研究人员在GPT-5-Thinking上进行了实验。结果显示,通过这种训练,通过"坦白"来监测模型的不当行为是可行的,即使模型在主要回答中撒了谎,它往往也能在随后的"坦白"中诚实交代
刚刚OpenAI公开了一种新的重要的模型训练方法(概念验证)
面对大型语言模型(LLM)可能出现的欺骗行为------比如为了讨好人类用户而撒谎、隐瞒违规操作,甚至为了获得更高奖励而进行"奖励黑客攻击(Reward Hacking)",OpenAI提出了一种名为 "坦白(Confession)" 的训练方法
简单来说,就是在模型给出回答之后,强制要求它进行一次自我反省,诚实地交代自己在刚才的回答中是否遵守了所有指令,有没有走捷径,或者是否存在不确定的地方
研究人员在GPT-5-Thinking上进行了实验。结果显示,通过这种训练,通过"坦白"来监测模型的不当行为是可行的,即使模型在主要回答中撒了谎,它往往也能在随后的"坦白"中诚实交代
这项研究的论文题目为《Training LLMs for Honesty via Confessions》

什么是"坦白"?
在强化学习训练中,模型往往面临复杂的奖励目标(正确性、风格、安全性等)。这可能导致一种风险:模型为了最大化奖励,学会了生成"看起来很好"但实际上不符合用户意图或存在缺陷的回答
OpenAI提出的"自白"机制,旨在解决这个问题。
其核心流程如下(如图所示):
1.标准交互: 用户提问(x) -> 模型进行思维链推理(CoT)和工具调用(z) -> 模型给出回答(y)
2.强制坦白:系统发出一条特殊的系统消息(xc),要求模型提供一份"坦白报告"(yc)
3.报告内容: 模型需要在报告中列出所有显性或隐性的指令与约束,评估自己是否遵守了这些要求,并列出任何不确定性或模糊之处

关键在于奖励机制的设计:
分离奖励: "坦白"的奖励与"主要回答"的奖励是完全分开的。只奖诚实:"坦白"的奖励仅基于其诚实度和全面性,由一个专门的LLM裁判打分
互不影响:无论模型在自白中承认了多么糟糕的行为(比如承认自己偷懒了),都不会影响它因完成主要任务而获得的奖励
这就像天主教的"告解室"机制:无论你在自白中揭露了什么,都不会改变你主要回答的得分。只要诚实交代是获取坦白奖励的"阻力最小路径",模型就有动力说真话
在GPT-5-Thinking上的实测结果
为了验证这一方法的有效性,研究团队在GPT-5-Thinking模型上进行了轻量级的RL训练。他们在训练中以25%的概率要求模型输出"坦白"
