PyTorch实战(14)------图注意力网络(Graph Attention Network,GAT)
0. 前言
我们已经通过使用图卷积网络 (Graph Convolutional Network, GCN) 模型在节点分类任务上具备了超越了基线多层感知机 (Multilayer Perceptron, MLP) 模型的性能。在本节中,我们将通过将 GCN 模型替换为图注意力网络 (Graph Attention Network, GAT) 模型来进一步提高分类准确率,核心改进在于将邻域节点信息平均聚合机制替换为注意力机制。接下来,将基于 GCN 的解决方案重构为基于 GAT 的解决方案。
1. 图注意力网络
GCN 采用平均值聚合机制来汇聚相邻节点的特征信息,但这种方式存在固有缺陷------它默认所有邻居节点的重要性相同,而实际情况未必如此。例如,假设节点 X 和 Y 的初始特征值完全相同,且邻居集合也一致,GCN 模型会将它们归为同一类别或簇。但这不一定是正确的。为了捕捉图中此类细微差异,我们可以用注意力机制替代简单的平均值聚合,这正是图注意力网络 (Graph Attention Network, GAT) 的核心思想。
我们已经在文本数据中学习过注意力机制,在文本数据的上下文中,其本质是为句子中的不同单词分配差异化的重要性权重,从而聚焦关键部分进行后续处理。在 GAT 中,注意力机制允许模型在分类节点类型时,为不同邻居节点分配不同的权重,从而构建更复杂、更强大的模型。通过注意力机制,我们可以为每个邻居节点学习注意力系数,这些系数为模型增加了可训练参数。下图展示了 GAT 与 GCN 在聚合邻居节点特征时的对比。
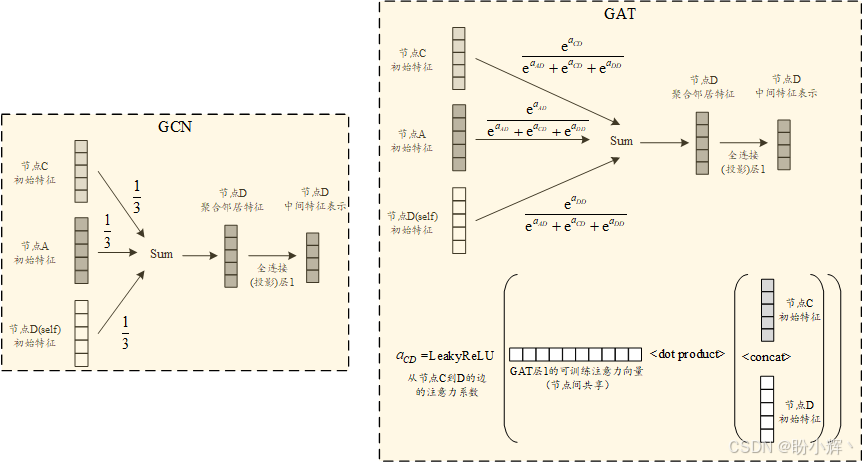
如上图所示,我们引入了一组新的可训练参数------注意力向量。该向量的长度是单个节点特征向量的两倍,因为它需要与"当前节点特征和邻居节点特征拼接结果"进行点积运算。在给定网络层中,这个可学习的注意力向量会在所有<节点,邻居>对之间共享。这组额外的可训练参数使 GAT 能够针对不同特征维度和不同邻居学习差异化权重。
