一、一个让人心动的问题
2023年初,GPT-4V发布后不久,我们接到一个老客户的电话。
他是某家电企业的技术负责人,两年前我们帮他们上了一套基于YOLOv5的外观检测系统,跑得一直不错。
电话里他问了一个问题:
"我看GPT-4V能看懂各种图片,什么都能识别。我们能不能直接用它做质检?这样是不是就不用标数据了?"
我当时没有直接回答。
因为说实话,我们自己也心动了。
多模态大模型的Demo确实惊艳------你随便给它一张图,它能告诉你图里有什么、哪里有问题、是什么类型的问题。不需要训练,不需要标注,Zero-shot就能用。
如果这是真的,那工业视觉检测这件事的游戏规则就要彻底改变了。
我们花了将近两年时间,在好几个项目里试了各种多模态大模型方案。
结论是:心动归心动,但现实很骨感。
这篇文章,就是把这两年的踩坑经验写出来。
二、先搞清楚现状:YOLO已经是事实标准
在聊多模态大模型之前,先明确一个背景:
当前工业视觉检测的主流方案,是以YOLO系列为代表的目标检测/分割模型。
这不是什么新鲜事。从YOLOv3开始,到现在的YOLOv8、YOLOv9、YOLOv10,YOLO系列在工业场景已经跑了好几年,技术栈非常成熟。
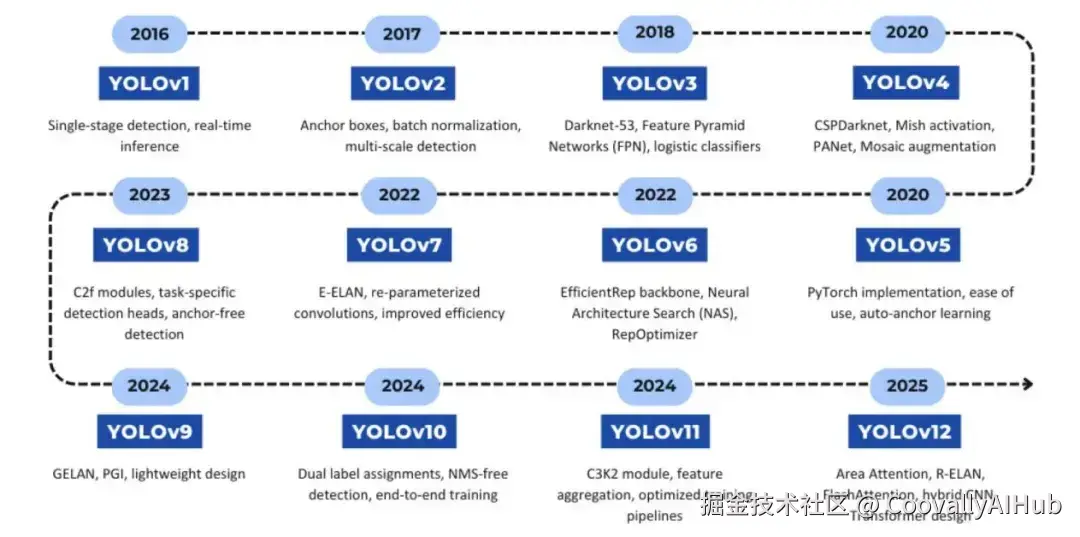
为什么YOLO能成为事实标准?
第一,速度够快。
YOLOv8在普通工业相机配的边缘计算盒子上,推理一张图可以做到10-30毫秒。这个速度能匹配绝大多数产线的节拍。
第二,精度够用。
在有足够标注数据的情况下,YOLO系列对常见缺陷类型的检测精度可以做到很高。mAP 90%以上不是什么难事。
第三,部署成熟。
ONNX、TensorRT、OpenVINO,各种部署方案都有现成的工具链。从训练到部署,整个流程已经被无数项目验证过。
第四,生态完善。
开源社区活跃,遇到问题基本都能搜到解决方案。预训练模型、数据增强工具、标注工具,一应俱全。
所以,2024年如果你要做工业视觉检测,YOLO系列几乎是默认选项。
不需要讨论"要不要用深度学习"------这个问题十年前就有答案了。
现在的问题是:多模态大模型出来之后,YOLO还是最优解吗?
