-
Batch Normalization 可以
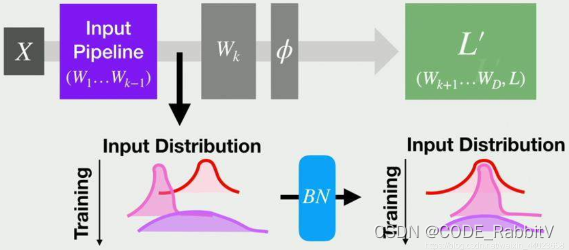
改善梯度消失/爆炸问题:前面层的梯度经过多次传递后会变得非常小(大),从而导致网络收敛速度慢(不收敛),应用 BN 可缓解加速网络收敛:BN 使得每个神经元的输入分布更加稳定减少过拟合:BN 可减少由于数据分布的变化导致的模型性能下降提高模型泛化能力:BN 使得模型对输入的微小变化更加稳定缓解超参敏感:对于 learning rate 等超参数敏感性降低- ...
-
Batch Normalization(BN):使 feature map 满足均值为 0,方差为 1 的分布规律
- 如果batch size为m,则在前向传播过程中,网络中每个节点都有m个输出,所谓的Batch Normalization,就是对该层每个节点的这m个输出进行归一化再输出
- 数学表达:每个 channel 下统计一个对应的均值和方差
x norm = x − E x V a r x + ϵ ∗ γ + β x_{\text{norm}} = \frac{x - \mathbb{E}x}{\sqrt{Varx+\epsilon}} * \gamma + \beta xnorm=Varx+ϵ x−Ex∗γ+β- 其中 γ , β \gamma, \beta γ,β 为可学习的参数
-
代码实践:
python3>>> import torch >>> import torch.nn as nn >>> >>> x = torch.rand(2,1,28,28) ## *0.创建输入 x >>> bn = nn.BatchNorm2d( ## *1. 创建 bn 层, 1, # -- 输入的 channel 数 training = False, # -- 是否为训练模式 affine = False) # -- 是否学习 γ β >>> out = bn(x) ## *2 获取输出 >>> # 查看相关数值 ------------------------------------------------ >>> bn.running_mean # 均值 tensor([0.0507]) >>> bn.running_var # 方差 tensor([0.9080]) >>> bn.weight # γ Parameter containing: tensor([1.], requires_grad=True) >>> bn.bias # β Parameter containing: tensor([0.], requires_grad=True)
PyTorch -- Batch Normalization(BN) 快速实践
CODE_RabbitV2024-06-16 5:05
相关推荐
i晟2 小时前
对齐:让模型学会“做人“小飞猪。。3 小时前
笔记十四:从零开始搞懂 DPO——大模型偏好对齐的“直球”方案OceanBase数据库官方博客9 小时前
OceanBase DataPilot AIP:Ontology 承载AI能力面的另一条路笨鸟先飞,勤能补拙10 小时前
AI 赋能网络安全:技术全景、成熟度评估与实战案例一次旅行10 小时前
AI 前沿日报 | 2026年07月31日2601_9637491010 小时前
标题:越华环保集团|面向美丽河湖项目的数字化污水治理云边协同采集架构设计沐籽李10 小时前
从溶剂可及表面积SASA理解抗体结构与工程改造智慧物业老杨10 小时前
物业如何做好预算管理?落地架构逻辑微学AI10 小时前
一根针指向所有方向:挂谷猜想对 LLM Agent 技能-记忆架构的启示城管不管10 小时前
ReAct、Plan-and-Execute、Reflection 三大智能 Agent 范式核心区别