1 下载解压Datax tar包
下载到自己指定的安装目录
#wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
进行解压
tar -zxvf datax.tar.gz
2 Datax验证
#修改datax/bin目录下datax.py的权限
chmod 777 datax/bin/datax.py
2.1运行官方给定的任务案例
cd $DATAX_HOME
bin/datax.py job/job.json

任务执行成功
2.2编写个人任务案例
需求:读取 MySQL 中的数据存放到 HDFS
2.2.1准备数据
登录MySQL创建student表,并插入数据
mysql -u root -p
mysql> use test;
mysql> > create table student(id int,name varchar(20));
mysql> insert into student values(1001,'zhangsan'),(1002,'lisi'),(1003,'wangwu');
2.2.2查看官方配置文件模板
python $DATAX_HOME /bin/datax.py -r mysqlreader -w hdfswriter
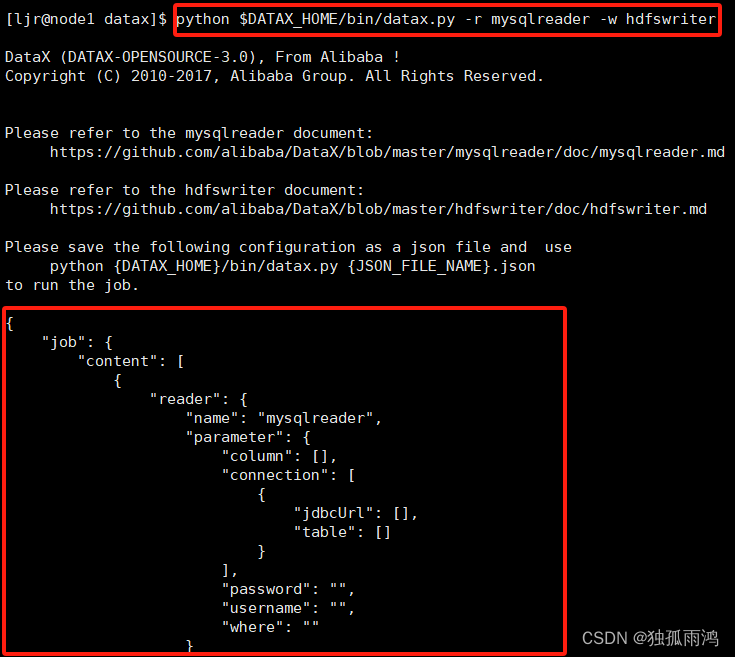
2.2.3编写配置文件
vim $DATAX_HOME /job/mysqlhdfs.json
{ "job": { "content": { "reader": { "name": "mysqlreader", "parameter": { "column": \[ "id", "name" , "connection": { "jdbcUrl": \[ "jdbc:mysql://node1:3306/test" , "table": "student" } ], "username": "root", "password": "1234" } }, "writer": { "name": "hdfswriter", "parameter": { "column": { "name": "id", "type": "int" }, { "name": "name", "type": "string" } , "defaultFS": "hdfs://node1:8020", "fieldDelimiter": "\t", "fileName": "student.txt", "fileType": "text", "path": "/", "writeMode": "append" } } } ], "setting": { "speed": { "channel": "1" } } }
2.2.4执行任务
cd $DATAX_HOME
bin/datax.py job/mysqlhdfs.json
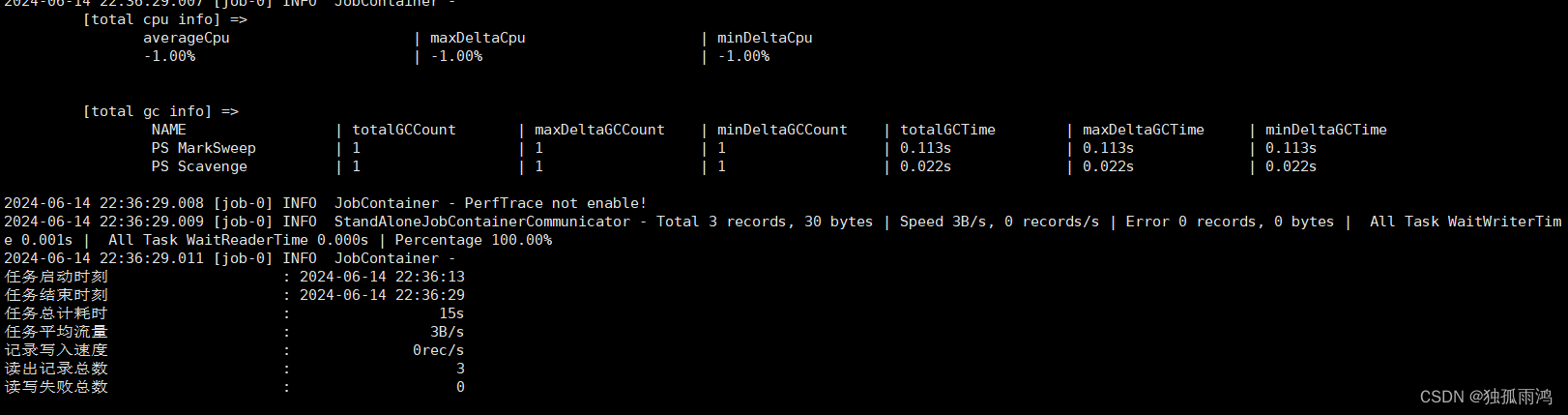
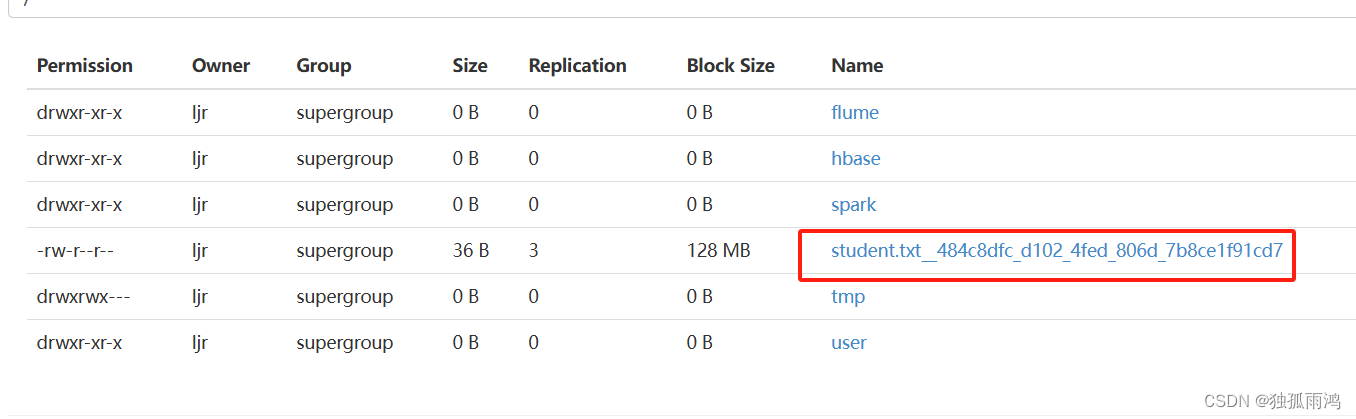
任务执行成功
查看 hdfs