kettle_Hbase
☀Hbase学习笔记
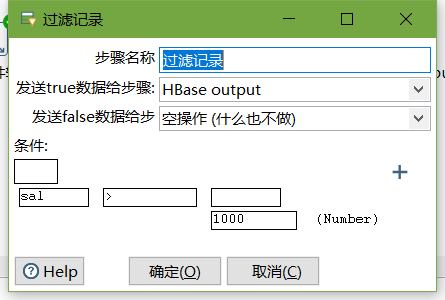
读取hdfs文件并将sal大于1000的数据保存到hbase中
前置说明:
1.需要配置HadoopConnect 将集群中的/usr/local/soft/hbase-1.4.6/conf/hbase-site.xml复制至Kettle中的
Kettle\pdi-ce-8.2.0.0-342\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp26目录中
2.配置Hadoop Cluster 中Zookeeper的Hostname为master,port为2181
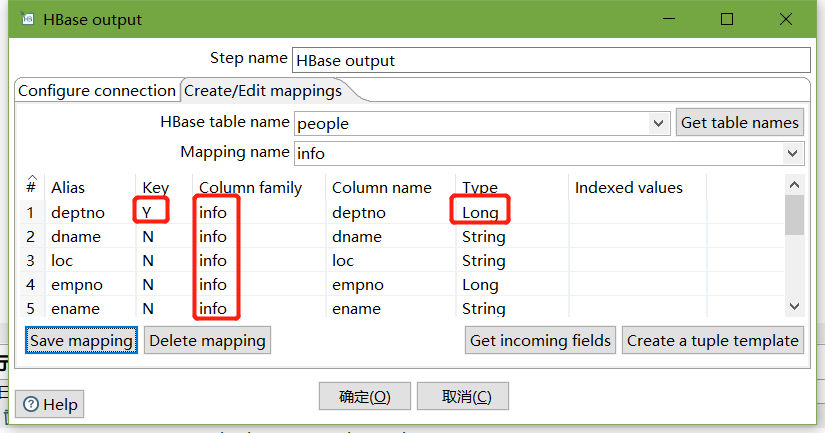
1、在HBase中创建一张people表
hbase(main):004:0> create 'people','info'2、按下图建立流程图
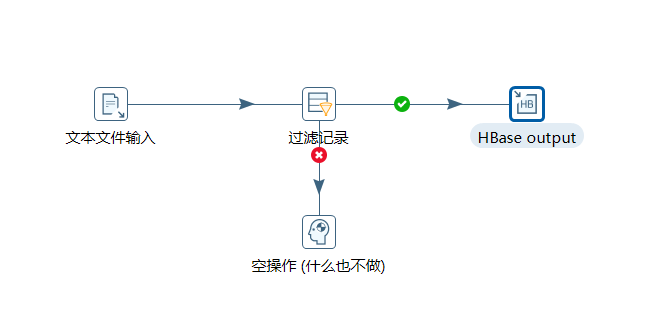
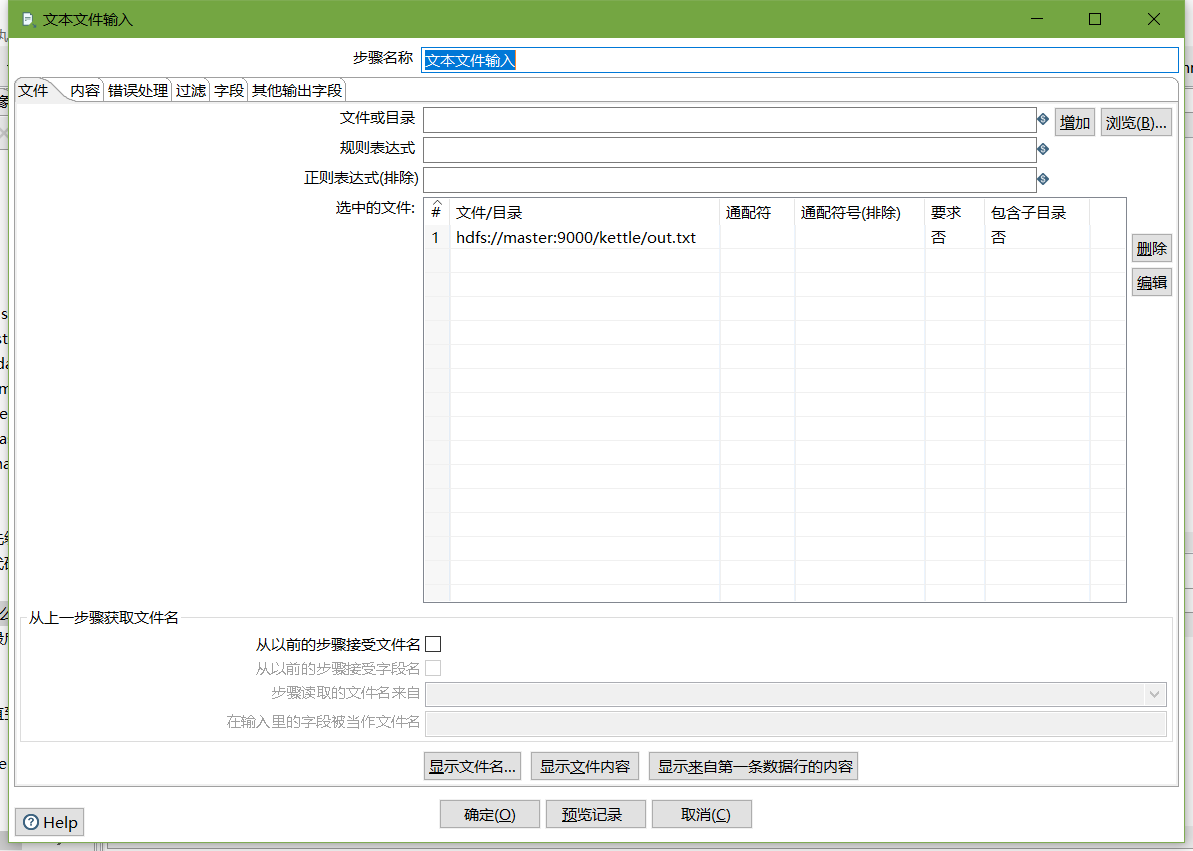
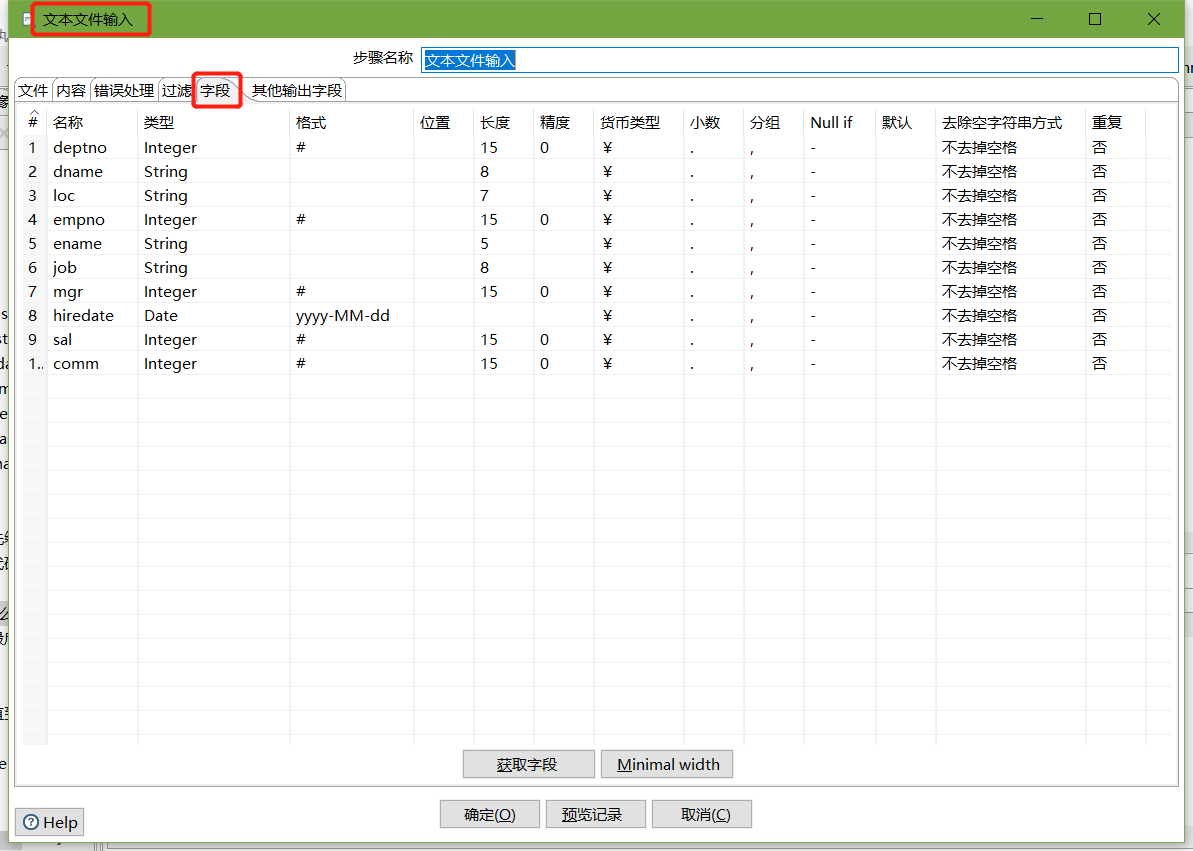
