几种经典查找算法
顺序查找法
顺序查找的平均查找长度为:


时间复杂度为0(n);
二分查找法
c
int binsearch(datatype* a,int n,datatype target)
{
int left=0;
int right=n-1;
int mid=(left+right)/2;
while(left<=right)
{
if(target<a[mid])
{
right=mid-1;
mid=(left+right)/2;
}
else if(target>a[mid])
{
left=mid+1;
mid=(left+right)/2;
}
else
return mid;
}
if(left>right)
return -1;
}我们来在主函数中测试一下:
c
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
typedef char datatype;
int binsearch(datatype*,int,datatype);
int main()
{
char arr[10]={'a','c','e','g','i','k','m','o','q','s'};
char x='m';
char y='z';
int xn=binsearch(arr,10,x);
int yn=binsearch(arr,10,y);
printf("%c:%d\n",x,xn);
printf("%c:%d\n",y,yn);
return 0;
}
int binsearch(datatype* a,int n,datatype target)
{
int left=0;
int right=n-1;
int mid=(left+right)/2;
while(left<=right)
{
if(target<a[mid])
{
right=mid-1;
mid=(left+right)/2;
}
else if(target>a[mid])
{
left=mid+1;
mid=(left+right)/2;
}
else
return mid;
}
if(left>right)
return -1;
}
结果正确。
下面是递归算法:
c