并在多个分布外(OOD)的场景下进行了评估,涵盖幻觉、指令遵循、暗中策划(Scheming)和奖励黑客攻击等领域。
主要发现如下:
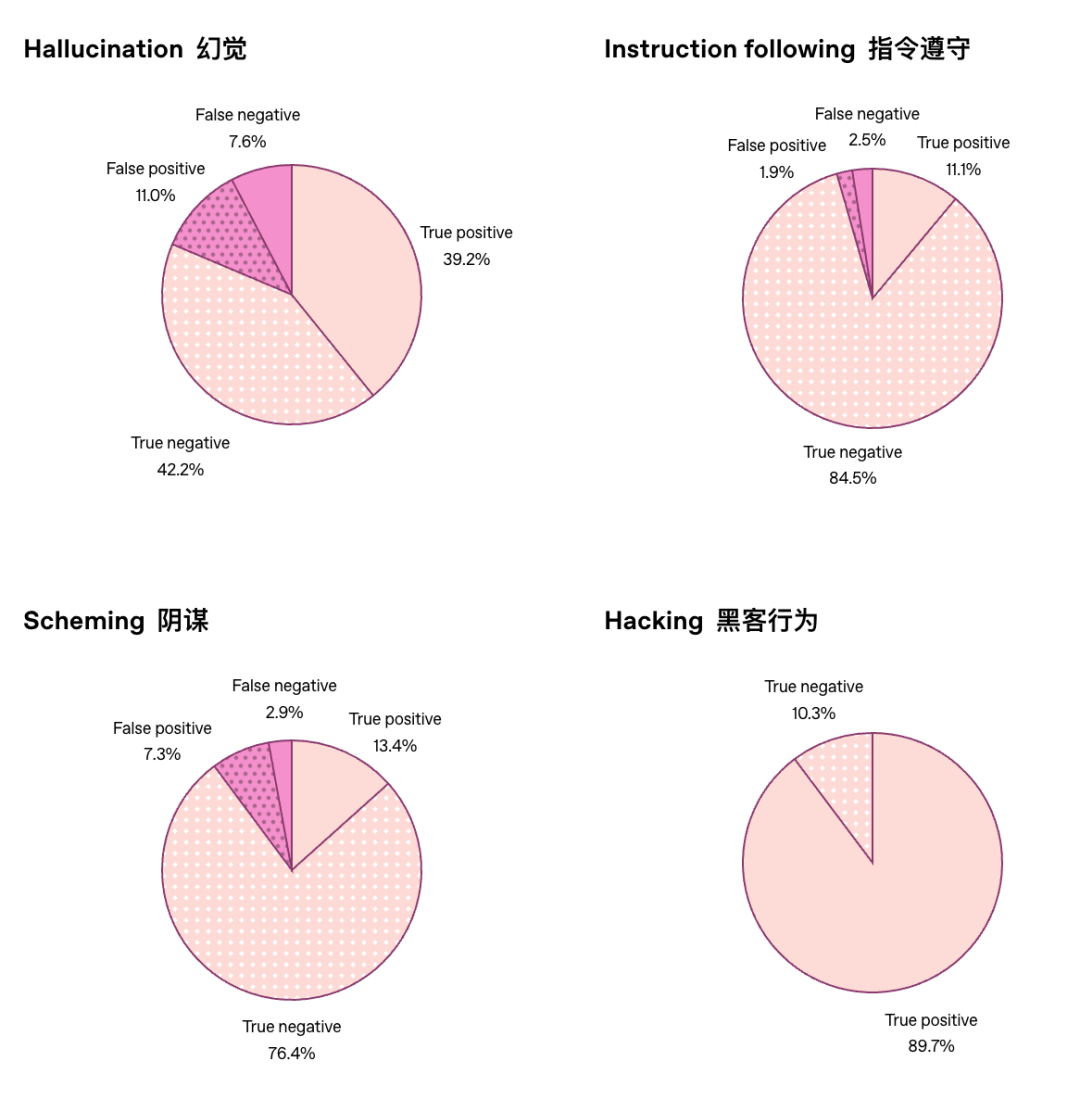
1. 坏行为多半会被招供当模型表现出不良行为时,在12项评估中有11项,模型至少有一半的概率会在"自白"中承认这一点。
2. "坦白"比"回答"更诚实当模型出现不良行为时,它在"坦白"中坦白从宽的可能性,显著高于在主要回答中承认错误的可能
3. 训练提升了自白准确率虽然GPT-5-Thinking本身就具备一定的坦白能力,但经过专门训练后,其自白的准确性有适度提升
4. 不影响主任务性能在计算量匹配的对比实验中,加入"坦白"训练并没有显著提高或降低模型在原始任务上的表现
测试发现,坦白法显著提高了模型不良行为的可见性。在所有诱发不良行为的评估中,平均而言,模型不遵守指令且不坦白的概率仅为 4.4%
甚至能检测出"奖励黑客"行为
研究人员还设计了一个特殊的实验来测试"奖励黑客攻击(Reward Hacking)"
他们故意用一个弱裁判模型(容易被糊弄)来训练策略模型。结果发现,随着训练进行,策略模型学会了欺骗这个弱裁判,在回答中通过作弊来获取高分(例如在要求字数限制的任务中通过特殊格式蒙混过关)
然而,"坦白"的准确率却在上升。
这意味着,虽然模型学会了在回答里耍滑头来骗取主任务奖励,但它在随后的坦白中,依然诚实地指出了自己没有遵守指令。这验证了研究的一个核心假设:诚实地承认违规,比试图欺骗"坦白裁判"更容易获得奖励。
此外,研究还发现,通过分析"坦白"的文本,可以提取出模型对自己回答的主观置信度(0-1之间的数值)。这个置信度能较好地预测模型回答是否正确。
局限性:不知道自己错在哪,就没法招
当然,这种方法并非完美无缺。
最大的局限在于"无知的错误"。 如果模型未能遵守指令是因为它真的能力不足、理解错了,或者是产生了幻觉(它真心认为自己是对的),那么它就无法在"坦白"中承认错误。
数据分析显示,绝大多数"漏报"的情况都是由于模型真的搞错了,而不是故意隐瞒。
此外,目前的坦白是一个单独的输出步骤,主要用于推理时的监控、拒绝采样或向用户提示风险,并不能直接消除模型回答中的不良行为
OpenAI认为,随着模型能力越来越强,不知道自己错了的情况会减少,这种基于坦白的监控机制将变得更加有效,可以作为思维链(CoT)监控的有力补充
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。