目录
[11 GaussDB云原生架构](#11 GaussDB云原生架构)
[11.1 云原生关键技术架构](#11.1 云原生关键技术架构)
[11.2 关键技术方案](#11.2 关键技术方案)
[11.2.1 通信组件](#11.2.1 通信组件)
[11.2.2 集群管理组件](#11.2.2 集群管理组件)
[11.2.3 多租组件](#11.2.3 多租组件)
GaussDB架构介绍(三)从智能关键技术方案、驱动接口关键技术方案等方面对GaussDB架构进行了解读,本篇将从云原生关键技术架构 **&**关键技术方案****两方面对GaussDB云原生架构展开介绍。
11 GaussDB云原生 架构
11.1 云原生关键技术架构

图1 云原生数据库1层逻辑模型
**1. 分层原则。**整体层次分为三层,分别为Application Layer,Computer Layer和Storage Layer。Application Layer应用层主要是客户端各种语言的驱动,这些驱动通过通信与计算层Computer Layer进行交互,对数据库进行操作。下面是Computer Layer计算层,计算层负责SQL处理和事务处理,数据库的备份处理,集群内和集群间的消息通信,整个集群的管理,与公有云基础服务(认证,计费,运维)的对接。最下面是Storage Layer存储层,存储层负责数据库数据的日志存储,数据存储,数据库的备份存储。
**2. 分平面原则。**管理面,控制面和用户面。管理面主要包括操作维护子系统,控制面主要包括资源调度子系统,用户面主要包括数据库服务子系统。
**3. 适配器原则。**底层存储支持本地文件系统,Dorado 存储,Ceph分布式文件系统和DFV存储。这些存储的操作接口统一封装为文件系统接口。
**4. 负荷分担。**所有子系统的服务节点对等,一个节点故障,其他节点可以接管。
**5. 数据存储多副本存储。**Dorado 支持多种Raid级别,PLOG存储支持数据存储为3副本。
11.2 关键技术方案
11.2.1 通信组件
云原生数据库采用shared disk架构,各个计算节点对等,计算节点之间通过页面交换实现缓存数据的一致性,为了提高页面传递的效率,需要利用RDMA或UB单边读写的能力;云原生数据库为了管理动态资源,需要对动态资源的owner分配进行加锁,分布式锁管理需要利用原子操作和RPC消息对资源进行加解锁;多租户资源管理服务需要下发调度信息,并从计算节点读取资源状态,需要RPC消息;集群管理组件进行故障检测、发送消息需要使用RPC消息。因此,通信组件需要能够支持原子操作、单边读写、双边RPC和RPC通信。
目前市场上有三种RDMA网络,分别是Infiniband、RoCE(RDMA over Converged Ethernet)、iWARP,如下图所示。其中,Infiniband是专为RDMA设计的网络,从硬件级别保证可靠传输 ,但是成本高昂。而RoCE 和 iWARP都是基于以太网实现的RDMA技术,在目前最广泛使用的以太网上实现了高速、超低延时、极低CPU使用率的RDMA通信。
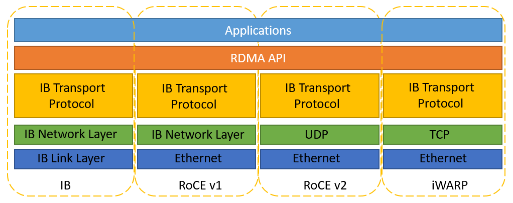
图2 RDMA网络种类
RoCE协议有RoCEv1和RoCEv2两个版本,RoCEv1是基于以太网链路层实现的RDMA协议(交换机需要支持PFC等流控技术,在物理层保证可靠传输),允许在同一个广播域下的任意两台主机直接访问;而RoCEv2是以太网TCP/IP协议中UDP层实现,即可以实现路由功能。
表1 InfinieBand和RoCE对比
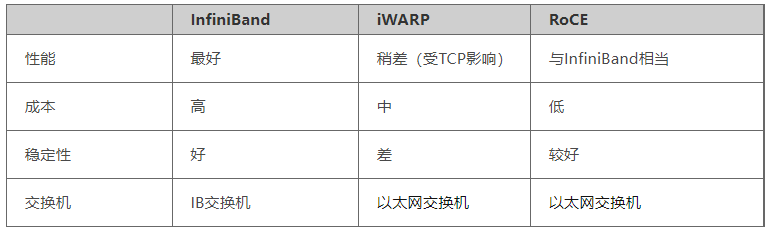
