一.什么是Redis
与MySQL一样,Redis也是客户端服务器结构的程序,是基于内存的键值对存储系统,属于NoSQL的一种。与很多键值对数据库不同的是,Redis 中的值可以是由 string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集合)、 Bitmaps(位图)、HyperLogLog、GEO(地理信息定位)等多种数据结构和算法组成,因此 Redis可以满⾜很多的应⽤场景。
Redis有很多优势
首先,Redis是基于内存进行存储的,也就是说Redis将数据存储到内存上,然而MySQL是将数据存储到硬盘上,我们知道cpu访问内存的速度比访问硬盘的速度快很多
有人可能会说,Redis是存储在内存中,但是定义变量不也是在内存中存储吗?那为啥还要使用Redis呢?其实Redis主要是在分布式系统中发挥威力,单机程序中使用变量才更方便。因为,我们知道,进程间具有隔离性,进程间的通信需要经过网络,而Redis就是基于网络的,它可以将自己内存中的变量给别的进程甚至别的主机上的进程使用
Redis虽然比MySQL快很多,但是它有一个缺点就是存储空间小。那怎么就能够又大又快呢?那就是Redis与MySQL配合使用,把Redis当作cache缓存,而MySQL还是主要的存储介质,全量数据依然存放在MySQL中,将常被访问到的热点数据存到Redis中,减少访问MySQL的次数。但这也是有代价的,那就是系统的复杂程度大大提高,而且在修改数据时会涉及到Redis与MySQL同步的问题
Redis初心是用作一个消息中间件(消息队列)来实现分布式系统下的生产者消费者模型,但现在很少使用Redis当作消息队列
二.Redis特性
1.In-memory Data Structures
在内存中存储数据。
MySQL是通过表的方式在硬盘中存储,是关系型数据库;而Redis则是通过键值对的方式在内存中存储数据
2.Programmability
Redis的可编程性。
使用Lua和Redis函数来扩展Redis
Redis 提供了一个编程接口,可让我们在服务器本身上执行自定义脚本。在 Redis 7 及更高版本中,可以使用 Redis 函数 来管理和运行脚本。在 Redis 6.2 及更低版本中,可以使用 Lua 脚本和 EVAL 命令 对服务器进行编程。
什么是脚本?Redis 中的可编程 性一词意味着能够由服务器执行任意用户定义的逻辑。我们将这样的逻辑片段称为脚本。
使用脚本可以减少网络开销。原本5次请求可以放到一次请求中,通过一个脚本同时传输给Redis,这样就可以在一次网络通信中完成5次访问Redis的操作。减少网络开销,提高了整体性能。
3.Extensibility
Redis的可扩展性
可以在Redis原有的功能的基础上再进行扩展。Redis提供了一组API,通过C、C++、Rust这几个语言编写Redis扩展(本质上是一个动态链接库),通过扩展能够让Redis使用更多的数据结构。
4.Persistence
持久化
Redis是将数据存储在内存上,但实际上内存中的数据是容易丢失的,会随着进程退出/系统重启而丢失
因此Redis也会将数据存储在硬盘上作为备份,内存为主硬盘为辅,Redis重启时就会加载硬盘中的数据到内存中
5.Clustering
集群
Redis作为一个分布式系统的中间件,能够支持集群是很关键的。一个Redis能存储的数据是有限的,所以引入多个主机,部署多个Redis节点,每个Redis存储数据的一部分,就可以解决问题
6.High availability
高可用
核心:冗余/备份
Redis自身支持主从结构,也就是主从复制架构。Redis提供了复制功能,实现了多个相同数据的Redis副本,从节点就是主节点的备份。主节点挂了,从节点就能够立马补上
7.快
为什么redis快?
1.数据在内存中存储,就比访问硬盘的数据库快
2.Redis的核心功能斗志较简单的逻辑,仅仅是较简单的操作内存的数据结构
3.网络角度:Redis使用了IO多路复用的方式(使用一个线程管理很多个socket,也就是一个线程中可以执行多个请求,或者说一次请求可以完成之前的多次请求的任务)
4.线程角度:Redis使用单线程模型,减少了不必要的线程之间的竞争开销。
为什么Redis不适用多线程呢?多线程不是可以提高效率吗?这就要挖掘本质了,多线程能够提效的前提就是这是一个CPU密集型任务,使用多个线程可以充分利用多核cpu资源。但Redis的核心任务主要是操作内存数据结构,不会吃很多cpu,所以此时使用多线程就起不到作用。
5.Redis使用C语言开发,更贴近操作系统,所以快。(这一条待定,毕竟MySQL也是C语言开发的)
三.Redis使用场景
1.Real-time data store
将Redis当作实时存储的数据库。
大多数情况下,考虑到数据存储,优先考虑"大",但仍有些场景需要考虑快
例如:搜索引擎的广告搜索(商业搜索),对性能要求就非常高,需要在很短的时间内将与用户输入关键字相关的广告找到并显示到网页上。这种情况下就不适合使用MySQL这样的数据库存储广告到硬盘中,而是要存储到内存中从而提高访问速度,用到的就是类似于Redis这样的内存数据库来完成,当然,使用这样的内存数据库存储大量的数据,需要不少的硬件资源。
2.caching
使用数据库存储数据,虽然存的多,但是非常慢。
然而数据的访问一般都遵循二八原则:20%的数据可以满足80%的访问。
所以可以将MySQL中的热点数据拎出来,存到Redis中,此时Redis只存部分数据,而MySQL依然存储全量数据。访问时,先从Redis中查找,实在找不到再去MySQL中找,减少了访问mysql的次数,从而提高性能。这就相当于将Redis作为cache缓存。
3.session storage
session storage 会话存储。在之前,session都是存储在应用服务器上

