目录
- [1. 作者介绍](#1. 作者介绍)
- [2. 梯度提升树算法](#2. 梯度提升树算法)
-
- [2.1 Boosting 算法](#2.1 Boosting 算法)
- [2.2 Boosting Tree (提升树)](#2.2 Boosting Tree (提升树))
- [2.3 梯度提升树(Gradient Boosting Tree)](#2.3 梯度提升树(Gradient Boosting Tree))
- [3. 利用梯度提升树分类法实现乳腺癌数据集分类实验](#3. 利用梯度提升树分类法实现乳腺癌数据集分类实验)
-
- [3.1 乳腺癌数据集介绍](#3.1 乳腺癌数据集介绍)
- [3.2 实验过程](#3.2 实验过程)
- [3.3 实验结果](#3.3 实验结果)
- [3.4 完整代码](#3.4 完整代码)
- [4. 参考文献](#4. 参考文献)
1. 作者介绍
谈翠红,女,西安工程大学电子信息学院,2023级研究生
研究方向:机器视觉与人工智能
电子邮件:t19856597379@163.com
徐达,男,西安工程大学电子信息学院,2023级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:1374455905@qq.com
2. 梯度提升树算法
2.1 Boosting 算法
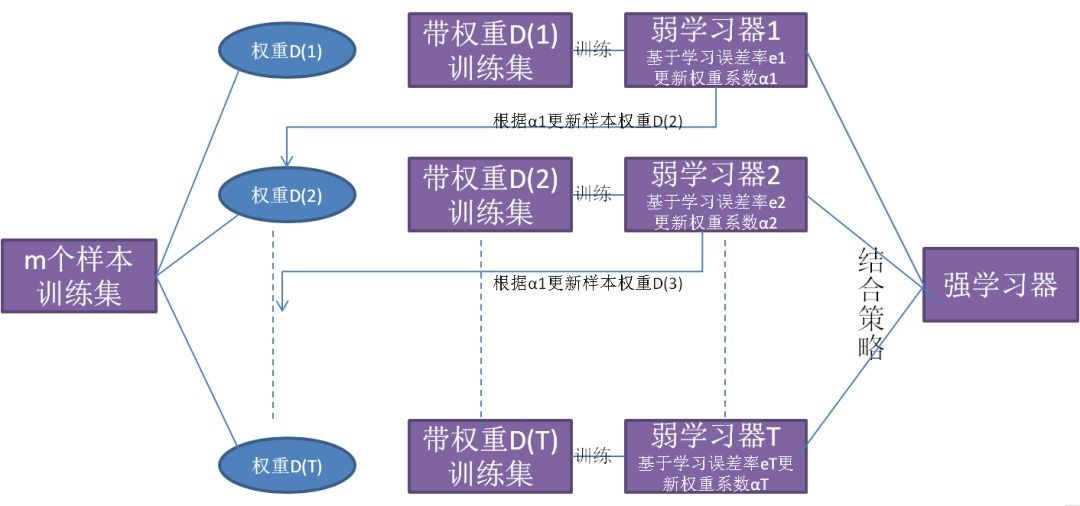
从图可以看出,Boosting 算法的工作机制是从训练集用初始权重训练出一个弱学习器1,根据弱学习器的学习误差率来更新训练样本的权重,使得之前弱学习器1中学习误差率高的训练样本点权重变高。然后这些误差率高的点在弱学习器2中得到更高的重视,利用调整权重后的训练集来训练弱学习器2。如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。了解Boosting方法后,我们便可将Boosting方法和Decision Tree相结合便可得到Boosting Decision Tree。
2.2 Boosting Tree (提升树)
提升树是以决策树为基本学习器的提升方法,它被认为是统计学习中性能最好的方法之一。对于分类问题,提升树的决策树是二叉决策树,对于回归问题,提升树中的决策是二叉回归树。不同问题的提升树学习算法主要区别在于使用的损失函数不同。
提升树模型可以表示为决策树为基学习器的加法模型:
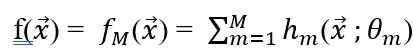
其中,hm(x ;θm)表示第m个决策树,θm为第 m个决策树的参数,M为决策树的数量。
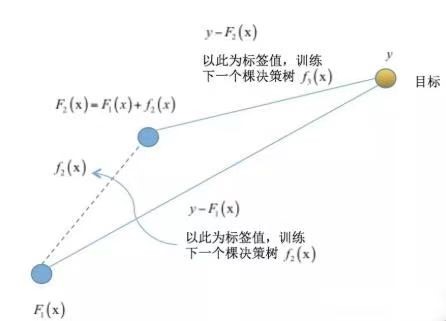
从图能够直观的看到,提升树的学习思想有点类似打高尔夫球,先粗略的打一杆,然后在之前的基础上逐步靠近球洞,也就是说每一棵树学习的是之前所有树的结论和残差,这个残差就是一个加预测值后得到真实值的累加量。
2.3 梯度提升树(Gradient Boosting Tree)
基于前面介绍的提升树基本思路,可以发现这个算法没有解决损失函数拟合方法的问题。针对这个问题,Freidman提出用损失函数的负梯度来拟合损失的近似值,所以结合得到了梯度提升树算法。而本次实验所使用的是梯度提升树分类算法,它是通过逐步构建一系列的决策树,每棵树都拟合前一棵树的残差,从而逐步提高模型的预测性能。通过对乳腺癌数据集的分类,梯度提升树能够有效地区分良性和恶性肿瘤,同时提供每个特征的重要性,从而帮助理解哪些特征对预测结果影响最大。它的核心原理如下:
初始化一个弱学习器F0(x) ,通常使用一个简单的初始模型(如平均值)来拟合目标变量y 。
对于m=1, 2, . . . , M (M 为迭代次数),迭代进行以下步骤:
计算当前模型的残差rim = yi-F(m-1)(xi) ,其中 F(m-1)(xi) 是前 m-1 个模型的组合预测结果。
拟合一个新的基本学习器 hm(x) ,使得 hm(x) 在训练集上拟合残差 rim 。
更行模型: Fm(x) = F(m-1)(x) +α hm(x) ,其中是一个学习率(也称为步长),控制每次迭代新模型的贡献程度。
最终模型为FM(x) 。
3. 利用梯度提升树分类法实现乳腺癌数据集分类实验
3.1 乳腺癌数据集介绍
威斯康星州乳腺癌数据集是scikit-learn(sklearn)库中一个常用的内置数据集,用于分类任务。该数据集包含了从乳腺癌患者收集的肿瘤特征的测量值,以及相应的良性(benign)或恶性(malignant)标签。以下是对该数据集的简单介绍:
数据集来源:数据集最初由威斯康星州医院的Dr. William H. Wolberg收集。
数据集大小:569 个样本,其中良性样本357个,恶性样本212个
特征数量:30 个数值特征
特征名称:每个特征表示从乳腺细胞核图像中提取的一个属性。以下是特征的具体描述:
• 半径(mean radius)
• 纹理(mean texture)
• 周长(mean perimeter)
• 面积(mean area)
• 平滑度(mean smoothness)
• 紧致度(mean compactness)
• 凹陷点(mean concavity)
• 凹点数(mean concave points)
• 对称性(mean symmetry)
• 分形维数(mean fractal dimension)
以上特征的计算方式包括平均值(mean)、标准误(standard error)、最大值(worst),每个特征的这三种计算方式形成了30个特征。
3.2 实验过程
下面展示一些 内联代码片。
python
pip install numpy pandas scikit-learn matplotlib seaborn -i
https://pypi.tuna.tsinghua.edu.cn/simplenumpy: 用于处理数值计算
pandas: 用于数据处理和分析
scikit-learn: 加载乳腺癌数据集
Matplotlib:提供基础的绘图功能,如线条图、散点图、柱状图等,支持广泛的图表类型和自定义,可以创建静态图形以及一些动态和交互式图形。
Seaborn:基于Matplotlib,提供更高级的数据可视化功能,如时间序列数据的静态图表,自动图形美化,特别适合统计数据可视化
1 首先导入相关库
python
# 导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
import seaborn as sns2 数据加载和预处理,将特征数据存储在 DataFrame 中,标签数据存储在 Series 中,使用StandardScaler 对特征数据进行标准化处理,以确保特征值在同一量级。
python
# 导入库
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.Series(data.target)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)3 将数据集划分为训练集和测试集 训练集70% 、测试集30%
python