**InfiniBand:**设计之初就考虑了 RDMA,从硬件级别保证可靠传输,提供更高的带宽和更低的时延。但是成本高,需要IB网卡和交换机支持。
**RoCE:**基于Ethernet 做RDMA,消耗的资源比 iWARP 少,支持的特性比 iWARP 多。可以使用普通的以太网交换机,但是需要支持RoCE的网卡。
**iWARP:**基于TCP的RDMA网络,利用TCP达到可靠传输。相比RoCE,在大型组网的情况下,iWARP的大量TCP连接会占用大量的内存资源,对系统规格要求更高。可以使用普通的以太网交换机,但是需要支持iWARP的网卡。
为了支持各种网卡类型的RDMA协议和实现低时延的网络通信,云原生数据库的节点通信组件的整体架构图如下:

图3 通信组件整体架构图
节点间通信组件包括以下几个模块:RPC接口层、配置管理、通用功能、会话管理,消息处理和协议层。各模块功能描述如下:
表2 模块功能描述
| 组件名 | 功能描述 |
|---|---|
| RPC接口层 | RPC请求入口,提供对外接口及统一RPC消息格式。对外接口主要包括创建实例、注册内存及同步/异步通信接口。消息类型包括RPC通信消息、内存访问消息、原子操作消息、跨集群同步消息等。 |
| 配置管理 | 包括配置文件的字段。配置文件指定了本节点ID、集群节点数、其他节点ID、通信协议、RDMA协议通信的QP、CQ深度、MTU、初始连接数、最大连接数、最大注册内存等信息。在节点启动阶段节点通过配置文件进行初始化。 |
| 通用模块 | 负责对整个通信系统的生命周期管理、资源管理、集群间通信路由管理、负载均衡及通信系统DFX工具。 |
| 会话管理 | 会话管理包括连接管理、上下文管理、传输管理。连接管理根据请求模式、目的节点将消息分发到不同连接,并以连接池的方式对连接进行管理;上下文管理用于管理RPC request和response的对应关系,对于同步接口要对异步处理进行阻塞和上下文切换;传输管理主要负责流控和保证传输的可靠性。 |
| 消息处理模块 | RPC消息流和协议消息流之间进行转换,即发送时将RPC消息封装为底层协议消息,接收时将协议消息解封为RPC消息。 |
| 协议层 | 适配底层不同通信库。 |
根据对通信时延的计算,一次单边通信留给CPU的时间只有3.36us,为了实现低时延通信,各个模块的设计考虑如下:
1、RPC Interface
根据不同场景对通信接口的需求,RPC接口层提供消息语义、内存语义和原子操作接口,并支持同步、异步和批量调用。
RDMA内存操作需先将内存注册到网卡。论文《用户态RPC over RDMA优化技术的研究与实现》实验表明,传输的块大小越小,内存注册在一次RPC调用中占比越大,当块大小小于64KB时,内存注册开销远大于传输本身的开销。为降低内存注册的开销,通信组件统一申请大块内存并注册到网卡,业务模块需要进行远端内存操作前通过调用请求内存接口获取指定长度的已注册内存。
2、配置管理
配置管理主要是静态设置节点间通信信息,在通信初始化时使用,不在通信关键路径上。
3、通用模块
通用模块主要负责计算节点注册内存的管理和集群间通信消息的转发,在初始化时使用,不在通信关键路径上。
4、会话管理
会话管理主要包括连接管理、上下文管理和传输管理。
RDMA协议通信的基本单元是QP(Queue Pair),通信的两端都需要创建QP,不同传输模式使用的QP类型不一样,并且支持的RDMA原语也不一样,如下表。
表3 不同传输模式支持的RDMA原语及消息大小
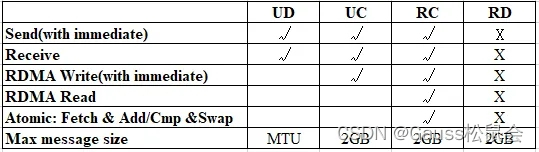
可见,单边读写和原子操作只能使用可靠连接,即每个连接的两个节点需要各自维护一个QP,并且不能被其他目的节点的连接共享。假设有N个节点需要相互通信,则至少需要N * (N - 1)个QP,而QP本身需要占用网卡和内存,当连接数很多时,存储资源消耗将会非常大。经计算一个未经封装的RDMA QP大概占186.67KB (0.1823M) 内存。为降低内存开销,与相同节点通信可以共享QP。但在高并发下竞争QP资源可能成为性能瓶颈。连接分发设计需要考虑性能和资源利用率。连接管理根据QP是否可共享支持共享连接(share-connection)和线程独占连接(per-thread)两种选择。
