目录
效果一览


基本介绍
高创新 | CEEMDAN-VMD-BiLSTM-Attention双重分解+双向长短期记忆神经网络+注意力机制多元时间序列预测
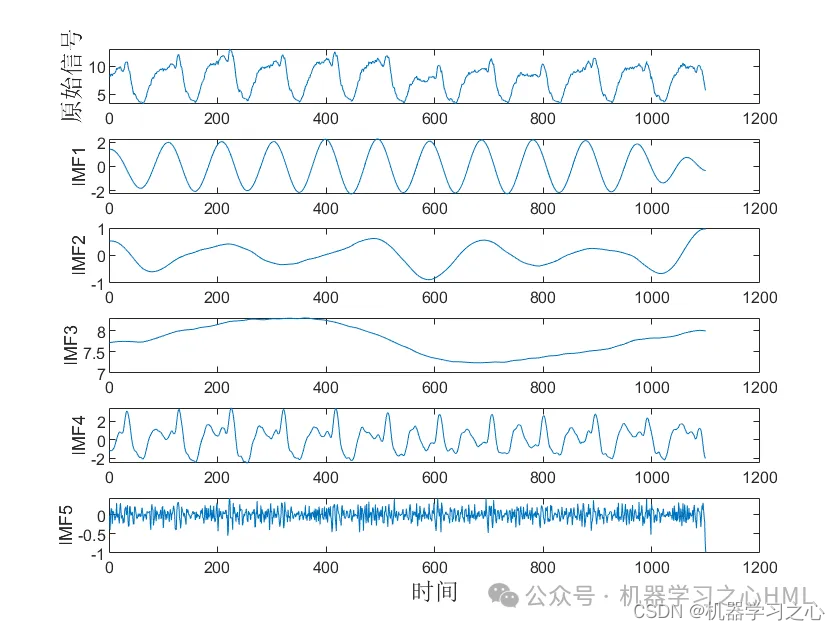
本文提出一种基于CEEMDAN 的二次分解方法,通过样本熵重构CEEMDAN 分解后的序列,复杂序列通过VMD 分解后,将各个分量分别通过BiLSTM-Attention模型预测,最终将预测结果整合。
模型设计
1.Matlab实现CEEMDAN-VMD-BiLSTM-Attention双重分解+双向长短期记忆神经网络+注意力机制多元时间序列预测(完整源码和数据)
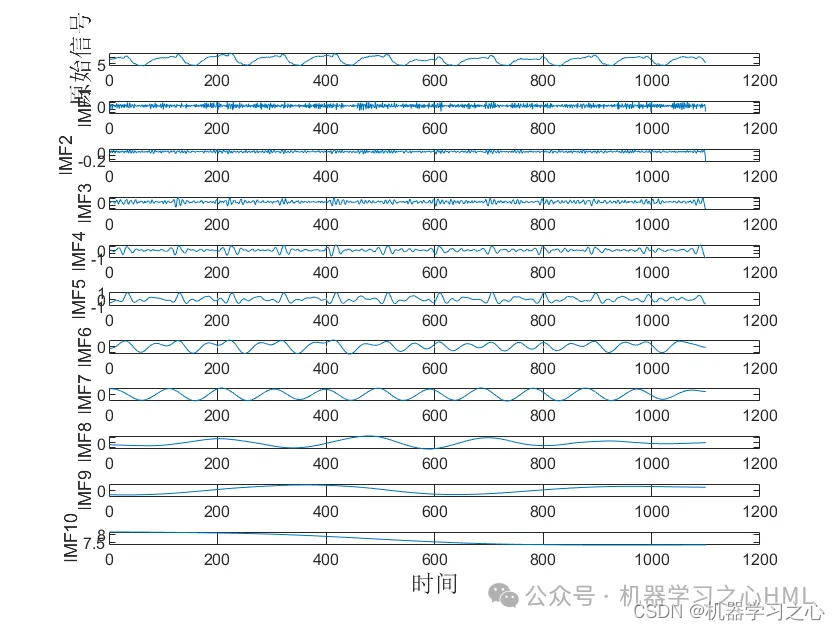
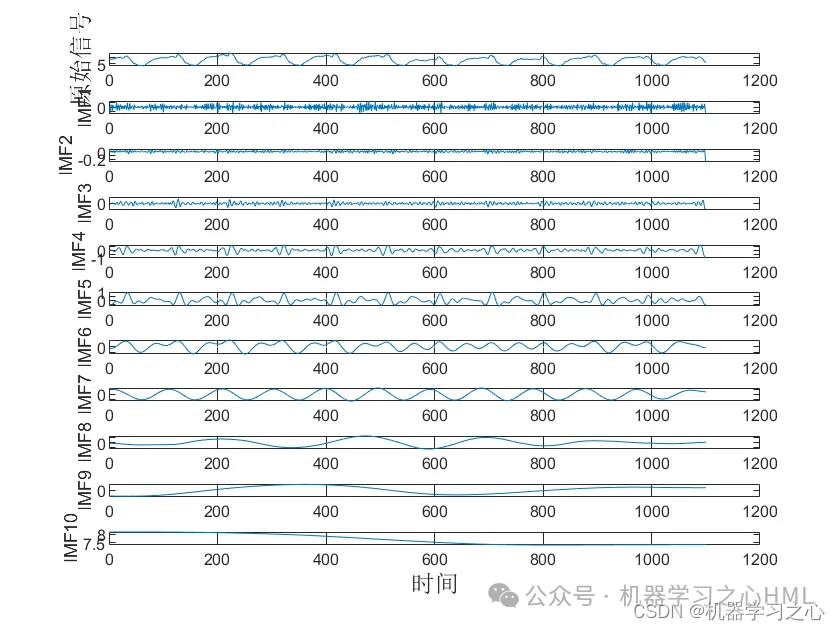
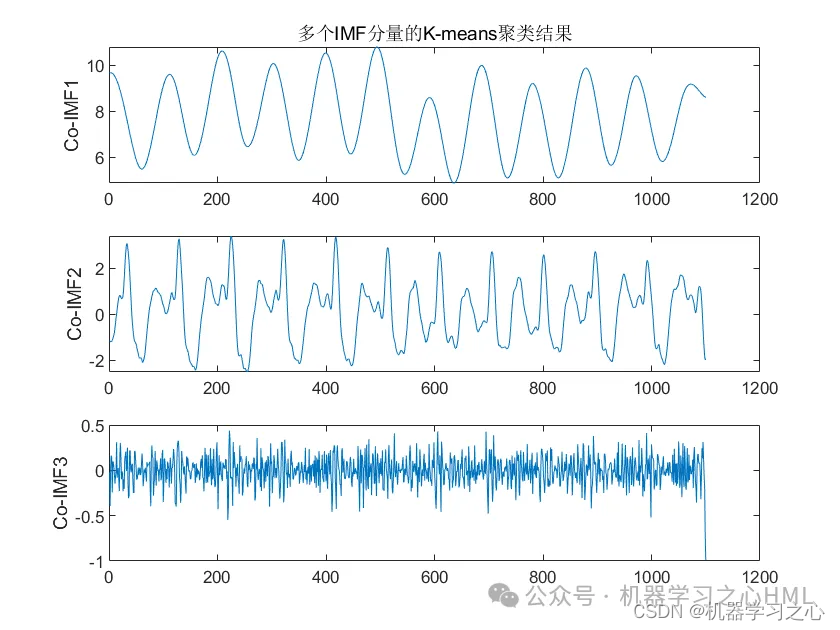
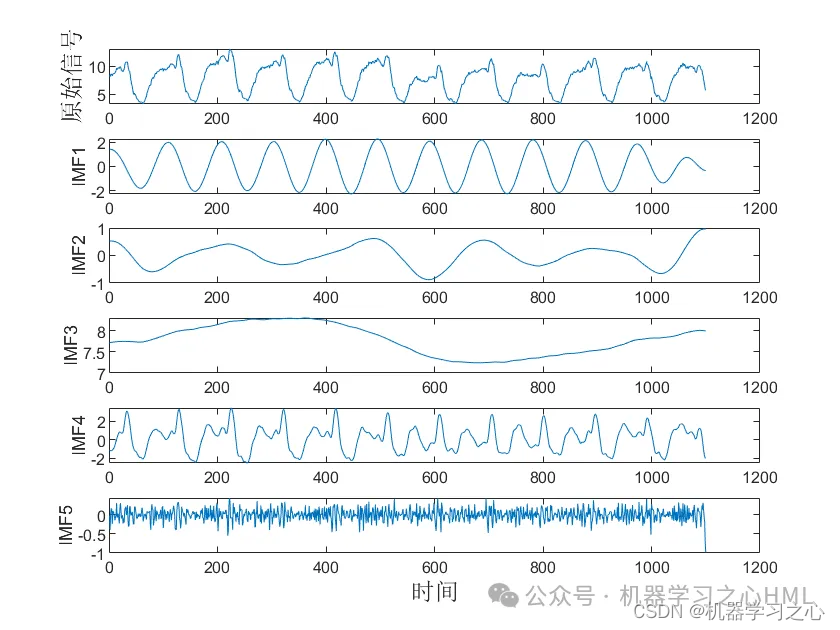
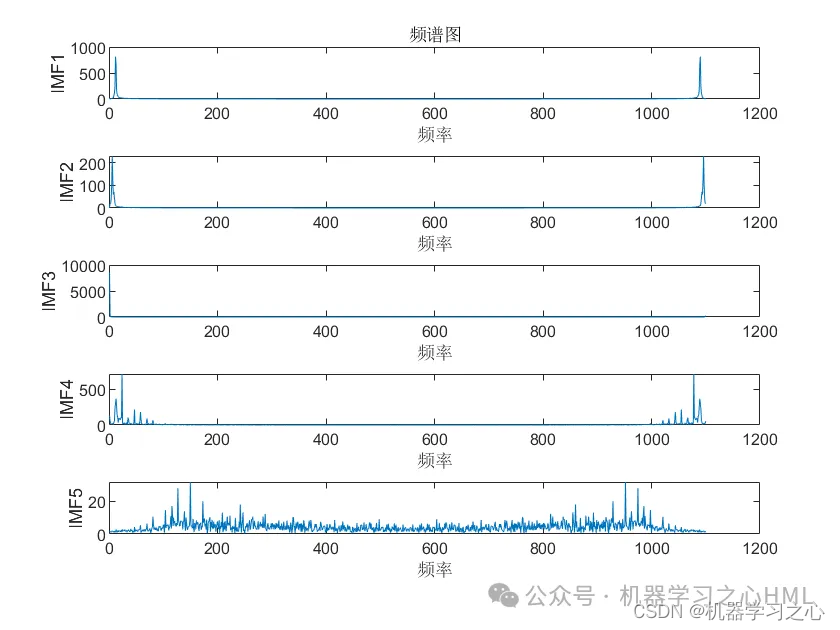
