主要通过宽度优先搜索(BFS)来实现有向无环图的拓扑序列,邻接表存储图。数组模拟单链表、队列,实现BFS基本操作。
前言
主要通过宽度优先搜索(BFS)来实现有向无环图的拓扑序列,邻接表存储图。数组模拟单链表、队列,实现BFS基本操作。
提示:以下是本篇文章正文内容,下面案例可供参考
一、有向图的拓扑序列
给定一个 n 个点 m 条边的有向图,点的编号是 1 到 n,图中可能存在重边和自环。
请输出任意一个该有向图的拓扑序列,如果拓扑序列不存在,则输出 −1。
若一个由图中所有点构成的序列 A 满足:对于图中的每条边 (x,y),x 在 A 中都出现在 y 之前,则称 A 是该图的一个拓扑序列。
输入格式
第一行包含两个整数 n 和 m。
接下来 m 行,每行包含两个整数 x 和 y,表示存在一条从点 x 到点 y 的有向边 (x,y)。
输出格式
共一行,如果存在拓扑序列,则输出任意一个合法的拓扑序列即可。
否则输出 −1。
数据范围
1≤n,m≤100000
二、算法思路
1.拓扑序列
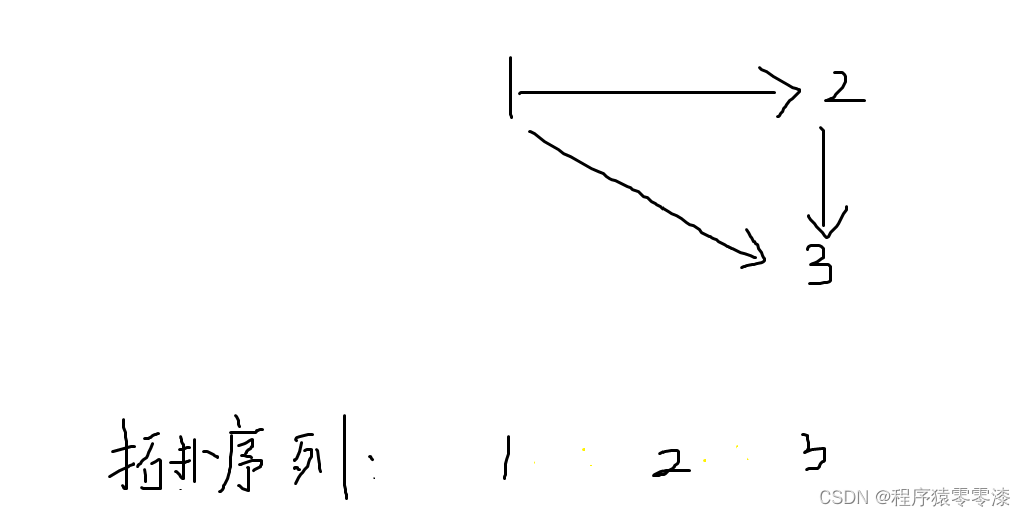
图1.1拓扑序列示例
有向图的拓扑排序是指将有向无环图(DAG)中的所有顶点排成一个线性序列,使得对于图中的每一条有向边 (u, v),顶点 u 在序列中都出现在顶点 v 的前面。换句话说,如果图中存在一条从顶点 u 到顶点 v 的有向边,那么在拓扑排序中顶点 u 将在顶点 v 的前面。
在有向图中,每个顶点都有两种相关的度量:入度(in-degree)和出度(out-degree)。这些度量用于描述有向图中顶点之间的关系。
-
入度:一个顶点的入度是指指向该顶点的边的数量。换句话说,对于顶点v,它的入度是有多少条边以v为终点。
-
出度:一个顶点的出度是指从该顶点发出的边的数量。换句话说,对于顶点v,它的出度是有多少条边以v为起点。
|----|----|----|
| 结点 | 入度 | 出度 |
| 1 | 0 | 2 |
| 2 | 1 | 1 |
| 3 | 2 | 0 |
[各结点出入度示例]
一个有向无环图一定至少存在一个入度为0的点。
开始入度为0的结点都是初始结点,然后当我们打印该结点,就将它指向的结点的入度擦去,然后我们在找入度为0的结点当作下一个结点重复上述操作,我们就可以得到该有向无环图的拓扑序列。
本次用宽度优先搜索来实现有向图的拓扑序列!