双边操作可以使用不可靠报文QP,即传输为不可靠数据报文且不同目的节点可共享QP。为节省QP资源,减少过多QP造成网卡cache miss导致的性能下降,考虑双边通信场景选择使用不可靠报文,但是为保证数据的可靠性,需要进一步做可靠性设计。考虑设计滑动窗口实现保序和重传机制,作为后续开发特性。(但是据FaSST测试数据,RDMA的不可靠发送丢包率近乎为0),需要设计传输管理模块实现保序、重传等功能(优先级低))。
由于RDMA协议通信接口为异步接口,对于同步RPC请求,多线程共享通信队列需要上下文切换,不能满足时延要求。需要设计低时延的同步机制进行上下文切换或无锁设计。
对于TCP而言,协议本身已经提供了流控机制和传输的可靠性,需要额外提供消息的上下文管理,即对发送消息和接收消息进行关联。
UB是无连接的,但与RDMA一样采用发送队列、接收队列和完成队列的方式进行通信,所以会话管理与RDMA一致。
5、消息处理
根据通信接口语义,需定义不同类型的消息,包括集群内节点间RPC通信消息、远端内存访问消息、节点间原子操作消息及集群间RPC通信消息。消息处理组件根据消息类型进行封装、解析为所需的消息类型。后续根据业务需要,对不同消息类型提供序列化、反序列化能力。
6、协议层
协议层需要同时适配RDMA/TCP/UB三种通信协议栈。
对于RDMA协议层的设计需要考虑:多线程并行发送RDMA请求时,并发请求的响应到达顺序与请求顺序不一致,因此不能在发送线程中通过检查CQ来查看自己的响应是否到达(可能先查到其它线程的响应),需要单独一个线程去检查CQ状态,这样就需要在发送线程与检查线程间进行同步,但线程同步机制很难满足时延要求(高并发场景下加解锁可能需要上千至上万个cycle),所以需要考虑协程或者无锁设计。如果使用协程,在线程的协程中轮询完成队列,其他协程进行发送请求,但是需要在业务模块启用协程,通信模块无法控制管理发送线程。如发送端无法采用协程设计,为了降低调度开销,对于有锁设计,CQ检查线程应该单独绑核,通过RDMA协议请求(WR)结构体ibv_send_wr、完成响应(CQE)结构体ibv_wc及响应(WR)结构体ibv_recv_wr三者的wr_id相互关联,该信息可放于双边通信的消息头的msgId字段或单边通信的立即数字段。wr_id是由通信组件传入的参数,可设置为消息的内存地址以避免重复。对于无锁设计,考虑采用run-to-complete模型,即线程间不共享QP,在一个线程内完成消息的发送和轮询事件,但资源消耗更大,更适用于对时延要求极高的单边操作场景。
RDMA原语的轮询CQ接口采用poll实现,对于大并发场景,poll的性能不及专门用于处理有大量IO操作请求的epoll异步编程接口。考虑设计epoll接口访问系统节点,轮询CQ完成队列,取代RDMA原语接口以获取更好性能。
RDMA协议不同传输模式支持的最大传输大小如上表所示, 双边通信可使用不可靠报文以节省内存资源,提高通信效率,但是最大传输数据长度受限于网卡MTU,需要限制发送数据,或者进行拆包发送、组包接收。
11.2.2 集群管理组件
云原生数据库支持全球集群部署和区域集群部署,相应的,故障检测也分为全球集群故障检测和区域集群内故障检测,全球集群故障主要检测区域集群网络故障、区域集群脑裂故障。区域集群内检测节点网络故障、租户节点分区、集群管理节点分区、DFV存储故障。不同的故障需要不同的心跳链路来检测,具体如下图所示。
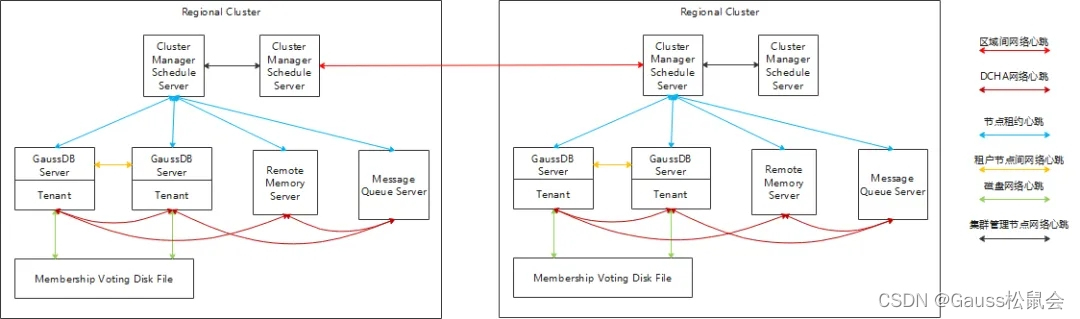
图4 集群组件心跳架构图
-
