es
- [0. 基础概念](#0. 基础概念)
-
- [0.1 倒排索引](#0.1 倒排索引)
- [0.2 文档、索引](#0.2 文档、索引)
- [0.3 与mysql对比](#0.3 与mysql对比)
- [1 基本操作](#1 基本操作)
-
- [1.1 mapping 索引库操作](#1.1 mapping 索引库操作)
- [1.2 单个文档CRUD](#1.2 单个文档CRUD)
- [3. DSL查询](#3. DSL查询)
-
- [3.1 查询所有](#3.1 查询所有)
- [3.2 全文检索](#3.2 全文检索)
- [3.3 精确查询](#3.3 精确查询)
- [3.4 复合查询-相关性得分](#3.4 复合查询-相关性得分)
- [3.5 分页](#3.5 分页)
- [3.6 高亮](#3.6 高亮)
- [3.7 总结](#3.7 总结)
- [2. RestClient](#2. RestClient)
- [4. aggs聚合](#4. aggs聚合)
-
- [4.1 bucket(分桶)聚合](#4.1 bucket(分桶)聚合)
- [4.2 metrics聚合](#4.2 metrics聚合)
- [5. mysql与es数据同步](#5. mysql与es数据同步)
- [6. es集群](#6. es集群)
- extra:es集群数据去重
0. 基础概念
es本质:一个基于Lucence开发出来的分布式搜索引擎

0.1 倒排索引

创建倒排索引后给词条创建索引,总计进行了两次查询
0.2 文档、索引
文档:一条数据记录
索引:类型相同的文档的集合
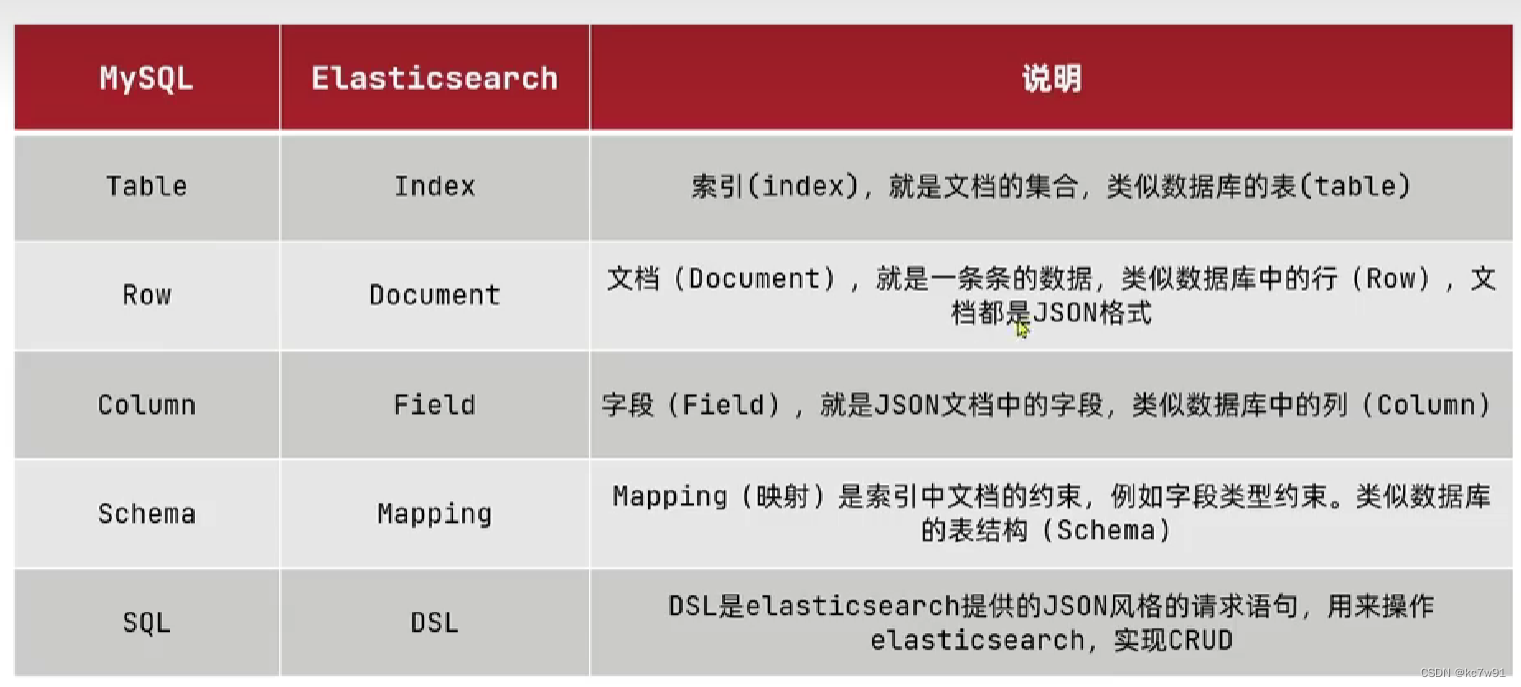
0.3 与mysql对比
交易等一致性要求高的mysql做
大范围搜索es做
1 基本操作
1.1 mapping 索引库操作

