引言
中国与英国的研究团队携手合作,开创了一种创新的视频面孔重塑技术。这项技术能够以极高的一致性对视频中的面部结构进行逼真的放大和缩小,且避免了常见伪影的产生。
从研究人员选取的YouTube视频样例中可见,经过处理后,女演员詹妮弗·劳伦斯的面容显得更加瘦削(如图右方所示)。欲观看更高分辨率的示例,请参阅文章底部的嵌入式视频。该技术源自链接:视频链接
传统上,此类面部变换需要借助复杂的CGI方法实现,这不仅成本高昂,还涉及到繁琐的动作捕捉、绑定和纹理处理流程,以完整重建面部特征。
然而,这项新技术另辟蹊径,将CGI与神经网络管道相结合,作为参数化的3D面部信息处理的一部分。这种方法随后构成了机器学习工作流程的基础,为视频编辑和面部动画领域带来了革命性的变革。

概述
传统的参数化面孔技术越来越多地被用作利用人工智能(AI)而非计算机生成图像(CGI)的变革性过程的指导原则。在这项研究中,作者们提出了一个目标:
"我们的目标是根据现实世界中的自然面部变形编辑人像面部的整体形状,生成高质量的人像视频重塑结果。这可用于诸如用于美化的匀称脸部生成和用于视觉效果的脸部夸张等应用。"
自从Photoshop这类图像编辑软件普及以来,消费者已经能够对2D图像进行面部扭曲和变形的操作。然而,这些操作有时会导致不自然甚至令人难以接受的结果,特别是当涉及到身体畸形的图像处理时。作者指出,尽管在静态图像上的应用相对成熟,但在视频上实现类似的面部变形技术,如果不借助CGI,仍然是一个挑战。这项研究的成果,旨在通过AI技术,使得在视频内容中进行面部重塑变得更加容易和高效,同时保持高质量和连贯性。

形体重塑,或称为人体形态编辑,是计算机视觉领域中一个非常活跃的研究方向。它涉及到使用人工智能算法来修改和调整人体图像或视频中的形态特征,例如身高、体型或骨骼结构。这项技术在时尚电子商务中具有巨大的应用潜力,例如,允许顾客在购买前预览服装在不同体型上的效果。
然而,这项技术面临着一些挑战。例如,使某人看起来更高或改变其骨骼结构,需要在不扭曲背景或周围环境的情况下,对图像进行复杂的几何变换。这在技术上是非常困难的,因为需要考虑人体和服装的三维结构,以及它们与环境的交互。
