基于DeepSeek-V2-Chat多卡推理演示不同的Profing方法
本文基于DeepSeek-V2-Chat多卡推理,演示了几种不同的Profing方法
备注:
- 1.torch prof.export_chrome_trace导出给ui.perfetto.dev可视化
- 2.Nsight Compute可以给出性能瓶颈及优化建议
一.结果
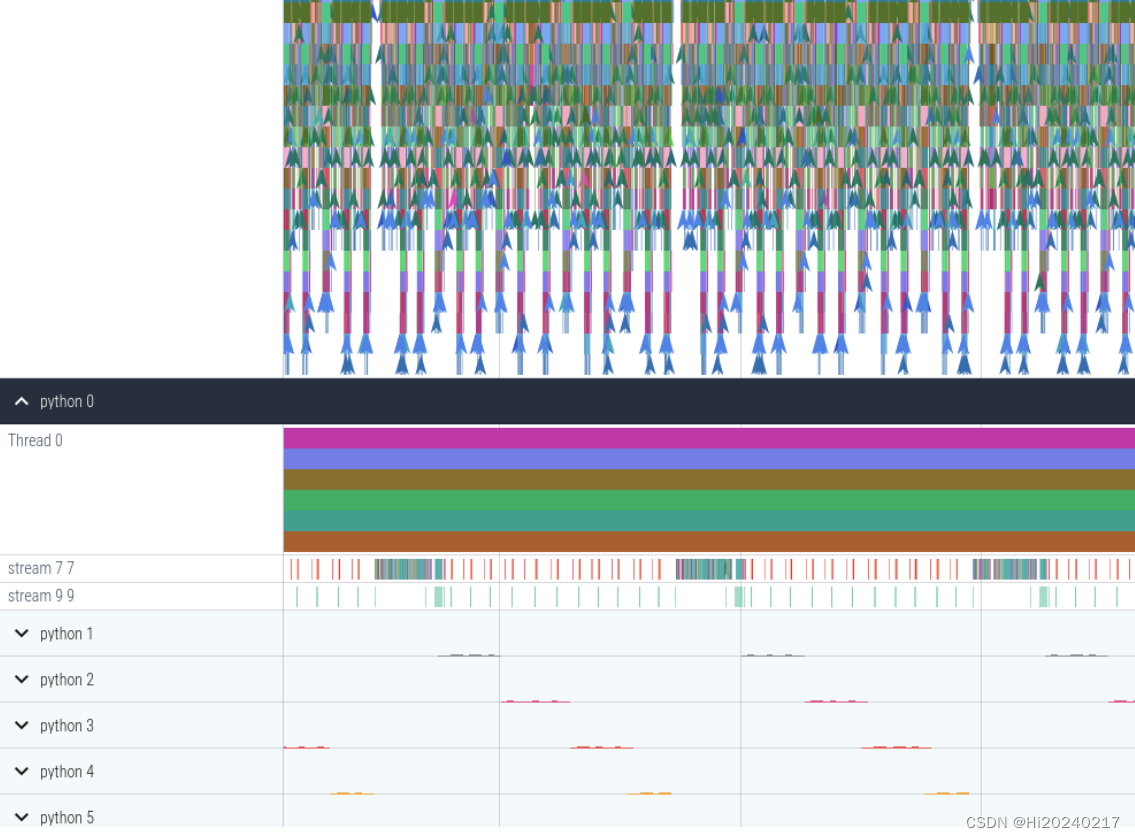
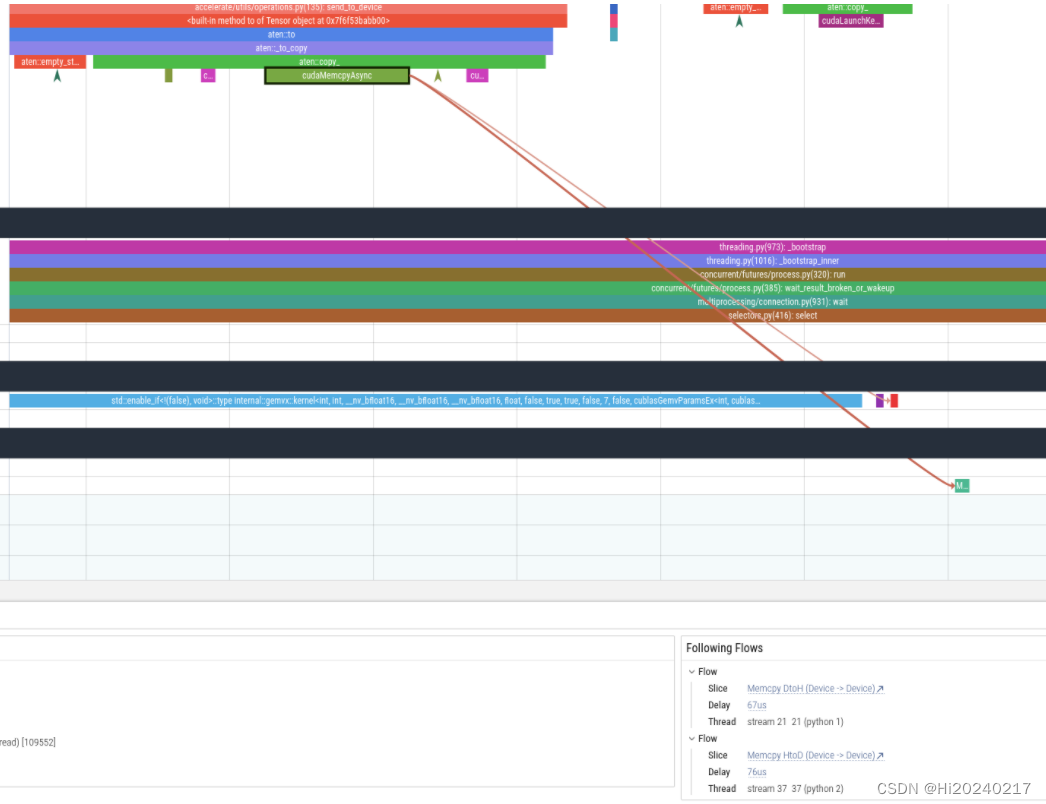
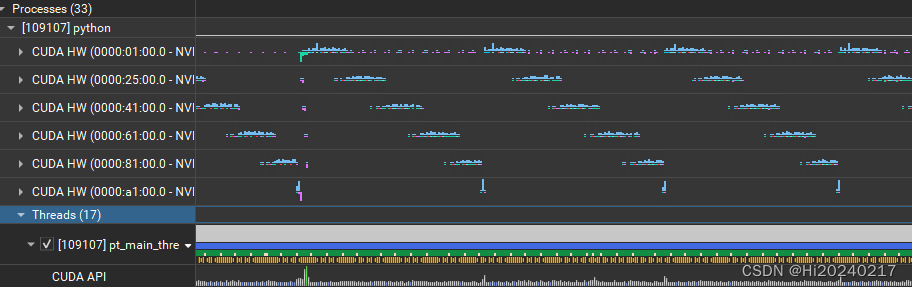
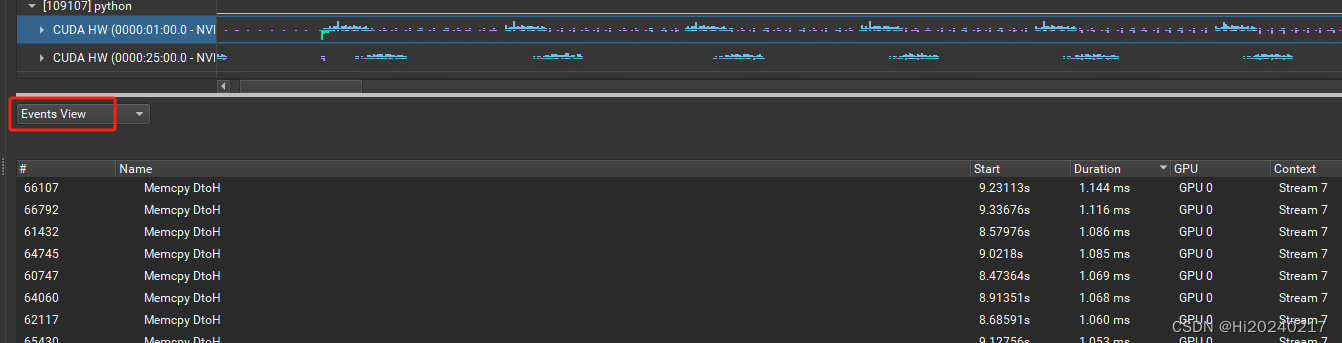
