注意力机制原理详解
Transformer模型,作为自然语言处理(NLP)领域的一块重要里程碑,于2017年由Google的研究者们提出,现在成为深度学习中对文本和语言数据处理具有根本性影响的架构之一。在NLP的宇宙中,如果说RNN、LSTM等神经网络创造了"序列记忆"的能力,那么Transformer则彻底颠覆了这种"记忆"的处理方式------它放弃了传统的顺序操作,而是通过自注意力机制(Self-Attention),赋予模型一种全新的、并行化的信息理解和处理方式。从自注意力的直观概念出发,Transformer的设计者们引进了多头注意力(Multi-Head Attention)、位置编码(Positional Encoding)等创新元素,大幅度提升了模型处理序列数据的效率和效果。通过精巧的数学构建和模型设计,Transformer能够同时捕捉序列中的局部细节和全局上下文,解决了以往模型在长距离依赖上的困难,使其在处理长文本序列时的能力大大增强。
经过几年的快速迭代,Transformer不仅优化了其原始架构,而且催生了一系列高效的后续模型如BERT、GPT-3、RoBERTa和T5等,这些模型在语言理解、文本生成等多种NLP任务上都取得了令人瞩目的成绩。如同LSTM在其领域内的长久影响一样,Transformer模型的论文和原理也成为了NLP领域的经典,而它本身的算法和架构也已成为当代处理语言数据的根基。今天,尽管存在多种高级的算法和模型,Transformer仍然是处理复杂语言模式、捕捉细腻语义的主流架构,它在多个维度上重塑了我们构建和理解语言模型的方式。现在,就让我们一起来探讨这一划时代结构背后的深邃原理。
一、Transformer模型的地位与发展历程
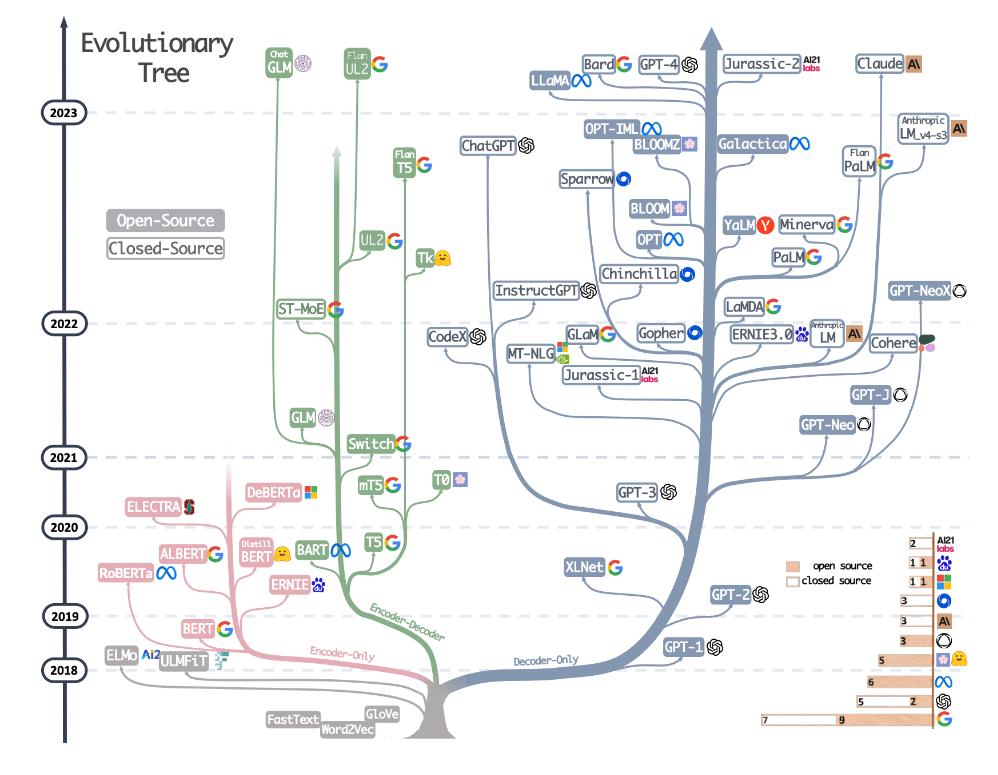
学习Transformer并不只是学习一个算法,而是学习以Transformer为核心的一整个、基于注意力机制的大体系。在NLP领域中,有这样一张著名的树状图,它展示了从2018年到2023年的各种基于Transformer架构的语言模型的发展历程,并将模型从"开源/闭源"、"encoder/decoder/encoder-decoder"以及开发公司三个维度进行了划分。这个演化树很好地概述了从2018年到2023年基于Transformer架构的模型的发展脉络,让我们一步步来解读这个发展历史。
- 2018年:
Transformer的早期探索
ELMo(Embeddings from Language Models)和ULMFiT(Universal Language Model Fine-tuning)虽然不是基于Transformer架构的,但它们引入了深层双向表示和迁移学习的概念,这对后来的Transformer模型产生了重要影响。
- 2019年:
BERT及其衍生模型
BERT(Bidirectional Encoder Representations fromTransformers)是一个重要的里程碑,它通过自注意力机制(Self-Attention)使模型能够生成上下文相关的词向量。它是首个大规模双向Transformer模型,对后续的模型产生了深远影响。Ro
BERTa 对BERT进行了改进,通过更大的数据集和更长的训练时间提高了性能。AL
BERT旨在减少模型大小的同时保持性能,通过因子分解嵌入层和跨层参数共享实现。
- 2020年:多样化的模型和架构
T5(text-to-text Transfer Transformer)将所有文本问题转化为文本到文本的格式,这样可以用相同的模型处理不同的任务。
BART(Bidirectional and Auto-Regressive Transformers)结合了自编码和自回归的特点,适用于序列生成任务。
- 2021年:专门化与效率优化
ELECTRA通过对抗性训练和效率优化来提高模型性能。
DeBERTa引入了改进的注意力机制,提高了模型对词之间关系的理解。
- 2022年:大型语言模型的崛起
GPT-3(Generative Pre-trained Transformer3)以其庞大的参数量和强大的生成能力成为当时最大的语言模型之一。
Switch-C(Switch Transformers)采用了稀疏激活,允许模型扩展到非常大的尺寸而不显著增加计算成本。
- 2023年:高级应用与细化模型
ChatGPT和InstructGPT是在GPT-3基础上针对特定应用,如聊天和指令性任务,进行了优化的模型。
Chinchilla和Gopher表示了更高级别的语言理解和生成能力。`FLAN 和 mT5 针对多语言任务设计,显示了模型的国际化和多样化发展。
这个演化树还展示了各个模型之间的继承关系,以及它们是否开源。模型的不断迭代和创新反映了这个领域对于理解和生成人类语言能力的不断追求。每一代模型都在数据处理能力、训练方法、应用范围以及解决特定问题的能力上做出了改进。这一进程不仅推动了NLP的边界,也为人工智能的其他领域提供了宝贵的见解。
当我们踏上学习Transformer的旅程时,实际上是在拥抱一个基于注意力机制的庞大而复杂的知识体系,这远远超出了单一算法的学习。Transformer及其衍生的模型不仅仅是NLP领域的工具,更是一扇窗口,透过它我们可以观察和理解语言的深层结构和流动的信息。这一体系以其独特的处理方式------自注意力机制------为核心,它挑战了传统的序列处理观念,引领我们探索如何让机器更深入地理解文本之间的复杂关系。从Transformer的基本架构到各种先进的变体,如BERT、GPT-3等,我们将学习如何让机器通过这些模型捕捉到词与词之间的微妙联系,理解语境的全局连贯性,以及如何将这些理解转化为处理多样化任务的能力。通过学习Transformer,我们不只是在掌握一种技术,更是在探索一个不断发展的领域,这个领域正推动着人工智能的边界,塑造着未来。所以,让我们开启这一段学习之旅,不仅为了掌握一个算法,更为了深入理解这个基于注意力的丰富体系,发现其在语言、思想和技术交汇处的无限可能。