- 文本文件输入
- 设置过滤记录
-
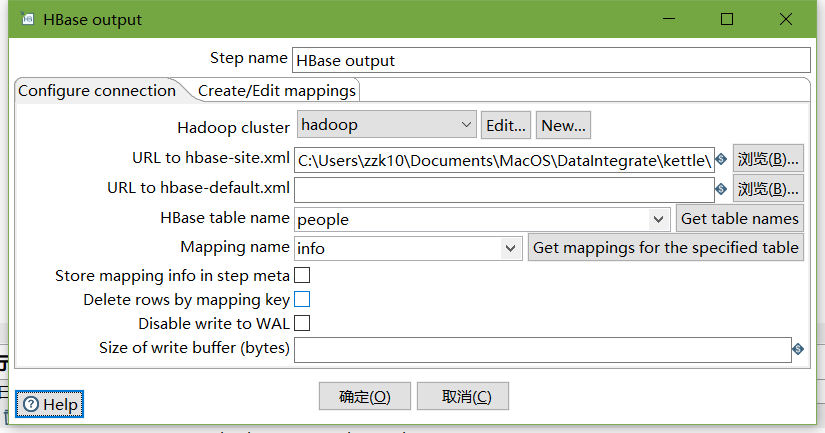
设置HBase output
编辑hadoop连接,并配置zookeeper地址
- 执行转换
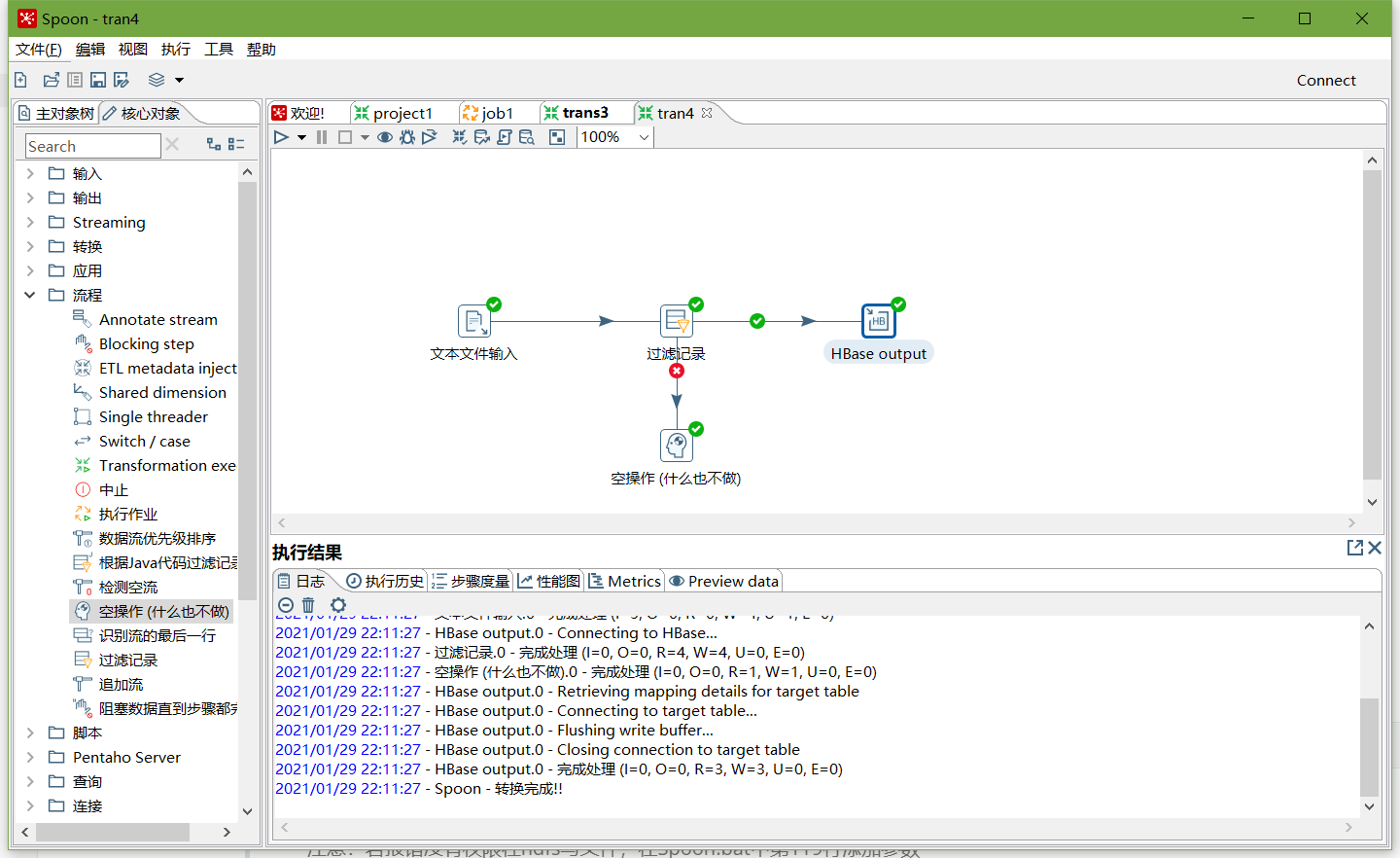
-
查看hbase people表的数据
scan 'people'注意:若报错没有权限往hdfs写文件,在Spoon.bat中第119行添加参数
"-DHADOOP_USER_NAME=root" "-Dfile.encoding=UTF-8"