2.CEEMDAN分解,计算样本熵,根据样本熵进行kmeans聚类,调用VMD对高频分量二次分解, VMD分解的高频分量与前分量作为卷积双向长短期记忆神经网络注意力机制模型的目标输出分别预测后相加。
3.多变量单输出,考虑历史特征的影响!评价指标包括R2、MAE、RMSE、MAPE等。
4.算法新颖。CEEMDAN-VMD-BiLSTM-Attention模型处理数据,具有更高的准确率,能够跟踪数据的趋势以及变化。VMD 模型处理非线性、非平稳以及复杂的数据,表现得比EMD 系列更好,因此将重构的数据通过VMD 模型分解,提高了模型的准确度。
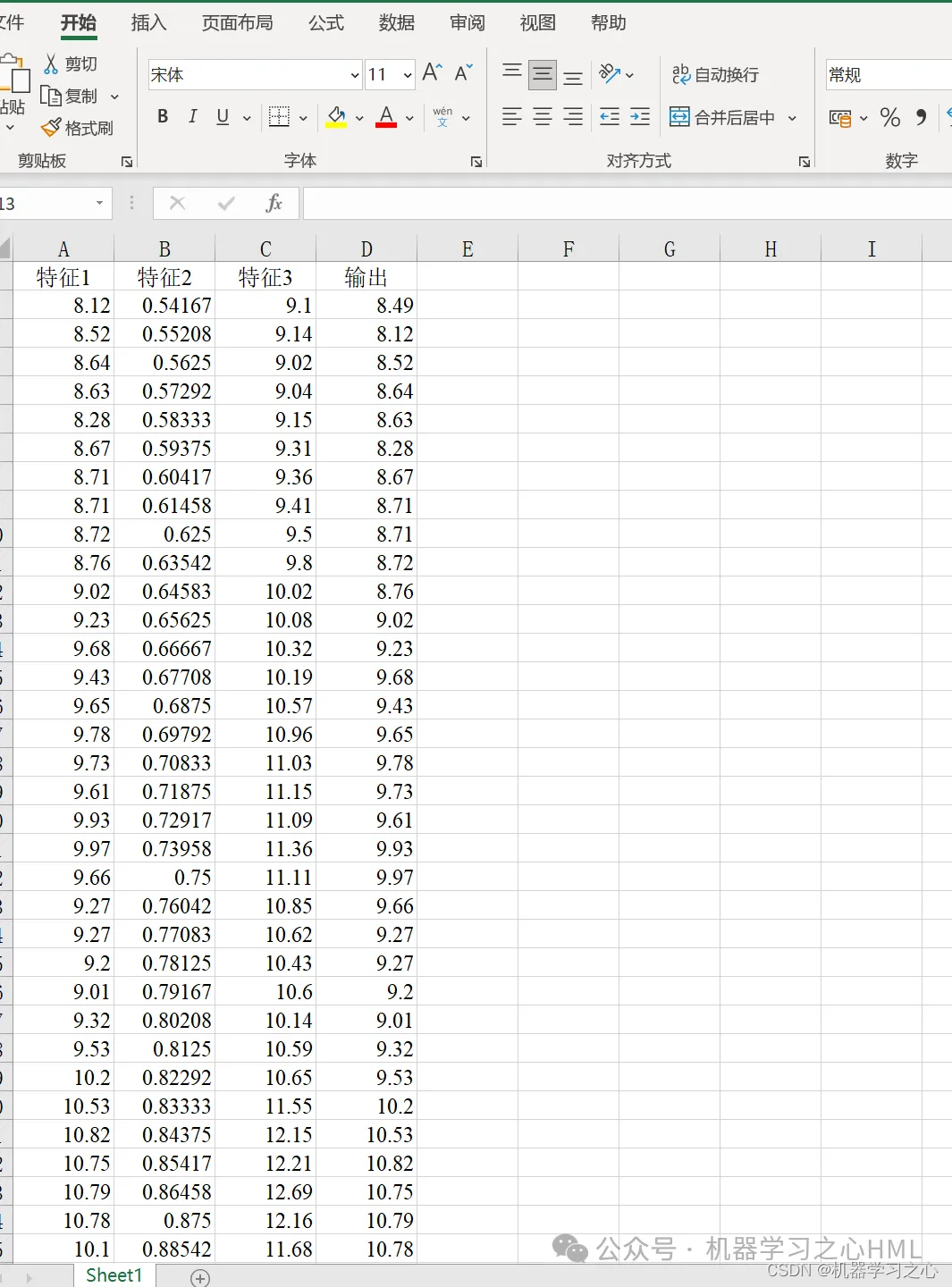
5.直接替换Excel数据即可用,注释清晰,适合新手小白,直接运行主文件一键出图。
6.代码特点:参数化编程、参数可方便更改、代码编程思路清晰、注释明细。
- 参考文献1

- 参考文献2

- 参考文献3

数据集
程序设计
- 完整程序私信博主回复CEEMDAN-VMD-BiLSTM-Attention双重分解+双向长短期记忆神经网络+注意力机制多元时间序列预测。
matlab
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[P_train, ps_input] = mapminmax(P_train, 0, 1);