注:有向无环图才有拓扑序列,无向图是没有的。

2.算法思路
我们采用宽度优先搜索来实现上述操作。我们还是用邻接表法来存储图。我们还是用一维整型数组head,其中headi表示结点i相连的边,对应的边用单链表存储;还是用数组来模拟单链表,一维整型数组e用来存储结点的值,一维整型数组存储该结点指向的下一结点在e数组中的索引,整型变量index表示新创建的结点在e数组中的索引。
添加a指向b边我们只需要在head数组中对应结点 a 的单链表中插入结点 b 即可。单链表的插入具体细节请看这篇博客单链表-java-CSDN博客。
java
public static void add(int a, int b){
e[index] = b;
ne[index] = head[a];
head[a] = index++;
}数组模拟单链表是基础!!!
我们引入一个一维整型数组d,来存储图中每个点的入度;一维整型数组queue来模拟队列,整型变量hh时队头指针,整型变量rear时队尾指针。当这个点的入度为0时,我们就把它当作拓扑序列的起点,放入队列;当队列不为空时,我们弹出一个结点即t**= queuehh++** ;我们来遍历与结点 t相连的点,找到与结点 t 相连的点 j ,将结点 j 对应的入度减1 即 dj-- ;如果该结点的入度为0的话,就说明该结点没有上一个结点指向它,我们就让它入队。当队列为空时,如果我们的队尾指针等于n -1 的话就说明我们已经找出对应的拓扑序列。如果图中存在环的话,那么我们我们的队列为空的时候,队尾指针根本不可能到 n-1,一定比这个值小。
拓扑序列的本质就是我们每次把入度为0的结点打印出来,然后该结点指向的所有的结点的入度减1,然后再打印入度为0的结点。
所以拓扑排序就是对应队列数组从0到n - 1打印即可。

三、使用步骤
1.代码如下(示例):
c
import java.io.*;
import java.util.Arrays;
public class Main {
static PrintWriter pw = new PrintWriter(new BufferedWriter(new OutputStreamWriter(System.out)));
static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
static StreamTokenizer st = new StreamTokenizer(br);
static int n,m;
static int N = 100100;
static int[] head = new int[N];
static int[] e = new int[N];
static int[] ne = new int[N];
static int index;
//存储每个点的入度
static int[] d = new int[N];
static int[] queue = new int[N];
public static void main(String[] args) throws Exception{
n = nextInt();
m = nextInt();
Arrays.fill(head,-1);
while (m-- > 0){
int a = nextInt();
int b = nextInt();
add(a,b);
d[b]++;
}
if(topSort()){
for(int i = 0;i < n;i++){
pw.print(queue[i]+" ");
}
}else {
pw.println("-1");
}
pw.flush();
}
public static boolean topSort(){
int hh = 0;
int rear = -1;
//将起点放入队列
for(int i = 1;i <= n;i++){
if(d[i] == 0){
queue[++rear] = i;
}
}
while (hh <= rear){
int t = queue[hh++];
for(int i = head[t]; i != -1;i = ne[i]){
//t指向j
int j = e[i];
d[j]--;
if(d[j] == 0){
queue[++rear] = j;
}
}
}
return rear == n - 1;
}
public static void add(int a, int b){
e[index] = b;
ne[index] = head[a];
head[a] = index++;
}
public static int nextInt()throws Exception {
st.nextToken();
return (int)st.nval;
}
}2.读入数据:
c
3 3
1 2
2 3
1 33.代码运行结果
java
1 2 3 总结
上述主要通过宽度优先搜索来实现有向无环图的拓扑序列,其中还是很常用的邻接表存储图。数组模拟单链表、队列,然后宽度优先搜索3部曲,大致就这些。