
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
博主简介:努力学习的22级本科生一枚 🌟;探索AI算法,C++,go语言的世界;在迷茫中寻找光芒🌸
博客主页:羊小猪~~-CSDN博客
内容简介:NLP入门三,Embedding和EmbeddingBag嵌入.
🌸箴言🌸:去寻找理想的"天空""之城
上一篇内容:【NLP入门系列二】NLP分词和字典构建-CSDN博客
文章目录
NLP文本嵌入
前言
📄 大模型语言理解文字方式: 将每一个词当做一个数字,然后不断地进行做计算题,从而不断地输出文字;
⛈ 举例:
如果用一个数字表示一个词,这里用1表示男人,2表示女人,这样的作用是给词进行了编号,但是表示无法表示词与词之间的关系。
但是,如果用两位数字表示呢?
👀 参考b站大佬视频:
在数学中,向量是有方向的,可以做运算,这里也一样,如图:

在数学中,向量是有方向的,可以做运算,这里也一样,如图:

这样就实现了:将每一个词当做一个数字,然后进行做计算题,从而输出文字;
💠 词嵌入: 用向量表示词。**原理:**将词嵌入到数学的维度空间,如果词用二维表示,那么嵌入到一个二维空间里,以此类推;
本质: 将离散的词汇映射到一个低维连续的向量空间中,这样词汇之间的关系就可以在向量空间中得到体现。
📘 大模型语言训练过程
大模型语言训练是一个很复杂的过程,但是了解最基本过程还是简单的,如下图表示(刚开始不同词随机分布在二维空间中不同位置):
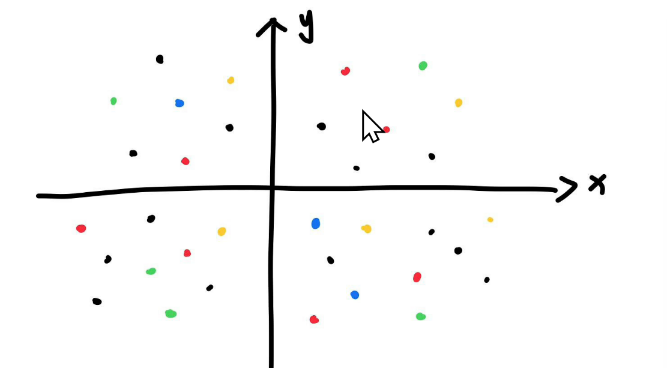
经过模型训练后:

将语义相近的分布在一起,但是也有一些中立词,如苹果这个词,吃苹果和苹果手机是不同意思的,所以苹果就是中立的,具体的意思需要根据模型训练过程中结合上下文进行运算得出结果。
Embedding和EmbeddingBag是pytorch处理文本数据词嵌入的工具。
1、Embedding嵌入
Embedding是pytorch中最基本的词嵌入操作。
输入:一整张向量,每个整数都代表一个词汇的索引
输出:是一个浮点型的张量,每个浮现数都代表着对应词汇的词嵌入向量。
维度变化:
- 输入shape:
[batch, seqSize],seqSize表示单个文本长度(注意:同一批次中每个样本的序列长度(seq_len)必须相同); - 输出shape:
[batch, seqSize, embed_dim],embed_bim表示嵌入维度。
👙 注意 :嵌入层被定义为网络的第一个隐藏层 ,采用随机权重初始化的方式,既可以作为深度学习模型的一部分,一起训练,也可以用于用于加载训练好的词嵌入模型。
函数原型:
python
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None,norm_type=2.0,scale_grad_by_freq=False, sparse=False,_weight=None,_freeze=False, device=None, dtype=None)常见参数:
- num_embeddings:词汇表大小, 即,最大整数 index + 1。
- embedding_dim:词向量的维度。
📚 以一个二分类案例为例:
1、导入库和自定义数据格式
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
# 自定义数据维度
class MyDataset(Dataset):
def __init__(self, texts, labels):
super().__init__()
self.texts = texts
self.labels = labels
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
text = self.texts[idx]
label = self.labels[idx]
return text, label2、定义填充函数(将所有词长度变成一致)
python
def collate_batch(batch):
# 解包
texts, labels = zip(*batch) # texts、labels存储在不同[]/()这样的数据结构
# 获取最大长度
max_len = max(len(text) for text in texts)
# 填充, 不够的填充为0
padding_texts = [F.pad(text, (0, max_len - len(text)), value=0) for text in texts] # 采用右填充
# 改变维度--> (batch_size, max_len)
padding_texts = torch.stack(padding_texts)
# 标签格式化(改变维度)--> (batch_size) --> (batch_size, 1), 不改变值
labels = torch.tensor(labels, dtype=torch.float).unsqueeze(1)
return padding_texts, labels3、定义数据
python
# 定义三个样本
data = [
torch.tensor([1, 1, 1], dtype=torch.long),
torch.tensor([2, 2, 2], dtype=torch.long),
torch.tensor([3, 3], dtype=torch.long)