三、多模态大模型的诱惑:看起来很美
2023年,多模态大模型集中爆发。
GPT-4V、Gemini、Claude 3,这些模型都具备了强大的图像理解能力。

我们测试过这些模型,说实话,Demo效果确实让人印象深刻:
诱惑一:Zero-shot能力
传统方案:你要检测什么缺陷,就得先收集这类缺陷的图片,标注,训练。没有数据,就没有模型。
多模态大模型:直接用自然语言描述"帮我看看这张图里有没有划痕",它就能给你答案。不需要训练,不需要标注。
这意味着什么?冷启动成本趋近于零。
新产品上线,不用再花两周时间收集数据、标注、训练。直接写几句Prompt就能用。
诱惑二:语义理解能力
传统方案:模型输出的是"检测框"和"置信度"。这个框里有缺陷,置信度0.87。
多模态大模型:能输出自然语言描述。"这张图的左上角有一条约2cm的划痕,可能是运输过程中造成的。建议检查包装流程。"
这意味着什么?检测结果可以直接变成质检报告。
诱惑三:强泛化能力
传统方案:模型只认识训练时见过的缺陷类型。来了一种新缺陷,模型就懵了。
多模态大模型:理论上,它"见过"互联网上几乎所有的图片。什么奇怪的缺陷类型,它都有可能识别出来。
这意味着什么?对长尾缺陷、罕见异常的覆盖能力大幅提升。
诱惑四:交互式检测
传统方案:检测逻辑是固定的,写死在模型里。想改检测标准,得重新训练。
多模态大模型:可以通过Prompt动态调整检测标准。今天要求"划痕超过1cm才算NG",明天可以改成"0.5cm",不用动模型。
这意味着什么?检测标准的调整变得极其灵活。
看到这里,你是不是也心动了?
我们当时就是被这些"诱惑"打动,决定在几个项目里试一试。
然后,就开始踩坑了。
四、六个坑,每一个都是真金白银
坑一:推理延迟------产线等不起
我们第一个试点项目是手机外壳的外观检测。
产线节拍:每3秒过一个工件。也就是说,检测延迟必须控制在2秒以内,留1秒给机械臂分拣。
我们测试了GPT-4V的API:
·上传一张图片 + Prompt
·等待响应
·拿到结果
平均延迟:4-6秒。
网络波动的时候,能到10秒以上。
产线根本等不起。
你可能会说,那就用私有化部署的开源多模态模型,比如LLaVA、Qwen-VL。
我们也试了。在A100上跑LLaVA-13B,单张图片推理延迟大约800毫秒到1.2秒 。比API快,但还是比YOLO慢了几十倍。
坑二:吞吐量------算力成本爆炸
退一步讲,假设延迟勉强能接受。
那算一笔账:一条产线一天检测多少张图?
按每3秒一个工件、每天运行20小时算,一条产线一天大约24000张图。
如果用GPT-4V的API,按当时的定价,一张图大约0.01-0.03美元(取决于分辨率和token数)。
一条产线一天:240-720美元。
一个月:7200-21600美元。
一年:86400-259200美元。
这还只是一条产线。客户有12条产线。
这个成本,客户直接摇头。
用私有化部署的开源模型呢?
