举个简单的例子:使用spark官方用例"取pi值"
一、local模式
进入spark目录执行后台命令:
powershell
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[*] \
./examples/jars/spark-examples_2.12-3.2.1.jar \
10运行结果
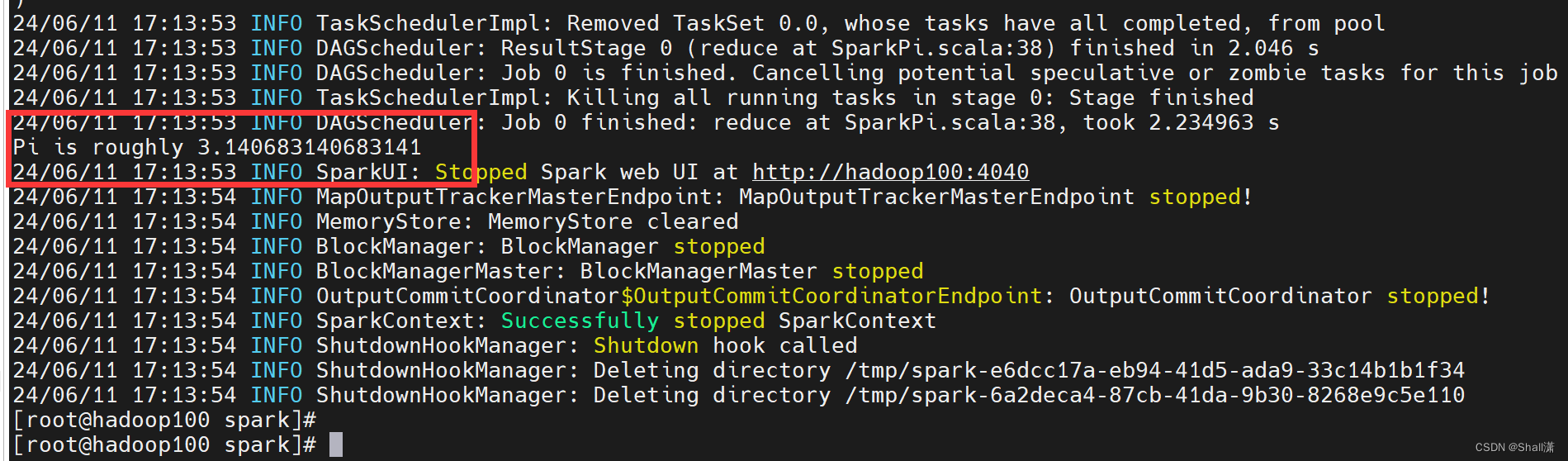
二、yarn模式
由于默认情况下,Spark作业只有在运行是可以通过web UI进行查看执行情况,任务一旦执行完,就看不了了,所以为了避免这种情况,我们通过配置历史进程将历史记录保存起来,仍可以在spark上查看。
【注意】:hadoop 3.0 端口号8020要改为 9000
1、配置spark-default.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop100:9000/directory
