一、引言
在大模型的特征提取技术中,注意力机制是核心支柱,它让模型能聚焦关键信息。但传统单尺度注意力存在明显短板,要么只盯着局部细节,忽略全局逻辑;要么只抓整体框架,丢失关键信息。
多尺度注意力通过同时捕捉不同粒度的特征,实现了"细节 + 全局"的双重理解,是大模型处理长文本、复杂图像、多模态数据的关键技术。今天我们将从基础概念出发,由浅入深拆解原理、流程,通过代码实践,通俗易懂的了解多尺度注意力机制的核心原理与应用价值。

二、基础概念
1. 注意力机制
注意力机制好比大模型的智能聚光灯,通俗的解释,就像我们看书时,会自动把目光聚焦在关键句子上,比如中心论点,从而忽略无关的修饰词;大模型的注意力机制就是相同的道理,从海量输入信息中,筛选出重要的部分重点处理,弱化无关信息的影响。
**核心作用:**解决信息过载问题。如果模型平等对待所有信息,不仅计算量大,还会被无用信息干扰,就像我们在找丢失的物品时,非要把整个房间的每样东西都看一遍,效率极低。
2. 特征
特征好比数据的核心身份标识,通俗的理解,特征就是数据背后的关键信息,比如:
- 文本数据:单个词的含义、词与词的搭配关系、句子的主旨,比如"猫抓老鼠"的特征是"动物+动作+对象";
- 图像数据:物体的边缘、纹理、颜色、形状,比如"苹果"的特征是"圆形+红色+光滑表面";
- 语音数据:音调的高低、语速的快慢、发音的特征,比如"你好"的特征是"特定音节组合+平缓语调"。
**核心作用:**特征是大模型理解世界的基础,模型处理数据,本质就是提取这些特征,再通过特征判断数据的属性,比如"这是猫"、"这句话是疑问句"。
3. 粒度
粒度可以看作是特征的粗细程度,也是多尺度的核心前提,通俗理解粒度就像看东西的焦距,焦距近,能看清细节,这体现的是细粒度;焦距远,能看到整体,这体现的是粗粒度。
具体区分(以文本和图像为例):
- 文本
- 细粒度特征:单个词的含义、相邻2-3个词的搭配,比如"红色的"、"飞快地跑"
- 粗粒度特征:句子的主旨、段落的逻辑关系、整篇文章的核心思想
- 图像
- 细粒度特征:单个像素的颜色、物体的边缘纹理,比如苹果的果柄纹理)
- 粗粒度特征:物体的整体形状、多个物体的位置关系、整个场景,比如"苹果放在桌子上,旁边有杯子"
4. 多尺度注意力
结合前文我们将"注意力机制比拟为大模型的智能聚光灯",那么多尺度注意力可以比拟为"大模型的多焦距聚光灯系统",通俗的解释,给模型装一套"可调节焦距的聚光灯",既有能看清细节的"近焦距灯"提取细粒度特征,也有能看清整体的"远焦距灯"提取粗粒度特征,最后把两个灯照到的信息整合起来,让模型的理解更全面。
**核心关键点:**多尺度注意力的核心是同时覆盖不同粗细的信息,而不是只关注某一种粒度。
5. 关键区分
多尺度注意力、多头注意力的核心差异
- **多头注意力:**把"同一焦距的聚光灯"分成多个,每个灯关注"不同维度"的信息,比如一个灯看"词的含义",一个灯看"词的语法属性");
- **多尺度注意力:**让"聚光灯有不同焦距",每个灯关注"不同粗细"的信息,比如一个灯看"单个词",一个灯看"整个句子"。
两者不是对立的,反而经常搭配使用,比如先用多头注意力提取同一粒度下的多维度信息,再用多尺度注意力整合不同粒度的信息,让模型的理解更立体。
6. 特征融合
特征融合是多尺度注意力的最终收尾步骤,就像我们整理资料时,把细节笔记和整体框架拼在一起,形成完整的资料包;特征融合就是把多尺度注意力提取的"细粒度特征"和"粗粒度特征",按重要性加权合并,输出一个既懂细节又懂全局的综合特征。