一张A100显卡,能支撑的QPS(每秒查询数)大约是1-2。一条产线的峰值需求大约是0.3 QPS,看起来一张卡能带几条线。
但A100要多少钱?算上服务器、机房、运维,一年的成本也是几十万人民币级别。
而YOLO方案呢?一个几千块的边缘计算盒子就能搞定一条产线。
成本差了两个数量级。
坑三:结果不确定性------同一张图,两次结果不一样
这个坑是最让我们头疼的。
工业检测有一个基本要求:确定性。
同一张图,不管检测多少次,结果必须一致。不然质检流程没法建立,追溯也没法做。
但多模态大模型的输出是概率性的。
我们做了一个测试:同一张缺陷图片,用相同的Prompt,调用GPT-4V十次。
结果:
·7次判定为"有缺陷"
·2次判定为"疑似缺陷,建议人工复核"
·1次判定为"未发现明显缺陷"
这还是同一张图、同一个Prompt。
在工业场景,这种不确定性是致命的。
你没法跟质检员解释"这个工件有70%的概率有缺陷"。要么OK,要么NG,必须给一个确定的答案。
你可能会说,把temperature调成0不就行了?
我们试了,确实能提高一致性,但依然无法做到100%确定。因为大模型的输出本质上就是采样过程,即使temperature为0,在某些边界情况下仍然会有波动。
坑四:Prompt工程的脆弱性------换个说法,结果就变了
既然用大模型,就得写Prompt。
我们花了很多精力优化Prompt,试图让检测结果更准确、更稳定。
然后发现一个问题:Prompt太脆弱了。
举个例子:
Prompt A:"请检查这张图片中是否有表面缺陷。"
Prompt B:"请仔细观察这张图片,判断产品表面是否存在划痕、凹坑、异物等缺陷。"
Prompt C:"你是一个专业的质检员。请检查这张图片中的产品,如果发现任何影响外观的缺陷,请指出位置和类型。"
这三个Prompt的意思差不多,但检测结果差异很大。
更麻烦的是,我们好不容易在产品A上调好了Prompt,换到产品B上就不灵了。每换一个产品,Prompt都要重新调。
这跟传统方案"换产品要重新训练模型"有什么区别?
区别是:模型训练有明确的评估指标,你知道什么时候训练好了;Prompt调优全靠感觉,你不知道什么时候是最优的。
坑五:幻觉问题------一本正经地胡说八道
大模型有一个著名的问题:幻觉(Hallucination) 。
就是它会一本正经地编造不存在的东西。
在工业检测场景,这个问题表现为:
·明明没有缺陷,它说有
·明明缺陷在左边,它说在右边
·明明是划痕,它说是凹坑
我们测试中遇到过一个案例:一张完全OK的产品图片,大模型输出了一段非常专业的描述------"检测到产品右下角存在一处约3mm的划痕,深度较浅,建议评估是否影响功能"。
我们仔细看了那张图,右下角什么都没有。
如果这种"幻觉"混进了产线,后果不堪设想。
要么漏检,让残次品流出去;要么误检,把良品当残次品扔掉。
坑六:私有化部署的资源门槛
前面说了,API成本太高、延迟太大,那就私有化部署。
我们评估了几个开源多模态模型的部署需求:
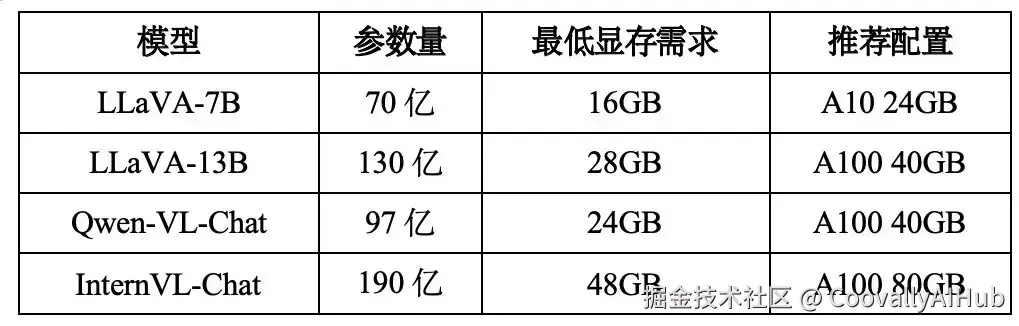
而YOLO呢?
