完整代码:
python
import numpy as np
import re
import pandas as pd
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import LatentDirichletAllocation
df1 = pd.read_csv('小红书评论.csv') # 读取同目录下csv文件
# df1 = df1.drop_duplicates(subset=['用户id']) # 获取一个id只评论一次的数据
pattern = u'[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;""''{}【】()...¥!---┄-]+'
df1['cut'] = df1['内容'].apply(lambda x: str(x))
df1['cut'] = df1['cut'].apply(lambda x: re.sub(pattern, ' ', x)) #对评论内容作清洗,只保留中文汉字,生成新的cut行
df1['cut'] = df1['cut'].apply(lambda x: " ".join(jieba.lcut(x))) #对评论内容作分词和拼接
print(df1['cut'])
print(type(df1['cut']))
# 1.构造TF-IDF
tf_idf_vectorizer = TfidfVectorizer()
tf_idf = tf_idf_vectorizer.fit_transform(df1['cut'])
# 2.特征词列表
feature_names = tf_idf_vectorizer.get_feature_names_out()
# 3.将特征矩阵转变为pandas DataFrame
matrix = tf_idf.toarray()
feature_names_df = pd.DataFrame(matrix,columns=feature_names)
print(feature_names_df)
# 所有的特征词组成列,所有的评论组成行,矩阵中的元素表示这个特征词在该评论中所占的重要性,即tf-idf值,0表示该句评论中没有该词。
n_topics = 5
# 定义LDA对象
lda = LatentDirichletAllocation(
n_components=n_topics,max_iter=50,
learning_method='online',
learning_offset=50.,
random_state=0
)
# 核心,将TF-IDF矩阵放入LDA模型中
lda.fit(tf_idf)
#第1部分
# 要输出的每个主题的前 n_top_words 个主题词数
n_top_words = 50
def top_words_data_frame(model: LatentDirichletAllocation,
tf_idf_vectorizer: TfidfVectorizer,
n_top_words: int) -> pd.DataFrame:
rows = []
feature_names = tf_idf_vectorizer.get_feature_names_out()
for topic in model.components_:
top_words = [feature_names[i]
for i in topic.argsort()[:-n_top_words - 1:-1]]
rows.append(top_words)
columns = [f'topic {i + 1}' for i in range(n_top_words)]
df = pd.DataFrame(rows, columns=columns)
return df
#2
def predict_to_data_frame(model: LatentDirichletAllocation, X: np.ndarray) -> pd.DataFrame:
matrix = model.transform(X)