int binsearch2(datatype* a,int L,int R,datatype tar)
{
if(L<R)
return -1;
int mid=(L+R)/2;
if(a[mid]==tar)
return mid;
else
{
if(tar>a[mid])
return binsearch2(a,mid+1,R,tar);
else
return binsearch2(a,L,mid-1,tar);
}
}判定树
二分查找法的平均查找长度和查找效率可以从判定树 来看:
若把当前查找范围内居中的记录的位置 作为根结点,前半部分与后半部分的记录的位置 分别构成根结点的左子树与右子树,于是就得到了一棵成为"判定树"的二叉树。(此处的位置不是下标,位置从1开始)
例如:数组【2,5,7 ,11,14,16 ,19,23,27 ,32,50】,其判定树为:
 我们发现:成功的查找过程正好等于走了一条从根结点到被查找结点的路径,经历的比较次数恰好是被查找结点在二叉树中所处的层数。
我们发现:成功的查找过程正好等于走了一条从根结点到被查找结点的路径,经历的比较次数恰好是被查找结点在二叉树中所处的层数。
由此,我们可以得到二分查找法的平均查找长度:
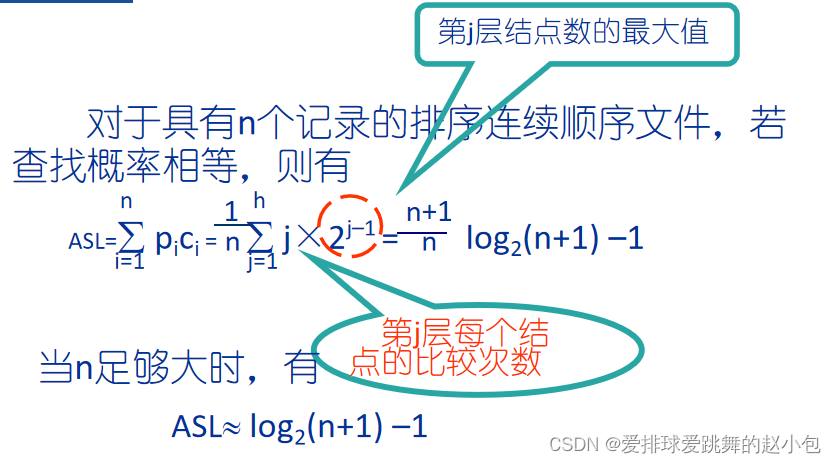 则上述案例的ASL为:(1 * 1 + 2 * 2 + 4 * 3 + 4 * 4)/ 11 = 23/11
则上述案例的ASL为:(1 * 1 + 2 * 2 + 4 * 3 + 4 * 4)/ 11 = 23/11
时间复杂度为O(logn)。
二分查找法适用于 :一经建立就很少改动(插入、删除),而又经常需要查找的查找表。
要使用二分查找法,必须满足:必须采用顺序存储结构,元素按值有序排列。
二叉查找树(BST)
二叉查找树可以同时兼顾查找和插入、删除操作的效率。
二叉树平衡的情况下,时间复杂度为:O(logn),退化的二叉树查找时间复杂度为:O(N)。
c
void searchBST(BTNodeptr p,int n)
{
BTNodeptr cur=p;
while(cur!=NULL)
{
if(n>cur->val)
{
cur=cur->right;
}
else if(n<cur->val)
{
cur=cur->left;
}
else