核心作用:
- 避免"只见树木不见森林"或"只见森林不见树木"的问题;
- 单独的细粒度特征会让模型钻牛角尖,比如只认苹果的纹理,不认苹果的形状;
- 单独的粗粒度特征会让模型模糊不清,比如只知道是水果,分不清是苹果还是橘子;
- 融合后才能兼顾准确性和全面性。
三、核心原理
1. 传统注意力机制的痛点
- **1. 只能单粒度聚焦:**要么只抓细节,要么只抓整体。比如处理"猫在院子里追蝴蝶"这句话,传统注意力可能只关注"猫""蝴蝶"这两个词(细粒度),却忽略"院子里"的场景关系(粗粒度);或者只关注"动物追逐"的主旨(粗粒度),却漏了"猫"和"蝴蝶"的具体对象。
- **2. 处理长数据时力不从心:**比如处理一篇1000字的文章,传统全局注意力需要计算每个词和其他所有词的关系,计算量会随着文本长度的增加呈倍数增长,比如1000个词要计算1000×1000=100万次关系,模型运行速度慢,还容易出错。
- **3. 泛化能力差:**比如训练时只让模型识别"红色苹果"(细粒度),遇到"绿色苹果"(不同细粒度)或"装在篮子里的苹果"(带粗粒度场景)时,就无法准确识别。
2. 多尺度注意力的解决思路
模拟人类的感知逻辑,人类感知世界的方式,就是"多尺度融合"的,比如当我们看到"小狗在公园奔跑",会同时做3件事:
- **1. 关注细节:**小狗的毛发颜色、耳朵形状、奔跑的姿态;
- **2. 查看整体:**小狗的整体轮廓、公园的场景,有草坪、树木等;
- **3. 融合信息:**把细节和整体结合,得出"小狗在公园奔跑"的完整认知。
多尺度注意力就是把这种"人类感知逻辑"搬到大模型里,通过3个关键设计实现:
- **1. 多尺度特征提取:**用不同的提取工具,分别抓细粒度和粗粒度特征,比如文本用小窗口滑动抓局部词搭配,用段落聚合抓全局主旨;
- **2. 动态权重分配:**模型通过学习自动判断哪个尺度的特征更重要,比如识别特定品种的狗时,给毛发纹理的细粒度特征更高权重;识别场景类型时,给公园布局的粗粒度特征更高权重;
- **3. 加权融合:**按权重把不同尺度的特征合并,输出综合特征,用于后续任务,比如识别、分类、生成。
四、执行流程
1. 流程图
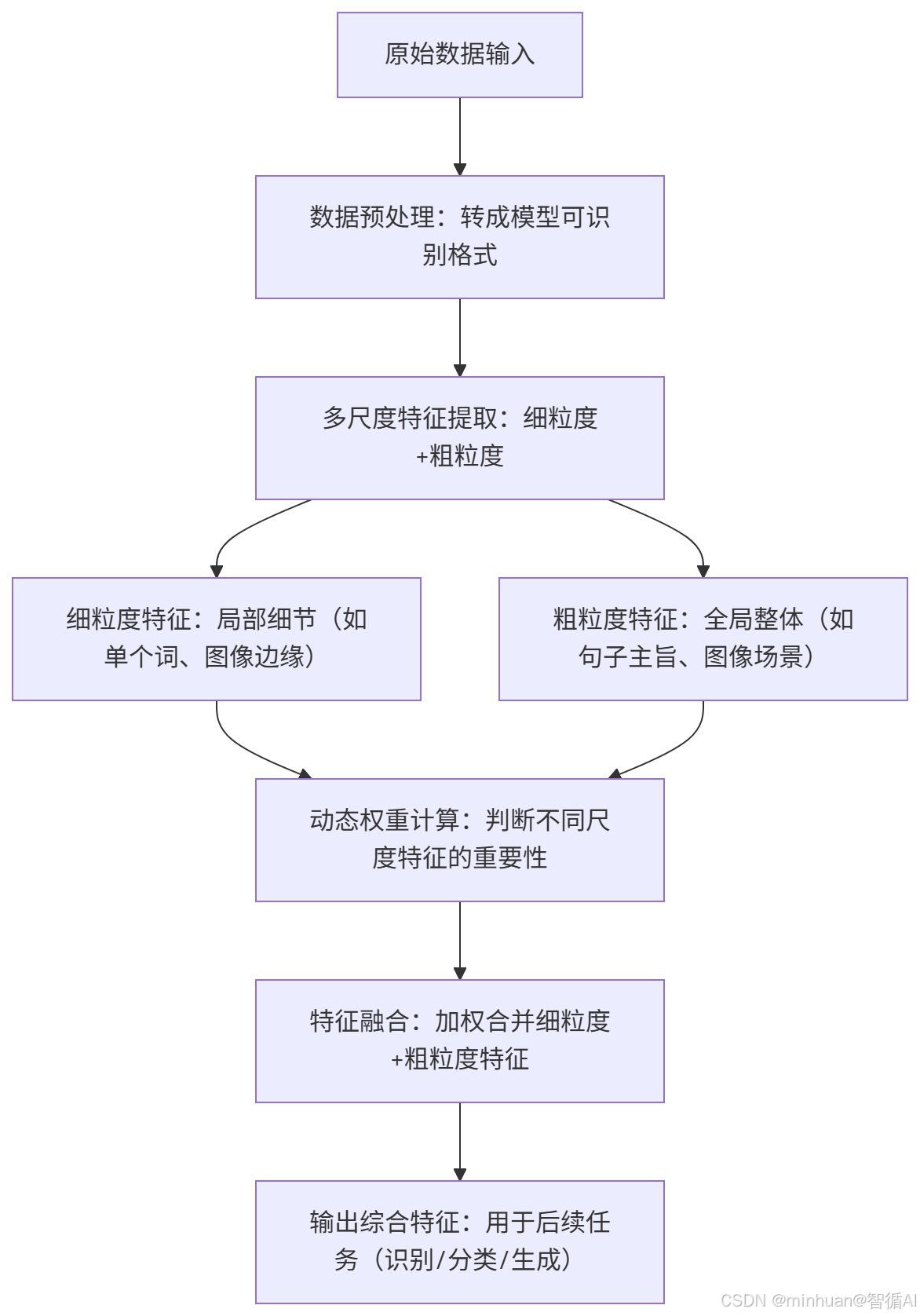
2. 流程说明
-
- 原始数据输入:输入可以是文本、图像、音频等。
-
- 数据预处理:将原始数据转换为模型可处理的格式,例如文本分词、图像归一化、音频分帧等。
-
- 多尺度特征提取:使用不同的方法或模型分支来提取不同尺度的特征。
- 细粒度特征:关注局部细节,例如文本中的词级特征、图像中的边缘和纹理、音频中的短时频谱特征。
- 粗粒度特征:关注全局结构,例如文本的句子或段落级特征、图像的整体场景特征、音频的长时间段特征。
-
- 动态权重计算:根据输入数据的内容,动态计算细粒度特征和粗粒度特征的权重。这可以通过注意力机制或其他可学习的权重分配模块来实现。
-
- 特征融合:将细粒度特征和粗粒度特征按照计算出的权重进行加权融合,得到综合特征。
-
- 输出综合特征:将融合后的特征用于下游任务,如分类、识别、生成等。
实际应用场景分析:
1. 输入的原始数据:"小明在图书馆认真看书"。
- 注意:不同数据类型的原始输入差异:图像数据是像素矩阵,语音数据是音频波形,文本数据是字符/词语序列。
2. 数据预处理:
大模型无法直接处理文字,需要通过我们在前期多篇文章提到过的Embedding嵌入把文字转换成"数值向量"