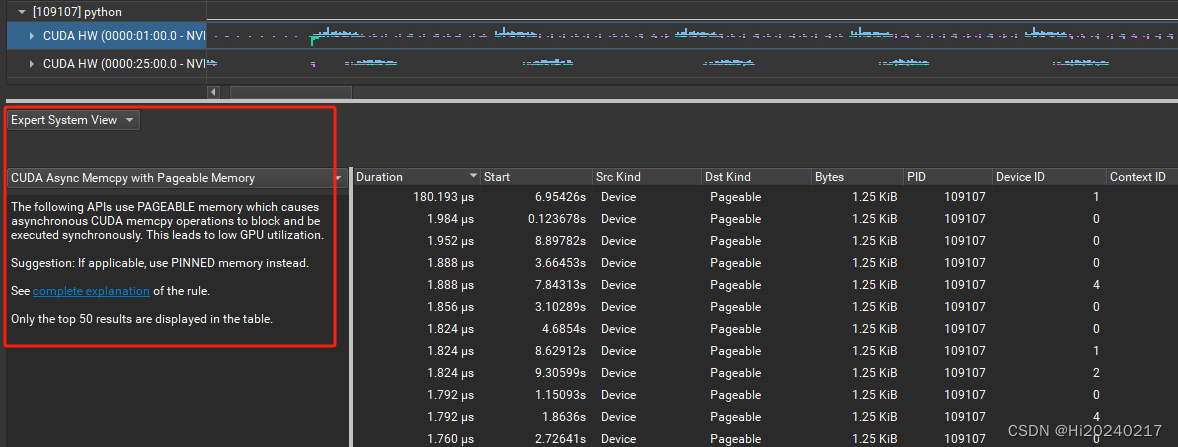
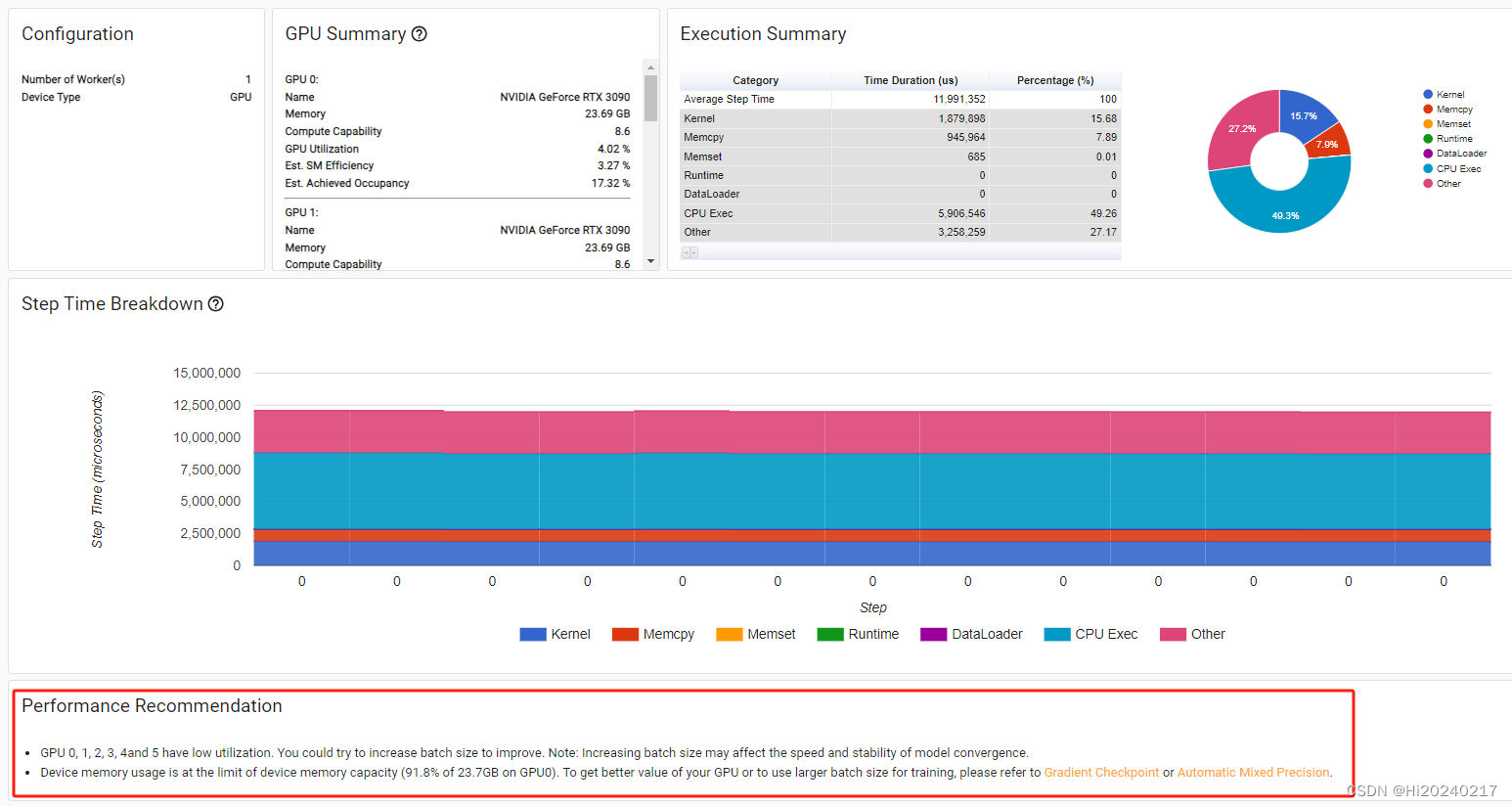
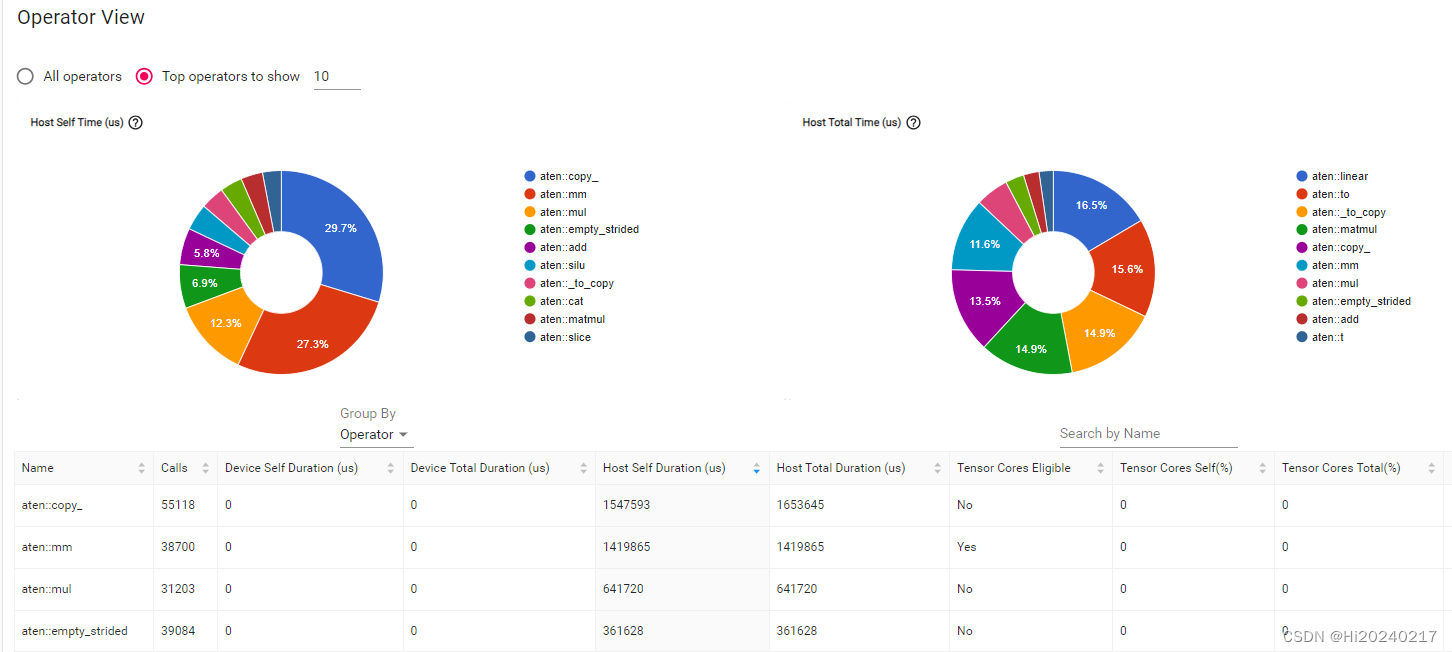
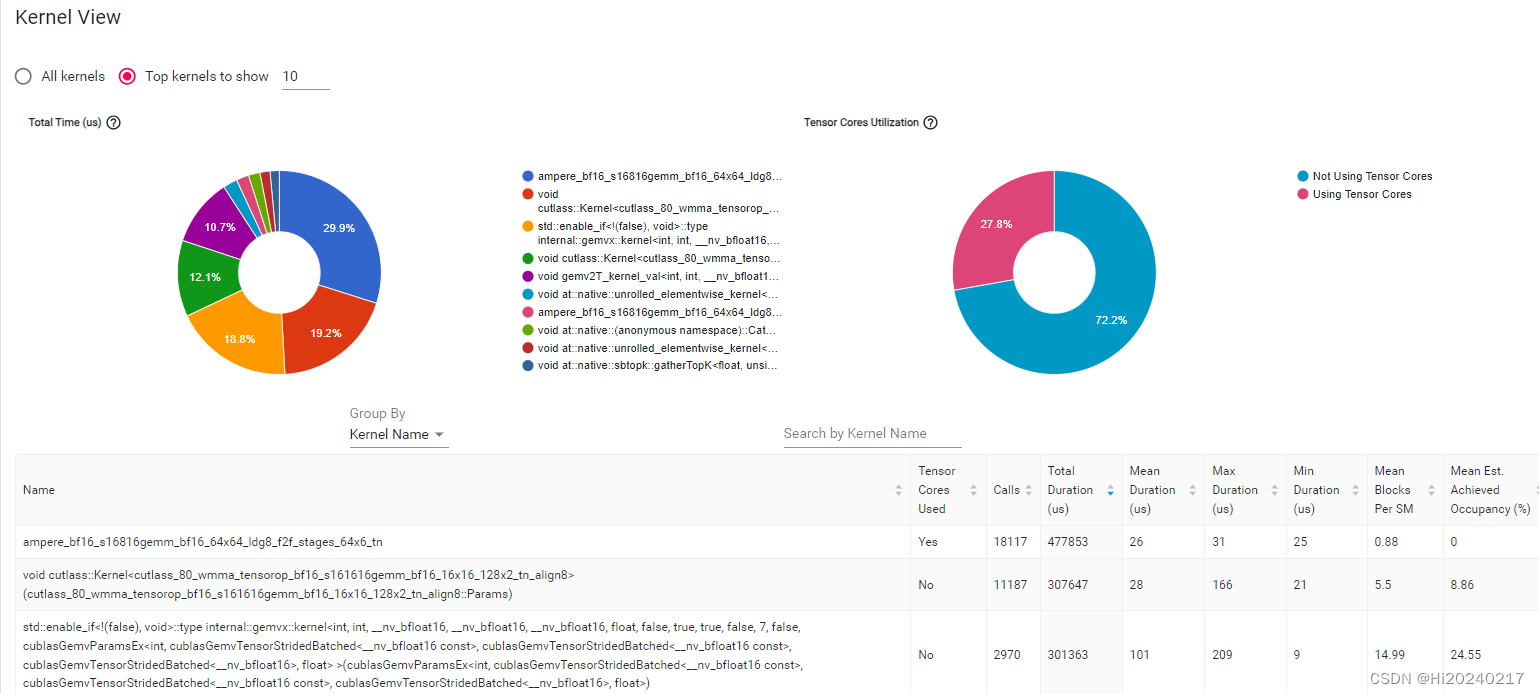
二.操作步骤
bash
tee prof.py <<-'EOF'
import torch
import time
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
from accelerate import init_empty_weights
import sys
from accelerate import dispatch_model, infer_auto_device_map
from accelerate.utils import get_balanced_memory
from torch.cuda.amp import autocast
import torch.cuda
import multiprocessing as mp
import inspect
model_name = "./models/deepseek-ai/DeepSeek-V2-Chat/"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
max_memory = {i: "23GB" for i in range(8)}
sys.path.insert(0,model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True,attn_implementation="eager",torch_dtype=torch.bfloat16)
model=model.eval()
no_split_module_classes = ['DeepseekV2MLP','DeepseekV2Attention']
device_map = infer_auto_device_map(
model,max_memory=max_memory,
no_split_module_classes=no_split_module_classes,
dtype='float16')
model = dispatch_model(model, device_map=device_map)
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [{"role": "user", "content": "Write a piece of quicksort code in C++"} ]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
outputs = model.generate(input_tensor, max_new_tokens=100)
print("warm up done!")