columns = [f'P(topic {i + 1})' for i in range(len(model.components_))]
df = pd.DataFrame(matrix, columns=columns)
return df
# 要输出的每个主题的前 n_top_words 个主题词数
# 计算 n_top_words 个主题词
top_words_df = top_words_data_frame(lda, tf_idf_vectorizer, n_top_words)
# 获取五个主题的前五十个特征词
print(top_words_df)
# 转 tf_idf 为数组,以便后面使用它来对文本主题概率分布进行计算
X = tf_idf.toarray()
# 计算完毕主题概率分布情况
predict_df = predict_to_data_frame(lda, X)
# 获取五个主题,对于每个评论,分别属于这五个主题的概率
print(predict_df)
import pyLDAvis
import pyLDAvis.sklearn
panel = pyLDAvis.sklearn.prepare(lda, tf_idf, tf_idf_vectorizer)
pyLDAvis.save_html(panel, 'lda_visualization.html')
pyLDAvis.display(panel)一、数据清洗
代码逐行讲解:
python
df1 = pd.read_csv('小红书评论.csv') # 读取同目录下csv文件
# df1 = df1.drop_duplicates(subset=['用户id']) # 获取一个id只评论一次的数据
pattern = u'[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;""''{}【】()...¥!---┄-]+'
df1['cut'] = df1['内容'].apply(lambda x: str(x))
df1['cut'] = df1['cut'].apply(lambda x: re.sub(pattern, ' ', x)) #对评论内容作清洗,只保留中文汉字,生成新的cut行
df1['cut'] = df1['cut'].apply(lambda x: " ".join(jieba.lcut(x))) #对评论内容作分词和拼接
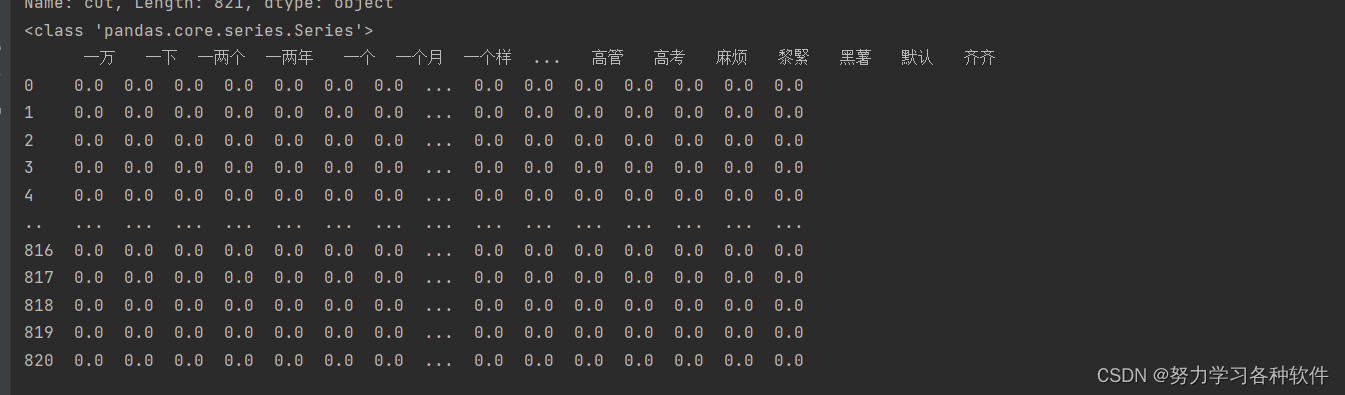
print(df1['cut'])
print(type(df1['cut']))读取同目录下的文件,df1是数据框格式
提取评论内容,并对评论内容做清洗,采用正则表达式,去除标点和英文。
用jieba对每一行的数据作分词处理,最后得到的数据展现以及数据类型。

二、模型构建
python
tf_idf_vectorizer = TfidfVectorizer()
tf_idf = tf_idf_vectorizer.fit_transform(df1['cut'])
# 2.特征词列表
feature_names = tf_idf_vectorizer.get_feature_names_out()
# 3.将特征矩阵转变为pandas DataFrame
matrix = tf_idf.toarray()
feature_names_df = pd.DataFrame(matrix,columns=feature_names)
print(feature_names_df)
# 所有的特征词组成列,所有的评论组成行,矩阵中的元素表示这个特征词在该评论中所占的重要性,即tf-idf值,0表示该句评论中没有该词。
# 定义LDA对象
n_topics = 5
lda = LatentDirichletAllocation(
n_components=n_topics, max_iter=50,
learning_method='online',
learning_offset=50.,
random_state=0
)
# 核心,将TF-IDF矩阵放入LDA模型中
lda.fit(tf_idf)-
tf_idf_vectorizer = TfidfVectorizer()- 这行代码创建了一个