- 例如:"小明"→0.2, 0.5, 0.8,"图书馆"→0.3, 0.6, 0.1,整个句子转成一个"向量序列",每个词对应一个向量。
- 注意:预处理的核心目的是统一格式,让模型能高效处理,就像我们需要把不同格式的文件(Word、PDF)转成TXT格式,方便理解。
3. 多尺度特征提取:
- 提取细粒度特征(局部细节):用"小窗口滑动"的方式,关注相邻词的搭配关系。比如窗口大小为2,提取"小明-在""在-图书馆""图书馆-认真""认真-看书"的局部关系,这些都是细粒度特征;
- 提取粗粒度特征(全局整体):用"段落聚合"的方式,把整个句子的向量做平均或求和,得到能代表"句子主旨"的向量,这里的主旨是"小明在图书馆进行看书行为",这就是粗粒度特征。
4. 动态权重计算:
如果任务是"判断人物的行为地点",那么"图书馆"相关的细粒度特征("在-图书馆")和"场景主旨"的粗粒度特征权重会更高(比如分别是0.4和0.5);而"认真-看书"的细粒度特征权重较低(0.1)。
- 注意:权重不是固定的,而是模型通过训练学出来的,比如模型见多了"在图书馆看书"的案例,就会自动知道图书馆这个特征对判断地点很重要。
5. 特征融合与输出
按权重把细粒度特征和粗粒度特征"加权合并",得到综合特征向量。比如:
综合特征 = 0.4×(在-图书馆细粒度特征) + 0.5×(场景粗粒度特征) + 0.1×(认真-看书细粒度特征)
最后把这个综合特征输出,用于后续任务,比如:
- "地点分类"任务中,模型根据综合特征判断"行为地点是图书馆";
- "行为识别"任务中,判断"人物行为是看书"。
六、示例解析
1. 多尺度注意力实现
通过不同尺度的卷积核提取文本特征,并动态融合多尺度特征,结构说明:
-
- 包含两个卷积层(small_conv和large_conv)分别提取细粒度和粗粒度特征
-
- 通过attention_weight层动态计算两个尺度特征的权重
-
- 最终输出加权融合后的特征
python
import torch
import torch.nn as nn
import torch.nn.functional as F
# 极简多尺度注意力模块(文本处理)
# 功能:通过不同尺度的卷积核提取文本特征,并动态融合多尺度特征
# 结构说明:
# 1. 包含两个卷积层(small_conv和large_conv)分别提取细粒度和粗粒度特征
# 2. 通过attention_weight层动态计算两个尺度特征的权重
# 3. 最终输出加权融合后的特征
class SimpleMultiScaleAttention(nn.Module):
def __init__(self, embed_dim=128):
super().__init__()
self.embed_dim = embed_dim # 词向量维度
# 定义两个不同尺度的窗口卷积(用于提取不同粒度特征)
self.small_conv = nn.Conv1d(embed_dim, embed_dim, kernel_size=2, padding=1) # 小窗口(细粒度):关注相邻2个词
self.large_conv = nn.Conv1d(embed_dim, embed_dim, kernel_size=4, padding=2) # 大窗口(粗粒度):关注相邻4个词
# 定义权重计算层(判断两个尺度特征的重要性)
self.attention_weight = nn.Linear(embed_dim * 2, 2) # 输入:两个尺度特征拼接;输出:2个权重(对应两个尺度)