P_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 数据平铺
P_train = double(reshape(P_train, f_, 1, 1, M));
P_test = double(reshape(P_test , f_, 1, 1, N));
t_train = t_train';
t_test = t_test' ;
%% 数据格式转换
for i = 1 : M
p_train{i, 1} = P_train(:, :, 1, i);
end
for i = 1 : N
p_test{i, 1} = P_test( :, :, 1, i);
end
%% 参数设置
options = trainingOptions('adam', ... % Adam 梯度下降算法
'MaxEpochs', 100, ... % 最大训练次数
'InitialLearnRate', 0.01, ... % 初始学习率为0.01
'LearnRateSchedule', 'piecewise', ... % 学习率下降
'LearnRateDropFactor', 0.1, ... % 学习率下降因子 0.1
'LearnRateDropPeriod', 70, ... % 经过训练后 学习率为 0.01*0.1
'Shuffle', 'every-epoch', ... % 每次训练打乱数据集
'Verbose', 1);
figure
subplot(2,1,1)
plot(T_train,'k--','LineWidth',1.5);
hold on
plot(T_sim_a','r-','LineWidth',1.5)
legend('真实值','预测值')
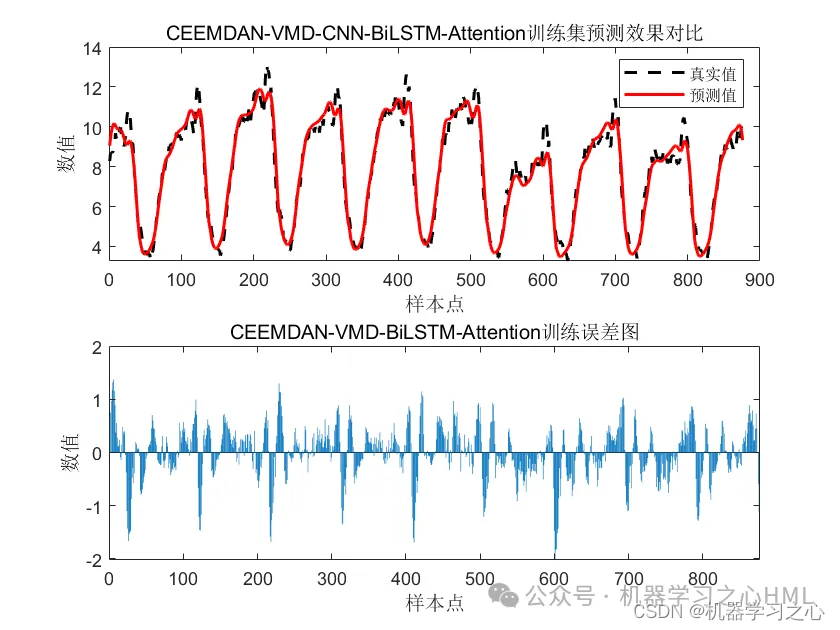
title('CEEMDAN-VMD-CNN-BiLSTM-Attention训练集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_a'-T_train)
title('CEEMDAN-VMD-BiLSTM-Attention训练误差图')
xlabel('样本点')
ylabel('数值')
disp('............测试集误差指标............')
[mae2,rmse2,mape2,error2]=calc_error(T_test,T_sim_b');