每个<节点,邻居>对的注意力系数计算过程如下:先将节点特征与邻居特征拼接,再与注意力向量做点积,最后通过 Leaky ReLU 激活函数。邻居节点的最终权重通过对注意力系数进行 softmax 归一化得到。这个 softmax 函数不仅增加了非线性,还确保了所有权重之和为 1。通过这种方式,GAT 显著增强了利用可训练注意力参数从邻居节点提取信息的机制。
2. 模型构建
(1) 首先,定义 GAT 模型架构及其前向传播函数:
python
class GAT(torch.nn.Module):
def __init__(self, hidden_channels, heads):
super().__init__()
self.conv1 = GATConv(dataset.num_features, hidden_channels, heads)
self.conv2 = GATConv(hidden_channels * heads, dataset.num_classes, heads=1)
def forward(self, x, edge_index):
x = F.dropout(x, p=0.6, training=self.training)
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, p=0.6, training=self.training)
x = self.conv2(x, edge_index)
return x
model = GAT(hidden_channels=16, heads=8)
print(model)输出结果如下所示:
shell
GAT(
(conv1): GATConv(3703, 16, heads=8)
(conv2): GATConv(128, 6, heads=1)
)该模型的一个关键特性在于每个 GATConv 层的注意力头数量。在第一层中,我们设置了 8 个注意力头,这意味着将通过 8 个并行且可独立训练的注意力系数,进行 8 个并行的邻居节点特征聚合,如下图所示。