TfidfVectorizer对象,这是scikit-learn库中的一个文本向量化工具。它将文本数据转换为TF-IDF特征矩阵,这是一种常用的文本表示形式,能够反映出文本中单词的重要性。
- 这行代码创建了一个
-
tf_idf = tf_idf_vectorizer.fit_transform(df1['cut'])- 这行代码执行了两个操作:
fit: 根据提供的文本数据(df1['cut'])来学习词汇表和计算IDF(逆文档频率)。transform: 使用学习到的词汇表和IDF来转换文本数据为TF-IDF矩阵。结果tf_idf是一个稀疏矩阵,其中每一行代表一个文档,每一列代表一个单词,矩阵中的值表示该单词在文档中的重要性(TF-IDF权重)。
- 这行代码执行了两个操作:
-
# 定义LDA对象- 这是一个注释行,说明接下来的代码将定义一个LDA(隐狄利克雷分配)模型对象。
-
n_topics = 5- 这行代码设置了一个变量
n_topics,其值为5,表示LDA模型中的主题数量。
- 这行代码设置了一个变量
-
lda = LatentDirichletAllocation( ...)- 这行代码创建了一个
LatentDirichletAllocation对象,即LDA模型,用于主题建模。它接受多个参数:n_components=n_topics: 设置模型中的主题数量,这里与之前定义的n_topics变量相等。max_iter=50: 设置模型训练的最大迭代次数。learning_method='online': 指定学习算法,这里使用在线学习算法。learning_offset=50.: 在线学习算法中的学习偏移量。random_state=0: 设置随机状态,以确保结果的可重复性。
- 这行代码创建了一个
-
lda.fit(tf_idf)- 这行代码将之前转换得到的TF-IDF矩阵
tf_idf用于训练LDA模型。fit方法将根据文档-词项矩阵和设置的主题数量来学习文档的主题分布以及词项在各个主题下的分布。
- 这行代码将之前转换得到的TF-IDF矩阵
总的来说,这段代码的目的是使用LDA模型来发现文档集合中的潜在主题。首先,它通过TF-IDF向量化器将文本数据转换为数值矩阵,然后使用这个矩阵来训练LDA模型,最后可以通过模型来分析文档的主题分布。
打印出来的结果为:
三、结果展现
python
#第1部分
# 要输出的每个主题的前 n_top_words 个主题词数
n_top_words = 50
def top_words_data_frame(model: LatentDirichletAllocation,
tf_idf_vectorizer: TfidfVectorizer,
n_top_words: int) -> pd.DataFrame:
rows = []
feature_names = tf_idf_vectorizer.get_feature_names_out()
for topic in model.components_:
top_words = [feature_names[i]
for i in topic.argsort()[:-n_top_words - 1:-1]]
rows.append(top_words)
columns = [f'topic {i + 1}' for i in range(n_top_words)]
df = pd.DataFrame(rows, columns=columns)
return df
#2
def predict_to_data_frame(model: LatentDirichletAllocation, X: np.ndarray) -> pd.DataFrame:
matrix = model.transform(X)
columns = [f'P(topic {i + 1})' for i in range(len(model.components_))]
df = pd.DataFrame(matrix, columns=columns)
return df