DCHA网络心跳,DCHA全称为DeCentralized High Availability,即去中心化故障快速检测方案。DCHA本质是一种邻居故障检测方法,能够更好地适应大规模集群故障检测,但是当大规模集群故障时可能导致漏报问题,需要通过其他机制,比如租约心跳机制作为补充。
-
节点租约心跳。节点租约心跳故障检测是指节点向集群管理节点获取心跳租约,当集群管理节点检测节点长时间未申请租约,将会判断此节点故障,同时如果节点长时间无法从集群管理节点获取租约,将进行自杀重启。
-
租户节点间网络心跳和DFV心跳。租户节点间互发网络心跳、写入DFV磁盘心跳,通过Membership Voting Disk机制判断租户脑裂和租户节点故障,并进行租户视图变更和故障重启。
-
集群管理间心跳根据部署形态选择不同心跳机制。如果是共享存储部署,则选用Membership Voting Disk机制。如果是share nothing单机部署形态,则选择普通心跳,通过Raft协议避免分区。
-
区域集群间网络心跳。每个区域集群通过Membership Voting Disk的一致性视图选择一个节点或者通过Raft协议选择的主节点当做本区域集群的节点代表与其他区域集群进行通信。区域集群间选择普通网络心跳,通过Raft协议避免区域集群的分区。
-
如果集群管理服务整体失效,则租户进程不能继续提供服务。如果节点主进程失效,则租户进程也不能继续提供服务。
****11.2.3多租组件
云原生数据库支持多租户,通过多租户资源共享,一是降低租户的成本,二是通过共享资源的池化实现租户的资源弹性,提高租户业务的可用性。租户的资源弹性支持两种模式,Scale Up和Scale Out。Scale Up是在单个计算节点上对租户的分配资源进行弹性处理,Scale Out是在计算节点之间对租户的分配资源进行弹性处理。
Scale Up的弹性模式在计算节点上实现,由计算节点上的多租户资源管理模块实现。Scale Out的弹性模式由集群管理节点的调度模块实现。因此整个多租户设计主要分为两个部分,分别为节点租户资源管理(节点上)和集群资源调度管理(节点间)。
租户购买的资源类型可以是固定型和弹性型。固定型的资源类型总是始终保证的。弹性型对应到Scale Up和Scale Out两种弹性模型。弹性型的资源类型由可变的节点个数和每个节点上可变的资源大小组成,分别表述为租户节点个数最小值和租户节点个数最大值、租户节点资源最小值和租户节点资源最大值。
最小值是始终保证的,弹性是在最小值和最大值之间做弹性伸缩。节点租户资源管理处理节点上租户资源的最小值-最大值之间的弹性;集群资源调度管理处理租户资源总的节点数在租户节点最小值-租户节点最大值之间的弹性。即绝对保证固定资源分配和最小预留资源分配,最小预留到最大上限部分的弹性资源不绝对保证,根据租户的工作负载情况和优先级进行资源调度。
租户节点资源管理和集群资源调度管理的两层整体架构如下:

图5 集群资源调度和计算节点资源管理逻辑图
对于集群资源调度,多个计算节点上的资源组成一个大的资源池,集群资源调度负责整个资源池的管理和调度,比如租户数据库服务初始化部署时一次调度分配资源,以及租户数据库服务迁移的二次调度分配资源。一次调度只关注租户资源配置进行静态的资源调度分配,即根据固定资源,或者最小预留资源设置进行调度。二次调度则是根据租户数据库服务负载统计信息和计算节点负载信息进行调度。
对于节点租户资源管理,云原生数据库采用进程级的资源隔离来实现多租户资源隔离,即在一个计算节点上每个租户拥有一个数据库服务进程。每个计算节点可以看作一个单独小资源池,节点租户资源管理主要负责计算节点上租户的资源分配,资源隔离与弹性控制,以及租户数据库服务的管理,如启动,停止等。
以上内容为云原生关键技术架构&关键技术方案的相关内容,由于关键技术方案部分内容过多,下篇将接着从事务存储组件、SQL引擎组件、DCS组件、实时分析组件等方面继续分享关键技术方案的相关内容,敬请期待!