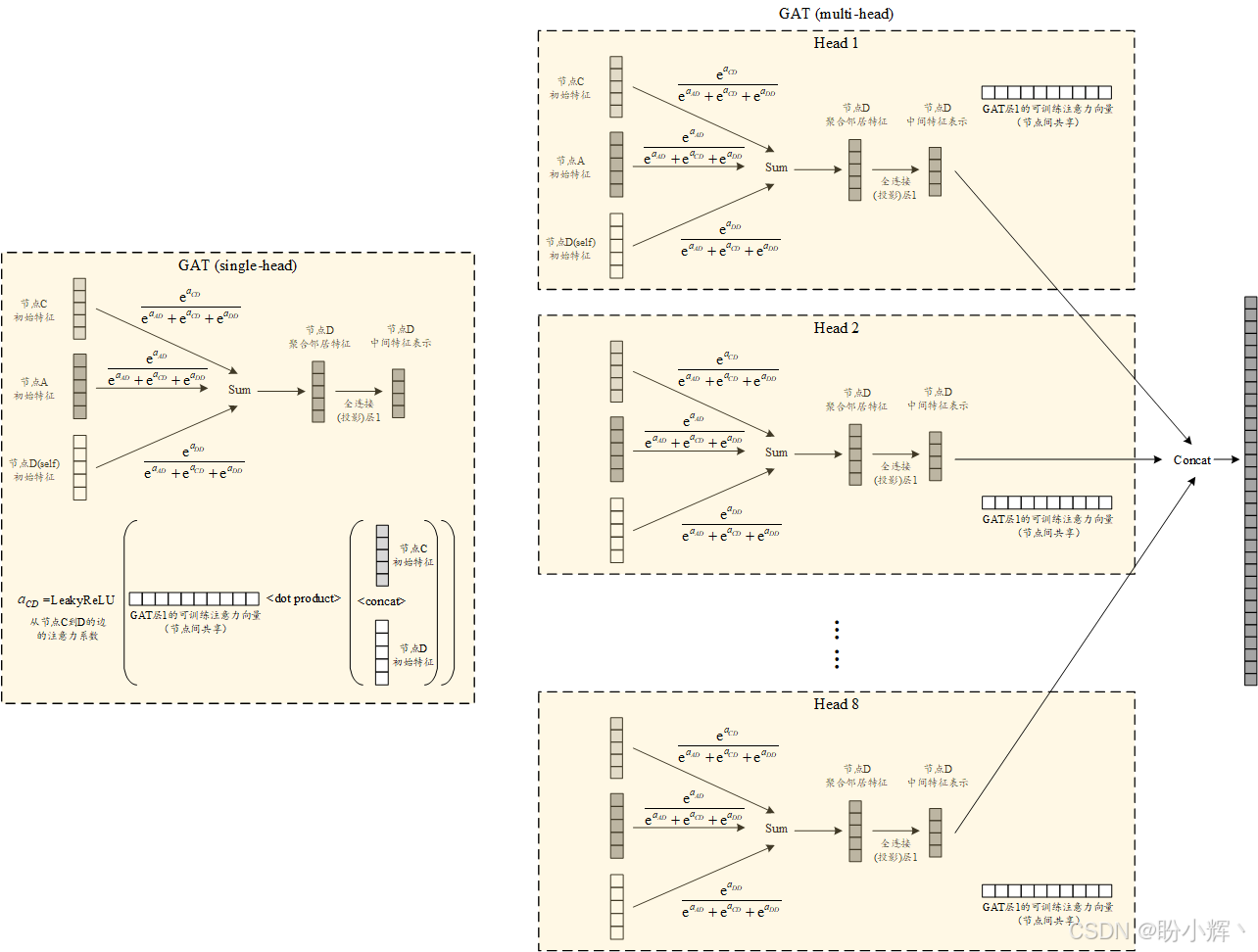
经过第一层 GAT 处理后,这 8 个注意力头生成的特征向量(每个维度为 16)将被拼接起来,最终输出 128 维特征。第二层 GATConv 仅包含 1 个注意力头,直接输出对应 6 个节点类别的结果。在该模型的前向传播过程中,我们采用了多重 dropout 策略来应对模型复杂度提升可能导致的过拟合问题(特别是多注意力头机制使得图信息传递过程更为精细)。
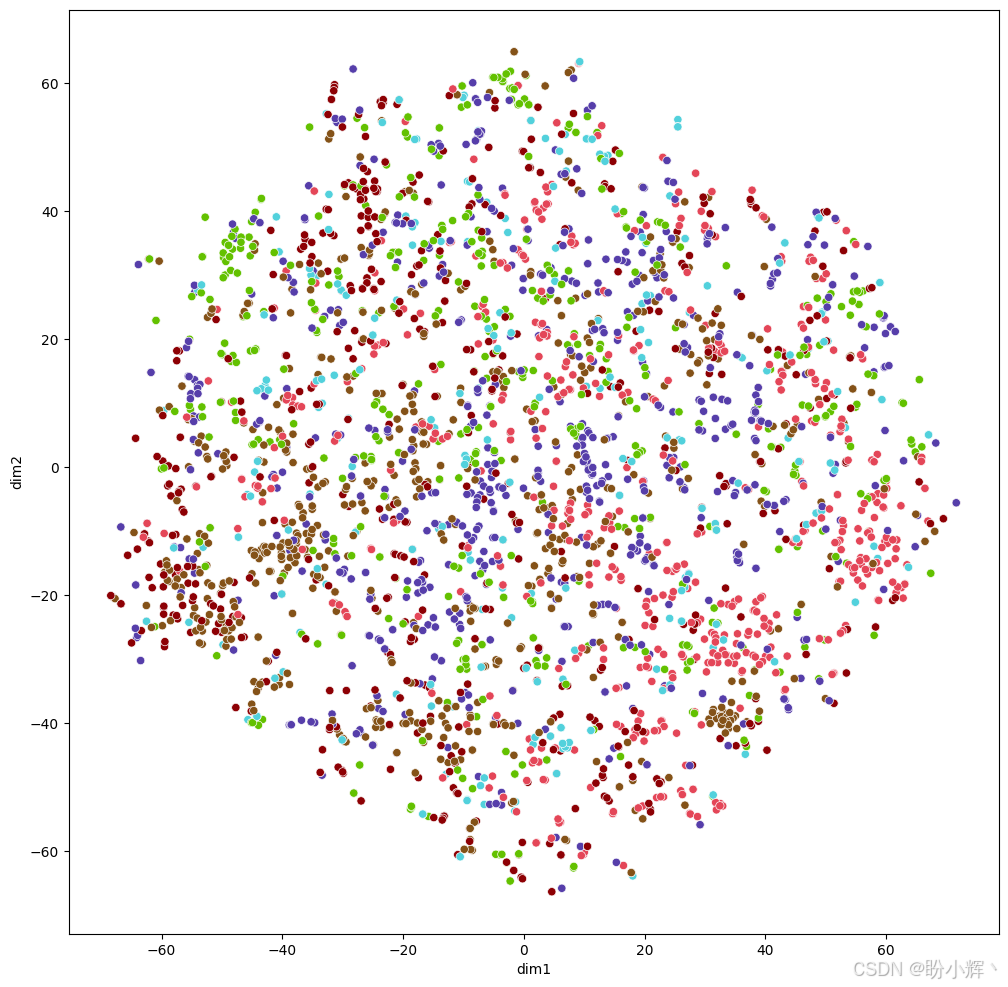
(2) 将数据集所有节点输入刚定义好的未训练 GAT 模型,生成 6 个节点类别的概率向量。随后对这些 6 维特征应用 t-SNE 降维至 2 维,实现所有节点在二维平面上的可视化:
python
model.eval()
out = model(data.x, data.edge_index)
visualize(out.detach().cpu().numpy(), data.y)输出如下所示,节点呈现随机分布状态:
3. 模型训练
(1) 在定义优化器、损失函数以及模型训练和评估流程后,训练 GAT 模型 100 个 epoch:
python
optimizer = torch.optim.Adam(model.parameters(), lr=0.0005, weight_decay=1e-1)
criterion = torch.nn.CrossEntropyLoss()
def train():
model.train()
optimizer.zero_grad() # Clear gradients.
out = model(data.x, data.edge_index) # Perform a single forward pass.
loss = criterion(out[data.train_mask], data.y[data.train_mask]) # Compute the loss solely based on the training nodes.