def forward(self, x):
# 输入说明:
# x: 输入的词向量序列,shape=(batch_size, seq_len, embed_dim)
# 例如:(2, 5, 128)表示2个样本,每个样本5个词,每个词128维向量
batch_size, seq_len, embed_dim = x.shape
# 步骤1:调整维度以适应Conv1d
# Conv1d需要输入shape=(batch_size, embed_dim, seq_len)
print("步骤1:调整输入维度以适应Conv1d")
print(f"原始输入维度: {x.shape}")
x_trans = x.transpose(1, 2) # 转置后shape=(2, 128, 5)
print(f"调整后维度: {x_trans.shape}")
# 步骤2:多尺度特征提取
# 细粒度特征:关注相邻2个词(小窗口)
fine_feature = self.small_conv(x_trans) # shape=(2, 128, 5)
print("\n步骤2:多尺度特征提取")
print("细粒度特征提取完成,shape:", fine_feature.shape)
# 粗粒度特征:关注相邻4个词(大窗口)
coarse_feature = self.large_conv(x_trans) # shape=(2, 128, 5)
print("粗粒度特征提取完成,shape:", coarse_feature.shape)
# 步骤3:调整维度回原格式
# 恢复为(batch_size, seq_len, embed_dim)以计算权重
print("\n步骤3:调整维度回原格式")
fine_feature = fine_feature.transpose(1, 2) # (2, 5, 128)
print("细粒度特征调整维度完成,shape:", fine_feature.shape)
coarse_feature = coarse_feature.transpose(1, 2) # (2, 5, 128)
print("粗粒度特征调整维度完成,shape:", coarse_feature.shape)
# 步骤4:动态权重计算
# 拼接两个尺度的特征:(batch_size, seq_len, embed_dim*2)
print("\n步骤4:动态权重计算")
combined_feature = torch.cat([fine_feature, coarse_feature], dim=-1)
print("特征拼接完成,shape:", combined_feature.shape)
# 计算权重(softmax归一化)
weights = F.softmax(self.attention_weight(combined_feature), dim=-1) # (2, 5, 2)
print("权重计算完成,shape:", weights.shape)
weight_fine, weight_coarse = weights[..., 0:1], weights[..., 1:2] # 拆分权重
print("权重拆分完成,细粒度权重shape:", weight_fine.shape, "粗粒度权重shape:", weight_coarse.shape)
# 步骤5:特征融合(加权求和)
print("\n步骤5:特征融合")
