大家好!今天我们来聊聊计算机视觉(CV)领域里一个"让模型更聪明"的核心技术------注意力机制。如果你刚接触图像处理,或者想搞懂为什么有些模型(比如ResNet+注意力)效果比普通CNN好,这篇入门博客会带你一步步理清思路,最后还会附上简单的代码实现,帮你快速上手。
一、先搞懂:为什么需要注意力机制?
在聊技术之前,我们先从"人"的角度思考------当你看一张图片时,你会把所有像素都同等对待吗?你会自然而然地把目光聚焦在"猫"身上,而忽略掉背景里的沙发、茶几这些无关细节。这种"主动聚焦关键区域"的能力,就是人类视觉的注意力。
但传统的CNN(卷积神经网络)做不到这一点!传统CNN对图像的所有区域、所有特征通道都"一视同仁":比如用3x3卷积扫过图片时,每个像素的权重都一样,通道之间也没有优先级。这就导致两个问题:
- 冗余信息干扰:背景的无用特征会"稀释"主体特征,比如检测猫时,沙发的纹理可能会让模型判断失误;
- 计算效率低:对所有区域都精细处理,浪费算力在不重要的地方。
而图像处理中的注意力机制,就是给模型赋予"类似人类的聚焦能力"------让模型自动学习"哪些区域/通道更重要",然后给这些重要部分分配更高的"权重",让模型优先学习它们;同时降低无用部分的权重,减少干扰。
二、注意力机制的核心思想:"权重分配"
简单来说,注意力机制的本质是动态权重分配:
- 对于输入的图像特征图(比如CNN输出的Feature Map),模型会生成一个和特征图维度匹配的"注意力权重图";
- 权重图中,数值高的位置/通道 代表"重要信息",数值低的位置/通道代表"冗余信息";
- 把原特征图和注意力权重图做"逐元素相乘",就能得到"被注意力增强后的特征图"------重要信息被放大,无用信息被抑制。
举个直观的例子:
原特征图中,猫的区域像素值是5,5,5,背景是1,1,1;
注意力权重图中,猫的区域权重是0.9,0.9,0.9,背景是0.1,0.1,0.1;
相乘后:猫的区域变成4.5,4.5,4.5(更突出),背景变成0.1,0.1,0.1(被抑制)。
三、图像处理中注意力机制的3种常见类型
根据"关注的对象不同",注意力机制主要分为3类,入门阶段掌握这3类就够了:
1. 空间注意力(Spatial Attention):关注"哪里重要"
核心目标 :在图像的"空间维度"(比如宽度W、高度H)上,找出重要的区域(像素点)。
比如:在检测任务中,空间注意力会给"目标物体"(如猫、汽车)所在的像素区域更高权重,给背景区域更低权重。
原理简化 :
输入特征图的维度是 B, C, H, W(B=批量大小,C=通道数,H=高度,W=宽度);
空间注意力模块会对特征图做"通道维度的聚合"(比如全局平均池化/全局最大池化),把 B, C, H, W 变成 B, 1, H, W(通道数压缩到1,保留空间维度);
然后通过简单的卷积层学习权重,生成最终的空间注意力图 B, 1, H, W;
最后和原特征图逐元素相乘,得到"空间增强特征图"。
直观感受:空间注意力图看起来就像"热力图"------红色区域(高权重)是模型关注的重点,蓝色区域(低权重)是模型忽略的背景。
2. 通道注意力(Channel Attention):关注"哪些特征重要"
核心目标 :在图像的"通道维度"(C)上,找出重要的特征通道。
我们知道,CNN的不同通道对应不同的特征:比如有的通道负责提取"边缘",有的负责"颜色",有的负责"纹理"。通道注意力就是让模型判断:当前任务(如分类、分割)中,哪些通道的特征更有用。
原理简化 :
输入特征图 B, C, H, W;
通道注意力模块会对特征图做"空间维度的聚合"(比如全局平均池化,把每个通道的H×W像素变成1个值),得到 B, C, 1, 1(空间维度压缩到1,保留通道维度);
然后通过2个全连接层(先降维再升维)学习每个通道的权重,生成通道注意力权重 B, C, 1, 1;
