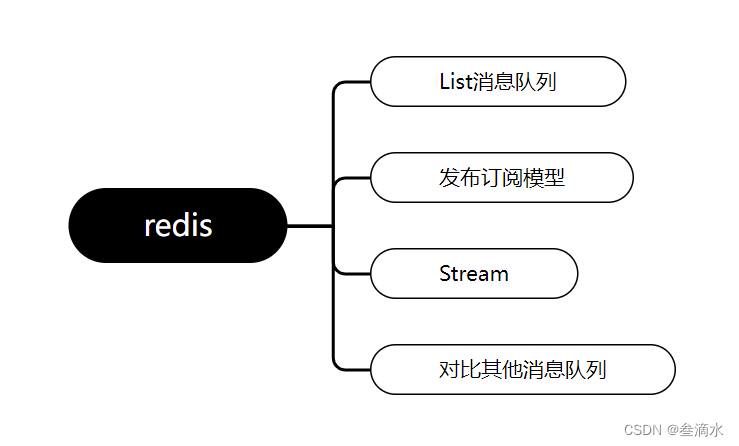
众所周知,redis常见的数据结构有String 、Hash 、List 、Set 、zset 。其中List可以是一个列表结构。可以通过LPUSH 、RPOP两个命令来实现一个简单的队列。
LPUSH将元素依次插入到列表头部RPOP获取最后一个元素,并且删除。
如下图所示:生产者通过LPUSH命令,依次插入a、b、c、d四个元素。消费者通过RPOP命令进行消费。
1.命令示例
生产者:
shell
# 通过LPUSH命令往test_queue填充a、b、c、d
127.0.0.1:6379> LPUSH test_queue a
(integer) 1
127.0.0.1:6379> LPUSH test_queue b
(integer) 2
127.0.0.1:6379> LPUSH test_queue c
(integer) 3
127.0.0.1:6379> LPUSH test_queue d
(integer) 4
127.0.0.1:6379> 消费者:
shell
消费者
127.0.0.1:6379> RPOP test_queue
"a"
127.0.0.1:6379> RPOP test_queue
"b"
127.0.0.1:6379> RPOP test_queue
"c"
127.0.0.1:6379> RPOP test_queue
"d"
127.0.0.1:6379> RPOP test_queue
(nil)
127.0.0.1:6379>2.伪代码示例
生产者相对简单,以简单的订单支付为例子
java
//在订单支付成功之后发送给积分系统
public void afterPayHandler(Order order){
//发送消息到积分系统
redisTemp.LPUSH("order",order);
}消费者
java
public void orderMessageListener(){
while(true){
//获取订单信息
Order order = redisTemp.RPOP("order");
if(order != null){
//做积分系统的业务,如添加积分等逻辑。
}
}
} 如上所示:消费者在消费的时候,必须通过循环一直拉取队列数据,达到数据的实时性,但是也出现了CPU空转的问题。如果我们判断空的时候sleep休眠一段时间,那就会存在消息实时性问题。休眠多久合适就成为了难以处理的问题。
好在redis有阻塞拉取的命令。
BRPOP test_queue 10(秒)。拉取命令,阻塞10秒。如果是0就是一直阻塞。
3.方案优劣
- 优点:足够简单,也很好理解。但是我确实是想不到哪个场景适合这个方案(笑哭)。感觉也只能算普及知识了。
- 缺点 :
- 不支持多消费者。任何一个消费者将redis的元素拉取删除之后,其他消费者都无法再次拉取到。那就只能仅限于一对一消费了。
- 消息丢失。没有ACK机制,如果拉取消息后宕机后,无法正常消费,就会导致消息的丢失。
二、Pub/Sub发布订阅
List数据结构可以认为是开发者为了简单方便,从而引进的一种消息队列的方式,但是绝不"正宗"。Pub/Sub这种从名字上可以看出来,就是专门为了消息队列而生的。
