之前介绍:
https://qq742971636.blog.csdn.net/article/details/132061304
文章目录
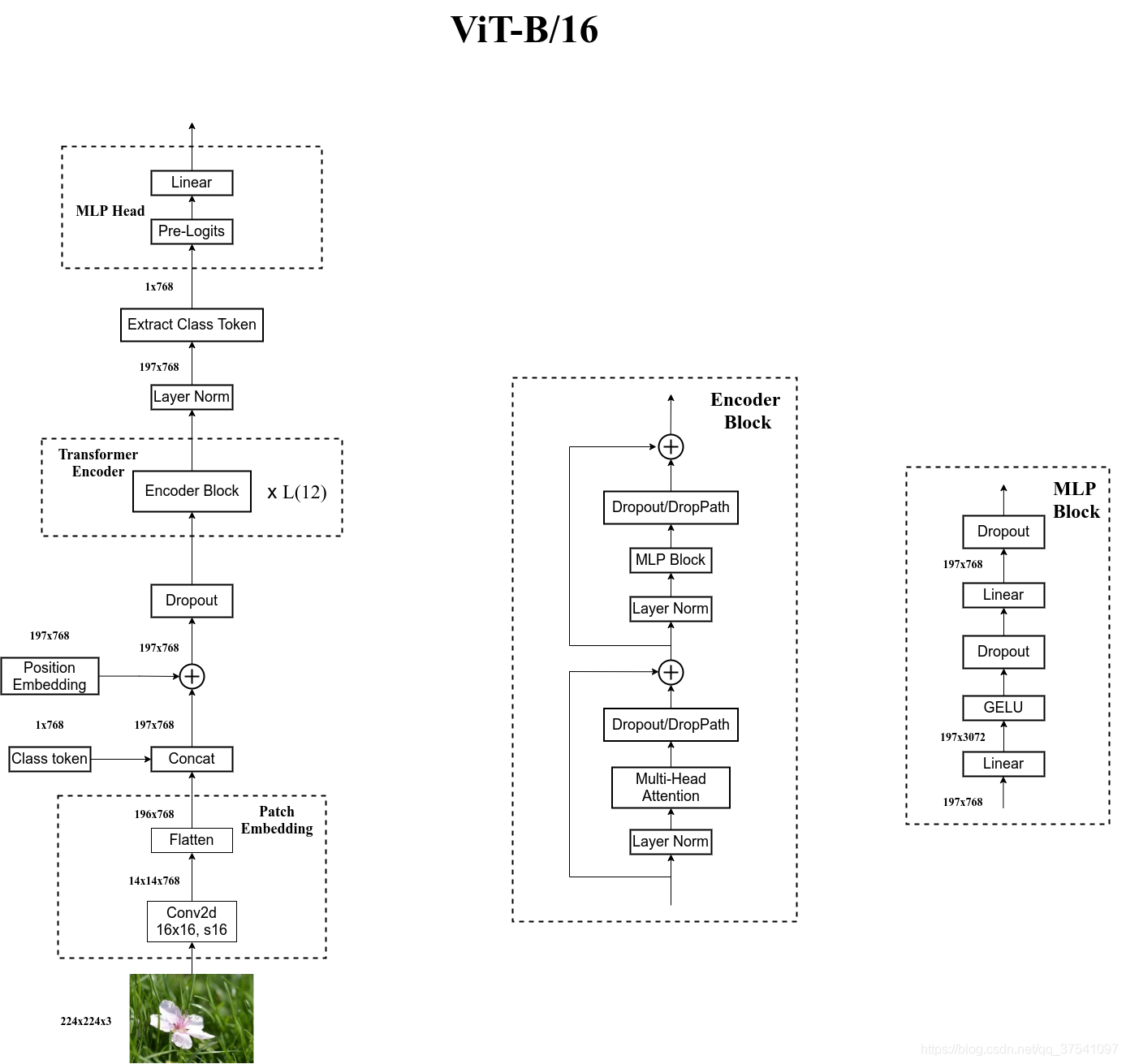
Vision Transformer(ViT)是一种基于transformer架构的视觉模型,它最初是由谷歌研究团队在论文《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》中提出的。ViT将图像分割成固定大小的patches(例如16x16),并将每个patch视为一个词(类似于NLP中的单词)进行处理。以下是ViT的详细讲解:
背景
在计算机视觉领域,传统的卷积神经网络(CNNs)一直是处理图像的主流方法。然而,CNNs存在一些局限性,如在处理长距离依赖关系时表现不佳。ViT引入了transformer架构,通过全局注意力机制,有效地处理图像中的长距离依赖关系。
实现代码示例
ViT代码:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrange, repeat
class PatchEmbedding(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = img_size // patch_size
self.num_patches = self.grid_size ** 2
self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.proj(x) # [B, embed_dim, H, W]
x = x.flatten(2) # [B, embed_dim, num_patches]
x = x.transpose(1, 2) # [B, num_patches, embed_dim]
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class MLP(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = nn.GELU()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0., drop_path=0.):
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = nn.Identity() if drop_path == 0 else nn.Dropout(drop_path)
self.norm2 = nn.LayerNorm(dim)
self.mlp = MLP(in_features=dim, hidden_features=int(dim * mlp_ratio), drop=drop)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class VisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=3, num_classes=1000, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4., qkv_bias=False, drop_rate=0., attn_drop_rate=0., drop_path_rate=0.):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim
self.patch_embed = PatchEmbedding(img_size, patch_size, in_channels, embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)]
self.blocks = nn.ModuleList([
Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i])
for i in range(depth)])
self.norm = nn.LayerNorm(embed_dim)
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
nn.init.trunc_normal_(self.pos_embed, std=0.02)
nn.init.trunc_normal_(self.cls_token, std=0.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=0.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
def forward(self, x):
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embed
x = self.pos_drop(x)
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
cls_token_final = x[:, 0]
x = self.head(cls_token_final)
return x
# 示例输入
img = torch.randn(1, 3, 224, 224)
model = VisionTransformer()
output = model(img)
