文章目录
ClickHouse快速安装教程(MacOS)
1.ClickHouse
ClickHouse®是一个用于在线分析处理(OLAP)的高性能、面向列的SQL数据库管理系统(DBMS)。ClickHouse专门针对大规模数据分析和实时查询的场景进行优化。它被设计用于高效处理PB级以上的数据,并能在秒级内完成复杂的查询分析。
OLAP场景的关键特征
- 绝大多数是读请求
- 数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
- 已添加到数据库的数据不能修改。
- 对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
- 宽表,即每个表包含着大量的列
- 查询相对较少(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每个查询有一个大表。除了他以外,其他的都很小。
- 查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
ClickHouse具有以下特点:
- 高性能:采用了列式存储和压缩技术,在处理大规模数据时能够快速高效地进行数据读取和查询。它使用了向量化查询引擎和多级缓存,可以实现即时的查询结果响应。
- 分布式架构:支持水平扩展,可以轻松地在集群中添加或删除节点。它使用分片和复制机制来实现高可用性和数据冗余。
- 强大的查询功能:支持标准的SQL查询语言,并提供了丰富的查询函数和聚合操作,可以方便地进行复杂的数据分析和数据挖掘。
- 可伸缩性:能够处理海量数据,并且能够在不降低性能的情况下轻松地扩展到更多的节点,以满足不断增长的数据需求。
- 低延迟查询:通过使用基于内存的数据存储和高效的查询引擎,可以在毫秒级的时间范围内处理查询请求,适用于需要实时响应的场景。 总之,ClickHouse是一个专门用于大规模数据分析和实时查询的高性能分布式列式数据库,它具有高可扩展性和低延迟查询的优势,适用于需要处理大量数据和复杂查询的应用场景。
2.快速安装
本地下载ClickHouse最简单的方法是运行以下curl命令:
sh
curl https://clickhouse.com/ | sh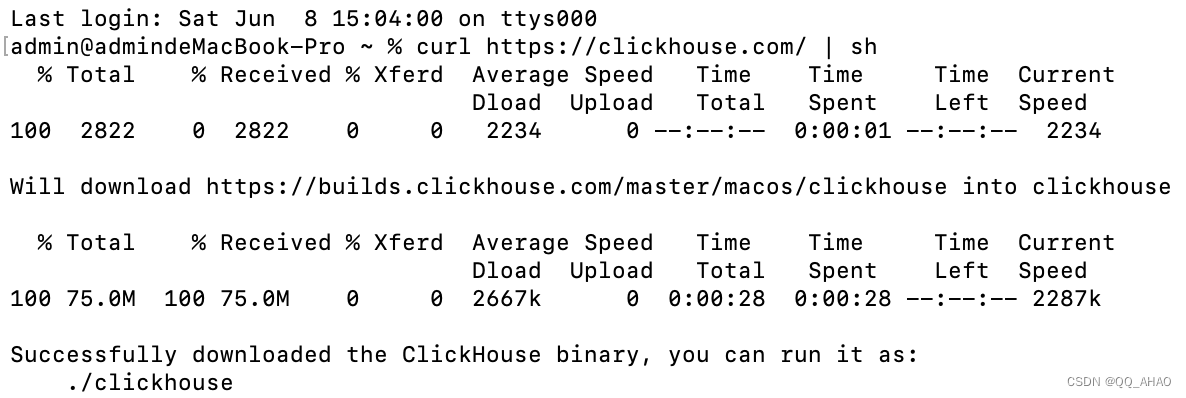
下载ClickHouse(执行本命令安装完成后,你可以编辑ClickHouse的配置文件来自定义参数和设置,例如监听地址、端口,以及数据存储和备份的路径等。)
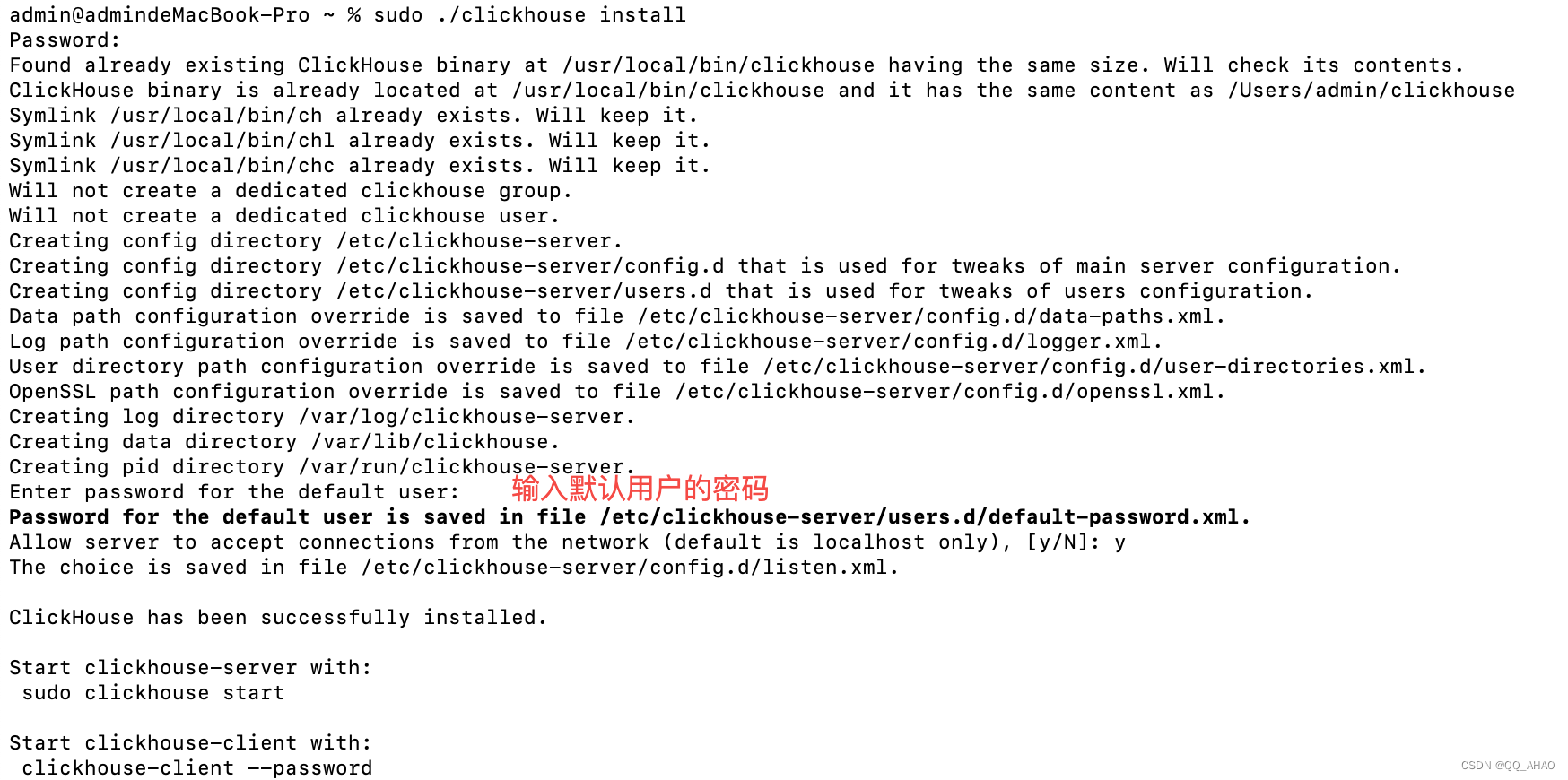
3.快速启动
3.1.启动服务器
sh
./clickhouse server
3.2.启动客户端
sh
./clickhouse client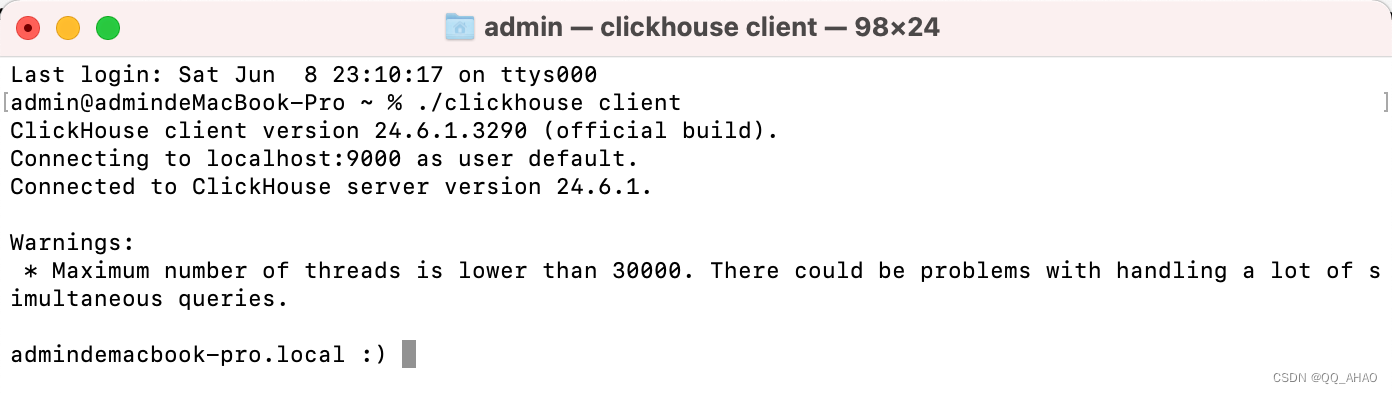
可以看到会出现以下警告:最大线程数低于30000。处理大量同时进行的查询可能会出现问题。
sh
Warnings:
* Maximum number of threads is lower than 30000. There could be problems with handling a lot of simultaneous queries.这个警告表明,当前设置的线程数可能不足以处理大量的同时查询。您可以通过修改ClickHouse的配置文件来增加线程数。在/etc/clickhouse-server/config.xml文件中找到max_threads设置,并根据您的服务器性能和负载情况进行调整
4.使用案例
1.配置文件
添加配置文件 config.xml
xml
<clickhouse>
<logger>
<level>trace</level>
<log>/Users/admin/ck/data/logs/clickhouse.log</log>
<errorlog>/Users/admin/ck/data/logs/error.log</errorlog>
<size>500M</size>
<count>5</count>
</logger>
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
<interserver_http_port>9001</interserver_http_port>
<interserver_http_host>127.0.0.1</interserver_http_host>
<listen_host>0.0.0.0</listen_host>
<max_connections>4096</max_connections>
<keep_alive_timeout>300</keep_alive_timeout>
<max_concurrent_queries>1000</max_concurrent_queries>
<uncompressed_cache_size>8589934592</uncompressed_cache_size>
<mark_cache_size>5368709120</mark_cache_size>
<default_profile>default</default_profile>
<default_database>default</default_database>
<builtin_dictionaries_reload_interval>3600</builtin_dictionaries_reload_interval>
<max_session_timeout>3600</max_session_timeout>
<default_session_timeout>300</default_session_timeout>
<max_table_size_to_drop>0</max_table_size_to_drop>
<merge_tree>
<parts_to_delay_insert>300</parts_to_delay_insert>
