引言
在数据科学的学习过程中,数据获取与数据可视化是两项重要的技能。本文将展示如何通过Python爬取豆瓣电影Top250的电影数据,并将这些数据存储到数据库中,随后进行数据分析和可视化展示。这个项目涵盖了从数据抓取、存储到数据可视化的整个过程,帮助大家理解数据科学项目的全流程。

环境配置与准备工作
在开始之前,我们需要确保安装了一些必要的库:
- urllib:用于发送HTTP请求和获取网页数据
- BeautifulSoup:用于解析HTML数据
- pymysql:用于连接和操作MySQL数据库
- time 和 random:用于添加延迟,防止被目标网站屏蔽
- pandas:用于数据操作和分析
- matplotlib 和 seaborn:用于数据可视化
数据爬取
我们将通过Python脚本爬取豆瓣电影Top250的数据。豆瓣Top250电影的页面按25部电影分页展示,我们将遍历这些页面获取电影信息。以下是爬取电影数据的伪代码描述:
- 设置数据库连接配置
- 定义豆瓣电影URL模板
- 创建函数 get_movie_data(start) 用于爬取指定页面的数据
a. 构造请求URL并发送请求
b. 解析返回的HTML数据
c. 提取电影的标题、评分、URL、描述和评论数量等信息 - 创建函数 save_to_db(movies) 用于将电影数据保存到数据库
- 遍历所有页面,获取电影数据并保存到数据库
- 关闭数据库连接
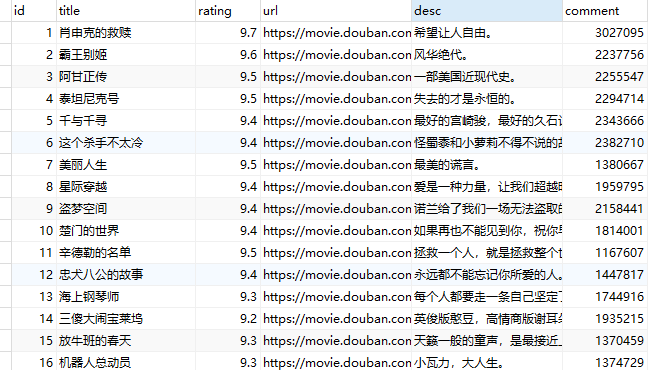
数据分析与可视化
完成数据爬取后,我们将数据从数据库中读取出来,并进行分析和可视化展示。
做出以下图表用来分析:
电影评分分布图:显示了电影评分的分布情况,评分主要集中在8.0到9.0之间。
评分与评论数量关系图:展示了评分与评论数量之间的关系,评论数量较多的电影评分也较高。
电影评分箱线图:展示了电影评分的箱线图,可以看出大部分电影的评分都很高,几乎没有低评分的电影。
热门电影前十排名:展示了评分最高的前十部电影。
评论数量分布图:显示了评论数量的分布情况,大部分电影的评论数量集中在几千到几万之间。
评分与评论数量双轴图:展示了每部电影的评分和评论数量的关系,方便对比。结果展示
通过这个项目,我们从豆瓣电影网站爬取了Top250的电影数据,并对这些数据进行了可视化展示。我们可以看到,豆瓣电影Top250的评分普遍较高,评分与评论数量之间存在一定的正相关关系。这种数据分析和可视化方法不仅可以应用于电影数据,还可以扩展到其他领域的数据分析中。希望这篇文章对大家有所帮助!
源码