二、序列模型的基本思路与根本诉求
要理解Transformer模型的本质,首先我们要回归到序列数据、序列模型这些基本概念上来。序列数据是一种按照特定顺序排列的数据,它在现实世界中无处不在,例如股票价格的历史记录、语音信号、文本数据、视频数据等等,主要是按照某种特定顺序排列、且该顺序不能轻易被打乱的数据都被称之为是序列数据。序列数据有着"样本与样本有关联"的特点;对时间序列数据而言,每个样本就是一个时间点,因此样本与样本之间的关联就是时间点与时间点之间的关联。对文字数据而言,每个样本就是一个字/一个词,因此样本与样本之间的关联就是字与字之间、词与词之间的语义关联。很显然,要理解一个时间序列的规律、要理解一个完整的句子所表达的含义,就必须要理解样本与样本之间的关系。
对于一般表格类数据,我们一般重点研究特征与标签之间的关联,但在序列数据中,众多的本质规律与底层逻辑都隐藏在其样本与样本之间的关联中 ,这让序列数据无法适用于一般的机器学习与深度学习算法。这是我们要创造专门处理序列数据的算法的根本原因。在深度学习与机器学习的世界中,序列算法的根本诉求是要建立样本与样本之间的关联,并借助这种关联提炼出对序列数据的理解。唯有找出样本与样本之间的关联、建立起样本与样本之间的根本联系,序列模型才能够对序列数据实现分析、理解和预测。
在机器学习和深度学习的世界当中,存在众多经典且有效的序列模型。这些模型通过如下的方式来建立样本与样本之间的关联------
- ARIMA家族算法群
过去影响未来,因此未来的值由过去的值加权求和而成,以此构建样本与样本之间的关联。
AR模型:yt=c+w1yt−1+w2yt−2+⋯+wpyt−p+εtAR模型:y_t = c + w_1 y_{t-1} + w_2 y_{t-2} + \dots + w_p y_{t-p} + \varepsilon_t AR模型:yt=c+w1yt−1+w2yt−2+⋯+wpyt−p+εt
- 循环网络家族
遍历时间点/样本点,将过去的时间上的信息传递存储在中间变量中,传递给下一个时间点,以此构建样本和样本之间的关联。
'RNN'模型:ht=Wxh⋅xt+Whh⋅ht−1`RNN`模型:h_t = W_{xh}\cdot x_t + W_{hh}\cdot h_{t-1}'RNN'模型:ht=Wxh⋅xt+Whh⋅ht−1
'LSTM'模型:C~t=tanh(Wxi⋅xt+Whi⋅ht−1+bi)`LSTM`模型:\tilde{C}t = tanh(W{xi} \cdot x_t + W_{hi} \cdot h_{t-1} + b_i)'LSTM'模型:C~t=tanh(Wxi⋅xt+Whi⋅ht−1+bi)
- 卷积网络家族
使用卷积核扫描时间点/样本点,将上下文信息通过卷积计算整合到一起,以此构建样本和样本之间的关联。如下图所示,蓝绿色方框中携带权重www,权重与样本值对应位置元素相乘相加后生成标量,这是一个加权求和过程。
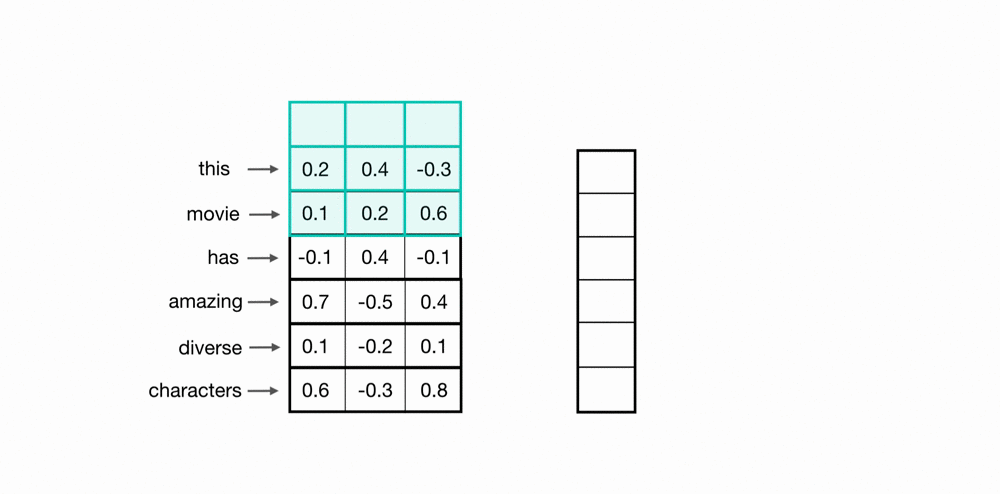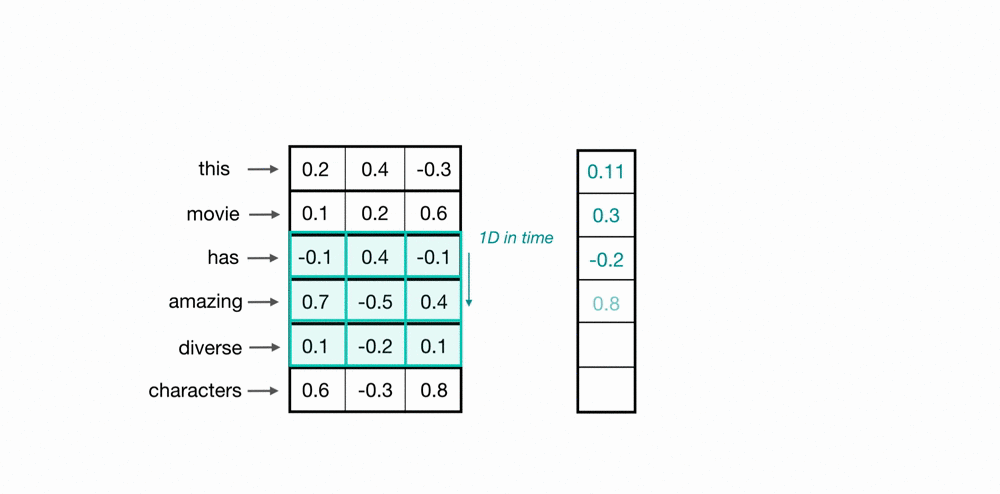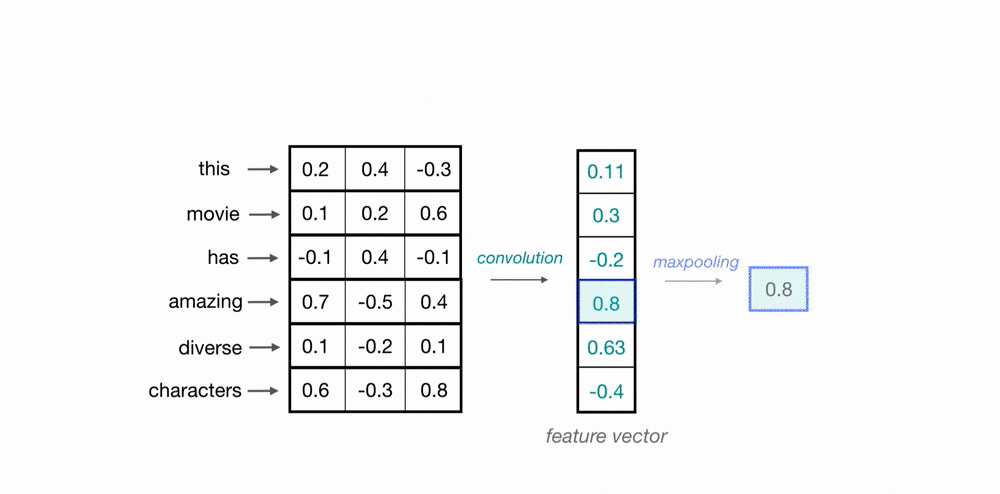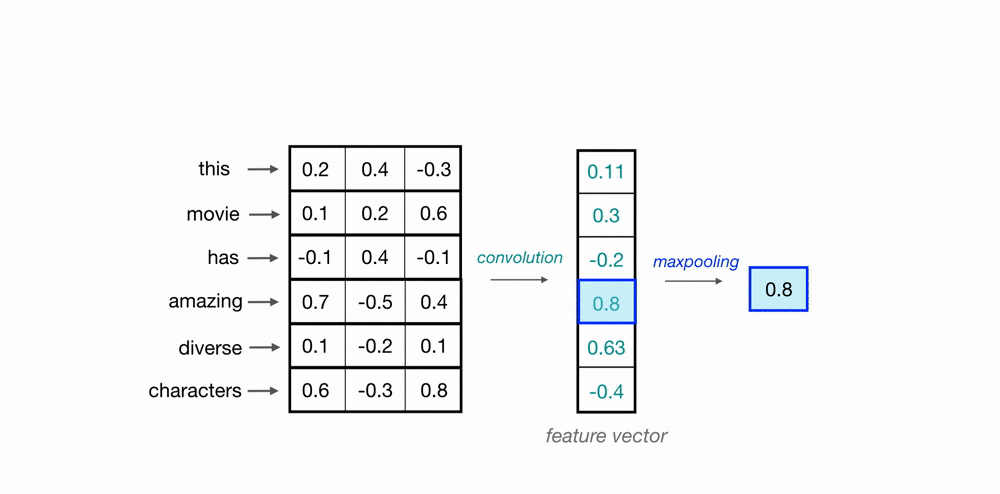
总结众多序列架构的经验,你会发现成功的序列架构都在使用加权求和的方式来建立样本与样本之间的关联 ,通过对不同时间点/不同样本点上的值进行加权求和,可以轻松构建"上下文信息的复合表示",只要尝试着使用迭代的方式求解对样本进行加权求和的权重,就可以使算法获得对序列数据的理解。加权求和是有效的样本关联建立方式,这在整个序列算法研究领域几乎已经形成了共识。在序列算法发展过程中,核心的问题已经由"如何建立样本之间的关联"转变为了"如何合理地对样本进行加权求和、即如何合理地求解样本加权求和过程中的权重" 。在这个问题上,Transformer给出了序列算法研究领域目前为止最完美的答案之一------Attention is all you need,最佳权重计算方式是注意力机制。
三、注意力机制
3.1 注意力机制的本质
注意力机制是一个帮助算法辨别信息重要性的计算流程,它通过计算样本与样本之间相关性来判断每个样本之于一个序列的重要程度 ,并给这些样本赋予能代表其重要性的权重 。很显然,注意力机制能够为样本赋予权重的属性与序列模型研究领域的追求完美匹配,Transformer正是利用了注意力机制的这一特点,从而想到利用注意力机制来进行权重的计算。
面试考点
作为一种权重计算机制、注意力机制有多种实现形式。经典的注意力机制(Attention)进行的是跨序列的样本相关性计算,这是说,经典注意力机制考虑的是序列A的样本之于序列B的重要程度。这种形式常常用于经典的序列到序列的任务(Seq2Seq),比如机器翻译;在机器翻译场景中,我们会考虑原始语言系列中的样本对于新生成的序列有多大的影响,因此计算的是原始序列的样本之于新序列的重要程度。
不过在
Transformer当中我们使用的是"自注意力机制"(Self-Attention),这是在一个序列内部对样本进行相关性计算的方式,核心考虑的是序列A的样本之于序列A本身的重要程度。
在Transformer架构中我们所使用的是自注意力机制,因此我们将重点围绕自注意力机制来展开讨论,我们将一步步揭开自注意力机制对于Transformer和序列算法的意义------
- 首先,为什么要判断序列中样本的重要性?计算重要性对于序列理解来说有什么意义?