<parts_to_throw_insert>600</parts_to_throw_insert>
<max_delay_to_insert>2</max_delay_to_insert>
</merge_tree>
<max_table_size_to_drop>0</max_table_size_to_drop>
<max_partition_size_to_drop>0</max_partition_size_to_drop>
<!-- Path to data directory, with trailing slash. -->
<path>/Users/admin/ck/data/</path>
<!-- Path to temporary data for processing hard queries. -->
<tmp_path>/Users/admin/ck/data/tmp/</tmp_path>
<!-- Sources to read users, roles, access rights, profiles of settings, quotas. -->
<user_directories>
<users_xml>
<!-- Path to configuration file with predefined users. -->
<!-- 此处的目录地址指向下方的users.xml -->
<path>/Users/admin/ck/users.xml</path>
</users_xml>
<local_directory>
<!-- Path to folder where users created by SQL commands are stored. -->
<!-- 用户创建sql语句的存储目录 -->
<path>/Users/admin/ck/users/</path>
</local_directory>
</user_directories>
</clickhouse>添加用户配置文件 users.xml
xml
<clickhouse>
<profiles>
<default>
<max_memory_usage>10000000000</max_memory_usage>
<use_uncompressed_cache>0</use_uncompressed_cache>
<load_balancing>random</load_balancing>
</default>
<readonly>
<max_memory_usage>10000000000</max_memory_usage>
<use_uncompressed_cache>0</use_uncompressed_cache>
<load_balancing>random</load_balancing>
<readonly>1</readonly>
</readonly>
</profiles>
<quotas>
<!-- Name of quota. -->