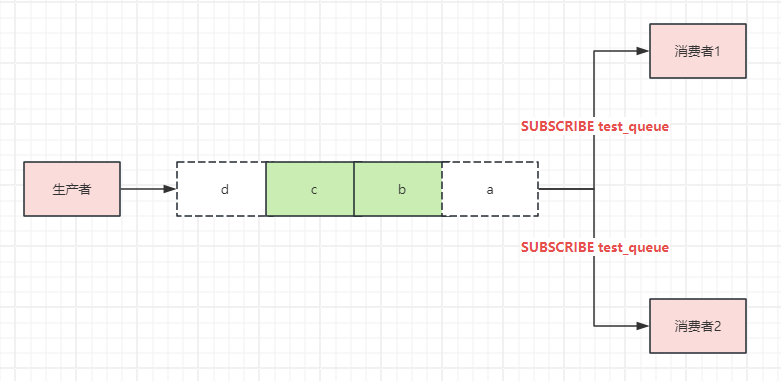
从上图可以看出,发布订阅模式,解决了多消费者的问题。但是还是存在两个问题。
1.消息丢失
发布订阅模型,没有进行消息存储,只是一个单纯的通道 ,实时的把消息传送给消费者。那么这样就会有一个问题,如果消费者中间下线,再次上线的时候,只能从最新的位置进行消费,这样就会有消息丢失啦。
2.消息堆积
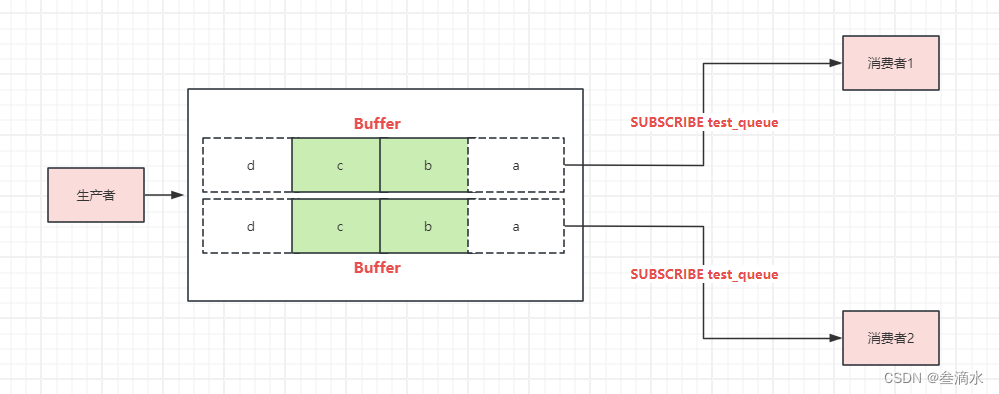
上文说,发布订阅模型没有基于任何数据类似,因此,这个操作不会写入RDB和AOF中(redis持久化机制)。另外,在消息堆积的时候,数据是通过Buffer缓冲区实现的。这个缓冲区的大小可以在redis中进行配置。如果超过了缓冲区配置的上限,此时,Redis 就会「强制」把这个消费者踢下线。
总的说,这个发布订阅模式相对比较脆弱,虽然解决了多消费者的问题,但是消息一致性较低,消息丢失概率较高(发布版本时重启了就可能丢消息),试用的场景较少。
三、相对成熟的Stream
Redis5.0 中增加了Stream消息队列相对成熟,解决了较多的问题。
- 支持消息
ACK反馈,在消息消费成功的时候,返回消费成功,才不会再次推送消息。 - 支持多消费者组。
- 消息堆积问题优化。
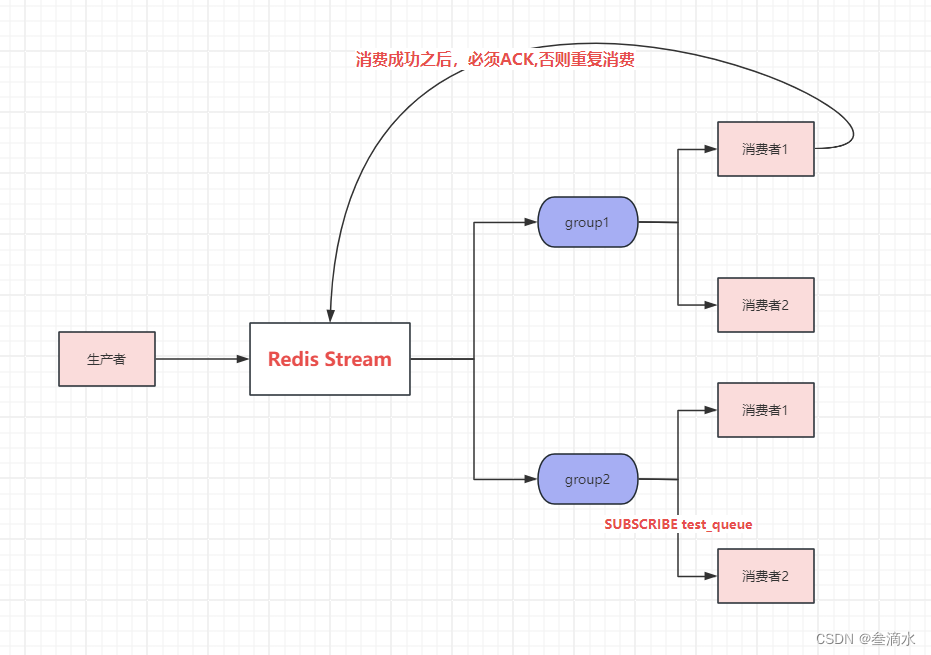
1.redis命令介绍
发布命令
shell
解释
#topic为 myStream1
# * 代表使用自动生成的ID作为消息的ID
# 接下来是多个 field value 组成的信息。
127.0.0.1:6379> XADD myStream1 * name zhangsan sex 20
"1717500637523-0"
127.0.0.1:6379> XADD myStream1 * name lisi sex 20
"1717500644429-0"
127.0.0.1:6379>消费命令
shell
# 消费myStream队列的10个数据,最后的0意思是从头开始消费。
127.0.0.1:6379> XREAD COUNT 10 STREAMS myStream1 0
1) 1) "myStream1"
2) 1) 1) "1717500637523-0"
2) 1) "name"
2) "zhangsan"
3) "sex"
4) "20"
2) 1) "1717500644429-0"
2) 1) "name"
2) "lisi"
3) "sex"
4) "20"
127.0.0.1:6379>2.多消费者组测试
shell
#创建一个消费者组为myGroup1并且指定消费位置。最后这个长串是信息的id
127.0.0.1:6379> XGROUP CREATE myStream1 myGroup1 1717500644429-0
OK
shell
#消费者组消费,消费者组为myGroup1 当前消费者id为consumer1 拉取10个信息 注意最后这个 '>'
127.0.0.1:6379> XREADGROUP GROUP myGroup1 consumer1 COUNT 10 STREAMS myStream1 >
1) 1) "myStream1"
2) 1) 1) "1717501299234-0"
2) 1) "name"
2) "lisi"