最后和原特征图逐元素相乘,得到"通道增强特征图"。
例子:在"猫分类"任务中,负责提取"猫耳朵形状""猫毛纹理"的通道会被分配更高权重,而负责提取"背景天空颜色"的通道权重会很低。
3. 混合注意力(Hybrid Attention):空间+通道一起关注
核心目标 :同时考虑"空间维度"和"通道维度"的重要性,是前两种注意力的结合,效果通常更好。
比如:先通过通道注意力筛选出有用的特征通道,再通过空间注意力在这些通道上定位重要区域;或者反过来。
直观理解:就像人眼------先确定"要看什么特征"(比如先关注"是否有动物的轮廓",对应通道),再确定"这个特征在哪个位置"(比如轮廓在图片中间,对应空间)。
四、入门必学:2个经典注意力算法
理论讲完,我们来看两个最经典、最容易实现的注意力算法,也是面试和项目中最常用的:
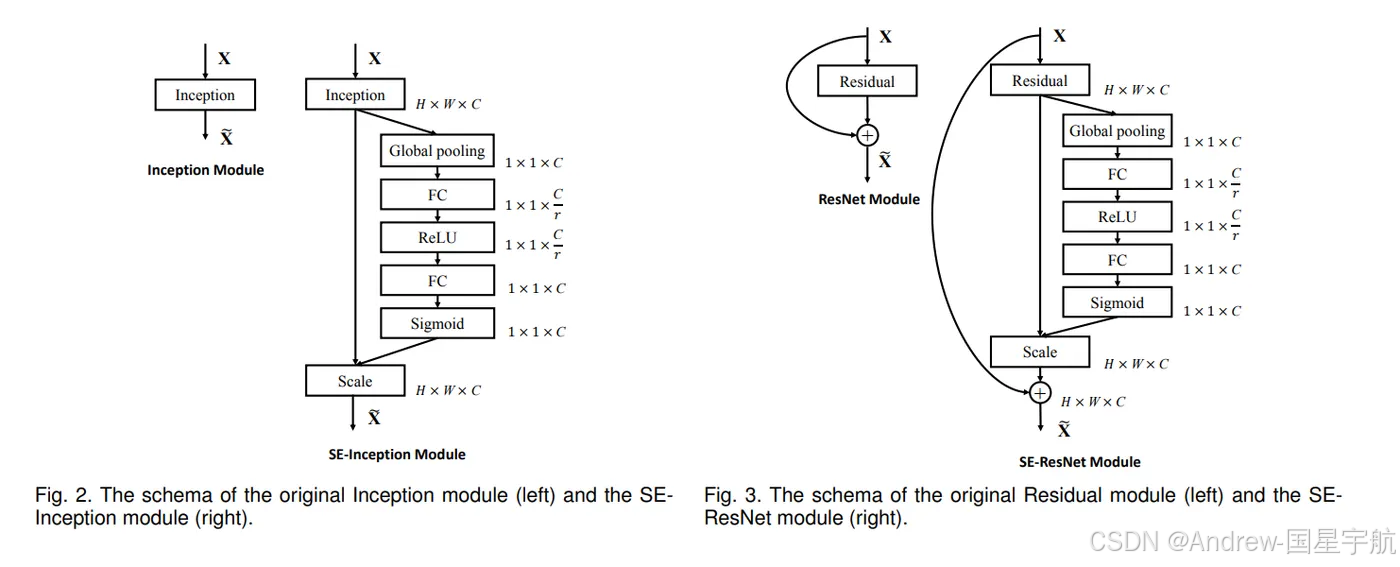
1. SENet(通道注意力代表):2017年ImageNet冠军
SENet(Squeeze-and-Excitation Networks)是第一个把通道注意力发扬光大的算法,结构非常简单,但效果提升很明显。它的核心只有3步:Squeeze(挤压)→ Excitation(激励)→ Rescale(重标定)。
SENet步骤详解:
-
Squeeze(挤压) :对每个通道的特征图做"全局平均池化"(GAP),把 H, W 大小的通道特征压缩成1个数值。
作用:聚合每个通道的全局空间信息,得到"通道的全局特征"(比如某个通道的平均值代表这个通道特征的整体强度)。
-
Excitation(激励):用2个全连接层(FC)对挤压后的特征做"降维→升维":
- 第一层FC:把通道数从C降到C/r(r是降维系数,通常取16,减少计算量);
- 激活函数:ReLU(增加非线性);
- 第二层FC:把通道数从C/r升回C;
- 激活函数:Sigmoid(把输出压缩到0~1,作为通道权重)。
作用:学习不同通道的重要性,生成通道权重。
-
Rescale(重标定) :把学习到的通道权重(B, C, 1, 1)和原特征图(B, C, H, W)逐元素相乘。
作用:增强重要通道的特征,抑制无用通道。
2. CBAM(混合注意力代表):简单高效的"通道+空间"结合
CBAM(Convolutional Block Attention Module)在SENet的基础上,增加了空间注意力模块,形成"通道注意力→空间注意力"的串联结构,实现了混合注意力。
CBAM步骤详解:
-
通道注意力模块 :和SENet类似,但增加了"全局最大池化"(GMP),并把GAP和GMP的结果拼接后输入全连接层(比SENet多了一种空间信息聚合方式,效果更好)。
输出:通道权重 B, C, 1, 1,和原特征图相乘得到"通道增强特征图"。
-
空间注意力模块 :对"通道增强特征图"做"通道维度的最大池化和平均池化",得到两个 B, 1, H, W 的特征图,拼接后通过1x1卷积压缩到1个通道,再用Sigmoid得到空间权重。
输出:空间权重 B, 1, H, W,和"通道增强特征图"相乘得到最终的"混合增强特征图"。
CBAM的优势:结构轻量(几乎不增加计算量),可以很容易地嵌入到任何CNN网络中(比如ResNet、VGG),提升模型性能。
五、实战:用PyTorch实现简单注意力模块
光说不练假把式,下面我们用PyTorch写两个简单的注意力模块(SENet和CBAM),代码注释非常详细,入门也能看懂!
1. SENet通道注意力模块实现
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class SEBlock(nn.Module):
def __init__(self, in_channels, reduction=16):
"""