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)4 使用 Gradient Boosting Classifier 进行模型训练
python
gbc = GradientBoostingClassifier(random_state=42)
gbc.fit(X_train, y_train)5 使用测试集进行模型评估
python
y_pred = gbc.predict(X_test)
print("初始模型评估:")
print(classification_report(y_test, y_pred))
print("混淆矩阵:")
print(confusion_matrix(y_test, y_pred))
print("准确率:", accuracy_score(y_test, y_pred))6优化参数:网格搜索使用 5 折交叉验证评估每个超参数组合,总共有 64 种超参数组合,因此需要进行 320 次模型训练和验证,得到最佳参数。
python
param_grid = {
'n_estimators': [50, 100, 150, 200],
'learning_rate': [0.01, 0.05, 0.1, 0.2],
'max_depth': [3, 4, 5, 6]
}
rid_search = GridSearchCV(estimator=gbc, param_grid=param_grid, cv=5, n_jobs=1, verbose=2)
grid_search.fit(X_train, y_train)
print("最佳参数:", grid_search.best_params_)7 优化后的模型评估
python
best_gbc = grid_search.best_estimator_
y_pred_best = best_gbc.predict(X_test)
print("优化后模型评估:")
print(classification_report(y_test, y_pred_best))
print("混淆矩阵:")
print(confusion_matrix(y_test, y_pred_best))
print("准确率:", accuracy_score(y_test, y_pred_best))8 混淆矩阵可视化
python
conf_matrix = confusion_matrix(y_test, y_pred_best)
plt.figure(figsize=(10, 7))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', xticklabels=data.target_names, yticklabels=data.target_names)
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix')
plt.show()9 特征重要性可视化
python
feature_importances = best_gbc.feature_importances_
features = data.feature_names
indices = np.argsort(feature_importances)
plt.figure(figsize=(15, 10))
plt.title('Feature Importances')
plt.barh(range(len(indices)), feature_importances[indices], color='b', align='center')