在序列数据当中,每个样本对于"理解序列"所做出的贡献是不相同的,能够帮助我们理解序列数据含义的样本更为重要,而对序列数据的本质逻辑/含义影响不大的样本则不那么重要。以文字数据为例------
尽管今天下了雨,但我因为_________而感到非常开心和兴奋。
__________,但我因为拿到了梦寐以求的工作offer而感到非常开心和兴奋。
观察上面两句话,我们分别抠除了一些关键信息。很显然,第一个句子令我们完全茫然,但第二个句子虽然缺失了部分信息,但我们依然理解事情的来龙去脉。从这两个句子我们明显可以看出,不同的信息对于句子的理解有不同的意义。
在实际的深度学习预测任务当中也是如此,假设我们依然以这个句子为例------
尽管今天下了雨,但我因为拿到了梦寐以求的工作offer而感到非常开心和兴奋。
假设模型对句子进行情感分析,很显然整个句子的情感倾向是积极的,在这种情况下,"下了雨"这一部分对于理解整个句子的情感色彩贡献较小,相对来说,"拿到了梦寐以求的工作offer"和"感到非常开心和兴奋"这些部分则是理解句子传达的正面情绪的关键。因此对序列算法来说,如果更多地学习"拿到了梦寐以求的工作offer"和"感到非常开心和兴奋"这些词,就更有可能对整个句子的情感倾向做出正确的理解,就更有可能做出正确的预测。
当我们使用注意力机制来分析这样的句子时,自注意力机制可能会为"开心"和"兴奋"这样的词分配更高的权重,因为这些词直接关联到句子的情感倾向。在很长一段时间内、长序列的理解都是深度学习世界的业界难题,在众多研究当中研究者们尝试着从记忆、效率、信息筛选等等方面来寻找出路,而注意力机制所走的就是一条"提效"的道路。如果我们能够判断出一个序列中哪些样本是重要的、哪些是无关紧要的,就可以引导算法去重点学习更重要的样本,从而可能提升模型的效率和理解能力。
- 第二,那样本的重要性是如何定义的?为什么?
自注意力机制通过计算样本与样本之间的相关性来判断样本的重要性,在一个序列当中,如果一个样本与其他许多样本都高度相关,则这个样本大概率会对整体的序列有重大的影响。举例说明,看下面的文字------
经理在会议上宣布了重大的公司______计划,员工们反应各异,但都对未来充满期待。
在这个例子中,我们抠除的这个词与"公司"、"计划"、"会议"、"宣布"和"未来"等词汇都高度相关。如果我们针对这些词汇进行提问,你会发现------
公司 做了什么?
宣布 了什么内容?
计划 是什么?
未来 会发生什么?
会议上的主要内容是什么?
所有这些问题的答案都围绕着这一个被抠除的词产生。这个完整的句子是------
经理在会议上宣布了重大的公司重组计划,员工们反应各异,但都对未来充满期待。
被抠掉的部分是重组。很明显,重组这个词不仅提示了事件的性质、是整个句子的关键,而且也对其他词语的理解有着重大的影响。这个单词对于理解句子中的事件------公司正在经历重大变革,以及员工们的情绪反应------都至关重要。如果没有"重组"这个词,整个句子的意义将变得模糊和不明确,因为不再清楚"宣布了什么"以及"未来期待"是指什么。因此,"重组"这个词很明显对整个句子的理解有重大影响,而且它也和句子中的其他词语高度相关。
相对的,假设我们抠掉的是------
经理在会议上宣布了重大的公司重组计划,______反应各异,但都对未来充满期待。
你会发现,虽然我们缺失了一些信息,但实际上这个信息并不太影响对于整体句子的理解,我们甚至可以大致推断出缺失的信息部分。这样的规律可以被推广到许多序列数据上,在序列数据中我们认为与其他样本高度相关的样本,大概率会对序列整体的理解有重大影响。因此样本与样本之间的相关性可以用来衡量一个样本对于序列整体的重要性。
- 第三,样本的重要性(既一个样本与其他样本之间的相关性)具体是如何计算的?