Args:
in_channels: 输入特征图的通道数(比如ResNet块的输出通道数)
reduction: 降维系数,默认16(经验值,可调整)
"""
super(SEBlock, self).__init__()
# 1. Squeeze:全局平均池化(GAP),把[B, C, H, W]→[B, C, 1, 1]
self.global_avg_pool = nn.AdaptiveAvgPool2d(1)
# 2. Excitation:全连接层(降维→激活→升维→激活)
self.fc = nn.Sequential(
# 降维:C → C/reduction
nn.Linear(in_channels, in_channels // reduction, bias=False),
nn.ReLU(inplace=True),
# 升维:C/reduction → C
nn.Linear(in_channels // reduction, in_channels, bias=False),
nn.Sigmoid() # 输出0~1的通道权重
)
def forward(self, x):
# x: 输入特征图,形状[B, C, H, W]
b, c, _, _ = x.size() # 获取批量大小b和通道数c
# 步骤1:Squeeze(全局平均池化)
y = self.global_avg_pool(x) # [B, C, 1, 1]
y = y.view(b, c) # 展平成[B, C],适配全连接层
# 步骤2:Excitation(学习通道权重)
y = self.fc(y) # [B, C]
y = y.view(b, c, 1, 1) # 恢复形状[B, C, 1, 1],适配原特征图
# 步骤3:Rescale(逐元素相乘)
return x * y # 输出[B, C, H, W],通道增强后的特征图2. CBAM混合注意力模块实现
python
class CBAMBlock(nn.Module):
def __init__(self, in_channels, reduction=16, kernel_size=7):
"""
Args:
in_channels: 输入特征图通道数
reduction: 通道注意力的降维系数
kernel_size: 空间注意力的卷积核大小(奇数,保证中心对称)
"""
super(CBAMBlock, self).__init__()
# ---------------------- 通道注意力模块 ----------------------
self.channel_attention = nn.Sequential(
# 空间聚合:GAP + GMP(比SENet多了GMP)
nn.AdaptiveAvgPool2d(1), # GAP:[B,C,H,W]→[B,C,1,1]
nn.Conv2d(in_channels, in_channels//reduction, 1, bias=False), # 降维
nn.ReLU(inplace=True),
nn.Conv2d(in_channels//reduction, in_channels, 1, bias=False), # 升维
# 另一个分支:GMP
nn.AdaptiveMaxPool2d(1),
nn.Conv2d(in_channels, in_channels//reduction, 1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels//reduction, in_channels, 1, bias=False),
# 两个分支相加后激活
nn.Add(),
nn.Sigmoid()
)