关于使用人工智能技术重塑人体形态的研究。这项研究提出了一种新的方法,通过深度学习模型来改善人体形态的编辑,使得结果更加自然和逼真。
关于改变视频中头部形状的研究。这项工作尝试在视频序列中以一种连贯和令人信服的方式改变人物的头部形状,但可能会受到一些技术限制的影响。
关于新系统的训练环境和使用的技术的描述。这个系统在一台高性能的台式电脑上进行训练,使用了多种技术和工具,包括OpenCV库进行运动估计、结构流框架进行图像修复、面部对齐网络(FAN)进行面部特征点的检测,以及Ceres求解器进行优化问题求解。
这些技术结合起来,使得新系统能够处理更为复杂的任务,比如从静态图像编辑扩展到视频编辑,提高编辑结果的质量和真实感。随着技术的不断进步,我们可以期待在未来形体重塑技术将更加成熟,应用范围也会更加广泛。

关于人脸
在新系统下,视频被提取为图像序列,并且首先估计每张脸的刚性姿势。 然后,联合估计代表性数量的后续帧,以沿着整个图像运行(即视频的帧)构建一致的身份参数。
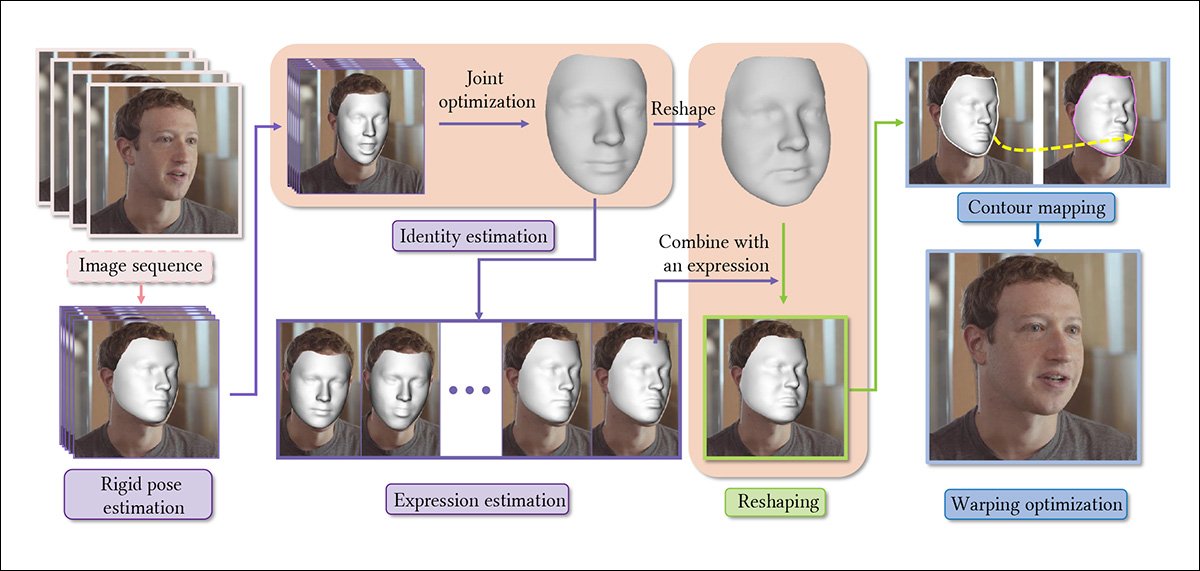
之后,对表达式进行求值,产生通过线性回归实现的重塑参数。接下来是一个新颖的有符号距离函数(自卫队)方法在重塑之前和之后构建了面部轮廓的密集二维映射。
最后,对输出视频执行内容感知的扭曲优化。
参数化面
该过程利用了 3D Morphable Face Model (3DMM),这是一种日益流行的技术。 流行的辅助语t 到基于神经和 GAN 的人脸合成系统,以及 相应 用于深度伪造检测系统。
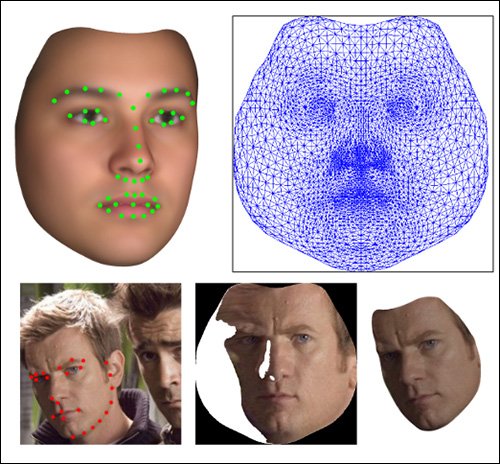
不是来自新论文,而是 3D Morphable 脸部模型 (3DMM) 的示例 - 新项目中使用的参数化原型脸部。 左上角,3DMM 面上的地标应用。 右上方是等位图的 3D 网格顶点。 左下角显示地标拟合; 中下,提取的面部纹理的等位图; 右下角是最终的装配和形状。_ 资料来源:http://www.ee.surrey.ac.uk/CVSSP/Publications/papers/Huber-VISAPP-2016.pdf