plt.yticks(range(len(indices)), [features[i] for i in indices])
plt.xlabel('Relative Importance')
plt.show()3.3 实验结果
得到最佳参数:学习率0.05、决策树的最大深度3、决策树的数量200
模型分类准确率为96%,如果计算机内存够大,可通过设置参数n_jobs=2/3/4得到更高准确率。
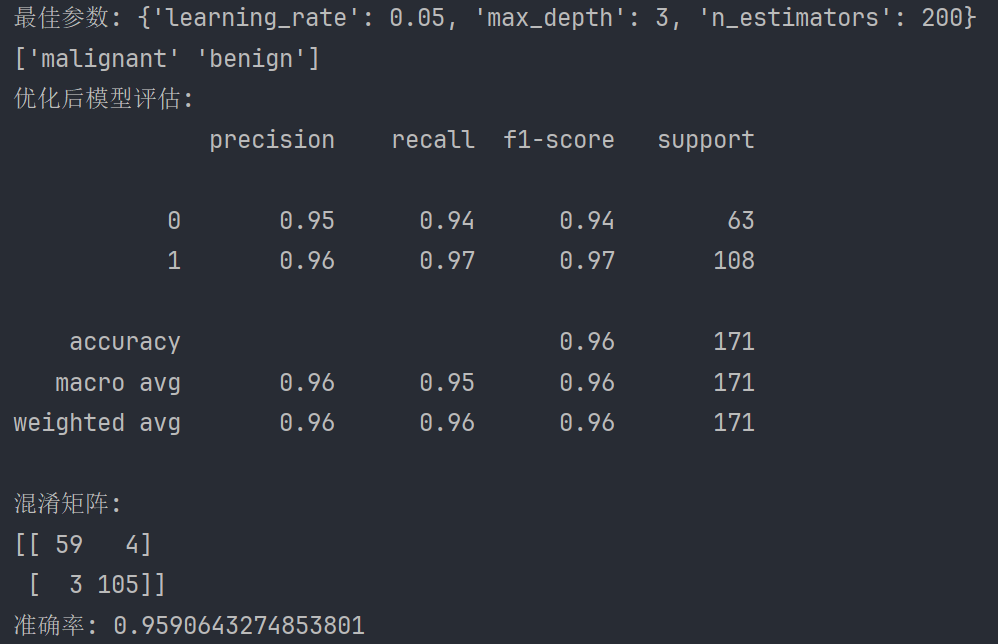
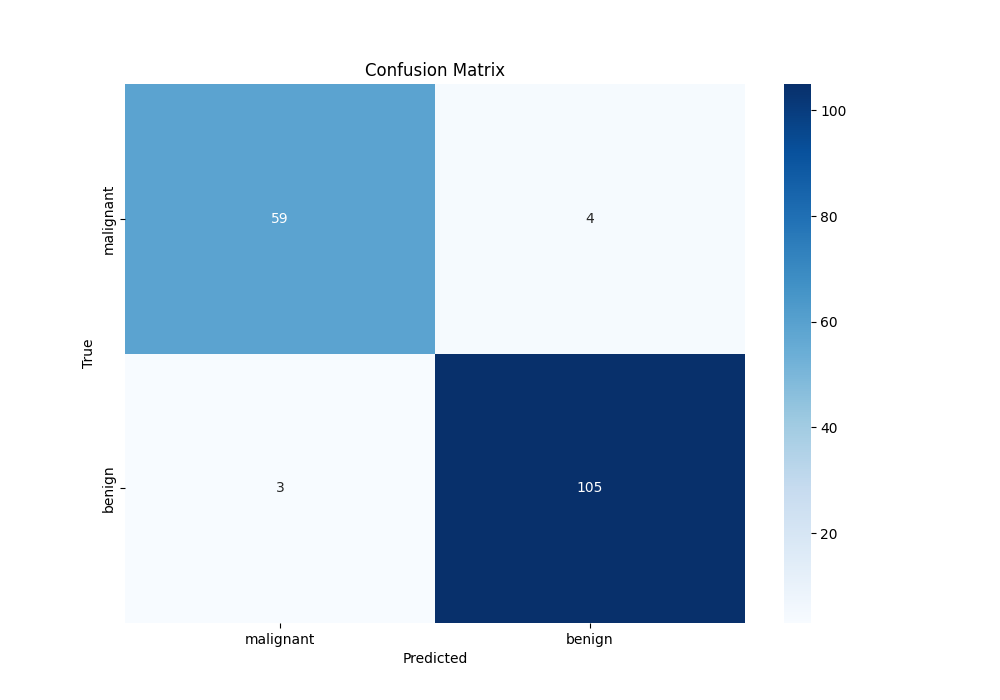
混淆矩阵可视化图
0 代表恶性(Malignant)1 代表良性(Benign)
59:表示模型将真实为类别0的样本预测为类别0的数量
105:表示模型将真实为类别1的样本预测为类别1的数量
3:表示模型将真实为类别1的样本错误地预测为类别0的数量
4:表示模型将真实为类别0的样本错误地预测为类别1的数量
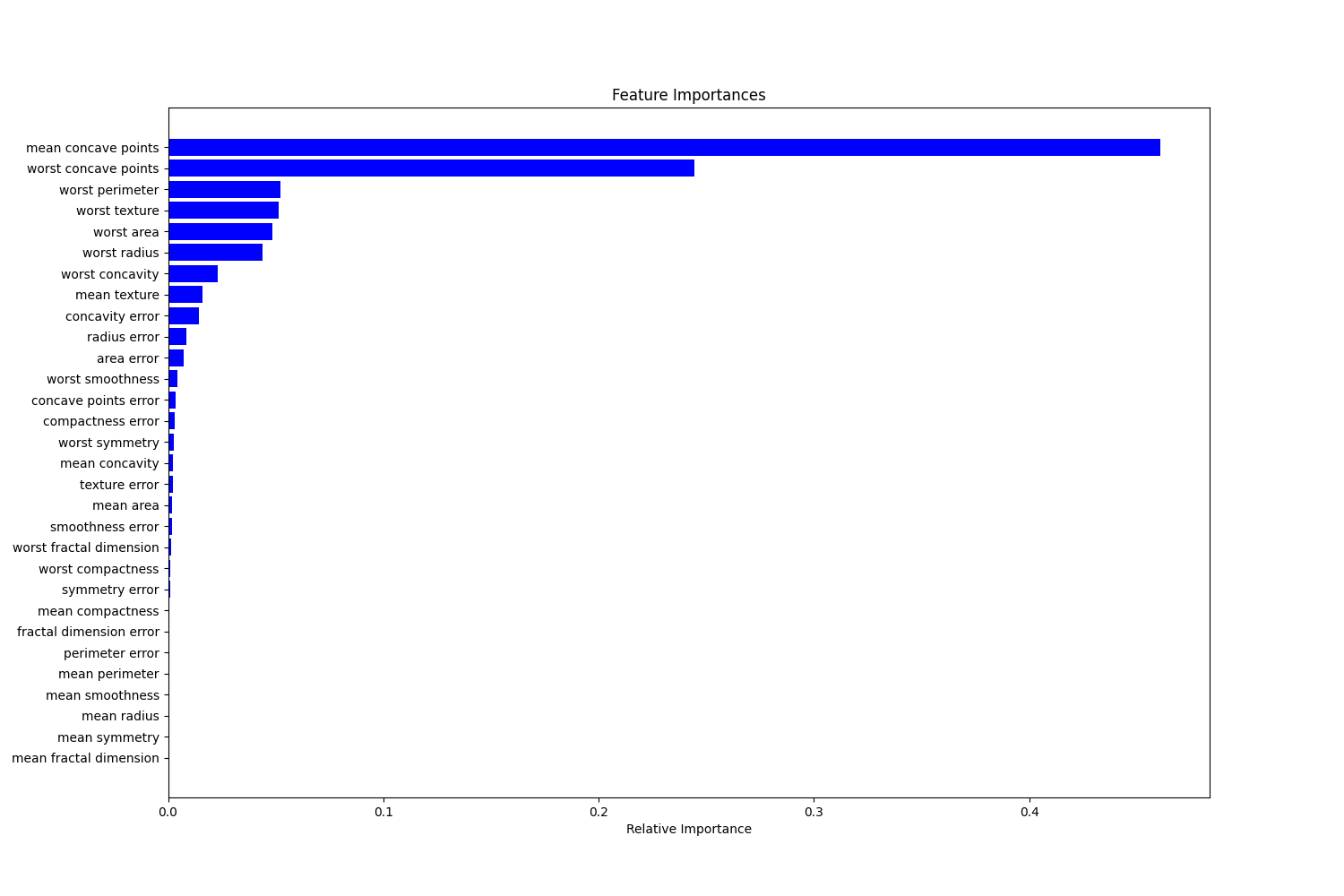
特征重要性图
这些特征的重要性分布揭示了在乳腺癌分类问题中,某些特征(如半径、周长和面积)比其他特征(如平滑度、对称性)更有影响力。理解这些特征的重要性有助于进一步改进模型,并且在实际应用中可能提供更多的临床意义
3.4 完整代码
python
# 导入库
import numpy as np # 处理数值计算
import pandas as pd # 数据处理和分析
from sklearn.datasets import load_breast_cancer # 加载乳腺癌数据集
# 将数据集划分为训练集和测试集以及超参数搜索和交叉验证
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler # 数据标准化
from sklearn.ensemble import GradientBoostingClassifier # 梯度提升树分类器模型
# 生成分类报告、混淆矩阵,计算准确率
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
# 绘制数据可视化图表
import seaborn as sns
import matplotlib.pyplot as plt
# 加载乳腺癌数据集
data = load_breast_cancer()
# 将特征数据存储在 DataFrame 中,标签数据存储在 Series 中
X = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.Series(data.target)
# 数据预处理
scaler = StandardScaler() # 标准化特征值,使每个特征具有相同的尺度
X_scaled = scaler.fit_transform(X)
# 数据分割 将数据集划分为训练集和测试集 训练集70% 测试集30%
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
# 使用梯度提升树分类器模型训练
gbc = GradientBoostingClassifier(random_state=42)
gbc.fit(X_train, y_train)
# 使用测试集进行模型评估
y_pred = gbc.predict(X_test)
print("初始模型评估:")