<default>
<interval>
<queries>0</queries>
<errors>0</errors>
<result_rows>0</result_rows>
<read_rows>0</read_rows>
<execution_time>0</execution_time>
</interval>
</default>
</quotas>
<users>
<default>
<!-- 明文:123456 -->
<password_sha256_hex>8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92</password_sha256_hex>
<networks>
<ip>::/0</ip>
</networks>
<profile>default</profile>
<quota>default</quota>
<access_management>1</access_management>
</default>
</users>
</clickhouse>⚠️注意:
如果不配置以上配置文件,使用CK默认的配置,在新增用户并配置权限会出现以下问题:DB::Exception: Could not insert user
testbecause there is no writeable access

2.启动CK服务
与之前不同,此处使用指定的配置文件启动,也就是上节的配置文件地址。
sh
./clickhouse server --config-file=/Users/admin/ck/config.xml
启动客户端,与之前一样。
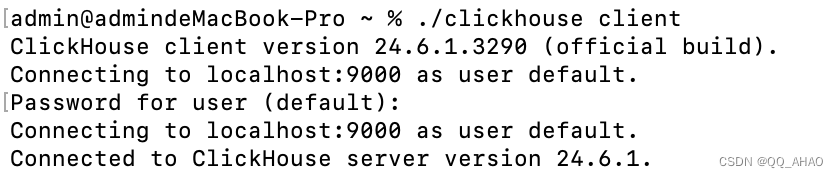
3.创建数据库
sql
CREATE DATABASE IF NOT EXISTS test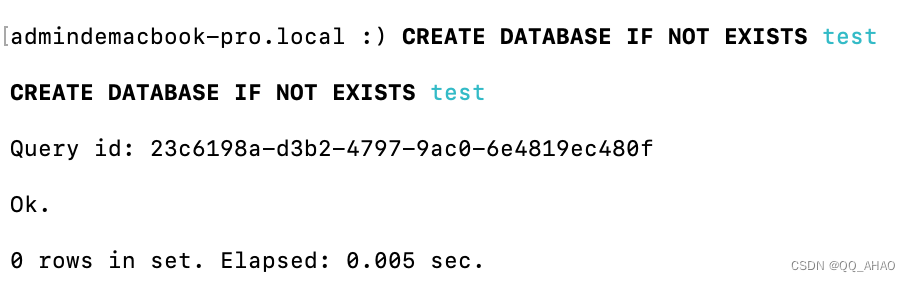
4.创建表
sql
CREATE TABLE IF NOT EXISTS test.t_users
(
`id` String COMMENT 'ID',
`name` Nullable(String) COMMENT '名称',
`age` Nullable(Int64) COMMENT '年龄',
`create_date` Nullable(Date) DEFAULT toDate(now()) COMMENT '创建时间'
) ENGINE = MergeTree
PRIMARY KEY(id);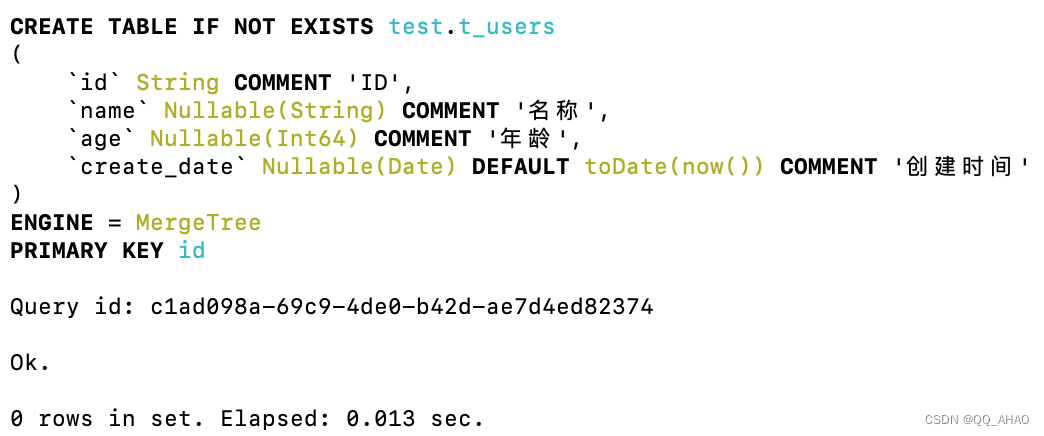
5.插入数据
sql
INSERT INTO test.t_users(id,name,age) VALUES (1, 'jack', 18)
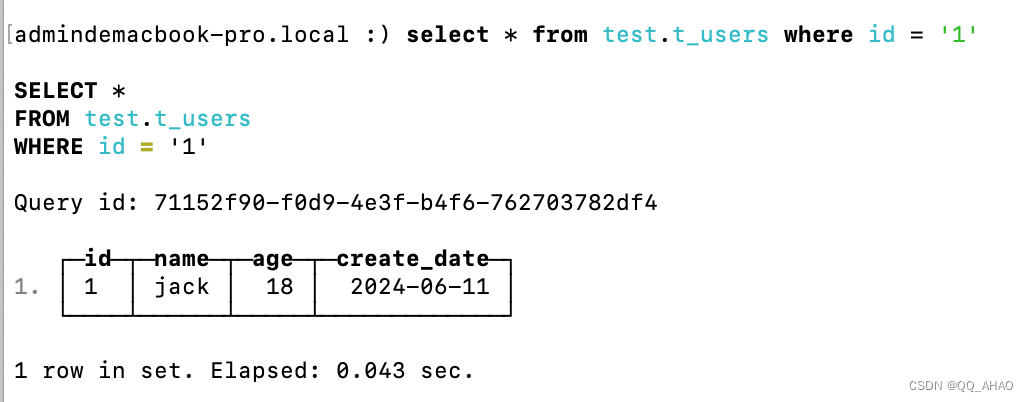
6.查询数据
sql
select * from test.t_users where id = '1'