# 要输出的每个主题的前 n_top_words 个主题词数
# 计算 n_top_words 个主题词
top_words_df = top_words_data_frame(lda, tf_idf_vectorizer, n_top_words)
# 获取五个主题的前五十个特征词
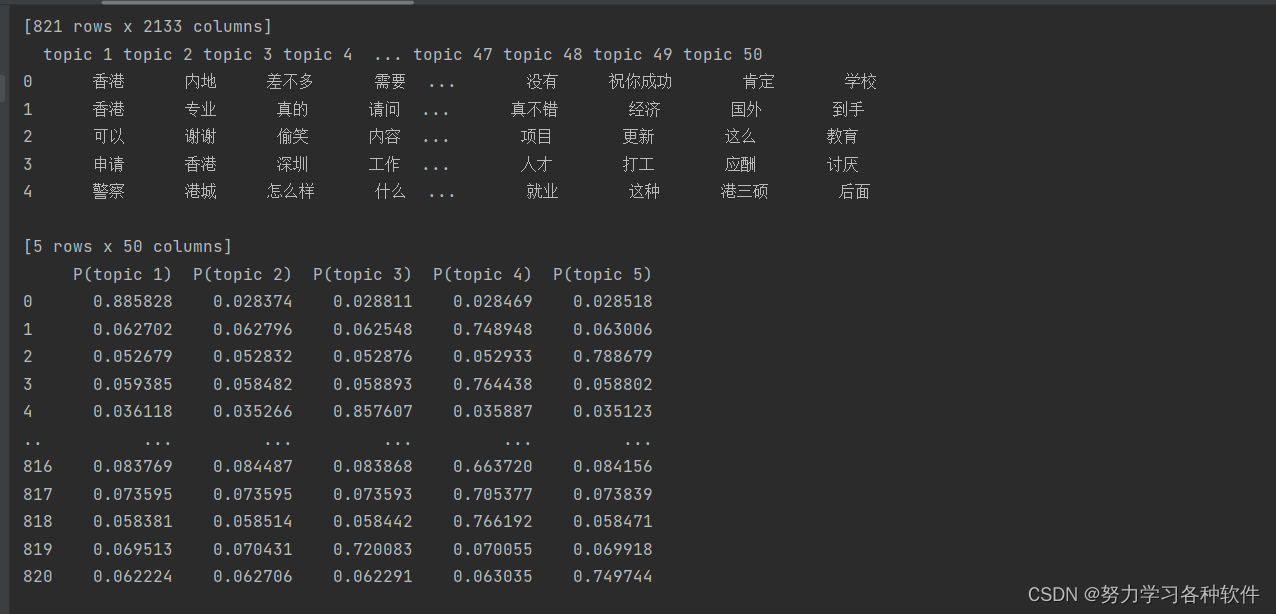
print(top_words_df)
# 转 tf_idf 为数组,以便后面使用它来对文本主题概率分布进行计算
X = tf_idf.toarray()
# 计算完毕主题概率分布情况
predict_df = predict_to_data_frame(lda, X)
# 获取五个主题,对于每个评论,分别属于这五个主题的概率
print(predict_df)这段代码是用于分析和可视化LDA(Latent Dirichlet Allocation,隐狄利克雷分配)模型的输出结果的。以下是对代码的逐行解释:
这部分代码定义了两个函数,用于处理和展示LDA模型的结果。
-
n_top_words = 50- 设置变量
n_top_words为50,表示每个主题中要提取的前50个最重要的词。
- 设置变量
-
def top_words_data_frame(...) -> pd.DataFrame:- 定义了一个名为
top_words_data_frame的函数,它接受一个LDA模型、一个TF-IDF向量化器和一个整数n_top_words作为参数,并返回一个包含每个主题的前n_top_words个词的DataFrame。
- 定义了一个名为
-
rows = []- 初始化一个空列表
rows,用于存储每个主题的顶级词汇。
- 初始化一个空列表
-
feature_names = tf_idf_vectorizer.get_feature_names_out()- 从TF-IDF向量化器中获取词汇表,以便知道每个特征索引对应的词。
-
for topic in model.components_:- 遍历LDA模型的每个主题。
-
top_words = [feature_names[i] for i in topic.argsort()[:-n_top_words - 1:-1])- 对每个主题,获取其权重数组的排序索引,然后选择前
n_top_words个索引对应的词。
- 对每个主题,获取其权重数组的排序索引,然后选择前
-
rows.append(top_words)- 将每个主题的顶级词汇列表添加到
rows列表中。
- 将每个主题的顶级词汇列表添加到
-
columns = [f'topic {i + 1}' for i in range(n_top_words)]- 创建DataFrame的列名,表示每个主题的顶级词汇。
-
df = pd.DataFrame(rows, columns=columns)- 使用
rows数据和columns列名创建一个DataFrame。
- 使用
-
return df- 返回包含每个主题顶级词汇的DataFrame。
这部分代码使用LDA模型对文档进行主题预测,并展示结果。
-
def predict_to_data_frame(model: LatentDirichletAllocation, X: np.ndarray) -> pd.DataFrame:- 定义了一个名为
predict_to_data_frame的函数,它接受一个LDA模型和一个NumPy数组X作为参数,并返回一个包含文档主题概率分布的DataFrame。
- 定义了一个名为
-
matrix = model.transform(X)- 使用LDA模型的
transform方法将文档集X转换为每个文档的主题概率分布矩阵。
- 使用LDA模型的
-
columns = [f'P(topic {i + 1})' for i in range(len(model.components_))]- 创建列名,表示每个文档属于每个主题的概率。
-
df = pd.DataFrame(matrix, columns=columns)- 使用转换得到的主题概率矩阵和列名创建一个DataFrame。
-
return df- 返回包含文档主题概率分布的DataFrame。