print(classification_report(y_test, y_pred))
print("混淆矩阵:")
print(confusion_matrix(y_test, y_pred))
print("准确率:", accuracy_score(y_test, y_pred))
# 模型优化 决策树的数量 学习率 决策树的最大深度
param_grid = {
'n_estimators': [50, 100, 150, 200],
'learning_rate': [0.01, 0.05, 0.1, 0.2],
'max_depth': [3, 4, 5, 6]
}
grid_search = GridSearchCV(estimator=gbc, param_grid=param_grid, cv=5, n_jobs=1, verbose=2)
grid_search.fit(X_train, y_train)
print("最佳参数:", grid_search.best_params_)
# 优化后的模型评估
best_gbc = grid_search.best_estimator_
y_pred_best = best_gbc.predict(X_test)
print("优化后模型评估:")
print(classification_report(y_test, y_pred_best))
print("混淆矩阵:")
print(confusion_matrix(y_test, y_pred_best))
print("准确率:", accuracy_score(y_test, y_pred_best))
# 混淆矩阵可视化
conf_matrix = confusion_matrix(y_test, y_pred_best)
plt.figure(figsize=(10, 7))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', xticklabels=data.target_names, yticklabels=data.target_names)
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix')
plt.show()
# 特征重要性可视化
feature_importances = best_gbc.feature_importances_ # 包含了每个特征的相对重要性
features = data.feature_names # 所有特征名称
# 返回一个数组,数组元素按特征重要性从小到大的顺序排列
indices = np.argsort(feature_importances)
# 绘制特征重要性图
plt.figure(figsize=(15, 10))
plt.title('Feature Importances')
plt.barh(range(len(indices)), feature_importances[indices], color='b', align='center')
plt.yticks(range(len(indices)), [features[i] for i in indices])
plt.xlabel('Relative Importance')
plt.show()4. 参考文献
机器学习之梯度提升决策树(GBDT)-腾讯云开发者社区-腾讯云 (tencent.com): link
GBT、GBDT、GBRT与Xgboost - 别再闹了 - 博客园 (cnblogs.com): link