在NLP的世界中,序列数据中的每个样本都会被编码成一个向量,其中文字数据被编码后的结果被称为词向量,时间序列数据则被编码为时序向量。
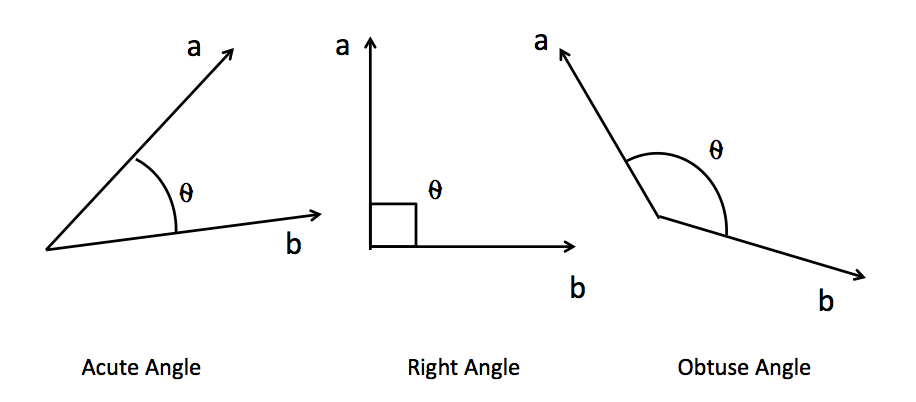
因此,要计算样本与样本之间的相关性,本质就是计算向量与向量之间的相关性。向量的相关性可以由两个向量的点积来衡量。如果两个向量完全相同方向(夹角为0度),它们的点积最大,这表示两个向量完全正相关;如果它们方向完全相反(夹角为180度),点积是一个最大负数,表示两个向量完全负相关;如果它们垂直(夹角为90度或270度),则点积为零,表示这两个向量是不相关的。因此,向量的点积值的绝对值越大,则表示两个向量之间的相关性越强,如果向量的点积值绝对值越接近0,则说明两个向量相关性越弱。
向量的点积就是两个向量相乘的过程,设有两个三维向量A\mathbf{A}A 和 B\mathbf{B}B,则向量他们之间的点积可以具体可以表示为:
A⋅BT=(a1,a2,a3)⋅(b1b2b3)=a1⋅b1+a2⋅b2+a3⋅b3 \mathbf{A} \cdot \mathbf{B}^T = \begin{pmatrix} a_1, a_2, a_3 \end{pmatrix} \cdot \begin{pmatrix} b_1 \\ b_2 \\ b_3 \end{pmatrix} = a_1 \cdot b_1 + a_2 \cdot b_2 + a_3 \cdot b_3 A⋅BT=(a1,a2,a3)⋅ b1b2b3 =a1⋅b1+a2⋅b2+a3⋅b3
相乘的结构为(1,3) y (3,1) = (1,1),最终得到一个标量。
在NLP的世界当中,我们所拿到的词向量数据或时间序列数据一定是具有多个样本的。我们需要求解样本与样本两两之间的相关性 ,综合该相关性分数,我们才能够计算出一个样本对于整个序列的重要性。在这里需要注意的是,在NLP的领域中,样本与样本之间的相关性计算、即向量的之间的相关性计算会受到向量顺序的影响。这是说,以一个单词为核心来计算相关性,和以另一个单词为核心来计算相关性,会得出不同的相关程度,向量之间的相关性与顺序有关。举例说明:
假设我们有这样一个句子:我爱小猫咪。
- 如果以"我"字作为核心词,计算"我"与该句子中其他词语的相关性,那么"爱"和"小猫咪"在这个上下文中都非常重要。"爱"告诉我们"我"对"小猫咪"的感情是什么,而"小猫咪"是"我"的感情对象。这个时候,"爱"和"小猫咪"与"我"这个词的相关性就很大。
- 但是,如果我们以"小猫咪"作为核心词,计算"小猫咪"与该剧自中其他词语的相关性,那么"我"的重要性就没有那么大了。因为不论是谁爱小猫咪,都不会改变"小猫咪"本身。这个时候,"小猫咪"对"我"这个词的上下文重要性就相对较小。
当我们考虑更长的上下文时,这个特点会变得更加显著:
- 我爱小猫咪,但妈妈并不喜欢小猫咪。
此时对猫咪这个词来说,谁喜欢它就非常重要。
- 我爱小猫咪,小猫咪非常柔软。
此时对猫咪这个词来说,到底是谁喜欢它就不是那么重要了,关键是它因为柔软的属性而受人喜爱。
因此,假设数据中存在A和B两个样本,则我们必须计算AB、AA、BA、BB四组相关性才可以。在每次计算相关性时,作为核心词的那个词被认为是在"询问"(Question),而作为非核心的词的那个词被认为是在"应答"(Key),AB之间的相关性就是A询问、B应答的结果,AA之间的相关性就是A向自己询问、A自己应答的结果。
这个过程可以通过矩阵的乘法来完成。假设现在我们的向量中有2个样本(A与B),每个样本被编码为了拥有4个特征的词向量。如下所示,如果我们要计算A、B两个向量之间的相关性,只需要让特征矩阵与其转置矩阵做点积就可以了------
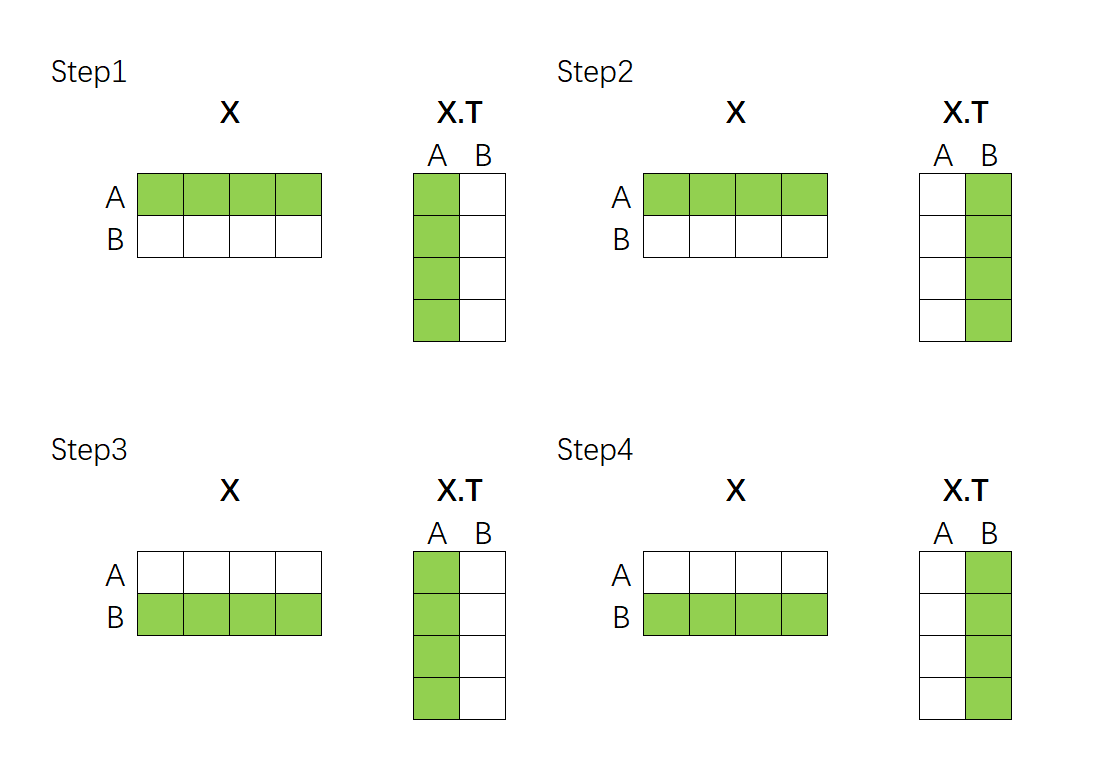
上述点积结果得到的最终矩阵是:
rAArABrBArBB\]\\begin{bmatrix} r_{AA} \& r_{AB} \\\\ r_{BA} \& r_{BB} \\end{bmatrix}\[rAArBArABrBB