]
# 定义标签
labels = torch.tensor([1, 2, 3], dtype=torch.float)
# 创建数据
data = MyDataset(data, labels)
data_loader = DataLoader(data, batch_size=2, shuffle=True, collate_fn=collate_batch)
# 展示
for batch in data_loader:
print(batch)
print("shape:", batch)(tensor([[1, 1, 1],
[3, 3, 0]]), tensor([[1.],
[3.]]))
shape: (tensor([[1, 1, 1],
[3, 3, 0]]), tensor([[1.],
[3.]]))
(tensor([[2, 2, 2]]), tensor([[2.]]))
shape: (tensor([[2, 2, 2]]), tensor([[2.]]))4、定义模型
python
class EmbeddingModel(nn.Module):
def __init__(self, vocab_size, embed_dim):
super(EmbeddingModel, self).__init__()
# 定义模型
self.embedding = nn.Embedding(vocab_size, embed_dim) # 词汇表大小 + 嵌入维度
self.fc = nn.Linear(embed_dim, 1) # 这里假设做二分类任务
def forward(self, text):
print("Embedding输入文本是: ", text)
print("Embedding输入文本shape: ", text.shape)
embedding = self.embedding(text)
embedding_mean = embedding.mean(dim=1)
print("embedding输出文本维度: ", embedding_mean.shape)
return self.fc(embedding_mean)注意 :
如果使用embedding_mean = embedding.mean(dim=1)语句对每个样本的嵌入向量求平均,输出shape为[batch, embed_dim]。若注释掉该语句,输出shape则为[batch, seqSize, embed_dim]。
5、模型训练
python
# 定义词表大小和嵌入维度
vacab_size = 10
embed_dim = 6
# 创建模型
model = EmbeddingModel(vacab_size, embed_dim)
# 设置超参数
cirterion = nn.BCEWithLogitsLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 模型训练
for epoch in range(1):
for batch in data_loader:
text, label = batch
# 前向传播
outputs = model(text)
loss = cirterion(outputs, label)
# 方向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item()}')Embedding输入文本是: tensor([[2, 2, 2],
[1, 1, 1]])
Embedding输入文本shape: torch.Size([2, 3])
embedding输出文本维度: torch.Size([2, 6])
Epoch 1, Loss: 0.6635428667068481
Embedding输入文本是: tensor([[3, 3]])
Embedding输入文本shape: torch.Size([1, 2])
embedding输出文本维度: torch.Size([1, 6])
Epoch 1, Loss: 0.56672024726867682、EmbeddingBag嵌入
EmbeddingBag是在Embedding基础上进一步优化的工具,其核心思想 是将每个输入序列的嵌入向量进行合并,能够处理可变长度的输入序列,并且减少了计算和存储的开销,并且可以计算句子中所有词汇的词嵌入向量的均值或总和。
减少计算量:因为embedding嵌入中需要要求每一个词向量长度需要一样。
在PyTorch中,EmbeddingBag的输入是一个 整数张量 和一个 偏移量张量 ,每个整数都代表着一个词汇的索引,偏移量则表示句子中每个词汇的位置,输出是一个浮点型的张量,每个浮点数都代表着对应句子的词嵌入向量的均值或总和。
- 输入shape:seqsSize(seqsSize为单个batch文本总长度)
- 输出shape:batch, embed_dim(embed_dim嵌入维度)
📐 假设原始输入数据为
[[1, 1, 1, 1], [2, 2, 2], [3, 3]]
展平的词汇索引张量
- 将所有样本的数据合并成一个一维数组。如
[1, 1, 1, 1, 2, 2, 2, 3, 3]。偏移量
偏移量表示每个样本在展平张量中的起始位置。如本案例:
[0, 4, 7],合并操作
- 根据偏移量进行合并
- 合并操作可以是求和、平均或取最大值,默认是平均(mean)。以平均为例:
- 第一个样本的平均值:
(1 + 1 + 1 + 1) / 4 = 1- 第二个样本的平均值:
(2 + 2 + 2) / 3 = 2- 第三个样本的平均值:
(3 + 3) / 2 = 3- 最后结果为
[1, 2, 3],即batch维度
📑 一个简单的案例如下:
1、导入库和自定义数据格式
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
# 自定义数据维度
class MyDataset(Dataset):
def __init__(self, texts, labels):
super().__init__()
self.texts = texts
self.labels = labels
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
text = self.texts[idx]
label = self.labels[idx]
return text, label2、定义数据
python
# 定义三个样本
data = [
torch.tensor([1, 1, 1], dtype=torch.long),
torch.tensor([2, 2, 2], dtype=torch.long),
torch.tensor([3, 3], dtype=torch.long)
]
# 定义标签
labels = torch.tensor([1, 2, 3], dtype=torch.float)
# 创建数据
data = MyDataset(data, labels)
data_loader = DataLoader(data, batch_size=2, shuffle=True, collate_fn=lambda x : x)
# 展示
for batch in data_loader:
print(batch)[(tensor([1, 1, 1]), tensor(1.)), (tensor([3, 3]), tensor(3.))]
[(tensor([2, 2, 2]), tensor(2.))]3、定义模型
python
class EmbeddingModel(nn.Module):
def __init__(self, vocab_size, embed_dim):
super(EmbeddingModel, self).__init__()
# 定义模型
self.embedding_bag = nn.EmbeddingBag(vocab_size, embed_dim, mode='mean')
self.fc = nn.Linear(embed_dim, 1) # 这里假设做二分类任务
def forward(self, text, offsets):
print("Embedding输入文本是: ", text)
print("Embedding输入文本shape: ", text.shape)
embedding_bag = self.embedding_bag(text, offsets)
print("embedding_bag输出文本维度: ", embedding_bag.shape)
return self.fc(embedding_bag)4、模型训练
python
# 定义词表大小和嵌入维度
vacab_size = 10
embed_dim = 6
# 创建模型
model = EmbeddingModel(vacab_size, embed_dim)
# 设置超参数
cirterion = nn.BCEWithLogitsLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 模型训练
for epoch in range(1):
for batch in data_loader:
# 展平和计算偏移量
texts, labels = zip(*batch)
# 偏移量计算,就是统计文本长度
offset = [0] + [len(text) for text in texts[:-1]] # 统计长度
offset = torch.tensor(offset).cumsum(dim=0) # 生成偏移量,累计求和
texts = torch.cat(texts) # 合并文本
labels = torch.tensor(labels).unsqueeze(1) # 增加维度-->(batch_size, 1)
# 前向传播
outputs = model(texts, offset)
loss = cirterion(outputs, labels)
# 方向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item()}')Embedding输入文本是: tensor([2, 2, 2, 1, 1, 1])
Embedding输入文本shape: torch.Size([6])
embedding_bag输出文本维度: torch.Size([2, 6])
Epoch 1, Loss: 0.07764509320259094
Embedding输入文本是: tensor([3, 3])
Embedding输入文本shape: torch.Size([2])
embedding_bag输出文本维度: torch.Size([1, 6])
Epoch 1, Loss: 3.315852642059326