{
printf("%d ",cur->val);
break;
}
}
}这个查找算法经过一些微改,还可以用于打印根结点到某结点的路径等。
索引查找
类似于牛津字典旁边的ABCD......把首字母一样的分为一类,首字母即为所谓的"索引"。当然,在实际运用的过程中,索引可以根据具体情况具体分析。
索引表是一个DataType*类型的数组,索引表数组的每一个元素都是一个数组,当然你也可以用链表来记录每一个索引下的数据。这里的代码以数组中的数组为例(因为可以两次运用二分查找法,如果内部用链表的话内部的查找就只能用顺序查找了)。
c
typedef struct node
{
char index;//存放每个索引
int num;//存放该索引下的元素个数
char* stuff[100];//这个里面放该索引下的内容
//也可用链表:
//DataType* link;
}NODE;
void indexsearch(NODE a[],int n,char* target)
{
char index=target[0];
int left=0;
int right=n-1;
int mid;
while(left<=right)
{
//索引如果有序的话,可以直接用二分查找法
mid=(left+right)/2;
if(target>a[mid].index)
{
left=mid+1;
}
else if(target<a[mid].index)
{
right=mid-1;
}
else
break;
}
//有两种情况会跳出循环,第一种是找到了匹配的索引,通过break跳出
//第二种是没找到,通过left>right跳出循环,这一种可以直接返回没找到
//因为索引都没找到,那内容肯定更找不到了
if(left>right)
{
printf("no find");
return;
}
//如果找到索引了,就在索引里再用二分查找(顺序存储)
int left=0;
int right=a[mid].num-1;
while(left<=right)
{
mid2=(left+right)/2;
int cmp=strcmp(target,a[mid].stuff[mid2]);
if(cmp>0)
left=mid+1;
else if(cmp<0)