如上,第一次请求,请求发送到了A,产生了一个会话,第二次请求,可能发到了B,就又得重新登陆。这如何解决?
方法一:让负载均衡器把同一个用户的请求始终达到同一个机器上,这需要使用userid之类的方式来配合
方法二:把会话拎出来放到同一台机器上(就比如Redis),每个应用服务器都从Redis上读取会话。(好处:即使应用程序重启了,会话也不会丢失)
4.streaming&messaging
Redis可作为消息队列(服务器)
基于此,可实现一个网络版本的生产者消费者模型(以前写的都是单机的生产者消费者模型)。在分布式系统中,服务器与服务器之间,优势也需要使用到生产者消费者模型(优势:解耦合。削峰填谷)
Redis不可以做什么?Redis不可以大规模存储数据
四.Redis本质
与MySQL相同,Redis也是客户端服务器结构的程序。
Redis服务器是Redis的本体。
Redis客户端有很多种形态
1.自带了命令行客户端 redis-cli,在Linux上直接输入redis-cli就可以启动Redis客户端;或者输入redis-cli -h (ip地址) -p (端口号),从而指定ip和端口号,例如 redis-cli -h 127.0.0.1 -p 6379
2.图形化界面的客户端:如桌面程序,web程序(网页),图形化程序依赖windows系统,而未来实际工作中,用来办公的windows系统连接到服务器可能会有诸多限制,你的图形化界面客户端能否连接到你们服务器里面的redis,是个未知数
3.基于redis的api自行开发的客户端(是工作中的主要形态),类似于MySQL的C语言api和JDBC编程
五.Ubuntu安装redis
在linux上安装程序,必须在root用户下
1.su 切换到root用户
2.apt search redis 使用apt命令搜索Redis相关软件包
3.apt install redis 安装redis
4.netstat -anp | grep redis 查看redis所使用的端口号

由图可知,它默认使用6379这个端口号
但上面使用的是127.0.0.1这个ip,需要修改
5.修改redis配置项
redis相关配置都在redis配置文件redis.conf中,它放在/etc/redis这个目录下,如下通过vim编辑器,将下面三个地方进行修改:
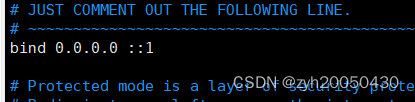
首先,在vim编辑器中按/键进入搜索模式,搜索关键字bind,将后面的127.0.0.1改成0.0.0.0,表示任何ip都可以访问我的redis服务器
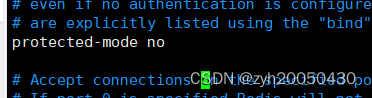
其次,找到protected-mode 改为no,以便于可以跨主机访问
6.修改完成后,重启redis服务器

没有提示说明重启成功,如果担心未重启,可以通过service redis-server status来查看redis服务器的运行状态
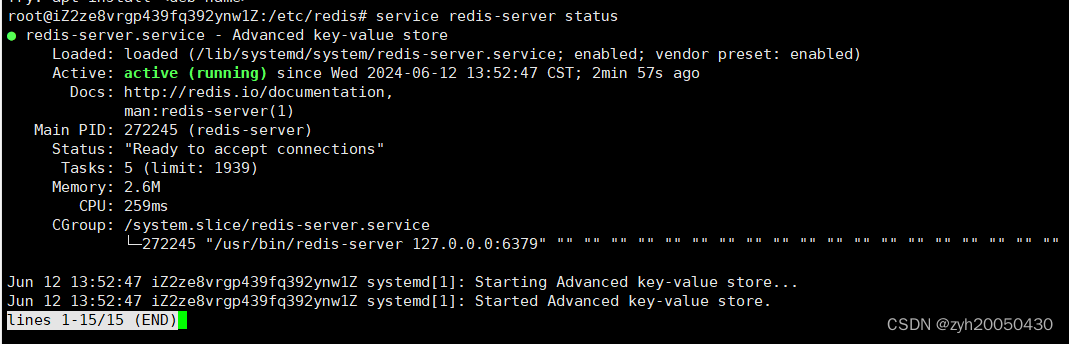
active running说明正常运行
7.redis-cli 使用redis自带的客户端来连接服务器

8.如何退出redis:ctrl+d,相当于输入EOF
9./var/lib/redis是redis的工作目录 /var/log/redis是redis的日志目录,redis-server.log就是redis的日志
10.service redis-server stop 停止redis服务