fused_feature = weight_fine * fine_feature + weight_coarse * coarse_feature # (2, 5, 128)
print("特征融合完成,shape:", fused_feature.shape)
return fused_feature
# 测试代码
if __name__ == "__main__":
# 构造模拟的词向量序列(2个样本,每个样本5个词,每个词128维)
x = torch.randn(2, 5, 128)
# 初始化多尺度注意力模块
multi_scale_attn = SimpleMultiScaleAttention(embed_dim=128)
# 执行前向传播,得到融合后的特征
fused_output = multi_scale_attn(x)
print("融合后特征的shape:", fused_output.shape) 输出结果:
步骤1:调整输入维度以适应Conv1d
原始输入维度: torch.Size(2, 5, 128)
调整后维度: torch.Size(2, 128, 5)
步骤2:多尺度特征提取
细粒度特征提取完成,shape: torch.Size(2, 128, 6)
粗粒度特征提取完成,shape: torch.Size(2, 128, 6)
步骤3:调整维度回原格式
细粒度特征调整维度完成,shape: torch.Size(2, 6, 128)
粗粒度特征调整维度完成,shape: torch.Size(2, 6, 128)
步骤4:动态权重计算
特征拼接完成,shape: torch.Size(2, 6, 256)
权重计算完成,shape: torch.Size(2, 6, 2)
权重拆分完成,细粒度权重shape: torch.Size(2, 6, 1) 粗粒度权重shape: torch.Size(2, 6, 1)
步骤5:特征融合
特征融合完成,shape: torch.Size(2, 6, 128)
融合后特征的shape: torch.Size(2, 6, 128)
结果说明:
我们有一个输入张量,原始形状为 2, 5, 128。这可以解释为:2个样本,每个样本有5个时间步(或序列长度为5),每个时间步的特征维度为128。
**步骤1:**为了适应Conv1d,我们将维度从 2, 5, 128 调整为 2, 128, 5。这是因为Conv1d期望的输入形状为 batch_size, channels, length,这里将128个特征作为通道数,5作为长度。
**步骤2:**进行多尺度特征提取,分别得到细粒度和粗粒度特征,形状均为 2, 128, 6。注意,这里的6是卷积操作后的长度,可能是由于卷积核大小和步长导致长度从5变为6。
**步骤3:**将特征维度调整回原格式,即从 2, 128, 6 调整为 2, 6, 128。这样,每个样本有6个时间步,每个时间步128维特征。
步骤4: 动态权重计算。
首先将细粒度和粗粒度特征在最后一个维度上拼接,得到形状 2, 6, 256。
然后通过一个线性层(或类似结构)计算权重,将256维映射到2维(分别对应细粒度和粗粒度特征的权重),得到形状 2, 6, 2。
接着将这两个权重拆分为两个 2, 6, 1 的张量,分别代表细粒度权重和粗粒度权重。
步骤5: 特征融合。
使用计算出的权重对细粒度和粗粒度特征进行加权求和。具体来说,将细粒度特征与细粒度权重相乘,粗粒度特征与粗粒度权重相乘,然后相加。
最终得到的融合特征形状为 2, 6, 128。