YOLOv8-m在一块8GB显存 的GTX 1080上就能跑得飞起。
甚至可以部署在英伟达Jetson这类边缘计算设备上,功耗只有几十瓦。
算力门槛差了一个量级。
对很多工厂来说,让他们在车间里放一台A100服务器,无论是成本还是运维,都是不现实的。
五、回到第一性原理:工业视觉检测到底需要什么?
踩完这些坑,我们冷静下来,重新思考一个问题:
工业视觉检测这件事,本质上需要什么能力?
需求一:确定性
同一张图,结果必须100%一致。这是质检流程的基础,也是追溯体系的基础。不能有"概率性输出"。
需求二:低延迟
毫秒级响应。产线节拍是刚性的,检测环节不能成为瓶颈。
10毫秒和1000毫秒,是两个世界。
需求三:高吞吐
一秒能处理多少张图?一天能处理多少个工件?
算力成本必须可控,不能一条产线一年烧几十万美元。
需求四:可边缘部署
工厂的网络环境复杂,很多场景没法联网或者网络不稳定。
模型必须能部署在产线边缘,不能依赖云端API。
需求五:可解释的结果
检测出缺陷,得能告诉质检员"在哪里"、"是什么类型"。
最好还能输出缺陷的坐标、面积、置信度,方便下游系统处理。
需求六:可控的维护成本
产品会换代,检测标准会调整。
每次变化,适配成本要可控。不能每次都从头来。
把这六个需求列出来,你会发现:
YOLO系列几乎全中。
·确定性:100%确定,同一输入同一输出
·低延迟:10-30毫秒级
·高吞吐:单卡QPS几十到上百
·可边缘部署:Jetson、工控机都能跑
·可解释的结果:输出检测框、类别、置信度
·可控的维护成本:增量训练、迁移学习,工具链成熟
多模态大模型呢?几乎全不中。
·确定性:概率性输出
·低延迟:秒级
·高吞吐:单卡QPS个位数
·可边缘部署:需要A100级别显卡
·可解释的结果:自然语言描述,需要二次解析
·可控的维护成本:Prompt工程不确定性高
所以,多模态大模型能替代YOLO吗? 答案是清楚的:
在当前的技术成熟度下,多模态大模型不适合作为工业视觉检测的主力方案。
它的优势(Zero-shot、语义理解、强泛化)在工业场景用不上;它的劣势(延迟高、成本高、不确定性)在工业场景是致命的。
六、不是替代,是互补
但这不意味着多模态大模型在工业视觉检测领域毫无用处。
关键是找到它的正确位置。
经过两年的摸索,我们总结出几个多模态大模型真正能发挥价值的场景:
场景一:辅助数据标注
传统方案最大的成本在哪?标注。
一个工业视觉检测项目,往往需要标注几千到几万张图片。按外包标注的市场价,一张图几毛到几块钱。整个项目的标注成本可能占总成本的30%-50%。
多模态大模型可以做什么?
预标注。
用大模型先过一遍原始图片,输出初步的标注结果。然后人工只需要"审核+修正",而不是从零开始标。
我们实测,这种方式可以把标注效率提升3-5倍。
一张图从平均30秒降到10秒以内。
场景二:长尾缺陷的兜底
YOLO模型的能力边界在哪?它只认识训练时见过的缺陷类型。
如果来了一种从没见过的罕见缺陷,YOLO就会漏检。
这种长尾缺陷虽然出现频率低,但往往危害更大------因为它罕见,说明生产过程出了非常规的问题。
多模态大模型可以做什么?
兜底。
当YOLO的置信度处于"灰色地带"(比如0.3-0.7之间),不是很确定的时候,把这张图送给大模型做二次判断。
大模型的Zero-shot能力,恰好可以覆盖这些YOLO没见过的罕见情况。
这种方式,大模型只需要处理**5%-10%**的图片,成本可控,但能显著提升对长尾缺陷的覆盖。
场景三:检测结果的语义化
YOLO输出的是什么?检测框 + 类别 + 置信度。
对下游系统够用,但对人不够友好。
质检员想知道的是:"这个缺陷严不严重?是什么原因造成的?需要怎么处理?"