fprintf('\n')
figure
subplot(2,1,1)
plot(T_test,'k--','LineWidth',1.5);
hold on
plot(T_sim_b','b-','LineWidth',1.5)
legend('真实值','预测值')
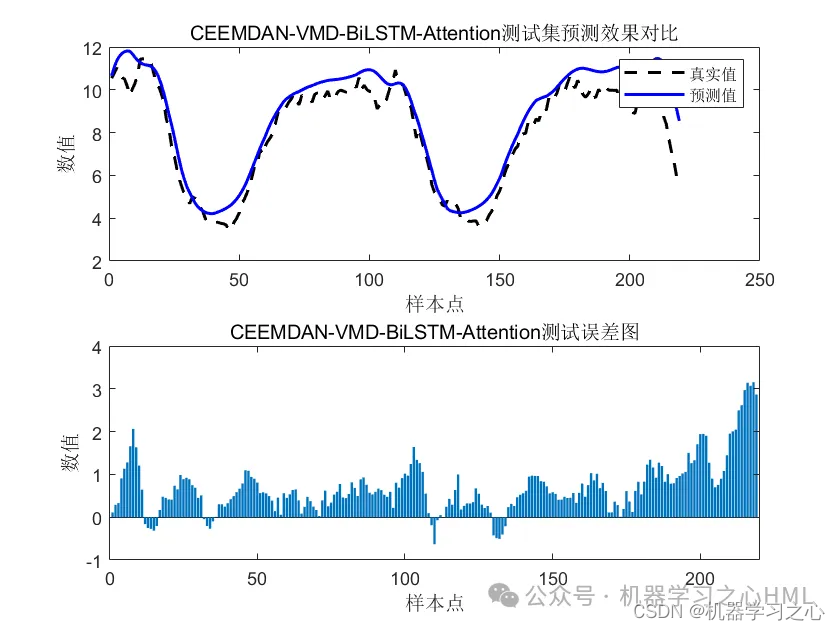
title('CEEMDAN-VMD-BiLSTM-Attention测试集预测效果对比')
xlabel('样本点')
ylabel('数值')
subplot(2,1,2)
bar(T_sim_b'-T_test)
title('CEEMDAN-VMD-BiLSTM-Attention测试误差图')
xlabel('样本点')
ylabel('数值')参考资料
1 https://hmlhml.blog.csdn.net/article/details/135536086?spm=1001.2014.3001.5502
2 https://hmlhml.blog.csdn.net/article/details/137166860?spm=1001.2014.3001.5502