def nsys_prof():
torch.cuda.cudart().cudaProfilerStart()
t0=time.time()
outputs = model.generate(input_tensor, max_new_tokens=100)
t1=time.time()
print("e2e:",t1-t0)
torch.cuda.cudart().cudaProfilerStop()
def torch_prof():
from torch.profiler import profile
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA,
],
record_shapes=True,
profile_memory=True,
with_stack=True,
with_flops=True
) as prof:
outputs = model.generate(input_tensor, max_new_tokens=100)
prof.export_chrome_trace("torch_prof.json")
def torch_tensorboard_trace():
prof = torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA,
],
schedule=torch.profiler.schedule(wait=0, warmup=0, active=1, repeat=0),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./log'),
record_shapes=True,
profile_memory=True,
with_stack=True)
prof.start()
for i in range(1):
outputs = model.generate(input_tensor, max_new_tokens=100)
torch.cuda.synchronize()
prof.step()
prof.stop()
def infer():
outputs = model.generate(input_tensor, max_new_tokens=100)
torch.cuda.synchronize()
def cprofile():
import cProfile
import pstats
cProfile.run('infer()', 'restats')
p = pstats.Stats('restats')
p.sort_stats('cumulative').print_stats(50)
def torch_prof_threadpool():
from torch.profiler import profile
from concurrent.futures import ThreadPoolExecutor
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA,
],
record_shapes=True,
profile_memory=True,
with_stack=True,
with_flops=True
) as prof:
def infer(index):
past_key_values=None
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
custom_stream = torch.cuda.Stream()
t0=time.time()
with torch.cuda.stream(custom_stream):
outputs = model.generate(input_tensor,max_new_tokens=100)
t1=time.time()
print(index,t1-t0)
return None
with ThreadPoolExecutor(max_workers=4) as executor:
results = list(executor.map(infer,range(0,4)))
prof.export_chrome_trace("torch_prof_threadpool.json")
eval(sys.argv[1])()
EOF
nsys profile --stats=true -o cuda_profing_report.nsys-rep -f true -t cuda,nvtx \
--gpu-metrics-device=0,1,2,3,4,5,6,7 \
--capture-range=cudaProfilerApi \
--capture-range-end=stop python prof.py nsys_prof
python prof.py torch_prof
mkdir log -p
python prof.py torch_tensorboard_trace
python prof.py cprofile
python prof.py torch_prof_threadpool
tee get_traceEvents.py <<-'EOF'
import json
import sys
filepath=sys.argv[1]
data=json.load(open(filepath,"r"))
f=open(f"traceEvents_{filepath}","w")
json.dump({"traceEvents":data['traceEvents']},f)
f.close()
EOF
python get_traceEvents.py torch_prof_threadpool.json
python get_traceEvents.py torch_prof.json
rm torch_prof.json torch_prof_threadpool.json -f输出
bash
Time (%) Total Time (ns) Num Calls Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Name
-------- --------------- --------- -------- -------- -------- -------- ----------- ---------------------------------------------
66.5 1387919547 200835 6910.7 6470.0 4070 518456 3693.0 cudaLaunchKernel
18.8 391445205 20190 19388.1 17149.5 5360 793835 22195.6 cudaMemcpyAsync
5.6 115988383 19115 6067.9 5810.0 3530 188359 3372.6 cudaMemsetAsync
2.9 60523944 23956 2526.5 1970.0 1240 205099 2145.7 cudaStreamWaitEvent
2.1 43275528 1904 22728.7 3120.0 2630 1948957 88939.7 cudaStreamSynchronize
1.7 36032225 23956 1504.1 1260.0 930 477756 3194.3 cudaEventRecord
1.4 28312023 23956 1181.8 950.0 700 481776 3321.9 cudaEventCreateWithFlags
1.1 22670547 23956 946.3 730.0 570 465647 7535.8 cudaEventDestroy
0.0 170028 100 1700.3 1640.0 1520 2060 140.6 cudaStreamIsCapturing_v10000
0.0 33330 16 2083.1 1715.0 1390 4950 894.8 cudaOccupancyMaxActiveBlocksPerMultiprocessor
0.0 7310 1 7310.0 7310.0 7310 7310 0.0 cuProfilerStart
[5/7] Executing 'cuda_gpu_kern_sum' stats report
Time (%) Total Time (ns) Instances Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Name
-------- --------------- --------- --------- --------- -------- -------- ----------- ----------------------------------------------------------------------------------------------------
24.6 488154814 18117 26944.6 26720.0 25920 31935 892.4 ampere_bf16_s16816gemm_bf16_64x64_ldg8_f2f_stages_64x6_tn
15.7 312293607 11187 27915.8 21408.0 21152 166178 15652.5 void cutlass::Kernel<cutlass_80_wmma_tensorop_bf16_s161616gemm_bf16_16x16_128x2_tn_align8>(T1::Para...
15.2 302994818 2970 102018.5 101168.5 9376 209283 92340.2 std::enable_if<!T7, void>::type internal::gemvx::kernel<int, int, __nv_bfloat16, __nv_bfloat16, __n...
9.8 195548625 3150 62078.9 41089.0 4064 91073 27330.1 void cutlass::Kernel<cutlass_80_wmma_tensorop_bf16_s161616gemm_bf16_16x16_128x1_tn_align8>(T1::Para...
