>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/0dvHCaOoFnW8SCp3JpzKxg) 中的学习记录博客**
>- **🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)**引言

一、前期准备
1.设置GPU
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
from torchvision import datasets
import torchvision.models as models
import torch.nn.functional as F
import torch.nn as nn
import torch,torchvision
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device2.获取类别名
import os,PIL,random,pathlib
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
data_dir = './015_licence_plate/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[1].split("_")[1].split(".")[0] for path in data_paths]
print(classeNames)
data_paths = list(data_dir.glob('*'))
data_paths_str = [str(path) for path in data_paths]
data_paths_str
3.数据可视化
plt.figure(figsize=(14,5))
plt.suptitle("数据示例(今晚2点水)",fontsize=15)
for i in range(18):
plt.subplot(3,6,i+1)
# plt.xticks([])
# plt.yticks([])
# plt.grid(False)
# 显示图片
images = plt.imread(data_paths_str[i])
plt.imshow(images)
plt.show()
4.标签数字化
import numpy as np
char_enum = ["京","沪","津","渝","冀","晋","蒙","辽","吉","黑","苏","浙","皖","闽","赣","鲁",\
"豫","鄂","湘","粤","桂","琼","川","贵","云","藏","陕","甘","青","宁","新","军","使"]
number = [str(i) for i in range(0, 10)] # 0 到 9 的数字
alphabet = [chr(i) for i in range(65, 91)] # A 到 Z 的字母
char_set = char_enum + number + alphabet
char_set_len = len(char_set)
label_name_len = len(classeNames[0])
# 将字符串数字化
def text2vec(text):
vector = np.zeros([label_name_len, char_set_len])
for i, c in enumerate(text):
idx = char_set.index(c)
vector[i][idx] = 1.0
return vector
all_labels = [text2vec(i) for i in classeNames]5加载数据文件
import os
import pandas as pd
from torchvision.io import read_image
from torch.utils.data import Dataset
import torch.utils.data as data
from PIL import Image
class MyDataset(data.Dataset):
def __init__(self, all_labels, data_paths_str, transform):
self.img_labels = all_labels # 获取标签信息
self.img_dir = data_paths_str # 图像目录路径
self.transform = transform # 目标转换函数
def __len__(self):
return len(self.img_labels)
def __getitem__(self, index):
image = Image.open(self.img_dir[index]).convert('RGB')#plt.imread(self.img_dir[index]) # 使用 torchvision.io.read_image 读取图像
label = self.img_labels[index] # 获取图像对应的标签
if self.transform:
image = self.transform(image)
return image, label # 返回图像和标签图片大小处理
划分数据集(4:1)
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_size,test_size
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=16,
shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset,
batch_size=16,
shuffle=True)
print("The number of images in a training set is: ", len(train_loader)*16)
print("The number of images in a test set is: ", len(test_loader)*16)
print("The number of batches per epoch is: ", len(train_loader))
for X, y in test_loader:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break二、自建模型构建
class Network_bn(nn.Module):
def __init__(self):
super(Network_bn, self).__init__()
"""
nn.Conv2d()函数:
第一个参数(in_channels)是输入的channel数量
第二个参数(out_channels)是输出的channel数量
第三个参数(kernel_size)是卷积核大小
第四个参数(stride)是步长,默认为1
第五个参数(padding)是填充大小,默认为0
"""
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24*50*50, label_name_len*char_set_len)