# ---------------------- 空间注意力模块 ----------------------
self.spatial_attention = nn.Sequential(
# 通道聚合:MaxPool + AvgPool(沿通道维度)
# 先在通道维度取max和avg,得到两个[B,1,H,W]的特征图
lambda x: torch.cat([torch.max(x, dim=1, keepdim=True)[0],
torch.mean(x, dim=1, keepdim=True)], dim=1),
# 1x1卷积压缩通道数(从2→1)
nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False),
nn.Sigmoid() # 输出0~1的空间权重
)
def forward(self, x):
# 先通道注意力,再空间注意力(顺序可调整,通常先通道)
x = x * self.channel_attention(x) # 通道增强
x = x * self.spatial_attention(x) # 空间增强
return x # 输出混合增强后的特征图如何使用这些模块?
很简单!把注意力模块嵌入到CNN的卷积块中即可。比如在ResNet的BasicBlock里:
python
# 以ResNet的BasicBlock为例,嵌入CBAM
class ResNetBasicBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, 3, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(out_channels, out_channels, 3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
self.cbam = CBAMBlock(out_channels) # 嵌入CBAM注意力
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.cbam(out) # 应用注意力
out += residual # 残差连接
out = self.relu(out)
return out六、注意力机制的应用场景
注意力机制不是"花架子",而是在很多CV任务中都能显著提升效果,常见场景包括:
- 目标检测:比如Faster R-CNN、YOLO中加入注意力,让模型更精准地定位目标,减少背景干扰;
- 图像分割:比如医学影像分割(分割肿瘤、器官),注意力能让模型聚焦病变区域,避免分割错误;
- 图像修复:比如修复老照片的划痕,注意力能让模型参考周围相似区域的像素,修复更自然;
- 超分辨率重建:把低清图放大成高清图,注意力能让模型重点优化细节区域(如文字、边缘);
- 人脸识别:注意力能聚焦面部关键特征(如眼睛、鼻子),提高识别准确率。
七、总结与展望
看到这里,相信你已经对图像处理中的注意力机制有了入门级的理解:
- 核心:动态分配权重,让模型"聚焦重要信息,忽略冗余信息";
- 分类:空间注意力(哪里重要)、通道注意力(哪些特征重要)、混合注意力(两者结合);
- 经典算法:SENet(通道)、CBAM(混合),结构简单,易实现;
- 价值:轻量高效,能快速提升现有CNN模型的性能。
对于入门者来说,下一步可以尝试:
- 用上面的代码实现一个"ResNet+CBAM"模型,在CIFAR-10数据集上训练,对比普通ResNet的效果;
- 调整注意力模块的参数(如降维系数reduction、卷积核大小),观察对模型性能的影响;
- 了解更复杂的注意力算法(如Transformer中的自注意力、Non-Local注意力),但入门阶段先掌握SENet和CBAM就够了。
如果有疑问,欢迎在评论区留言讨论!觉得有用的话,别忘了点赞收藏~