这部分代码执行了上述定义的函数,并打印了结果。
-
top_words_df = top_words_data_frame(lda, tf_idf_vectorizer, n_top_words)- 调用
top_words_data_frame函数,获取LDA模型的每个主题的前50个词。
- 调用
-
print(top_words_df)- 打印每个主题的前50个词。
-
X = tf_idf.toarray()- 将TF-IDF矩阵转换为一个NumPy数组,以便用于主题预测。
-
predict_df = predict_to_data_frame(lda, X)- 调用
predict_to_data_frame函数,获取文档的主题概率分布。
- 调用
-
print(predict_df)- 打印每个文档属于每个主题的概率。
这段代码的目的是分析LDA模型的结果,展示每个主题的代表性词汇以及文档的主题概率分布,从而帮助理解文档集合中的潜在主题结构。
四、可视化分析
python
# 获取五个主题,对于每个评论,分别属于这五个主题的概率
print(predict_df)
import pyLDAvis
import pyLDAvis.sklearn
panel = pyLDAvis.sklearn.prepare(lda, tf_idf, tf_idf_vectorizer)
pyLDAvis.save_html(panel, 'lda_visualization.html')
pyLDAvis.display(panel)结果展现:
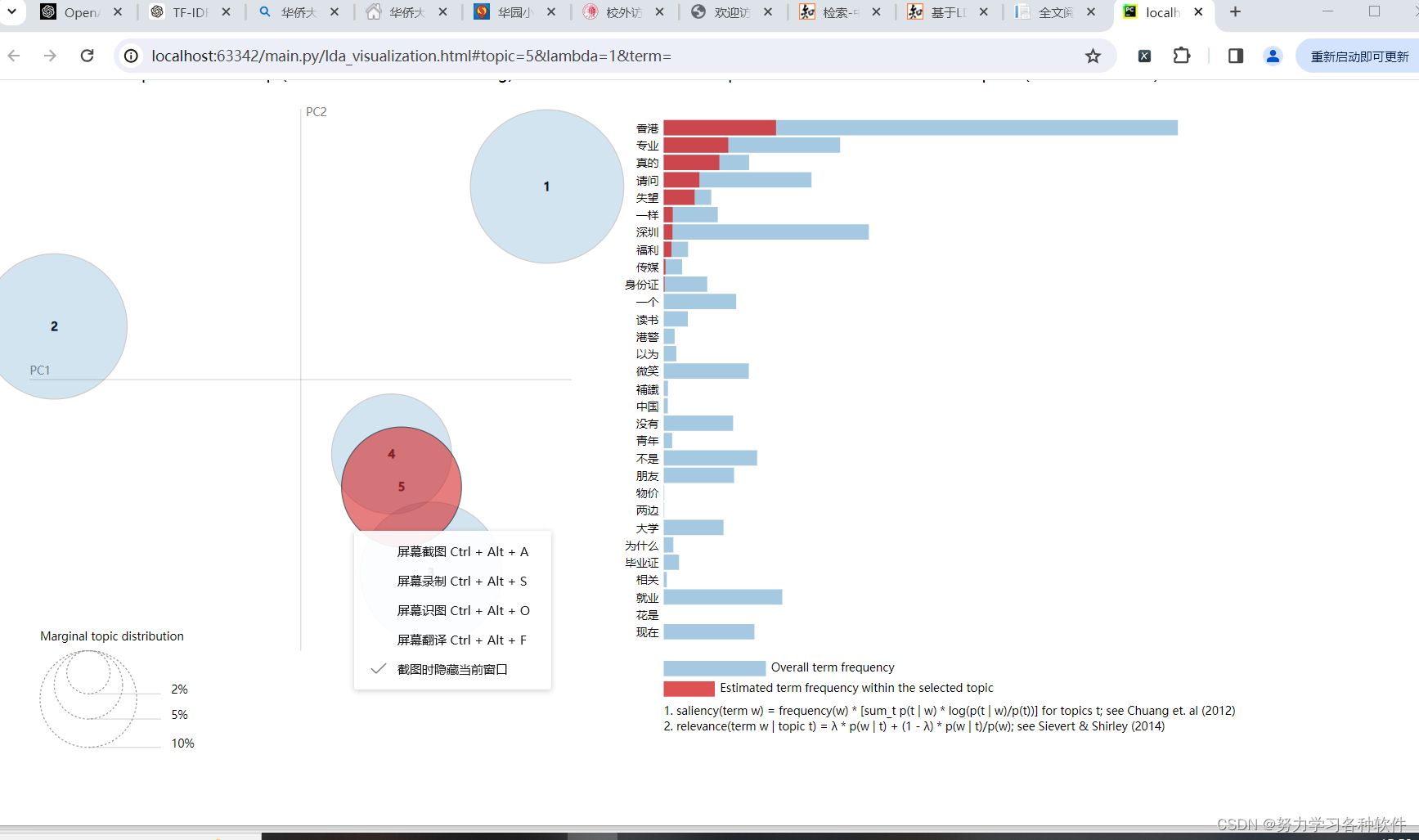
五、词云图分析
另写代码,加入停用词后,对数据内容作词云图分析:
python
import numpy as np
import re
import pandas as pd
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import LatentDirichletAllocation
from wordcloud import WordCloud # 导入 WordCloud 类
import matplotlib.pyplot as plt
# 读取小红书评论数据
df1 = pd.read_csv('小红书评论.csv')
pattern = u'[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;""''{}【】()...¥!---┄-]+'
df1['cut'] = df1['内容'].apply(lambda x: str(x))
df1['cut'] = df1['cut'].apply(lambda x: re.sub(pattern, ' ', x))
# 定义停用词列表,将你、了、的、我、你等常见词加入其中
stop_words = set(['你', '了', '的', '我', '你', '他', '她', '它','是','有','哭','都','吗','也','啊'])
# 分词并过滤停用词
df1['cut'] = df1['cut'].apply(lambda x: " ".join([word for word in jieba.lcut(x) if word not in stop_words]))
# 生成小红书评论的词云图
def generate_wordcloud(text):
wordcloud = WordCloud(background_color='white', font_path='msyh.ttc').generate(text)
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.title("小红书评论词云")
plt.axis("off")
plt.show()
# 获取小红书评论的文本
all_comments_text = ' '.join(df1['cut'])
# 生成词云图
generate_wordcloud(all_comments_text)结果展现:
数据我在上方绑定了,需要可自取。