多模态大模型可以做什么?
把结构化的检测结果,转化成自然语言的质检报告。
输入:检测框坐标、缺陷类别、产品型号、工艺参数
输出:"该产品在左侧边缘检测到一处长约5mm的划痕,可能由模具磨损导致,建议安排模具检修。"
这种场景对延迟不敏感(报告可以异步生成),对成本也不敏感(只处理NG件,数量有限)。
场景四:小样本场景的快速冷启动
有时候客户有一个紧急需求:新产品下周就要上线,但只有几十张缺陷样本,来不及训练YOLO。
传统方案:数据不够,没法做。
多模态大模型:凑合能用。
用大模型的Zero-shot能力,先顶上去。检测精度可能不够高,但至少比纯人工检要快。同时持续收集数据,等数据够了再切换到YOLO方案。
这是一个"过渡方案",不是"长期方案"。
七、混合架构:我们的实践
基于上面的分析,我们在最近的几个项目里采用了混合架构:
主检测通道:YOLO
·承担95%以上的检测任务
·部署在边缘设备,延迟10-20毫秒
·输出检测框、类别、置信度
辅助通道:多模态大模型
·只处理"不确定"的图片(置信度在灰色地带)
·异步调用,不影响主通道的吞吐
·用于长尾缺陷兜底、结果语义化、辅助标注
这套架构的核心设计原则:
-
YOLO是主力,大模型是辅助------不要本末倒置
-
分流而不是串联------大模型不在关键路径上,不影响主通道的延迟和吞吐
-
按置信度分流------高置信度的图片直接过,低置信度的图片送大模型复核
-
成本可控------大模型只处理小比例的图片,成本可预测
八、技术选型决策框架
最后,总结一个技术选型的决策框架。
如果你正在做工业视觉检测的技术选型,可以按这个流程来判断:
问题一:延迟要求是什么?
·如果需要<100毫秒 → YOLO方案
·如果可以接受秒级延迟 → 可以考虑大模型
问题二:吞吐量要求是什么?
·如果每秒>1张图 → YOLO方案
·如果每天只有几百张图 → 可以考虑大模型
问题三:部署环境是什么?
·如果是边缘部署/离线环境 → YOLO方案
·如果有稳定的云端算力 → 可以考虑大模型
问题四:数据情况是什么?
·如果有几千张以上的标注数据 → YOLO方案
·如果只有几十张样本,且急着上线 → 大模型先顶上,后续切换
问题五:预算是多少?
·如果希望单条产线年成本<10万 → YOLO方案
·如果预算充足 → 可以考虑混合架构
在大多数工业场景下,答案都会指向YOLO。
只有在特定条件下------延迟不敏感、吞吐量要求低、有云端算力、数据极度稀缺------才值得考虑以大模型为主的方案。
而最务实的选择,往往是混合架构:
·YOLO做主力检测
·大模型做辅助(标注、兜底、报告生成)
·各取所长,成本可控
九、写在最后
回到开头那个问题:多模态大模型能替代YOLO吗?
两年踩坑之后,我的答案是:
问错问题了。
这不是一个"A替代B"的问题,而是一个"各自找到生态位"的问题。
多模态大模型很强,但它的强项------Zero-shot、语义理解、强泛化------在工业检测的核心场景用不上。
它的弱项------延迟高、成本高、结果不确定------恰恰是工业场景最不能容忍的。
技术选型的本质,不是追逐最新最热的技术,而是找到最匹配场景的技术。
YOLO系列已经在工业视觉检测领域跑了好几年,有它成为"事实标准"的道理。
多模态大模型是一个强大的补充,但在当前的技术成熟度下,还不是一个合格的替代者。
也许三年后、五年后,情况会变化。
推理速度会更快,部署成本会更低,确定性问题会被解决。
到那时候,我们再来聊"替代"这件事。
但在今天,如果你要做工业视觉检测,我的建议是:
·主力用YOLO,别犹豫
·大模型做辅助,找对场景
·保持关注,但不要押注