right=mid-1;
else
{
//找到了,根据具体要求做具体操作就行
}
}
}这个示例代码的作用类似字典,即索引表为单词首字母,然后现在索引表中找目标查找单词的索引,如果没找到(比如x开头的单词基本没有),那就直接返回,如果找到了,那就在找到的那部分索引中继续查找。
B-树
B-树的基本原理强烈大家去看b站

这个博主的视频!!!!ppt看了好久没搞明白但是博主动画一做就立马明白了真的讲的很清楚!
笔记这部分配图均来自上述博主及ppt,非本人原创↓
 一棵n阶B-树的特点:
一棵n阶B-树的特点:
- 根结点最少要有两个分支,最少要有一个元素
- 各个除根结点外分支节点最多有m个分支,m-1个元素;最少有【m/2】(向上取整)个分支,【m/2】-1个元素。
- 所有的叶结点都在同一层。教材们对B-树叶结点说法不统一,有些说上面红框子是叶子结点(也叫失败节点)。有些说是红框的上一层是叶结点。
- 各节点内部的元素是有序的
B树麻烦的地方在于它的插入
比如说,我们现在要在一个已有的3阶 B-树中插入元素20
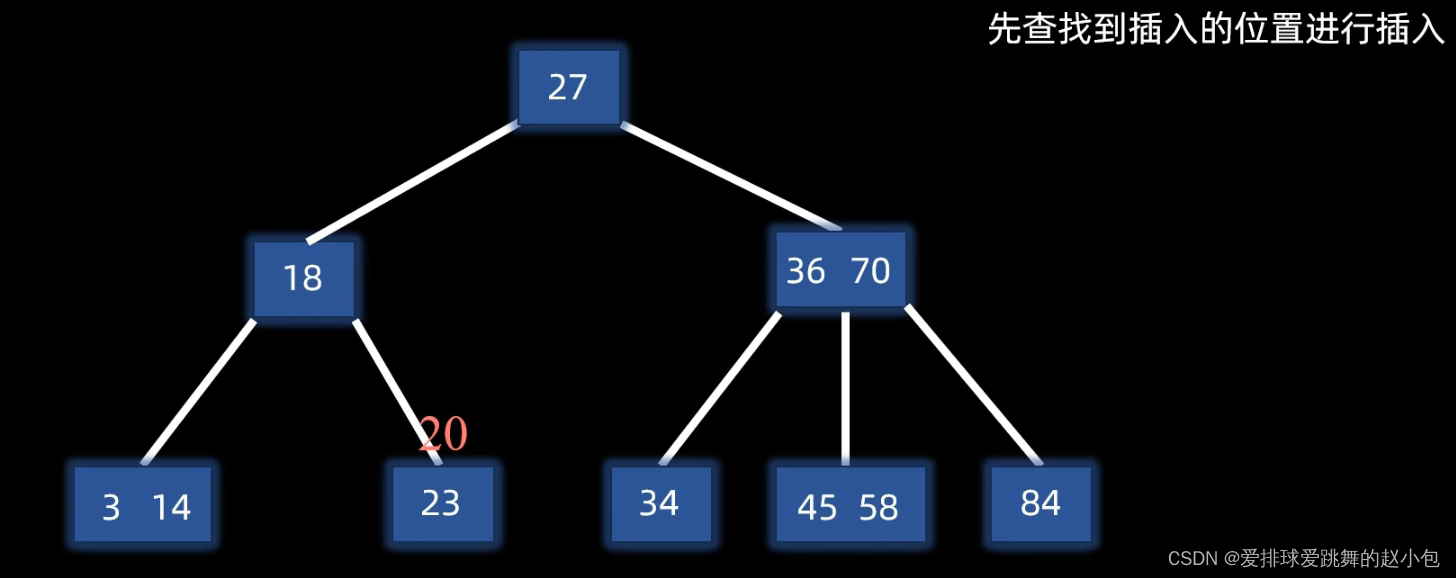 经过比较,发现20比23小,那就应该插在它的左边:
经过比较,发现20比23小,那就应该插在它的左边:
 插入之后,发现这个节点的元素个数是2,没有超过每个结点的最大元素个数2,所以性质并未被破坏,则无需调整。
插入之后,发现这个节点的元素个数是2,没有超过每个结点的最大元素个数2,所以性质并未被破坏,则无需调整。
但是,我们再来插入17:
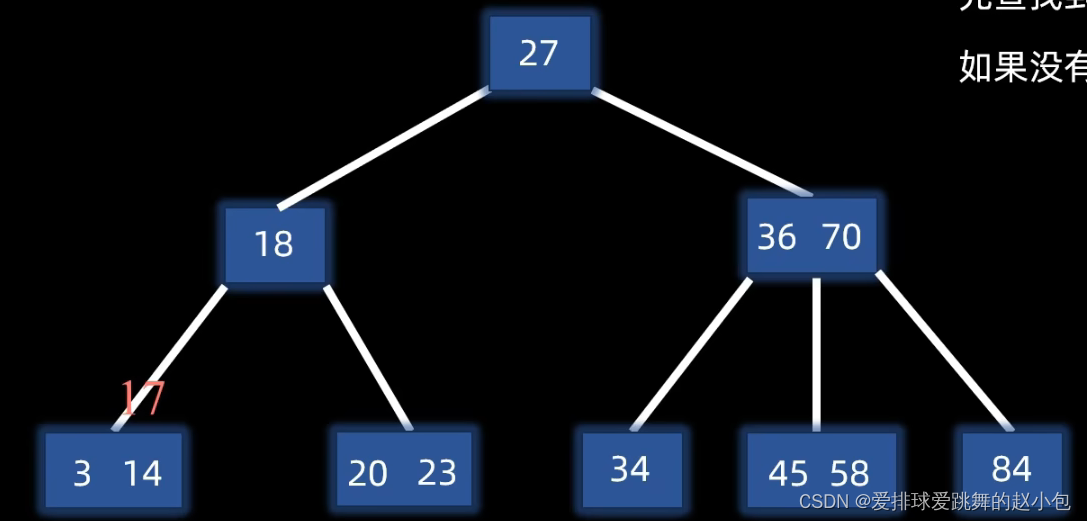
通过比较,发现应该插入14的右边
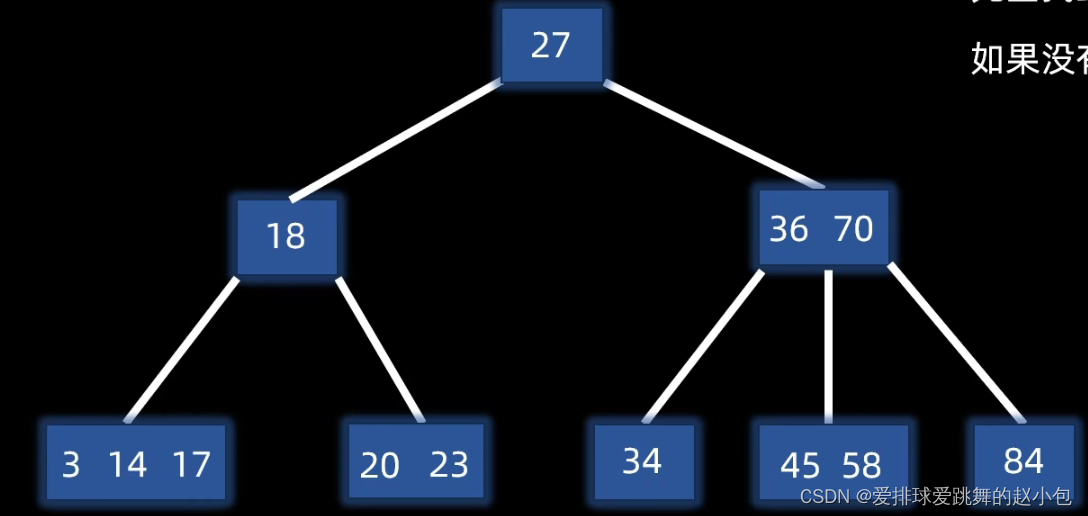
此时发现,该结点有3个元素,超出3阶B-树的最大元素个数,那么这个时候就需要分裂节点
以第【m/2】(上取整)个元素为中间结点,分为14左边,14,和14右边。
将14上移至父节点,而原来14的左边和右边,分别变为14在父节点中的左分支和右分支:
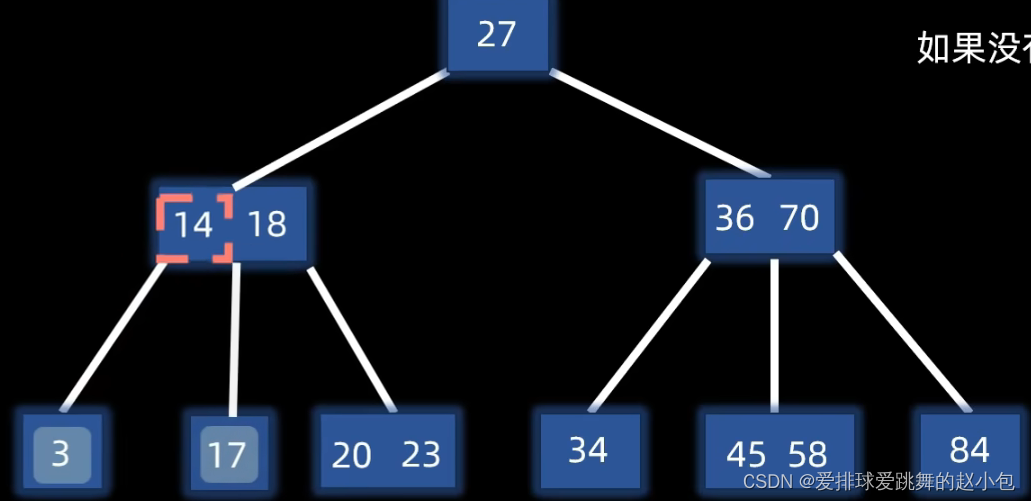 但如果,调整之后,父节点又超过最大元素了,怎么办呢?
但如果,调整之后,父节点又超过最大元素了,怎么办呢?