spark.yarn.historyServer.address=hadoop100:18080
spark.history.ui.port=18080
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop100:9000/directory
-Dspark.history.retainedApplications=30"
3、开启历史进程
sbin/start-history-server.sh
进入spark目录执行后台命令:
powershell
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
./examples/jars/spark-examples_2.12-3.2.1.jar \
10控制台运行结果:
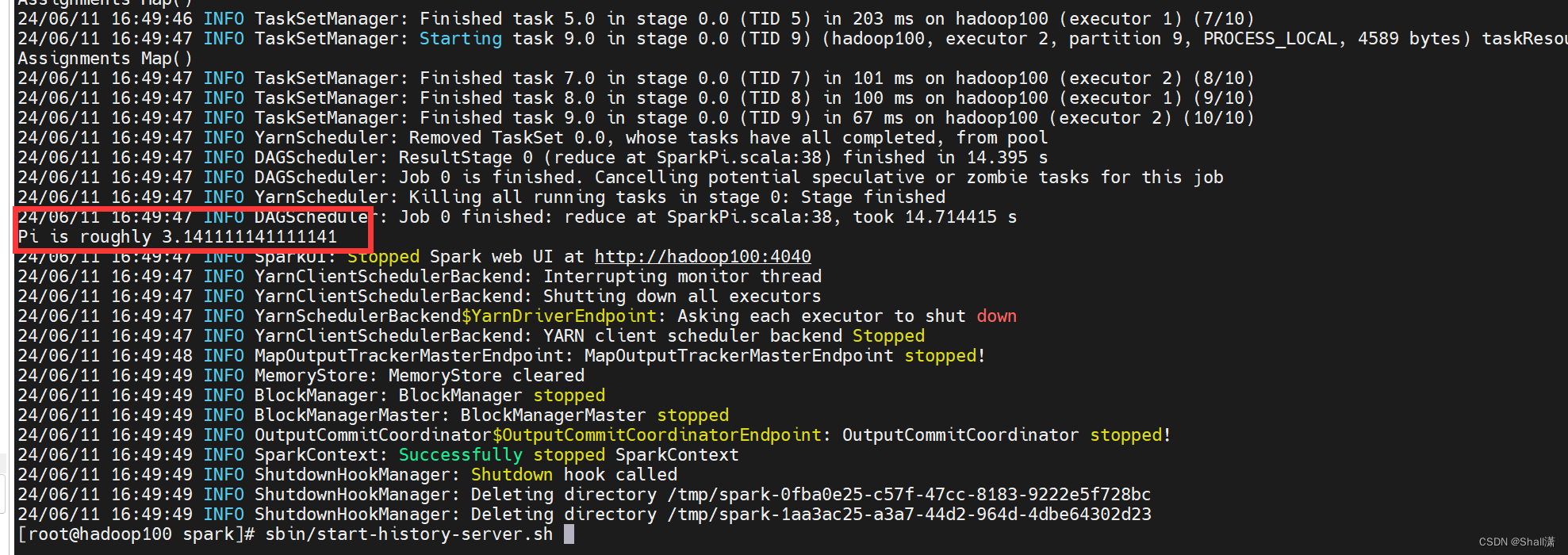
可以通过yarn上的历史记录查到spark的执行记录
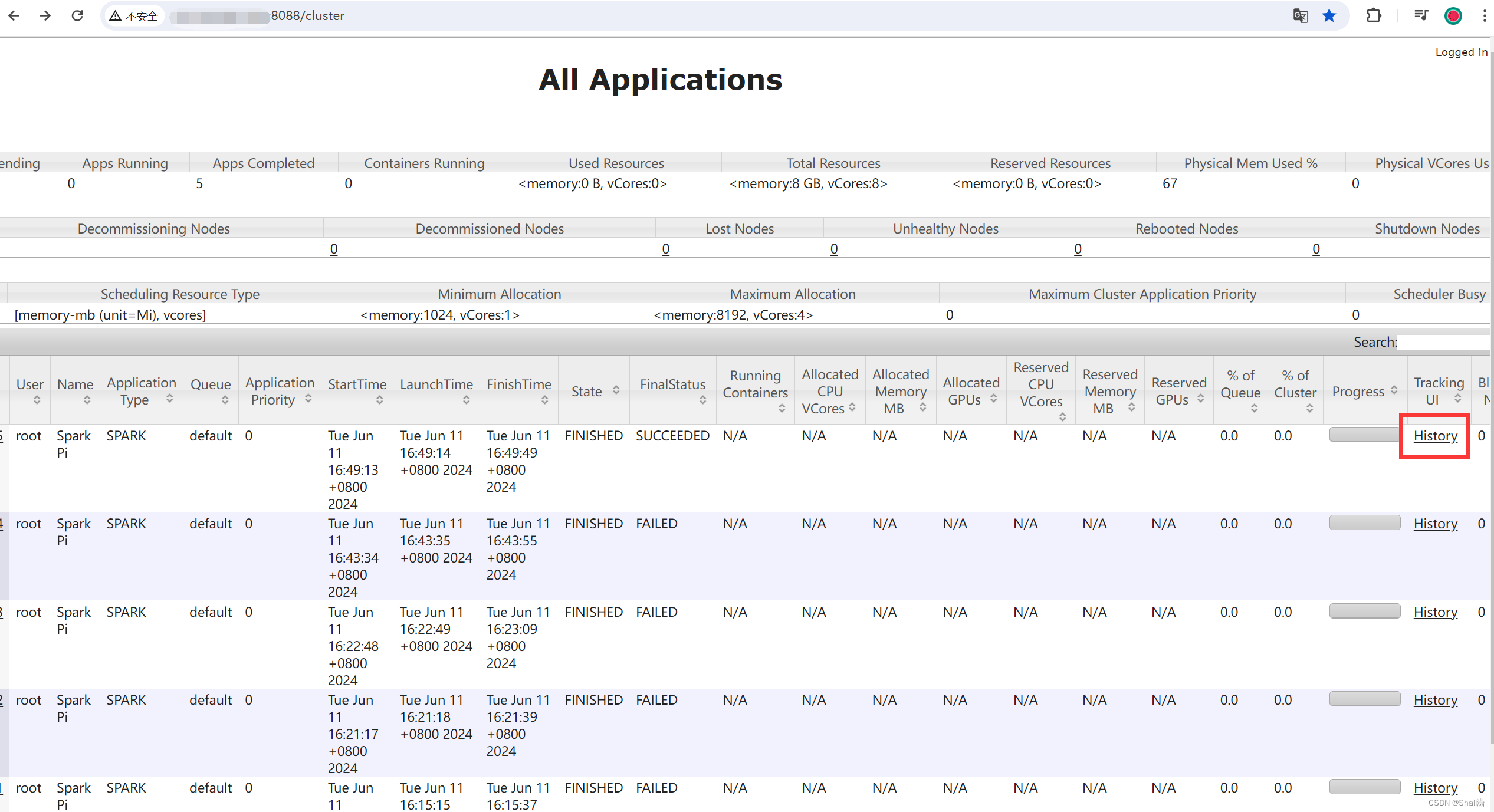
会自动跳转到spark的界面,更方便