新系统的工作流程必须考虑遮挡的情况,例如主体将视线移开的情况。 这是 Deepfake 软件面临的最大挑战之一,因为 FAN 地标几乎没有能力解释这些情况,并且随着面部避开或被遮挡,质量往往会下降。
新系统能够通过定义一个 轮廓能量 它能够匹配 3D 人脸 (3DMM) 和 2D 人脸(由 FAN 地标定义)之间的边界。
优化
这种系统的一个有用部署是实现实时变形,例如在视频聊天过滤器中。 当前的框架无法实现这一点,并且所需的计算资源将使"实时"变形成为一个显着的挑战。
根据该论文,假设视频目标为 24fps,管道中的每帧操作表示每秒镜头的延迟为 16.344 秒,另外还有用于身份估计和 3D 面部变形的一次性命中(分别为 321 毫秒和 160 毫秒) 。
因此,优化是降低延迟方面取得进展的关键。 由于跨所有帧的联合优化会给过程增加严重的开销,并且初始化式优化(假设第一帧中说话者的后续身份一致)可能会导致异常,因此作者采用了稀疏模式来计算系数以实际间隔采样的帧数。
然后对该帧子集执行联合优化,从而实现更精简的重建过程。
脸部变形
该项目中使用的变形技术改编自作者 2020 年的作品 深邃匀称的肖像 (数字信号处理器)。
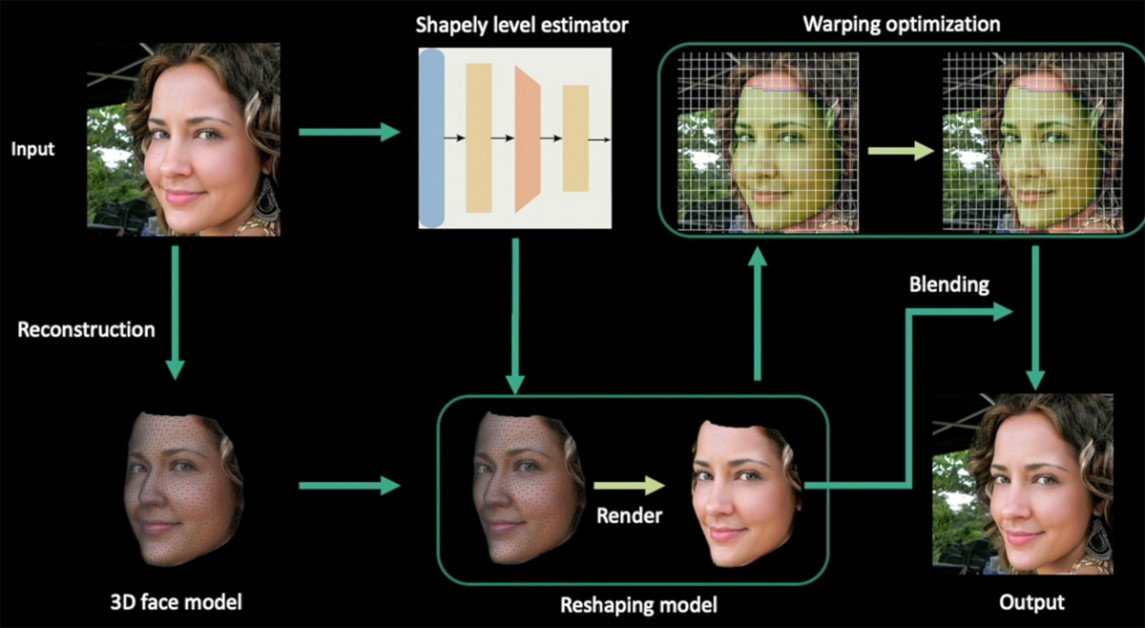
Deep Shapely Portraits,2020 年提交给 ACM Multimedia 的作品。 该论文由浙江大学-腾讯游戏与智能图形创新技术联合实验室的研究人员领导。 来源:http://www.cad.zju.edu.cn/home/jin/mm2020/demo.mp4
作者观察到 "我们将这种方法从重塑一个单眼图像扩展到重塑整个图像序列。"
检测
该论文指出,没有可比的现有材料来评估新方法。 因此,作者将扭曲视频输出的帧与静态 DSP 输出进行了比较。

作者指出,由于 DSP 方法使用了稀疏映射,因此出现了伪影,而新框架通过密集映射解决了这个问题。 此外,该论文还指出,DSP 制作的视频, 演示 缺乏流畅度和视觉连贯性。