2. 场景:小明在图书馆认真看书
python
import torch
import torch.nn as nn
import torch.nn.functional as F
# 1. 定义简易多尺度注意力模块(适配案例文本)
class CaseMultiScaleAttention(nn.Module):
def __init__(self, vocab_size=100, embed_dim=16):
super().__init__()
self.embed_dim = embed_dim
# 词嵌入层:将词语转为向量(适配案例文本的简易词汇表)
self.embedding = nn.Embedding(vocab_size, embed_dim)
# 细粒度提取:小窗口卷积(窗口大小2,捕捉相邻词搭配)
self.fine_conv = nn.Conv1d(embed_dim, embed_dim, kernel_size=2, padding=1)
# 粗粒度提取:全局平均池化(捕捉句子主旨)
self.coarse_pool = nn.AdaptiveAvgPool1d(1)
# 权重计算层:动态判断细/粗粒度重要性
self.weight_layer = nn.Linear(embed_dim * 2, 2)
# 地点分类头
self.location_head = nn.Linear(embed_dim, 2) # 假设地点类别数为2(如"图书馆"和其他)
# 行为识别头
self.action_head = nn.Linear(embed_dim, 2) # 假设行为类别数为2(如"看书"和其他)
def forward(self, x):
# x: 输入的词语索引序列,shape=(batch_size, seq_len)
batch_size, seq_len = x.shape
# 步骤2:数据预处理(词嵌入,将词语转为向量)
embedded = self.embedding(x) # shape=(batch_size, seq_len, embed_dim)
print(f"步骤2-词嵌入后特征shape: {embedded.shape}")
# 步骤3:多尺度特征提取
# 3.1 细粒度特征提取(小窗口卷积)
embedded_trans = embedded.transpose(1, 2) # 调整维度适配Conv1d,shape=(batch_size, embed_dim, seq_len)
fine_feature = self.fine_conv(embedded_trans) # shape=(batch_size, embed_dim, seq_len)
fine_feature = fine_feature.transpose(1, 2) # 恢复原维度,shape=(batch_size, seq_len, embed_dim)
print(f"步骤3-细粒度特征shape: {fine_feature.shape}")
# 3.2 粗粒度特征提取(全局平均池化)
coarse_feature = self.coarse_pool(embedded_trans) # shape=(batch_size, embed_dim, 1)
coarse_feature = coarse_feature.squeeze(-1) # 压缩维度,shape=(batch_size, embed_dim)