8.7 172566020 1485 116206.1 40000.0 38976 1185823 285264.4 void gemv2T_kernel_val<int, int, __nv_bfloat16, __nv_bfloat16, __nv_bfloat16, float, (int)128, (int...
[6/7] Executing 'cuda_gpu_mem_time_sum' stats report
Time (%) Total Time (ns) Count Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Operation
-------- --------------- ----- -------- -------- -------- -------- ----------- ------------------
53.3 847221455 13679 61935.9 1600.0 1120 1117006 155051.3 [CUDA memcpy DtoH]
45.6 724555193 12181 59482.4 2528.0 448 1027370 143492.5 [CUDA memcpy HtoD]
0.6 10113989 19115 529.1 480.0 447 1568 172.0 [CUDA memset]
0.5 8129349 6308 1288.7 1280.0 1185 1728 90.1 [CUDA memcpy DtoD]
[7/7] Executing 'cuda_gpu_mem_size_sum' stats report
Total (MB) Count Avg (MB) Med (MB) Min (MB) Max (MB) StdDev (MB) Operation
---------- ----- -------- -------- -------- -------- ----------- ------------------
6213.111 13679 0.454 0.010 0.000 6.963 1.129 [CUDA memcpy DtoH]
6211.319 12181 0.510 0.010 0.000 6.963 1.184 [CUDA memcpy HtoD]
134.408 6308 0.021 0.000 0.000 0.410 0.088 [CUDA memcpy DtoD]
16.679 19115 0.001 0.000 0.000 0.035 0.005 [CUDA memset]
Generated:
/home/autotrain/torch_prof/cuda_profing_report.nsys-rep
/home/autotrain/torch_prof/cuda_profing_report.sqlite
warm up done!
e2e: 9.11670708656311
----------------------------------------------------------------------------------------------------------------
3206138 function calls (2757755 primitive calls) in 6.868 seconds
Ordered by: cumulative time
List reduced from 330 to 50 due to restriction <50>
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 6.868 6.868 {built-in method builtins.exec}
1 0.000 0.000 6.868 6.868 <string>:1(<module>)
1 0.000 0.000 6.868 6.868 /home/autotrain/torch_prof/prof.py:75(infer)
1401/1 0.019 0.000 6.868 6.868 /root/anaconda3/envs/autotrain/lib/python3.10/site-packages/torch/utils/_contextlib.py:112(decorate_context)
1 0.000 0.000 6.868 6.868 /root/anaconda3/envs/autotrain/lib/python3.10/site-packages/transformers/generation/utils.py:1440(generate)
1 0.017 0.017 6.866 6.866 /root/anaconda3/envs/autotrain/lib/python3.10/site-packages/transformers/generation/utils.py:2310(_sample)
70800/100 0.064 0.000 6.661 0.067 /root/anaconda3/envs/autotrain/lib/python3.10/site-packages/torch/nn/modules/module.py:1528(_wrapped_call_impl)
70800/100 0.155 0.000 6.661 0.067 /root/anaconda3/envs/autotrain/lib/python3.10/site-packages/torch/nn/modules/module.py:1534(_call_impl)
58500/100 0.182 0.000 6.660 0.067 /root/anaconda3/envs/autotrain/lib/python3.10/site-packages/accelerate/hooks.py:160(new_forward)
100 0.001 0.000 6.613 0.066 /root/.cache/huggingface/modules/transformers_modules/modeling_deepseek.py:1611(forward)
100 0.007 0.000 6.594 0.066 /root/.cache/huggingface/modules/transformers_modules/modeling_deepseek.py:1425(forward)
1500 0.059 0.000 6.419 0.004 /root/.cache/huggingface/modules/transformers_modules/modeling_deepseek.py:1209(forward)
1400 0.035 0.000 3.599 0.003 /root/.cache/huggingface/modules/transformers_modules/modeling_deepseek.py:564(forward)
1400 0.242 0.000 2.756 0.002 /root/.cache/huggingface/modules/transformers_modules/modeling_deepseek.py:586(moe_infer)
1500 0.253 0.000 2.093 0.001 /root/.cache/huggingface/modules/transformers_modules/modeling_deepseek.py:799(forward)
9900 0.229 0.000 1.973 0.000 /root/.cache/huggingface/modules/transformers_modules/modeling_deepseek.py:386(forward)
58500 0.070 0.000 1.388 0.000 /root/anaconda3/envs/autotrain/lib/python3.10/site-packages/accelerate/hooks.py:316(pre_forward)