loss.backward() # Derive gradients.
optimizer.step() # Update parameters based on gradients.
return loss
def test(mask):
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1) # Use the class with highest probability.
correct = pred[mask] == data.y[mask] # Check against ground-truth labels.
acc = int(correct.sum()) / int(mask.sum()) # Derive ratio of correct predictions.
return acc
for epoch in range(1, 101):
loss = train()
val_acc = test(data.val_mask)
test_acc = test(data.test_mask)
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}, Val: {val_acc:.4f}')输出结果如下所示:

可以看到,验证集的准确率 (72.20%) 略高于 GCN 模型的验证集准确率 (70.00%)。
(2) 我们使用训练好的 GAT 模型,评估其在测试集上的准确率:
python
test_acc = test(data.test_mask)
print(f'Test Accuracy: {test_acc:.4f}')输出结果如下所示:
shell
Test Accuracy: 0.7110相较于 GCN 模型 69.60% 的准确率,采用 GAT 模型后性能进一步提升 2.5 个百分点。这一提升源自注意力层的强大特性------该机制不仅为模型增加了更多可训练参数,还赋予图模型更高灵活性,从而可以学习不同邻居节点之间的自定义关系。
(3) 最后,我们使用训练好的 GAT 模型对所有图节点进行预测,并将 6 维节点类别概率经 t-SNE 降维至 2 维实现可视化:
python
out = model(data.x, data.edge_index)
visualize(out.detach().cpu().numpy(), data.y)输出结果如下所示:
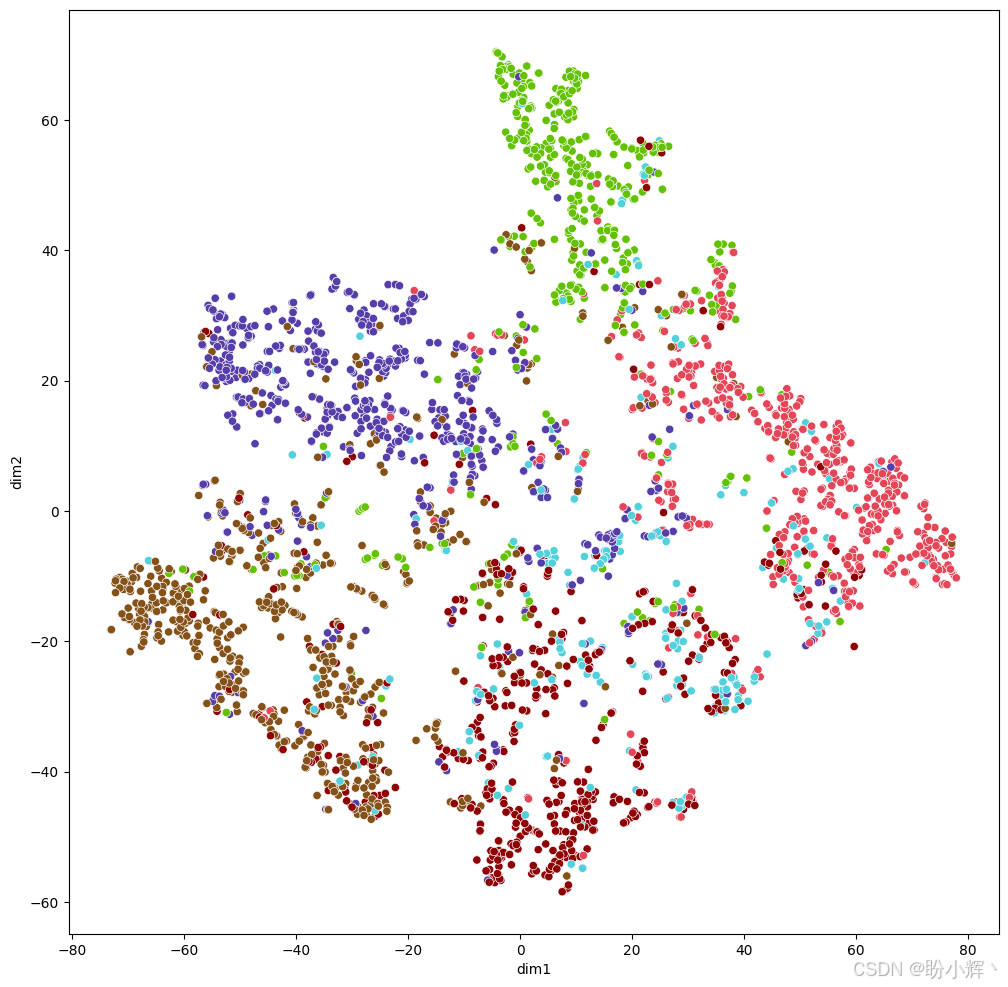
与随机分布相比,节点已形成明显的聚类分布,这表明模型确实得到了有效训练。更重要的是,该模型学习到的节点表征质量优于 GCN 模型,不同类别节点的分离边界更加清晰可辨。
小结
本节介绍了图注意力网络 (Graph Attention Network, GAT) 在节点分类任务中的应用。相比图卷积网络 (Graph Convolutional Network, GCN)的平均聚合机制,GAT 通过引入注意力机制,能够为不同邻居节点分配差异化权重,从而更精准地捕捉图结构信息。实验表明,GAT 在 CiteSeer 数据集上的分类准确率达到 71.1%,较 GCN 提升 2.5 个百分点。可视化结果显示,GAT 学习到的节点表征具有更好的类别区分度。这验证了注意力机制在图数据建模中的有效性,为处理复杂图结构任务提供了更优解决方案。
系列链接
PyTorch实战(1)------深度学习(Deep Learning)
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络
PyTorch实战(8)------图像描述生成
PyTorch实战(9)------从零开始实现Transformer
PyTorch实战(10)------从零开始实现GPT模型
PyTorch实战(11)------随机连接神经网络(RandWireNN)
PyTorch实战(12)------图神经网络(Graph Neural Network,GNN)
PyTorch实战(13)------图卷积网络(Graph Convolutional Network,GCN)