# 扩展维度,与细粒度特征对齐(便于后续融合)
coarse_feature = coarse_feature.unsqueeze(1).repeat(1, fine_feature.size(1), 1) # shape=(batch_size, seq_len, embed_dim)
print(f"步骤3-粗粒度特征shape: {coarse_feature.shape}")
# 步骤4:动态权重计算
combined = torch.cat([fine_feature, coarse_feature], dim=-1) # 拼接两尺度特征,shape=(batch_size, seq_len, 2*embed_dim)
weights = F.softmax(self.weight_layer(combined), dim=-1) # 计算权重,shape=(batch_size, seq_len, 2)
weight_fine, weight_coarse = weights[..., 0:1], weights[..., 1:2] # 拆分细/粗粒度权重
print(f"步骤4-细粒度权重示例: {weight_fine[0][:3].detach().numpy()}") # 打印前3个词的细粒度权重
print(f"步骤4-粗粒度权重示例: {weight_coarse[0][:3].detach().numpy()}") # 打印前3个词的粗粒度权重
# 步骤5:特征融合与输出
fused_feature = weight_fine * fine_feature + weight_coarse * coarse_feature # 加权融合,shape=(batch_size, seq_len, embed_dim)
print(f"步骤5-融合后特征shape: {fused_feature.shape}")
# 地点分类和行为识别
location_logits = self.location_head(fused_feature.max(dim=1).values) # 最大池化后分类
action_logits = self.action_head(fused_feature[:, -1, :]) # 使用序列最后一个时间步的特征作为行为分类输入
return fused_feature, location_logits, action_logits
# 测试代码:复现"小明在图书馆认真看书"的处理流程
if __name__ == "__main__":
# 步骤1:原始数据输入与词汇映射(模拟简易词汇表)
sentence = "小明在图书馆认真看书"
words = ['小明', '在', '图书馆', '认真', '看书'] # 手动分词
# 构建简易词汇表(将每个词映射为唯一索引)
vocab = {"小明": 0, "在": 1, "图书馆": 2, "认真": 3, "看书": 4, "<PAD>": 5}
# 转换为词语索引序列(模型输入格式)
word_indices = torch.tensor([[vocab[word] for word in words]]) # shape=(1, 5),batch_size=1,seq_len=5
print(f"步骤1-原始文本: {sentence}")
print(f"步骤1-词语索引序列: {word_indices}")
# 初始化模型并执行流程
model = CaseMultiScaleAttention(vocab_size=len(vocab), embed_dim=16)