我们现在来插入元素53:
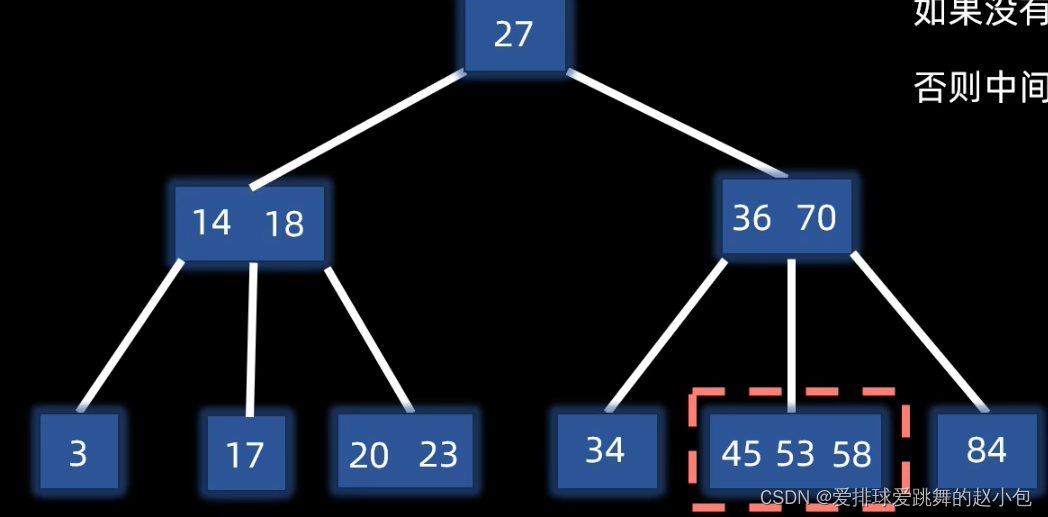 那么这个时候,需要以53为分割点,进行上移:
那么这个时候,需要以53为分割点,进行上移:
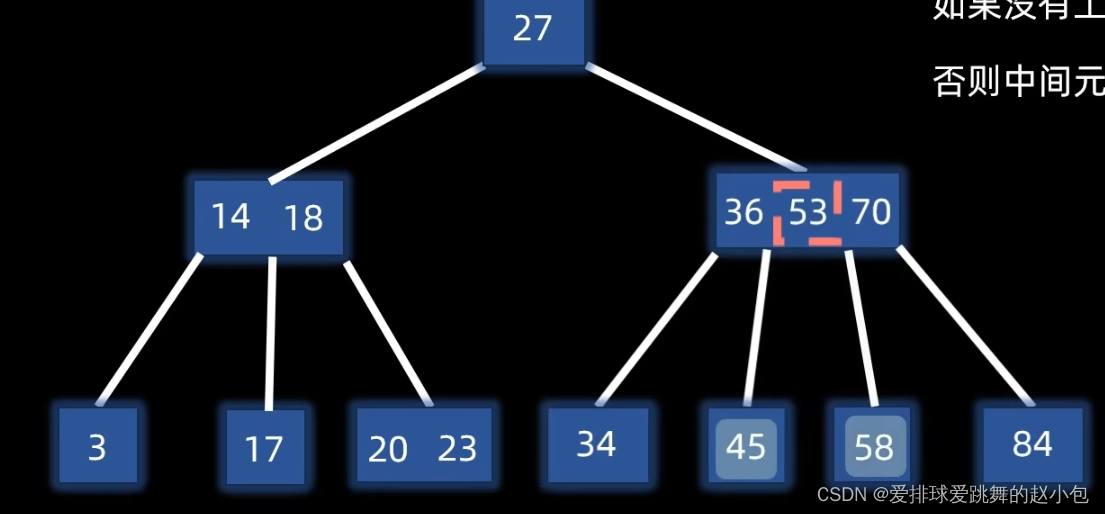 这个时候【36,53,70】这个节点又溢出了,那我们继续分裂这个节点。
这个时候【36,53,70】这个节点又溢出了,那我们继续分裂这个节点。
这个时候要注意,此时分裂节点时,被分裂的就不仅是一个元素了,而是一个子树。
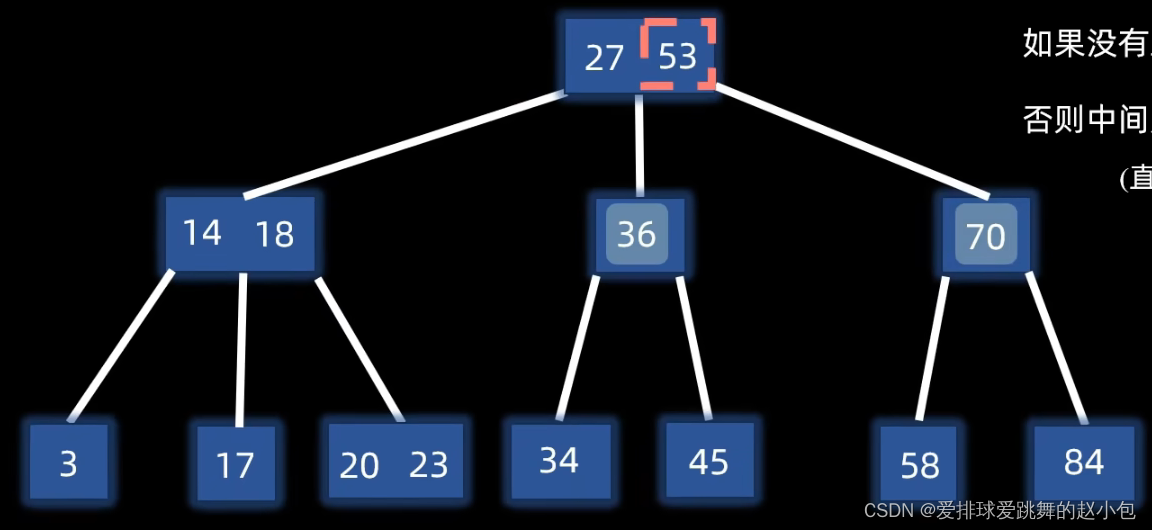
ok此时父节点没有发生溢出。但如果根结点也溢出了,就需要再向上分裂,此时树层数加一。
B+树
 B+树的特点:
B+树的特点:
(前三点与B-树同)
- m阶B+树的各个分支节点最多有m棵子树
- 除根结点外,每个分支节点最少有【m/2】(上取整)棵子树
- 根结点至少有两棵子树(除非他就是叶子结点)
从第四点开始,就是B+树不同于B-树的地方:
- 具有n棵子树的结点中,必有n个元素(B-树只有n-1个)
- 每个叶结点存放着记录的关键字以及指向记录的指针。(B-树是在每个结点中存储记录)
- 所有分支节点可以看做是索引的索引,结点中仅包含它的各个孩子中的最大值或最小值以及指向孩子结点的指针。
