在 Java 开发中,处理 HTML 解析、数据爬取的需求十分常见,而JSoup正是一款为解决这类问题而生的优秀 Java 库。它以简洁的 API、类似 DOM 和 jQuery 的操作方式,让 HTML 解析、数据提取变得轻松高效,同时还具备 XSS 防护等实用功能,成为 Java 开发者处理 HTML 的首选工具之一。本文将从 JSoup 核心特性、核心类、基础使用方法出发,结合实际案例讲解其应用,最后附上实战作业要求,帮助大家快速掌握 JSoup 的使用。
一、JSoup 核心特性
JSoup 作为专注于 HTML 处理的 Java 库,功能覆盖了 HTML 抓取、解析、操作、数据提取及安全防护等多个方面,核心特性如下:
- 多源 HTML 抓取:支持从 URL、本地文件、字符串中获取并解析 HTML 内容,适配不同的数据源场景;
- 友好的操作 API:提供类似 DOM 和 jQuery 的操作方式,降低开发者的学习和使用成本;
- 强大的元素定位:支持 CSS 选择器定位 HTML 元素,精准找到目标数据所在位置;
- 灵活的 HTML 操作:可对 HTML 元素进行增删改查,满足自定义处理 HTML 的需求;
- 实用的安全防护:内置 XSS 防护机制,有效避免恶意 HTML 代码带来的安全风险;
- 轻量易用:无复杂的依赖,集成到 Java 项目中简单便捷。
二、JSoup 核心类
使用 JSoup 进行开发,核心围绕以下几个关键类展开,掌握这些类的作用,就能搭建起 JSoup 开发的基础框架:
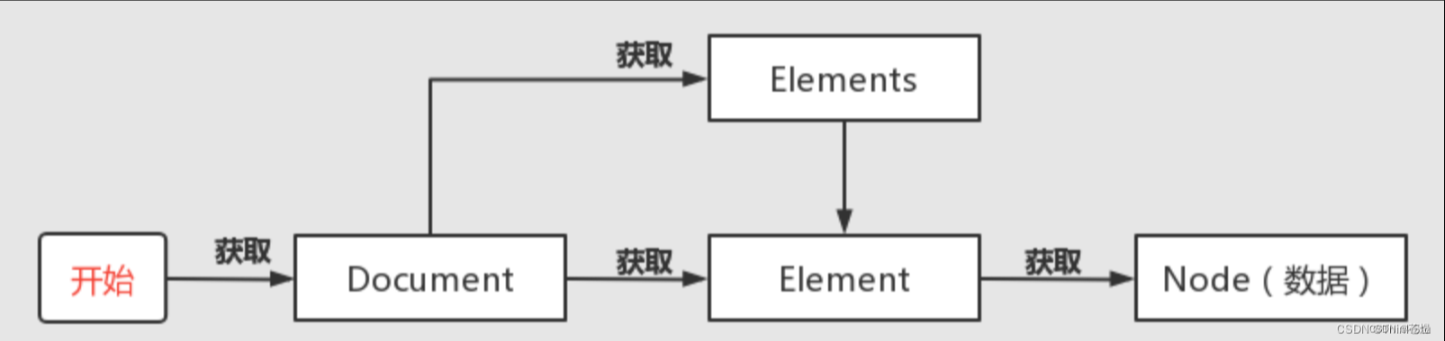
- Document:代表整个 HTML 文档,是解析 HTML 后的根节点,所有的元素操作都基于 Document 对象展开;
- Element :代表 HTML 中的单个元素,如
<div>、<a>、<p>等,可通过该类获取元素的属性、文本内容等; - Elements:是 Element 的集合类,用于存储多个匹配的 HTML 元素,支持批量操作;
- Node:HTML 节点的基础类,Element 等类均继承自该类,定义了节点的通用属性和方法。
三、JSoup 基础使用步骤
JSoup 的使用流程遵循获取文档→定位元素→提取数据的核心逻辑,步骤清晰且易于上手,关键操作如下:
1. 获取 HTML 文档
通过 JSoup 的connect()方法传入目标 URL,即可建立连接并获取 Document 对象。为了模拟浏览器访问,避免被目标网站反爬,可通过链式调用设置请求头(如 User-Agent、Referer 等)。
// 示例:获取网页的Document对象
Document doc = Jsoup.connect("https://www.example.com")
.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
.get();除此之外,也可通过Jsoup.parse(File file, String charsetName)解析本地 HTML 文件,或通过Jsoup.parse(String html)解析 HTML 字符串。
2. 定位目标元素
借助select()方法传入 CSS 选择器,即可定位到单个或多个 HTML 元素,返回结果为 Element 或 Elements 对象。CSS 选择器的语法与 jQuery 一致,如div.classname、#id、a[href]等,精准匹配目标元素。
// 示例:通过CSS选择器定位元素
Elements items = doc.select("div.movie-item"); // 定位class为movie-item的div元素
Element title = doc.selectFirst("h1#title"); // 定位id为title的第一个h1元素3. 提取数据
获取到 Element/Elements 对象后,通过attr()方法获取元素的属性值(如 href、src、class 等),通过text()方法获取元素的文本内容,完成数据提取的核心操作。
// 示例:提取元素的属性和文本
String href = title.select("a").attr("href"); // 获取a标签的href属性
String text = items.get(0).text(); // 获取第一个元素的文本内容四、定位选择元素
1. 查找元素 - 下列方法返回的是 Element 或 Elements
getElementById(String id): 通过 id 来查找元素getElementsByTag(String tag): 通过标签来查找元素getElementsByClass(String className): 通过类选择器来查找元素getElementsByAttribute(String key): 通过属性名称来查找元素,例如查找带有 href 元素的标签。siblingElements(): 获取兄弟元素。如果元素没有兄弟元素,则返回一个空列表。firstElementSibling(): 获取第一个兄弟元素。lastElementSibling(): 获取最后一个兄弟元素。nextElementSibling(): 获取下一个兄弟元素。previousElementSibling(): 获取上一个兄弟元素。parent(): 获取此节点的父节点。children(): 获取此节点的所有子节点。child(int index): 获取此节点的指定子节点。