198455/117100 0.479 0.000 1.339 0.000 /root/anaconda3/envs/autotrain/lib/python3.10/site-packages/accelerate/utils/operations.py:135(send_to_device)
37300 0.076 0.000 1.090 0.000 /root/anaconda3/envs/autotrain/lib/python3.10/site-packages/torch/nn/modules/linear.py:115(forward)
38700 1.015 0.000 1.015 0.000 {built-in method torch._C._nn.linear}
89249 0.789 0.000 0.789 0.000 {method 'to' of 'torch._C.TensorBase' objects}
6100 0.278 0.000 0.687 0.000 /root/.cache/huggingface/modules/transformers_modules/modeling_deepseek.py:103(forward)
61684/58699 0.068 0.000 0.657 0.000 /root/anaconda3/envs/autotrain/lib/python3.10/site-packages/accelerate/utils/operations.py:73(honor_type)
127539/118584 0.051 0.000 0.557 0.000 /root/anaconda3/envs/autotrain/lib/python3.10/site-packages/accelerate/utils/operations.py:181(<genexpr>)
1400 0.073 0.000 0.370 0.000 /root/.cache/huggingface/modules/transformers_modules/modeling_deepseek.py:418(forward)
1500 0.161 0.000 0.357 0.000 /root/.cache/huggingface/modules/transformers_modules/modeling_deepseek.py:337(apply_rotary_pos_emb)
738474/604072 0.117 0.000 0.261 0.000 {built-in method builtins.isinstance}
58600 0.020 0.000 0.203 0.000 /root/anaconda3/envs/autotrain/lib/python3.10/site-packages/accelerate/utils/operations.py:189(<dictcomp>)
1400 0.193 0.000 0.193 0.000 {method 'cpu' of 'torch._C.TensorBase' objects}
2985 0.010 0.000 0.160 0.000 /root/anaconda3/envs/autotrain/lib/python3.10/site-packages/transformers/cache_utils.py:123(update)
67201 0.034 0.000 0.159 0.000 /root/anaconda3/envs/autotrain/lib/python3.10/typing.py:993(__instancecheck__)
9900 0.008 0.000 0.142 0.000 /root/anaconda3/envs/autotrain/lib/python3.10/site-packages/torch/nn/modules/activation.py:395(forward)
9900 0.010 0.000 0.135 0.000 /root/anaconda3/envs/autotrain/lib/python3.10/site-packages/torch/nn/functional.py:2080(silu)
67201 0.041 0.000 0.125 0.000 /root/anaconda3/envs/autotrain/lib/python3.10/typing.py:1154(__subclasscheck__)
7570 0.125 0.000 0.125 0.000 {built-in method torch.cat}
265447 0.079 0.000 0.124 0.000 /root/anaconda3/envs/autotrain/lib/python3.10/site-packages/accelerate/utils/operations.py:44(is_torch_tensor)
9900 0.122 0.000 0.122 0.000 {built-in method torch._C._nn.silu}
3000 0.071 0.000 0.119 0.000 /root/.cache/huggingface/modules/transformers_modules/modeling_deepseek.py:329(rotate_half)
155900 0.114 0.000 0.114 0.000 /root/anaconda3/envs/autotrain/lib/python3.10/site-packages/torch/nn/modules/module.py:1696(__getattr__)
3000 0.097 0.000 0.097 0.000 {built-in method torch.matmul}
6100 0.086 0.000 0.086 0.000 {method 'mean' of 'torch._C.TensorBase' objects}
5900 0.084 0.000 0.084 0.000 {method 'reshape' of 'torch._C.TensorBase' objects}
6100 0.078 0.000 0.078 0.000 {method 'pow' of 'torch._C.TensorBase' objects}
5600 0.072 0.000 0.072 0.000 {method 'type' of 'torch._C.TensorBase' objects}
1400 0.072 0.000 0.072 0.000 {method 'argsort' of 'torch._C.TensorBase' objects}
203 0.070 0.000 0.070 0.000 {built-in method torch.tensor}
67202 0.025 0.000 0.069 0.000 {built-in method builtins.issubclass}
70800 0.060 0.000 0.060 0.000 {built-in method torch._C._get_tracing_state}
200 0.002 0.000 0.058 0.000 /root/anaconda3/envs/autotrain/lib/python3.10/site-packages/transformers/generation/logits_process.py:72(__call__)
6100 0.058 0.000 0.058 0.000 {built-in method torch.rsqrt}
----------------------------------------------------------------------------------------------------------------