1.概述
- 将数据库表中的一列或者多列的值进行排序存储;
- 用索引表记录字段的索引和偏移量,方便查询索引列时能快速定位到对应的行记录;
- 索引类似于图书的目录,可以根据目录页码快速定位。
2.执行流程
(1)不使用索引时,hive执行流程
sql
SELECT * FROM test_table WHERE key='xx'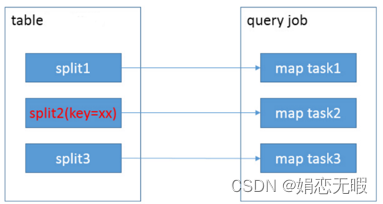
(2)使用索引时,hive执行流程

3.使用场景
- 对于查询中经常被当做WHERE子句的判断条件的列;
- 值不经常更新的列或者值是几个枚举值的列。
- Hive3.0开始,索引将被移除,但提供了与索引类似的功能:
使用带有自动重写的物化视图 ;选择列式的文件格式(ORC),它们可以进行选择性扫描,甚至可以跳过整个文件块 。
4.Hive索引与分区、分桶的区别!
- Hive索引与分区、分桶都是Hive的优化手段;
- 索引时使用额外的存储空间换取查询时间;
- 分区是将大的数据库按分区字段拆分成多个小数据库,对应HDFS上不同的文件夹;
- 分桶是按照列的哈希函数进行分隔,对应于HDFS不同的文件。
5.索引操作
(1)创建索引
sql
#其中ROW FORMAT,STORED AS,STORED BY, LOCATION, PARTITION BY 等子句参照创建表的语法
#AS子句指定了索引处理器,Hive内置的索引处理器有CompactIndexHandler和BitMap
#WITH DEFERRED REBUILD延迟重建标识,指定该处,新索引将呈现空白状态,在任何时间用户都可 #以进行第一次索引创建或者使用ALTER INDEX对索引进行重建。
#IN TABLE 指定索引表的名称,可选值,如果不指定,Hive会默认生成索引表名。
CREATE INDEX index_name
ON TABLE base_table_name(col_name,...)
AS 'index.handler.class.name'
[WITH DEFERRED REBUILD]
[IDXPROPERTIES(property_name=property_value,...)]
[IN TABLE index_table_name]
[PARTITION BY (col_name,...)]
[
[ROW FORMAT ...] STORED AS ...
| STORED BY...
]
[LOCATION hdfs_path]
[TBLPROPERTIES(...)]
[COMMENT "index comment"];(2)重建索引
sql
#使用ALTER INDEX命令可以重建索引,该语句主要用于重建使用"WITH DEFERRED REBUILD"子句创建的索引,或 #者重建已经创建的索引,如果制定了分区,则仅重新构建指定分区的索引
ALTER INDEX index_name ON table_name [PARTITION partition_spec] REBUILD;(3)显示索引/删除索引
sql
#索引创建后,可以使用SHOW INDEX命令查看索引
SHOW [FORMATTED] (INDEX|INDEXES) ON table_with_index [(FROM|IN)db_name];
#删除索引可以使用DROP INDEX语句
DROP INDEX [IF EXISTS] index_name ON table_name;6.元数据表IDXS
Hive元数据表IDXS包含每个索引创建的实例信息,并且记录了与元数据表TBLS的关联信息。
|---------------------|---------|--------------------------------------------------------------|
| 元数据表字段 | 说明 | 实例数据 |
| INDEX_ID | 索引ID | 3 |
| CREATE_TIME | 创建时间 | 1545118376 |
| DEFERRED_REBUILD | 延迟重建标识 | 空 |
| INDEX_HANDLER_CLASS | 索引处理类 | org.apache.hadoop.hive.ql.index. compact.CompactIndexHandler |
| INDEX_NAME | 索引名字 | order_item_product_id_index |
| INDEX_TBL_ID | 索引表的ID | 788 |
| LAST_ACCESS_TIME | 最后访问时间 | 1545118376 |
| ORIG_TBL_ID | 原始表的ID | 782 |
| SD_ID | 序列化配置信息 | 791 |
7.元数据表INDEX_PARAMS
INDEX_PARAMS表包含每个索引的属性信息
|-------------|------|----------------|
| 元数据表字段 | 说明 | 实例数据 |
| INDEX_ID | 索引ID | 3 |
| PARAM_KEY | 属性名 | base_timestamp |
| PARAM_VALUE | 属性值 | 1545047366911 |
8.其他
(1)row group index(行组索引)

(2) Bloom Filter Index(布隆过滤索引)

在建表时候,通过表参数"orc.bloom.filter.columns"="pcid"来指定为那些字段建立BloomFilter索引,这样,在生成数据的时候,会在每个stripe中,为该字段建立BloomFilter的数据结构,当查询条件中包含对该字段的=号过滤时候,先从BloomFilter中获取以下是否包含该值,如果不包含,则跳过该stripe。