该乘法规律可以推广到任意维度的数据上,如果是带有3个样本的序列与自身的转置相乘,就会得到3y3结构的相关性矩阵,如果是n个样本的序列与自身的转置相乘,就会得到nyn结构的相关性矩阵,这些相关性矩阵代表着这一序列当中每个样本与其他样本之间的相关性 ,相关系数的个数、以及相关性矩阵的结构只与样本的数量有关,与样本的特征维度无关。因此面对任意的数据,我们只需要让该数据与自身的转置矩阵相乘,就可以自然得到这一序列当中每个样本与其他样本之间的相关性构成的相关性矩阵了。
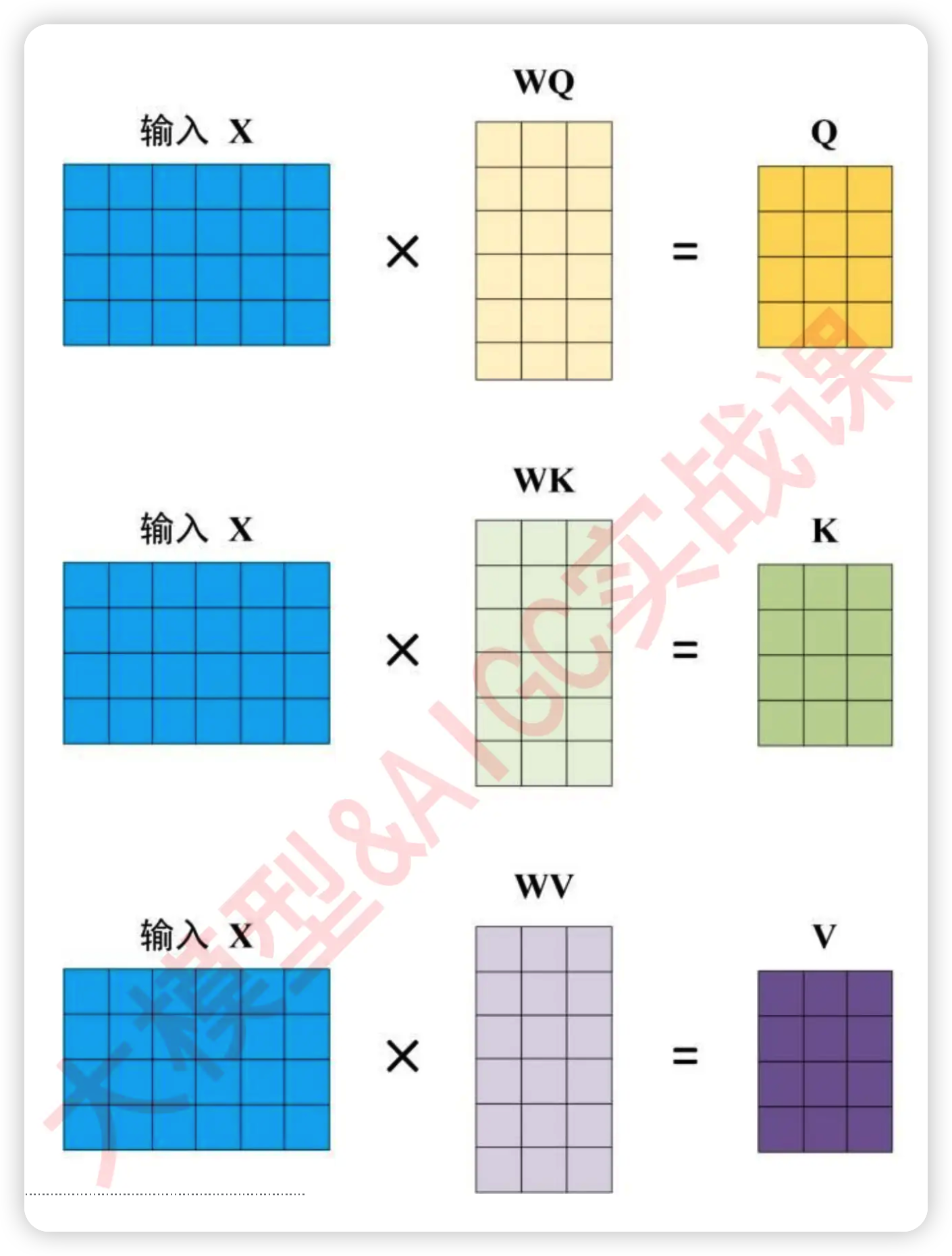
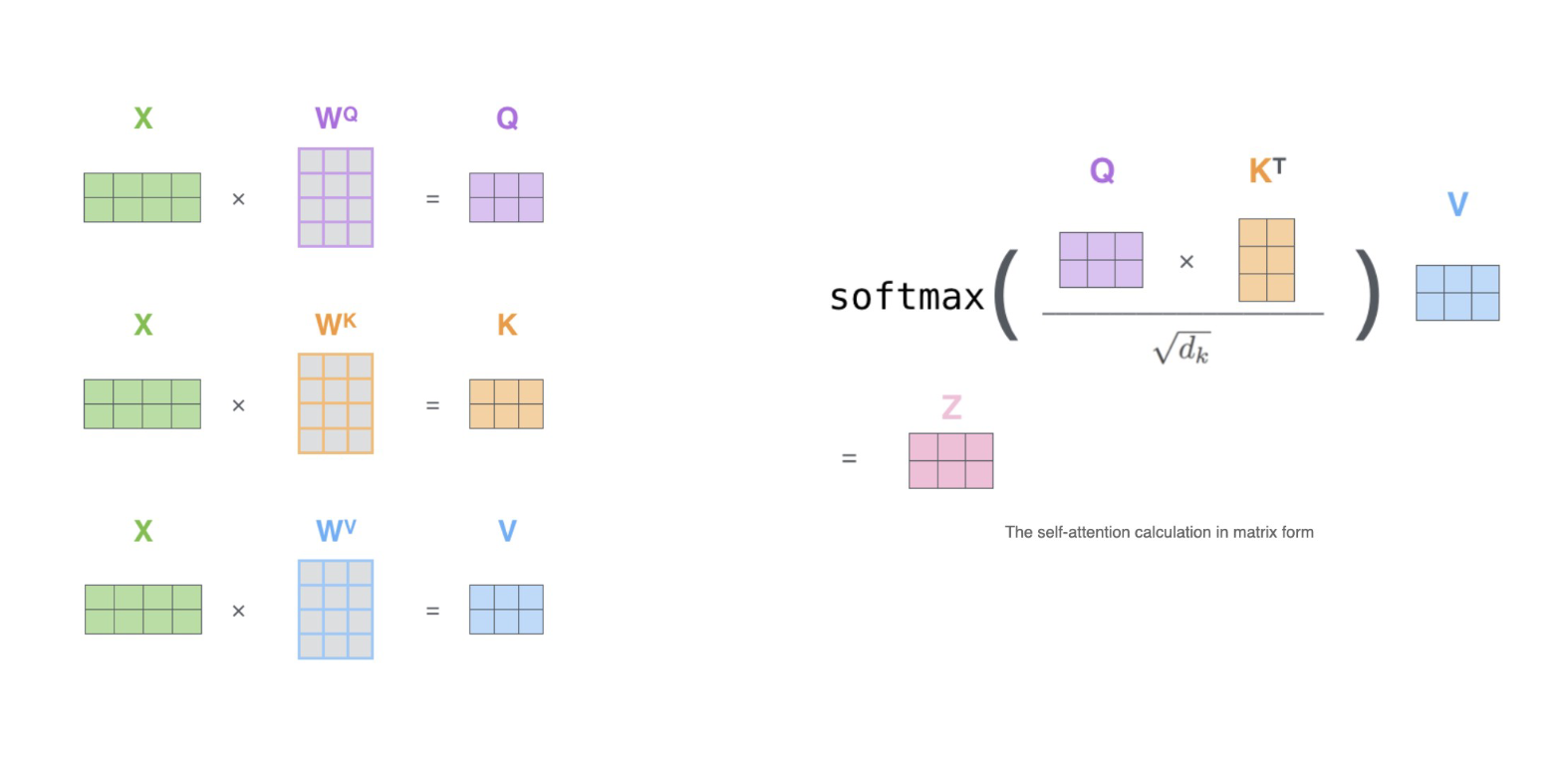
当然,在实际计算相关性的时候,我们一般不会直接使用原始特征矩阵并让它与转置矩阵相乘,因为我们渴望得到的是语义的相关性,而非单纯数字上的相关性 。因此在NLP中使用注意力机制的时候,我们往往会先在原始特征矩阵的基础上乘以一个解读语义的www参数矩阵,以生成用于询问的矩阵Q、用于应答的矩阵K以及其他可能有用的矩阵。
在实际进行运算时,www是神经网络的参数,是由迭代获得的,因此www会依据损失函数的需求不断对原始特征矩阵进行语义解读,而我们实际的相关性计算是在矩阵Q和K之间运行的。使用Q和K求解出相关性分数的过程,就是自注意力机制的核心过程,如下图所示 ↓
到这里,我们已经将自注意力机制的内容梳理完毕了。
3.2 Transformer中的自注意力机制运算流程
现在我们知道注意力机制是如何运行的了,在Transformer当中我们具体是如何使用自注意力机制为样本增加权重的呢?来看下面的流程。
Step1:通过词向量得到QK矩阵
首先,Transformer当中计算的相关性被称之为是注意力分数,该注意力分数是在原始的注意力机制上修改后而获得的全新计算方式,其具体计算公式如下------
Attention(Q,K,V)=softmax(QKTdk)VAttention(Q,K,V) = softmax(\frac{QK^{T}}{\sqrt{d_k}})VAttention(Q,K,V)=softmax(dk QKT)V
在这个公式中,首先我们要先将原始特征矩阵转化为Q和K,然后令Q乘以K的转置,以获得最基础的相关性分数。同时,我们计算出权重之后,还需要将权重乘在样本上,以构成"上下文的复合表示",因此我们还需要在原始特征矩阵基础上转化处矩阵V,用于表示原始特征所携带的信息值。假设现在我们有4个单词,每个单词被编码成了6列的词向量,那计算Q、K、V的过程如下所示:
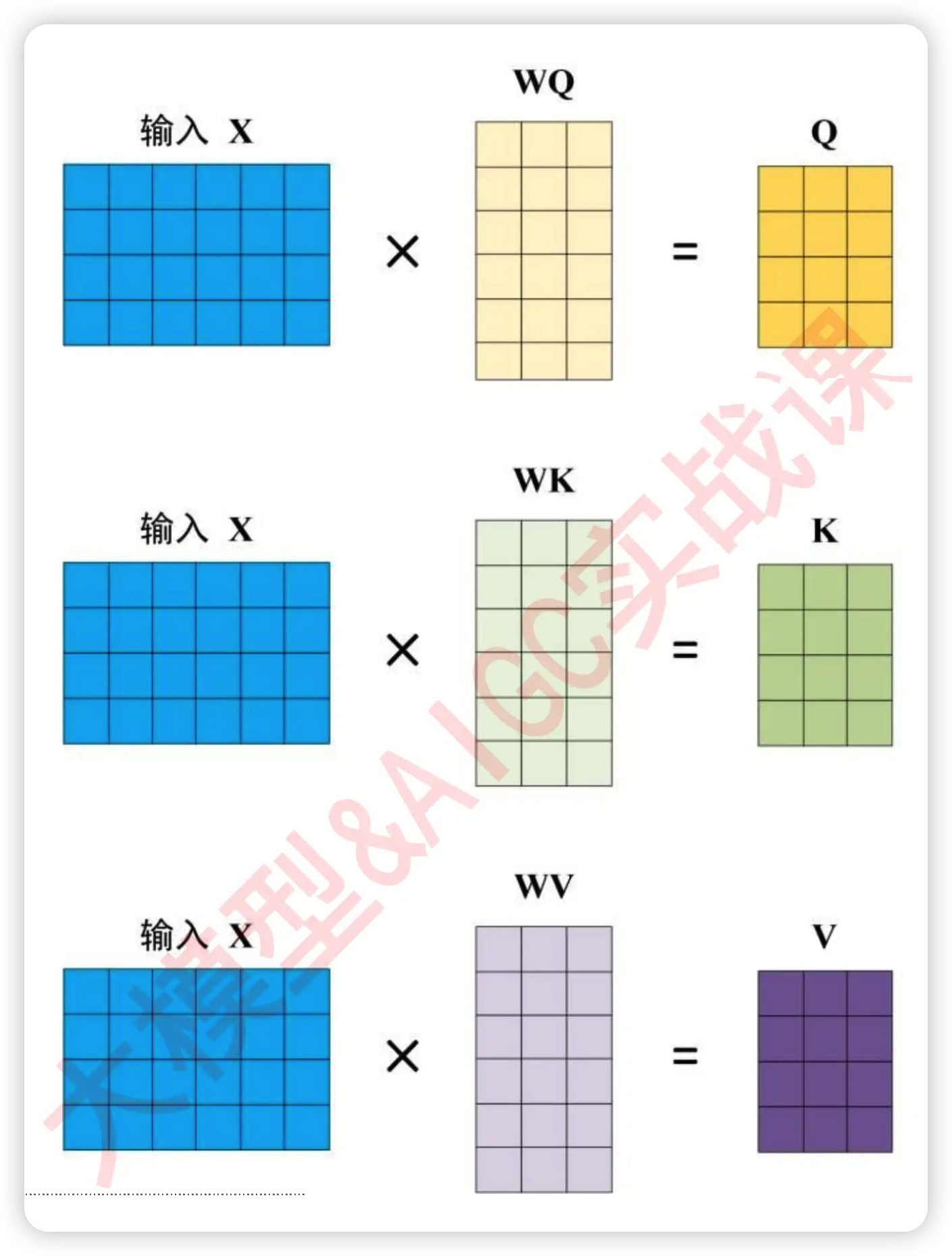
其中的WQW_QWQ与WKW_KWK的结构都为(6,3),事实上我们值需要保证这两个参数矩阵能够与yyy相乘即可(即这两个参数矩阵的行数与y被编码的列数相同即可),在现代大部分的应用当中,一般WQW_QWQ与WKW_KWK都是正方形的结构。
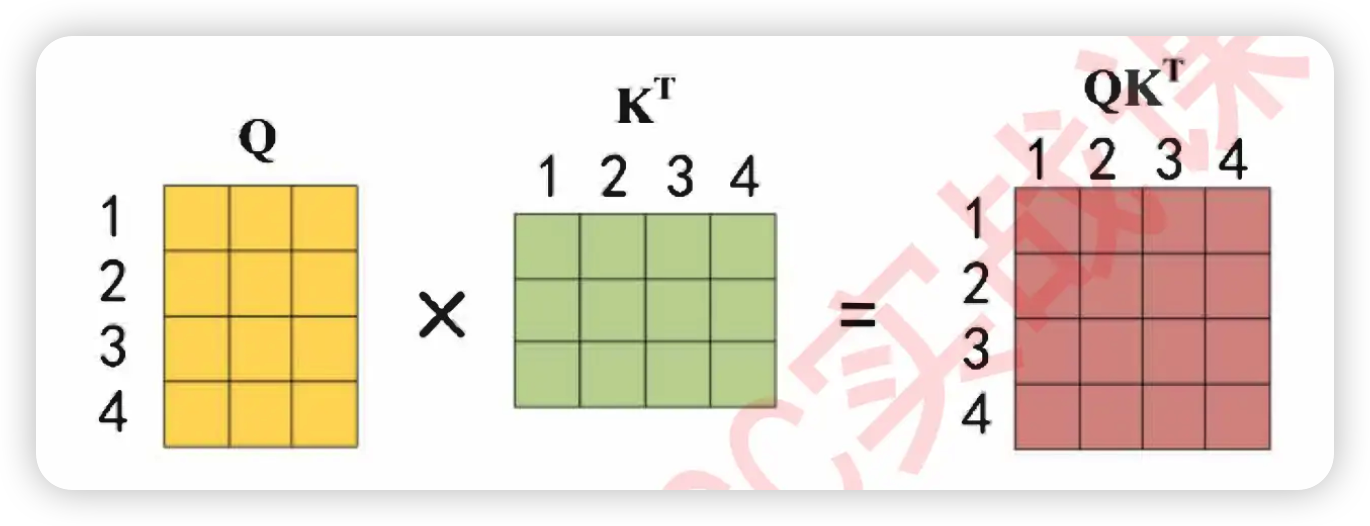
Step2:计算QKQKQK相似度,得到相关性矩阵
接下来我们让Q和K的转置相乘,计算出相关性矩阵。
Attention(Q,K,V)=softmax(QKTdk)VAttention(Q,K,V) = softmax(\frac{QK^{T}}{\sqrt{d_k}})VAttention(Q,K,V)=softmax(dk QKT)V
QKTQK^{T}QKT的过程中,点积是相乘后相加的计算流程,因此词向量的维度越高、点积中相加的项也就会越多,因此点积就会越大。此时,词向量的维度对于相关性分数是有影响的,在两个序列的实际相关程度一致的情况下,词向量的特征维度高更可能诞生巨大的相关性分数,因此对相关性分数需要进行标准化。在这里,Transformer为相关性矩阵设置了除以dk\sqrt{d_k}dk 的标准化流程,dkd_kdk就是特征的维度,以上面的假设为例,dkd_kdk=6。
Step3:softmax函数归一化