3) "sex"
4) "20"
127.0.0.1:6379>验证ACK机制
myGroup1消费者组拉取一次之后将所有的消息拉取回来- 因为没有进行消息反馈
ACK。所以再次拉取的时候,还是将全量的消息拉取回来。 - 执行一次
ACK命令之后,再次拉取消息,发现少了一条消息。 - 再次执行
ACK命令后,拉取不到消息了。
shell
127.0.0.1:6379> XREADGROUP GROUP myGroup1 consumer1 COUNT 10 STREAMS myStream1 0
1) 1) "myStream1"
2) 1) 1) "1717501299234-0"
2) 1) "name"
2) "lisi"
3) "sex"
4) "20"
2) 1) "1717502213457-0"
2) 1) "name"
2) "lisi"
3) "sex"
4) "20"
127.0.0.1:6379> XREADGROUP GROUP myGroup1 consumer1 COUNT 10 STREAMS myStream1 0
1) 1) "myStream1"
2) 1) 1) "1717501299234-0"
2) 1) "name"
2) "lisi"
3) "sex"
4) "20"
2) 1) "1717502213457-0"
2) 1) "name"
2) "lisi"
3) "sex"
4) "20"
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379> XACK myStream1 myGroup1 1717502213457-0
(integer) 1
127.0.0.1:6379> XREADGROUP GROUP myGroup1 consumer1 COUNT 10 STREAMS myStream1 0
1) 1) "myStream1"
2) 1) 1) "1717501299234-0"
2) 1) "name"
2) "lisi"
3) "sex"
4) "20"
127.0.0.1:6379> XACK myStream1 myGroup1 1717501299234-0
(integer) 1
127.0.0.1:6379> XREADGROUP GROUP myGroup1 consumer1 COUNT 10 STREAMS myStream1 0
1) 1) "myStream1"
2) (empty list or set)
127.0.0.1:6379>3.Stream会持久化吗?
会,不管是RDB 还是AOF都会写入。所以不用担心宕机的问题。
4.消息堆积如何解决?
既然会将Stream会进行持久化,那么必然消息也会保存在内存中,但是为了内存爆炸,Stream可以在XADD命令的时候,可以通过MAXLEN命令指定消息的最大长度,在超过最大长度的时候,旧消息会被删除,只保留固定长度的新消息。这样看来,消息堆积的问题只是进行了优化,并没有完美的解决。
总结
到此,获取对于redis消息队列的历史有了一定的了解,redis作为运行在内存的数据库而言,这个功能已经是很不错了,或许你的场景足够简单,消息的数量不多,并且对于消息的丢失不是特别的敏感的话,redis的Stream消息队列也是一个不错的选择。