协程(coroutine)是一种比线程更轻量级的并发执行单位,他们允许函数在执行过程中阻塞暂停,,并在需要的时候恢复执行,,从而实现协作式多任务处理,,跟传统的线程不同,协程不需要依赖操作系统的调度,,因为始终都在一个线程里,,里面有一个 event_loop 去监测哪一部分需要阻塞,,一但阻塞,就切换到不被阻塞的代码执行,,
通过 await 进行挂起和恢复,,,异步IO
xpath获取页面内容
py
from lxml import etree
etree.xpath(...)开启协程:
py
asyncio.run(方法名)
# 或者
# 事件轮询 监测函数
event_loop = asyncio.get_event_loop()
event_loop.run_until_complete(main())协程函数,都有一个关键字async
py
async def mian():
# 创建任务 asyncio.create_task(...)
# 等待所有任务执行完成. ,,, done:已经完成的任务,,是一个set对象,无序的,, 通过t.result()返回协程任务的返回值,,如果想要是有序的,使用gather函数
done,pending = await asyncio.wait(tasks)
# gather会直接返回有序的数组,一般return_exception设置为True,遇到错误会返回在数组中,,如果设置为False,遇到错误会抛错,代码无法执行
result = await asyncio.gather(*task,return_exception=True)协程发送请求和存文件:
py
import aiohttp
import aiofiles
# aiohttp发送请求 和 requests类似
async with aiohttp.ClientSession() as session:
async with session.get(href) as resp:
# aiohttp设置编码
page_source = await resp.text(encoding="gbk")
async with aiofiles.open(f"./hehe/{title}.txt",mode="w",encoding="utf-8") as f:
await f.write(content)如果文件写入失败,重试请求:
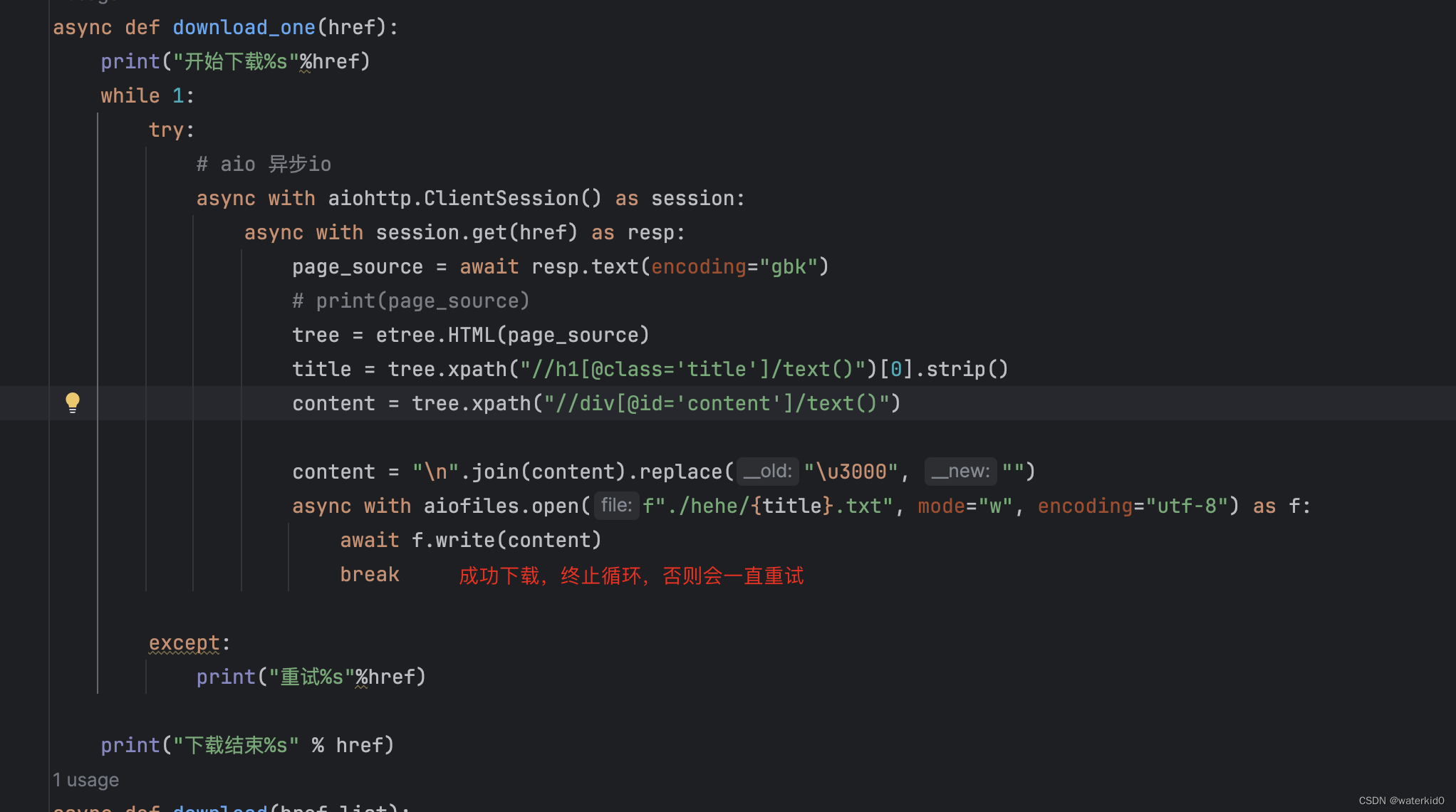
代码:
py
import asyncio
import aiofiles
import aiohttp
import requests
from lxml import etree
def get_href_list():
resp = requests.get("https://www.biquge635.com/mingchaonaxieshier/")
resp.encoding = "gbk"
href_list = etree.HTML(resp.text).xpath("//div[@class='section-box']/ul/li/a/@href")
print(href_list)
return href_list
async def download_one(href):
print("开始下载%s"%href)
while 1:
try:
# aio 异步io
async with aiohttp.ClientSession() as session:
async with session.get(href) as resp:
page_source = await resp.text(encoding="gbk")
# print(page_source)
tree = etree.HTML(page_source)
title = tree.xpath("//h1[@class='title']/text()")[0].strip()
content = tree.xpath("//div[@id='content']/text()")
content = "\n".join(content).replace("\u3000", "")
async with aiofiles.open(f"./hehe/{title}.txt", mode="w", encoding="utf-8") as f:
await f.write(content)
break
except:
print("重试%s"%href)
print("下载结束%s" % href)
async def download(href_list):
tasks = []
for href in href_list:
tasks.append(asyncio.create_task(download_one(href)))
await asyncio.wait(tasks)
def main():
href_list = get_href_list()
# 启动协程
asyncio.run(download(href_list))
if __name__ == '__main__':
main()