self.reshape = Reshape([label_name_len,char_set_len])
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool(x)
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.pool(x)
x = x.view(-1, 24*50*50)
x = self.fc1(x)
# 最终reshape
x = self.reshape(x)
return x
# 定义Reshape层
class Reshape(nn.Module):
def __init__(self, shape):
super(Reshape, self).__init__()
self.shape = shape
def forward(self, x):
return x.view(x.size(0), *self.shape)
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = Network_bn().to(device)
model显示网络结构
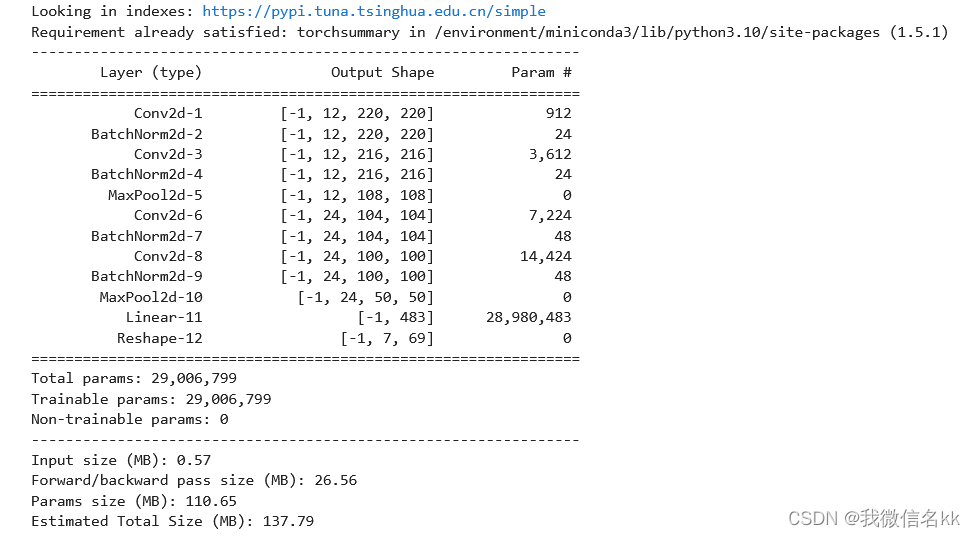
import torchsummary
''' 显示网络结构 '''
torchsummary.summary(model, (3, 224, 224))
三、训练模型
1.设置优化器和损失函数
optimizer = torch.optim.Adam(model.parameters(),
lr=1e-4,
weight_decay=0.0001)
loss_model = nn.CrossEntropyLoss()
from torch.autograd import Variable
def test(model, test_loader, loss_model):
size = len(test_loader.dataset)
num_batches = len(test_loader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in test_loader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_model(pred, y).item()
test_loss /= num_batches
print(f"Avg loss: {test_loss:>8f} \n")
return correct,test_loss
def train(model,train_loader,loss_model,optimizer):
model=model.to(device)
model.train()
for i, (images, labels) in enumerate(train_loader, 0): #0是标起始位置的值。
images = Variable(images.to(device))
labels = Variable(labels.to(device))
optimizer.zero_grad()
outputs = model(images)
loss = loss_model(outputs, labels)
loss.backward()
optimizer.step()
if i % 1000 == 0:
print('[%5d] loss: %.3f' % (i, loss))正确率的计算
计算匹配的数量和准确率的代码片段中使用的逻辑基于以下假设和步骤:
1. **匹配数量计算**:
- `pred_classes == true_classes`: 这是一个元素级别的比较,其中 `pred_classes` 是模型预测的类别索引,而 `true_classes` 是实际的类别索引。这个比较返回一个由布尔值组成的张量,表示每个位置的预测是否正确。
- `.sum()`: 这个函数计算了上述比较张量中所有 `True` 值的数量,即正确预测的数量。
- `.item()`: 将结果转换为一个标准的Python数值。
2. **平均损失计算**:
- `total_loss`: 这是在训练过程中累计的所有批次损失的总和。
- `len(train_loader)`: 这是训练数据加载器中的批次总数。
- `total_loss / len(train_loader)`: 这个除法操作计算了所有批次损失的平均值。
3. **准确率计算**:
- `correct`: 这是在训练或测试过程中累计的总正确预测数量。
- `size`: 这是数据集中样本的总数。
- `7`: 这个数字代表每个样本的类别数量。在你的上下文中,它可能表示每个样本有7个类别的标签,或者每个样本有7个独立的预测任务。
- `correct / (size * 7)`: 这个除法操作计算了准确率。这里假设 `correct` 已经包含了所有样本中每个类别的正确预测总数。如果 `correct` 是每个批次正确预测的累计和,那么乘以7意味着我们考虑了每个样本的所有类别。然后,除以 `size * 7` 给出了整体的平均准确率。
这种准确率的计算方式适用于多标签分类问题,其中每个样本有多个相关的标签,并且我们对每个标签的预测都是独立的。然而,如果 `7` 并不代表每个样本的类别数量,或者如果 `correct` 的计算没有考虑到所有相关的预测,那么这种计算方法可能不适用。
如果每个样本只有一个标签,那么 `correct` 应该是一个简单的计数,记录了预测正确的样本数,而 `accuracy` 应该是 `correct` 除以 `size`(样本总数)。如果每个样本有多个标签,并且你希望计算所有标签的平均准确率,则需要使用上述方法。但是,确保 `correct` 的计算反映了所有相关预测的总数。4.正式训练
test_acc_list = []
test_loss_list = []
epochs = 30
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(model,train_loader,loss_model,optimizer)
test_acc,test_loss = test(model, test_loader, loss_model)
test_acc_list.append(test_acc)
test_loss_list.append(test_loss)
print("Done!")
四、结果可视化
import numpy as np
import matplotlib.pyplot as plt
x = [i for i in range(1,31)]
plt.plot(x, test_loss_list, label="Loss", alpha=0.8)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.show()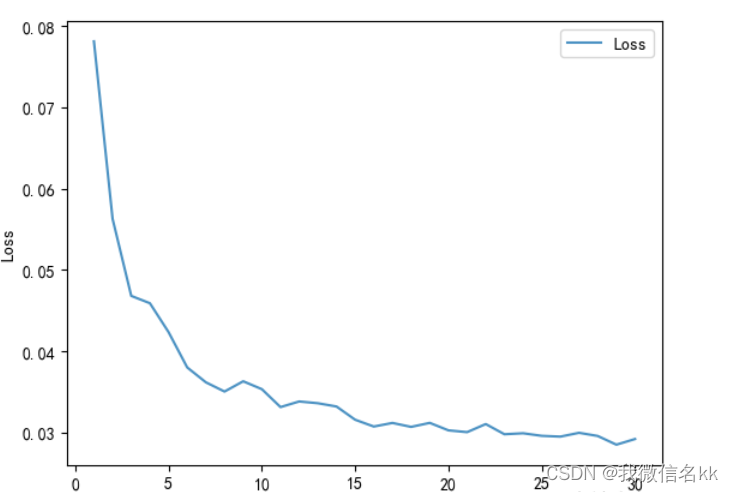
五,总结
本次导入数据集方式不同,数据集未分类,我们需要先获取类别名,然后标签数字化,在加载数据文件。
本次网络结构由自己设计,卷积卷积池化卷积卷积全连接reshape,使用了批量归一化层来加速训练过程,并通过池化层来减少参数数量和防止过拟合。