这是B-树和B+树的区别: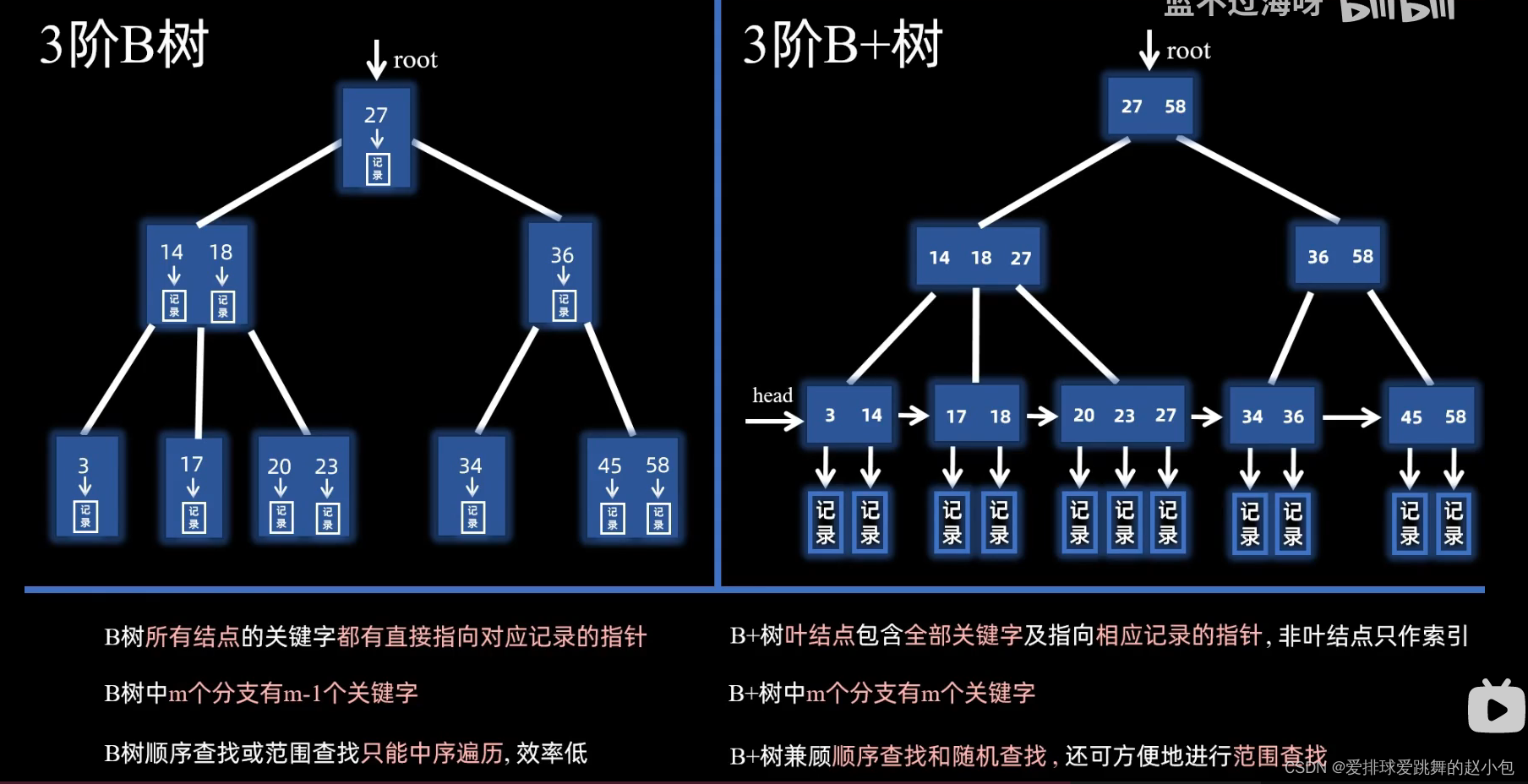
散列表(hash)查找
上述查找方式,多多少少都要进行关键字的比较,从而增加了时间复杂度。
那么有没有一种查找方式,不用经过任何关键字的比较,或者经过很少次关键字的比较,就能够达到目的的方法?
有,那就是哈希表,也叫散列表。

若 i ≠ j 但是,H(i) = H(j),也就是关键字不同,但散列地址相同,那么这种现象叫散列冲突。
一个好的散列表应该具备的特点是:
- 散列函数的定义域必须包括将要存储的全部关键字;
若散列表允许有m个位置时,则函数的值为0,......,m-1(地址空间) - 利用散列函数计算出来的地址应能尽可能均匀分布在整个地址空间中。
- 散列函数应该尽可能简单,应该在较短的时间内计算出结果。
建立散列表的步骤有:
- 确定散列的地址空间
- 构造合适的散列函数
- 选择处理冲突的方法
散列函数的构造方法有很多,我们最常用的就是:除留余数法
H(k)= k MOD p (p为小于等于m的素数)
冲突的处理方法也有很多,我们常用的是:链地址法 ,就是散列地址一样的链在后面。有点像日本鲤鱼旗那种感觉。。。
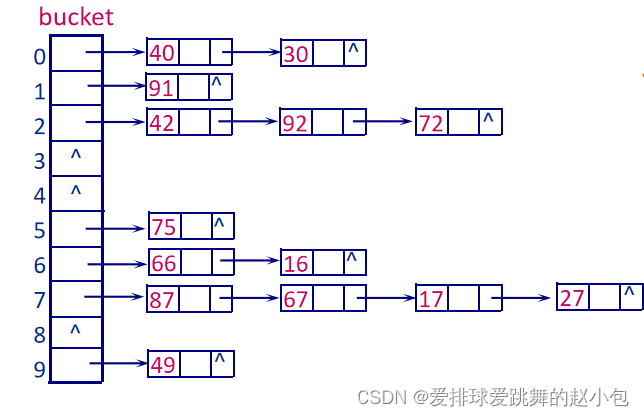
但是链表的查找效率比较低,所以我们可以换成一颗颗二叉搜索树。
下面的函数用于,查找哈希表中的某一个值,如果该值存在,则返回它的地址,如果不存在,则插入:
c
#define MAX 100
typedef struct node
{
int data;
struct node* next;
}NODE;
//因为有时经常需要按照一定的规律插入哈希表
//因此我们将哈希表每个位置的链表的头结点都设置为哨兵位
//这样方便头插
NODE* Hashtab[MAX];
NODE* find(int key)
{
unsigned int h;
NODE* cur;
h=hash(key);//这是散列函数,根据具体情况做
for(cur=Hashtab[h];cur->next!=NULL;cur=cur->next)
{
if(cur->next.data==key)
return cur->next;
}
//如果函数能进行到这个地方,就说明没找到,那就需要插入了,我们这里就进行尾插就行
NODE* new=(NODE*)malloc(sizeof(NODE));
new->data=key;
new->next=NULL;
cur->next=new;
cur=new;
return cur;
}OK,今天的分享就到这里了。