print(output.shape) # 输出大小为 [1, 1000]解释
- PatchEmbedding:将输入图像分割为不重叠的patches,并通过卷积操作将其转换为embedding。
- Attention:实现自注意力机制。
- MLP:实现多层感知器(MLP),包括GELU激活函数和Dropout。
- Block:包含一个注意力层和一个MLP层,每层都有残差连接和层归一化。
- VisionTransformer:组合上述模块,形成完整的ViT模型。包含位置嵌入和分类头。
训练
为了在GPU上训练ViT模型,你可以使用PyTorch中的DataLoader来处理数据,并确保模型和数据都在GPU上。以下是一个详细的代码示例,包括数据准备、模型定义、训练和评估。
数据准备
假设你的数据结构如下:
dataset/
class1/
img1.jpg
img2.jpg
...
class2/
img1.jpg
img2.jpg
...
...你可以使用 torchvision.datasets.ImageFolder 来加载数据。
python
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from tqdm import tqdm
# 数据转换和增强
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 加载数据
data_dir = 'dataset'
train_dataset = datasets.ImageFolder(os.path.join(data_dir, 'train'), transform=transform)
val_dataset = datasets.ImageFolder(os.path.join(data_dir, 'val'), transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=4)
# 获取类别数
num_classes = len(train_dataset.classes)模型定义
定义ViT模型并将其移动到GPU上。
python
# VisionTransformer定义(使用上面的定义)
model = VisionTransformer(num_classes=num_classes).cuda()
# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
# 如果有多个GPU,使用DataParallel
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model)训练和评估
定义训练和评估函数,并进行训练。
python
def train_one_epoch(model, criterion, optimizer, data_loader, device):
model.train()
running_loss = 0.0
running_corrects = 0
for inputs, labels in tqdm(data_loader):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(data_loader.dataset)
epoch_acc = running_corrects.double() / len(data_loader.dataset)
return epoch_loss, epoch_acc
def evaluate(model, criterion, data_loader, device):
model.eval()
running_loss = 0.0
running_corrects = 0
with torch.no_grad():
for inputs, labels in data_loader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(data_loader.dataset)
epoch_acc = running_corrects.double() / len(data_loader.dataset)
return epoch_loss, epoch_acc
# 训练模型
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
num_epochs = 25
for epoch in range(num_epochs):
train_loss, train_acc = train_one_epoch(model, criterion, optimizer, train_loader, device)
val_loss, val_acc = evaluate(model, criterion, val_loader, device)
print(f'Epoch {epoch}/{num_epochs - 1}')
print(f'Train Loss: {train_loss:.4f} Acc: {train_acc:.4f}')
print(f'Val Loss: {val_loss:.4f} Acc: {val_acc:.4f}')
# 保存模型
torch.save(model.state_dict(), 'vit_model.pth')总结
这段代码展示了如何使用PyTorch在GPU上训练Vision Transformer模型。包括数据加载、模型定义、训练和评估步骤。请根据你的实际需求调整批量大小、学习率和训练轮数等参数。