将每个单词之间的相关性向量转换成0,1之间的概率分布。例如,对AB两个样本我们会求解出AA、AB、BB、BA四个相关性,经过softmax函数的转化,可以让AA+AB的总和为1,可以让BB+BA的总和为1。这个操作可以令一个样本的相关性总和为1,从而将相关性分数转化成性质上更接近"权重"的0,1之间的比例。这样做也可以控制相关性分数整体的大小,避免产生数字过大的问题。
经过softmax归一化之后的分数,就是注意力机制求解出的权重。
Step4:对样本进行加权求和,建立样本与样本之间的关系
现在我们已经获得了softmax之后的分数矩阵,同时我们还有代表原始特征矩阵值的V矩阵------
r=(a11a12a21a22),V=(v11v12v13v21v22v23) \mathbf{r} = \begin{pmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \end{pmatrix}, \quad \mathbf{V} = \begin{pmatrix} v_{11} & v_{12} & v_{13} \\ v_{21} & v_{22} & v_{23} \end{pmatrix} r=(a11a21a12a22),V=(v11v21v12v22v13v23)
二者相乘的结果如下:
Z(Attention)=(a11a12a21a22)(v11v12v13v21v22v23)=((a11v11+a12v21)(a11v12+a12v22)(a11v13+a12v23)(a21v11+a22v21)(a21v12+a22v22)(a21v13+a22v23)) \mathbf{Z(Attention)} = \begin{pmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \end{pmatrix} \begin{pmatrix} v_{11} & v_{12} & v_{13} \\ v_{21} & v_{22} & v_{23} \end{pmatrix} = \begin{pmatrix} (a_{11}v_{11} + a_{12}v_{21}) & (a_{11}v_{12} + a_{12}v_{22}) & (a_{11}v_{13} + a_{12}v_{23}) \\ (a_{21}v_{11} + a_{22}v_{21}) & (a_{21}v_{12} + a_{22}v_{22}) & (a_{21}v_{13} + a_{22}v_{23}) \end{pmatrix} Z(Attention)=(a11a21a12a22)(v11v21v12v22v13v23)=((a11v11+a12v21)(a21v11+a22v21)(a11v12+a12v22)(a21v12+a22v22)(a11v13+a12v23)(a21v13+a22v23))
观察最终得出的结果,式子a11v11+a12v21a_{11}v_{11} + a_{12}v_{21}a11v11+a12v21不正是v11v_{11}v11和v21v_{21}v21的加权求和结果吗?v11v_{11}v11和v21v_{21}v21正对应着原始特征矩阵当中的第一个样本的第一个特征、以及第二个样本的第一个特征,这两个v之间加权求和所建立的关联,正是两个样本之间、两个时间步之间所建立的关联。
在这个计算过程中,需要注意的是,列脚标与权重无关。因为整个注意力得分矩阵与特征数量并无关联,因此在乘以矩阵vvv的过程中,矩阵rrr其实并不关心一行上有多少个vvv,它只关心这是哪一行的v。因此我们可以把Attention写成:
Z(Attention)=(a11a12a21a22)(v11v12v13v21v22v23)=((a11v1+a12v2)(a11v1+a12v2)(a11v1+a12v2)(a21v1+a22v2)(a21v1+a22v2)(a21v1+a22v2)) \mathbf{Z(Attention)} = \begin{pmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \end{pmatrix} \begin{pmatrix} v_{11} & v_{12} & v_{13} \\ v_{21} & v_{22} & v_{23} \end{pmatrix} = \begin{pmatrix} (a_{11}v_{1} + a_{12}v_{2}) & (a_{11}v_{1} + a_{12}v_{2}) & (a_{11}v_{1} + a_{12}v_{2}) \\ (a_{21}v_{1} + a_{22}v_{2}) & (a_{21}v_{1} + a_{22}v_{2}) & (a_{21}v_{1} + a_{22}v_{2}) \end{pmatrix} Z(Attention)=(a11a21a12a22)(v11v21v12v22v13v23)=((a11v1+a12v2)(a21v1+a22v2)(a11v1+a12v2)(a21v1+a22v2)(a11v1+a12v2)(a21v1+a22v2))
很显然,对于矩阵aaa而言,原始数据有多少个特征并不重要,它始终都在建立样本1与样本2之间的联系。
3.3 Multi-Head Attention 多头注意力机制
Multi-Head Attention 就是在 Self-Attention 的基础上,对于输入的 embedding 矩阵, Self-Attention 只使用了一组WQ,WK,WVW^Q,W^K,W^VWQ,WK,WV 来进行变换得到Query,Keys,Values。而Multi-Head Attention使用多组WQ,WK,WVW^Q,W^K,W^VWQ,WK,WV 得到多组Query,Keys,Values,然后每组分别计算得到一个Z矩阵,最后将得到的多个Z矩阵进行拼接。Transformer原论文里面是使用了8组不同的WQ,WK,WVW^Q,W^K,W^VWQ,WK,WV 。
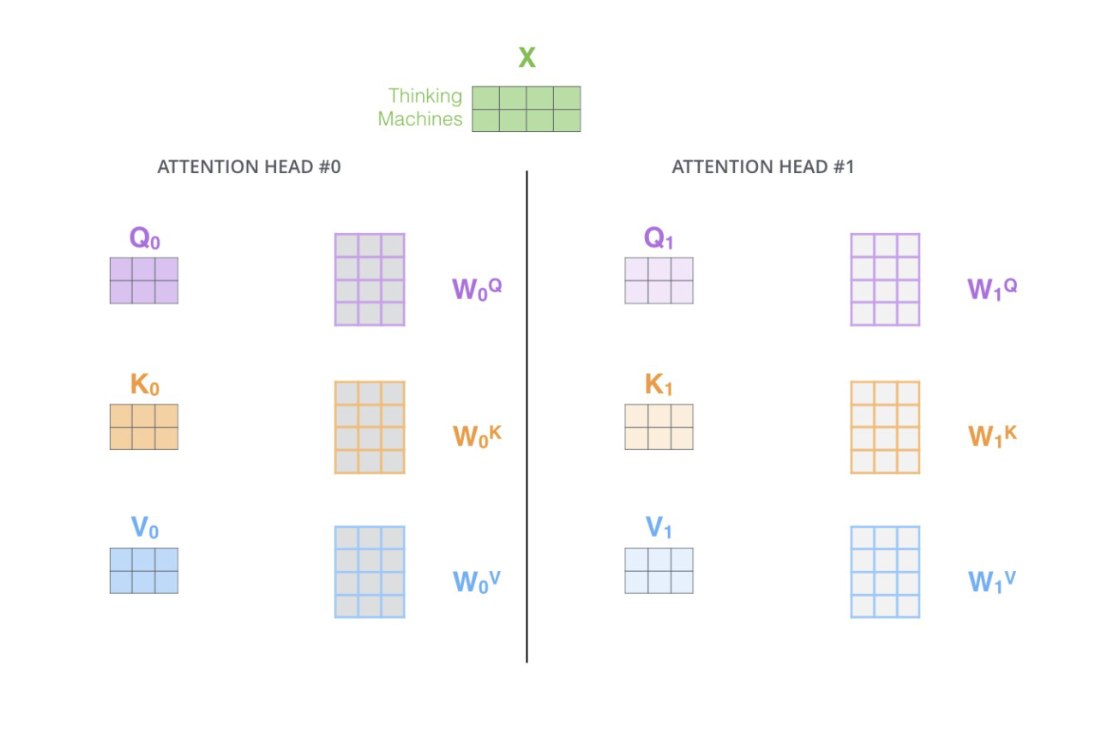
假设每个头的输出ZiZ_iZi是一个维度为(2,3)的矩阵,如果我们有hhh个注意力头,那么最终的拼接操作会生成一个维度为(2, 3h)的矩阵。
假设有两个注意力头的例子:
-
头1的输出 Z1Z_1Z1:
Z1=(z11z12z13z14z15z16) Z_1 = \begin{pmatrix} z_{11} & z_{12} & z_{13} \\ z_{14} & z_{15} & z_{16} \end{pmatrix} Z1=(z11z14z12z15z13z16) -
头2的输出 Z2Z_2Z2:
Z2=(z21z22z23z24z25z26) Z_2 = \begin{pmatrix} z_{21} & z_{22} & z_{23} \\ z_{24} & z_{25} & z_{26} \end{pmatrix} Z2=(z21z24z22z25z23z26) -
拼接操作:
Zconcatenated=(z11z12z13z21z22z23z14z15z16z24z25z26) Z_{\text{concatenated}} = \begin{pmatrix} z_{11} & z_{12} & z_{13} & z_{21} & z_{22} & z_{23} \\ z_{14} & z_{15} & z_{16} & z_{24} & z_{25} & z_{26} \end{pmatrix} Zconcatenated=(z11z14z12z15z13z16z21z24z22z25z23z26)
一般情况:
对于hhh个注意力头,每个头的输出ZiZ_iZi为:
Zi=(zi1zi2zi3zi4zi5zi6) Z_i = \begin{pmatrix} z_{i1} & z_{i2} & z_{i3} \\ z_{i4} & z_{i5} & z_{i6} \end{pmatrix} Zi=(zi1zi4zi2zi5zi3zi6)
总拼接操作如下:
Zconcatenated=(z11z12z13z21z22z23⋯zh1zh2zh3z14z15z16z24z25z26⋯zh4zh5zh6) Z_{\text{concatenated}} = \begin{pmatrix} z_{11} & z_{12} & z_{13} & z_{21} & z_{22} & z_{23} & \cdots & z_{h1} & z_{h2} & z_{h3} \\ z_{14} & z_{15} & z_{16} & z_{24} & z_{25} & z_{26} & \cdots & z_{h4} & z_{h5} & z_{h6} \end{pmatrix} Zconcatenated=(z11z14z12z15z13z16z21z24z22z25z23z26⋯⋯zh1zh4zh2zh5zh3zh6)
最终的结构为 (2,3h)。因此假设特征矩阵中,序列的长度为100,序列中每个样本的 embedding 维度为3,并且设置了8头注意力机制,那最终输出的序列就是(100,24)。
以上就是Transformer当中的自注意力层,Transformer就是在这一根本结构的基础上建立了样本与样本之间的链接。在此结构基础上,Transformer丰富了众多的细节来构成一个完整的架构。让我们现在就来看看Transformer的整体结构。
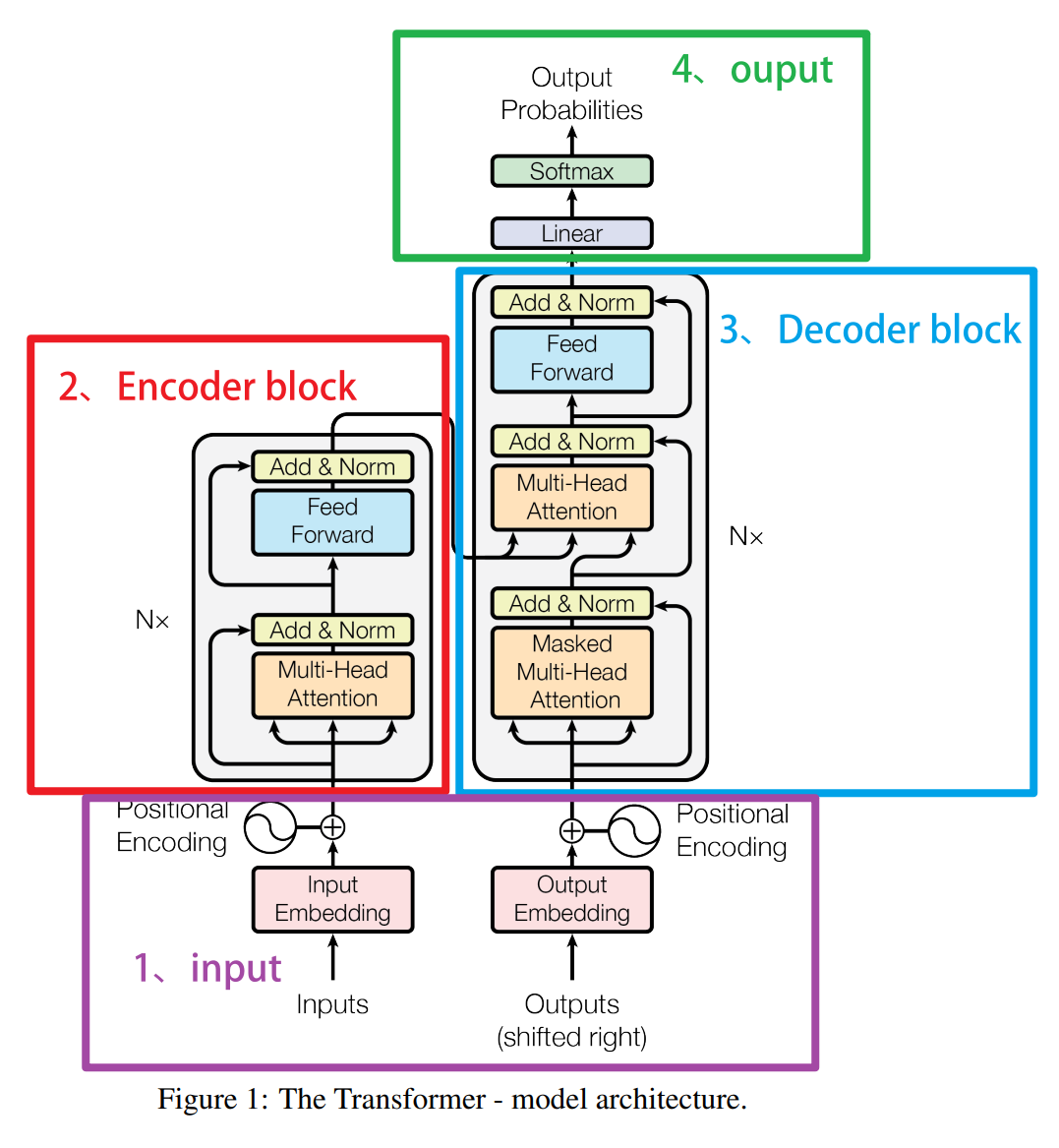
让我们一起来看看Transformer算法都由哪些元素组成,以下是来自论文《All you need is Attention》的架构图:
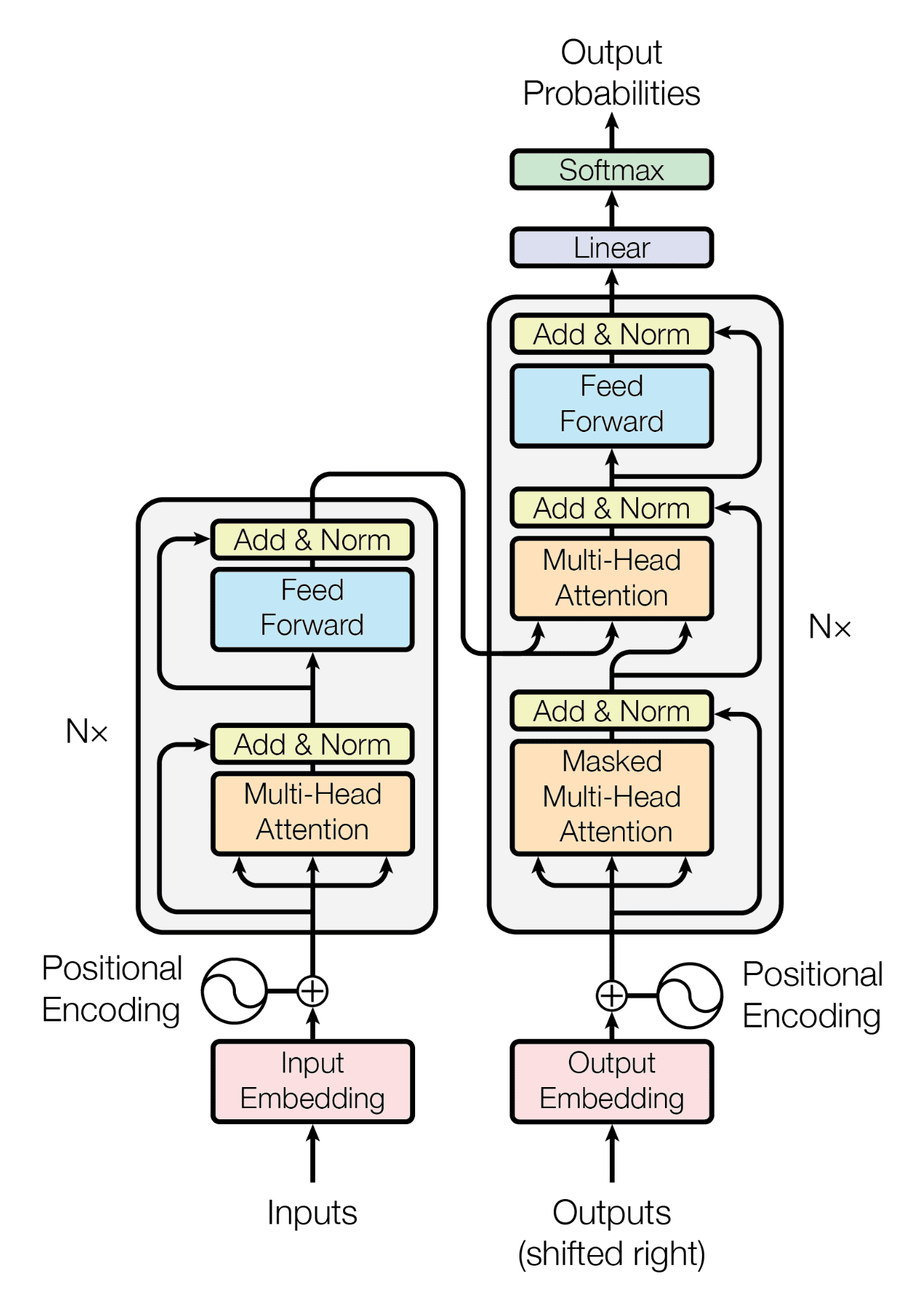
Transformer的总体架构主要由两大部分构成:编码器(Encoder)和解码器(Decoder)。在Transformer中,编码是解读数据的结构,在NLP的流程中,编码器负责解构自然语言、将自然语言转化为计算机能够理解的信息,并让计算机能够学习数据、理解数据;而解码器是将被解读的信息"还原"回原始数据、或者转化为其他类型数据的结构,它可以让算法处理过的数据还原回"自然语言",也可以将算法处理过的数据直接输出成某种结果。因此在Transformer中,编码器负责接收输入数据、负责提取特征,而解码器负责输出最终的标签。当这个标签是自然语言的时候,解码器负责的是"将被处理后的信息还原回自然语言",当这个标签是特定的类别或标签的时候,解码器负责的就是"整合信息输出统一结果"。
在信息进入解码器和编码器之前,我们首先要对信息进行Embedding和Positional Encoding两种编码 ,这两种编码在实际代码中表现为两个单独的层,因此这两种编码结构也被认为是Transformer结构的一部分。经过编码后,数据会进入编码器Encoder和解码器decoder,其中编码器是架构图上左侧的部分,解码器是架构图上右侧的部分。
编码器(Encoder)结构包括两个子层:一个是多头的自注意力(Self-Attention)层,另一个是前馈(Feed-Forward)神经网络 。输入数据会先经过自注意力层,这层的作用是为输入数据中不同的信息赋予重要性的权重、让模型知道哪些信息是关键且重要的。接着,这些信息会经过前馈神经网络层,这是一个简单的全连接神经网络,用于将多头注意力机制中输出的信息进行整合。两个子层都被武装了一个残差连接(Residual Connection),这两个层输出的结果都会有残差链接上的结果相加,再经过一个层标准化(Layer Normalization),才算是得到真正的输出。在神经网络中,多头注意力机制+前馈网络的结构可以有很多层,在Transformer的经典结构中,encoder结构重复了6层。
解码器(Decoder)也是由多个子层构成的:第一个也是多头的自注意力层(此时由于解码器本身的性质问题,这里的多头注意力层携带掩码),第二个子层是普通的多头注意力机制层,第三个层是前馈神经网络 。自注意力层和前馈神经网络的结构与编码器中的相同。注意力层是用来关注编码器输出的。同样的,每个子层都有一个残差连接和层标准化。在经典的Transformer结构中,Decoder也有6层。
这个结构看似简单,但其实奥妙无穷,这里有许多的问题等待我们去挖掘和探索 。现在就让我们从解码器部分开始逐一解读Transformer结构。