2. select(String selector)- 下列方法返回的是 Element 或 Elements
tagname: 通过标签查找元素,例如通过 "a" 来查找<a>标签。#id: 通过 ID 查找元素,比如通过#logo查找<p id="logo">.class: 通过 class 名称查找元素,比如通过.title查找<p class="title">ns|tag: 通过标签在命名空间查找元素,比如使用fb|name来查找<fb:name>[attribute]: 利用属性查找元素,比如通过[href]查找<a href="...">[^attribute]: 利用属性名前缀来查找元素,比如:可以用[^data-]来查找带有 HTML5 dataset 属性的元素[attribute=value]: 利用属性值来查找元素,比如:[width=500][attribute^=value], [attribute$=value], [attribute*=value]: 利用匹配属性值开头、结尾或包含属性值来查找元素,比如通过[href^=/path/]来查找[attribute~=regex]: 利用属性值匹配正则表达式来查找元素,比如通过img[src~=(?i)\.(png|jpe?g)]来匹配所有的 png 或者 jpg、jpeg 格式的图片*: 通配符,匹配所有元素
五、获取数据
attr(String key): 获取单个属性值attributes(): 获取所有属性值attr(String key, String value): 设置属性值text(): 获取文本内容text(String value): 设置文本内容html(): 获取元素内的 HTML 内容html(String value): 设置元素内的 HTML 内容outerHtml(): 获取元素外 HTML 内容data(): 获取数据内容(例如:script 和 style 标签)id(): 获得 id 值className(): 获得第一个类选择器值classNames(): 获得所有的类选择器值tag(): 获取元素标签tagName(): 获取元素标签名
六、JSoup 实战案例
理论结合实践是掌握 JSoup 的关键,该库可广泛应用于各类网页数据爬取场景,经典的实战案例主要有以下两个:
1. 爬取豆瓣电影信息
豆瓣电影页面包含电影名称、评分、简介、海报等丰富信息,通过 JSoup 可轻松抓取:先通过connect()方法获取豆瓣电影榜单的 Document 对象,再通过 CSS 选择器定位电影条目元素,最后遍历元素,提取电影名称、评分、海报链接等数据,实现数据的批量采集。
2. 爬取智联招聘信息
智联招聘的职位列表页包含职位名称、公司名称、薪资、工作地点、招聘要求等信息,利用 JSoup 的 URL 连接功能获取页面文档,通过 CSS 选择器定位职位卡片元素,再通过attr()和text()方法提取各字段数据,可快速实现招聘信息的爬取与整理。
七、实战作业:爬取 2024 中国大学排名
为了巩固 JSoup 的学习成果,结合实际应用场景,布置实战作业:使用 JSoup 爬取 2024 中国大学排名信息。
作业要求
从发布 2024 中国大学排名的正规网页中,通过 JSoup 实现数据爬取,至少提取大学排名、学校名称、综合得分三个核心字段,可根据能力拓展提取办学类型、所在省份、学科优势等附加信息;将爬取到的数据进行整理,可输出为控制台打印、本地文本文件 / Excel 文件等形式。
作业思路提示
- 确定目标爬取网址,分析网页的 HTML 结构,找到大学排名信息对应的 HTML 元素和 CSS 选择器;
- 新建 Java 项目,引入 JSoup 依赖(Maven/Gradle);
- 编写代码,通过
connect()方法获取网页 Document 对象,设置请求头模拟浏览器; - 用
select()方法定位排名条目元素,遍历 Elements 集合; - 提取每个条目中的排名、学校名称、综合得分等数据;
- 对提取的数据进行格式化处理并输出,处理可能出现的空值、异常情况。
八、总结
JSoup 凭借轻量、易用、功能强大的特点,成为 Java 开发中处理 HTML 的必备工具,无论是简单的 HTML 解析,还是复杂的网页数据爬取,都能高效完成。本文介绍的核心特性、核心类、基础步骤是使用 JSoup 的基础,而豆瓣电影、智联招聘的案例则为实际应用提供了参考,最后的 2024 中国大学排名爬取作业,更是检验学习成果的重要实践。
在实际开发中,使用 JSoup 爬取数据时,需遵守目标网站的robots.txt协议,控制爬取频率,避免对网站服务器造成压力,同时注意数据的合法使用,杜绝违规爬取和滥用数据的行为。掌握 JSoup 的使用,能为 Java 开发者在数据采集、HTML 处理等场景中提供高效的解决方案,提升开发效率。