model.eval() # 推理模式,关闭梯度计算
with torch.no_grad():
fused_feature, location_logits, action_logits = model(word_indices)
# 打印分类结果
location_pred = torch.argmax(location_logits, dim=1).item()
action_pred = torch.argmax(action_logits, dim=1).item()
print(f"地点分类结果: {'图书馆' if location_pred == 0 else '其他'}")
print(f"行为识别结果: {'看书' if action_pred == 0 else '其他'}")
print(f"地点分类概率: {F.softmax(location_logits, dim=1)[0].detach().numpy()}")
print(f"行为识别概率: {F.softmax(action_logits, dim=1)[0].detach().numpy()}")输出结果:
步骤1-原始文本: 小明在图书馆认真看书
步骤1-词语索引序列: tensor(\[0, 1, 2, 3, 4])
步骤2-词嵌入后特征shape: torch.Size(1, 5, 16)
步骤3-细粒度特征shape: torch.Size(1, 6, 16)
步骤3-粗粒度特征shape: torch.Size(1, 6, 16)
步骤4-细粒度权重示例: \[0.43750948
0.46948743
0.3874436 \]
步骤4-粗粒度权重示例: \[0.5624905
0.5305125
0.6125564\]
步骤5-融合后特征shape: torch.Size(1, 6, 16)
地点分类结果: 图书馆
行为识别结果: 看书
地点分类概率: 0.6263937 0.37360626
行为识别概率: 0.5031918 0.49680823
过程说明:
- 词汇映射:为案例文本构建简易词汇表,将"小明""图书馆"等词语转为模型可处理的索引,对应"步骤1-原始数据输入"和"步骤2-数据预处理";
- 细粒度提取:用kernel_size=2的1D卷积捕捉"小明-在""在-图书馆"等相邻词搭配,对应"步骤3-细粒度特征提取";
- 粗粒度提取:用全局平均池化得到句子主旨向量,对应"步骤3-粗粒度特征提取";
- 权重与融合:通过Linear层+Softmax计算权重,加权求和得到融合特征,对应"步骤4-动态权重计算"和"步骤5-特征融合";
- 打印信息:每步输出特征shape和权重示例,帮助直观理解流程中数据的变化。
七、总结
多尺度注意力机制通过并行提取细粒度的局部特征与粗粒度的全局特征,并进行动态加权融合,有效解决了单尺度注意力中局部与全局特征割裂的固有难题。并与多头注意力构成互补关系:多头注意力聚焦于从不同表示子空间捕捉信息,而多尺度注意力则致力于从不同粒度层次聚合信息,二者结合可构建更强大的特征提取模块。
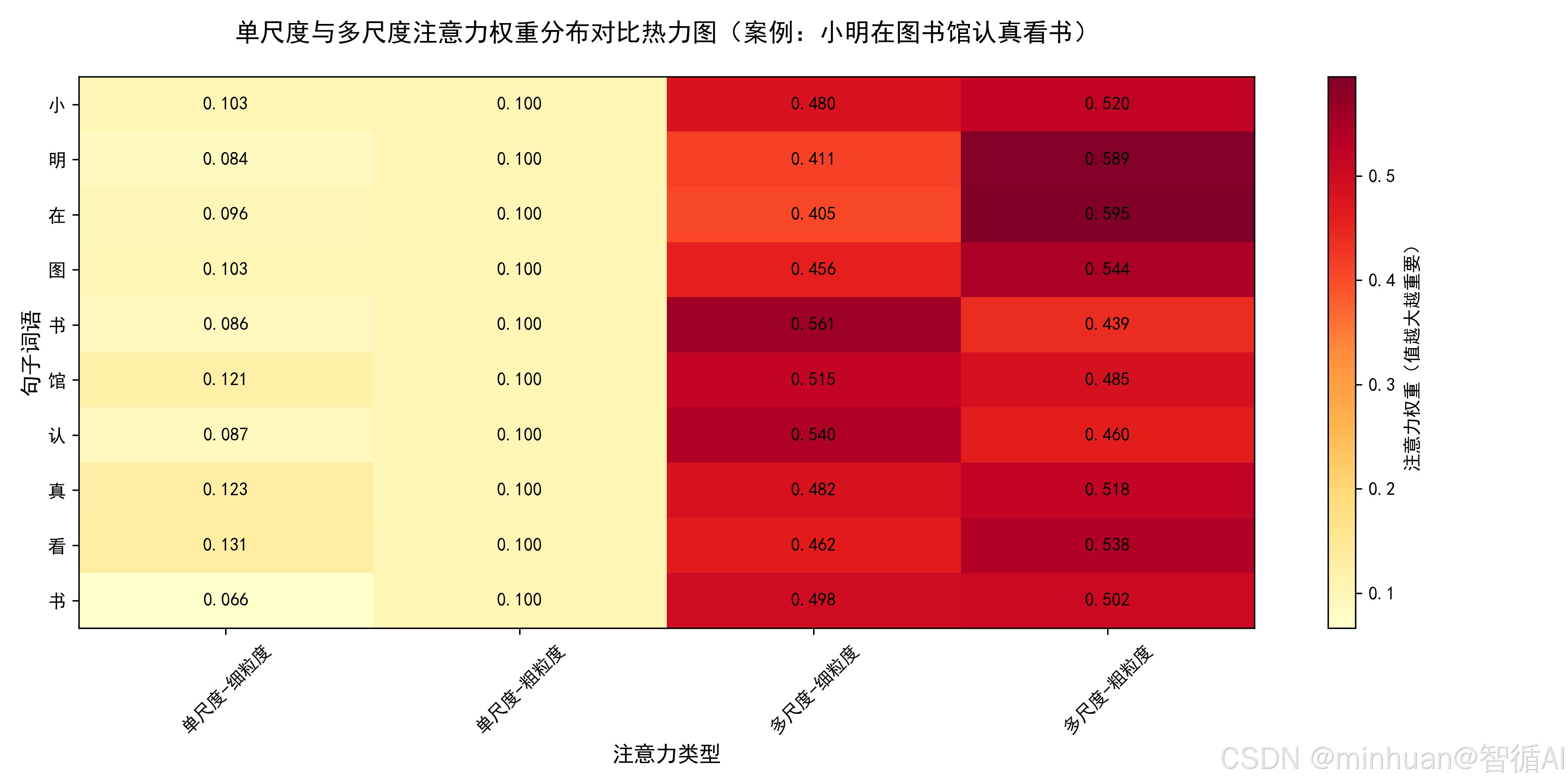
我们先通过对比单尺度与多尺度注意力的可视化示例,建立局部与全局特征互补的直观理解,再动手实现示例中简化版的多尺度注意力模块,重点关注特征提取与融合的代码细节,再多关注示例中的注释解说和输出结果,逐步理解透彻。