举例:注意object嵌套关系

禁止修改索引库,但是可以添加新字段
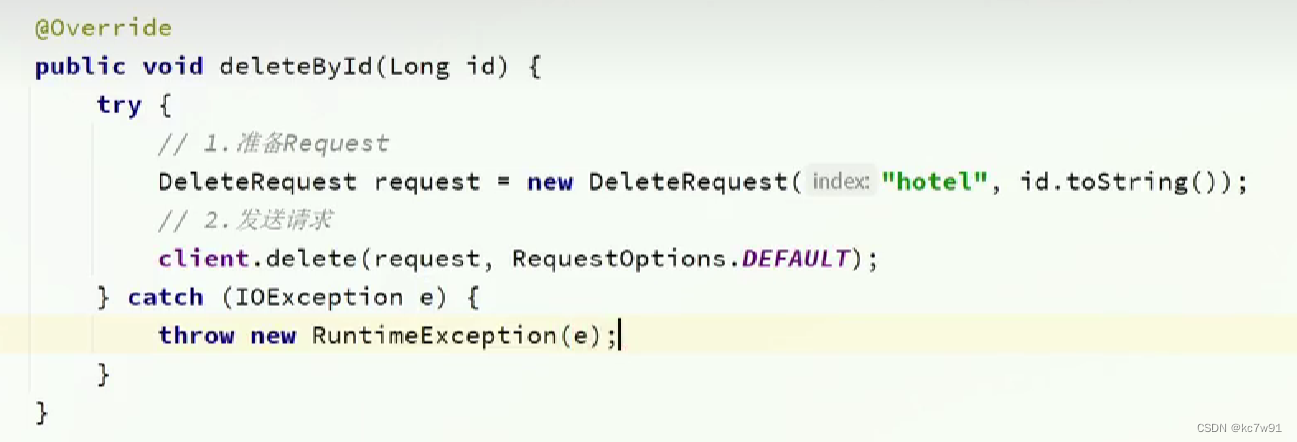
1.2 单个文档CRUD
文档查询:
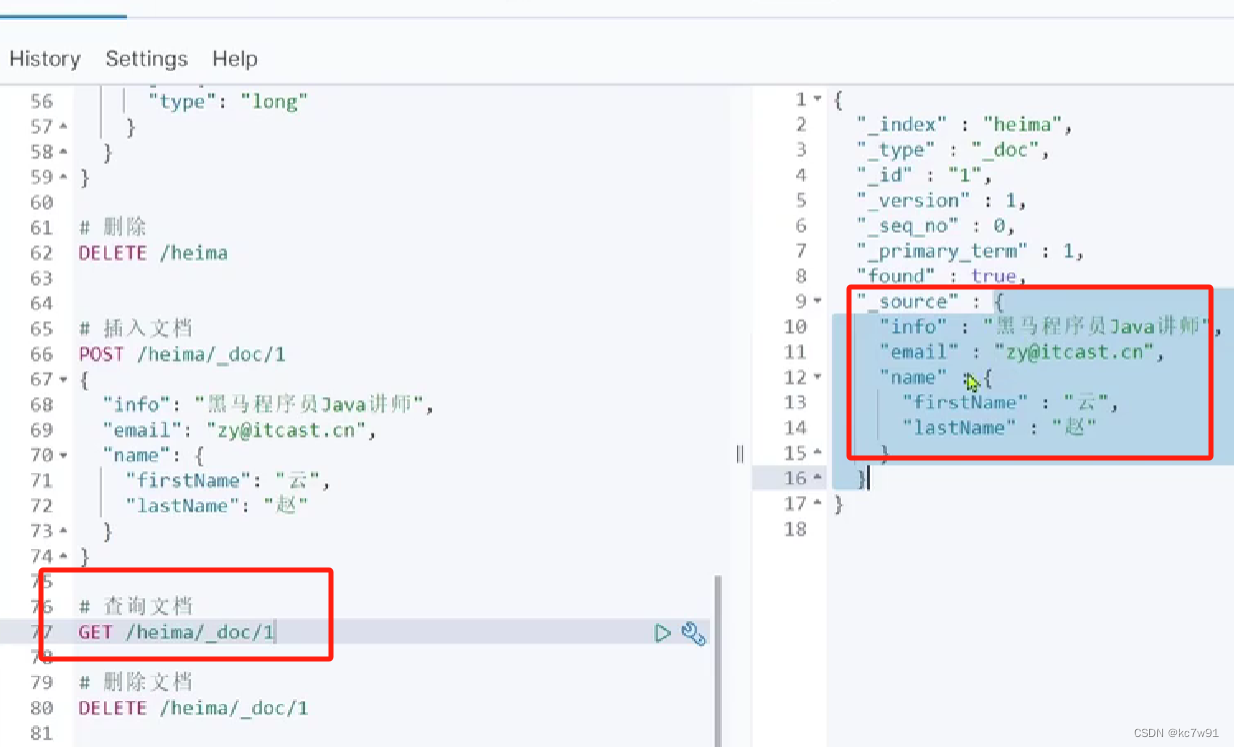
_source字段下是查询到的原始文档
文档修改:
全量修改:旧的直接删除,新增改后的文档
增量修改:在旧的上面修改

3. DSL查询
dsl常见查询分类:

3.1 查询所有

3.2 全文检索

muti_match的方式能够额外指定针对哪些字段进行查询(任意一个字段包含即可)
3.3 精确查询
值是确定的,不可分割,不可分词,完全匹配

3.4 复合查询-相关性得分
相关性得分算法:(第三种 default)
es 自带的 query score:

自定义function score函数:

自定义score函数时主要确定三个部分:
- 哪些文档将进行加权
- 算分函数function score如何定义
- function score怎么与原始得分query score(BM25)进行加权
demo:

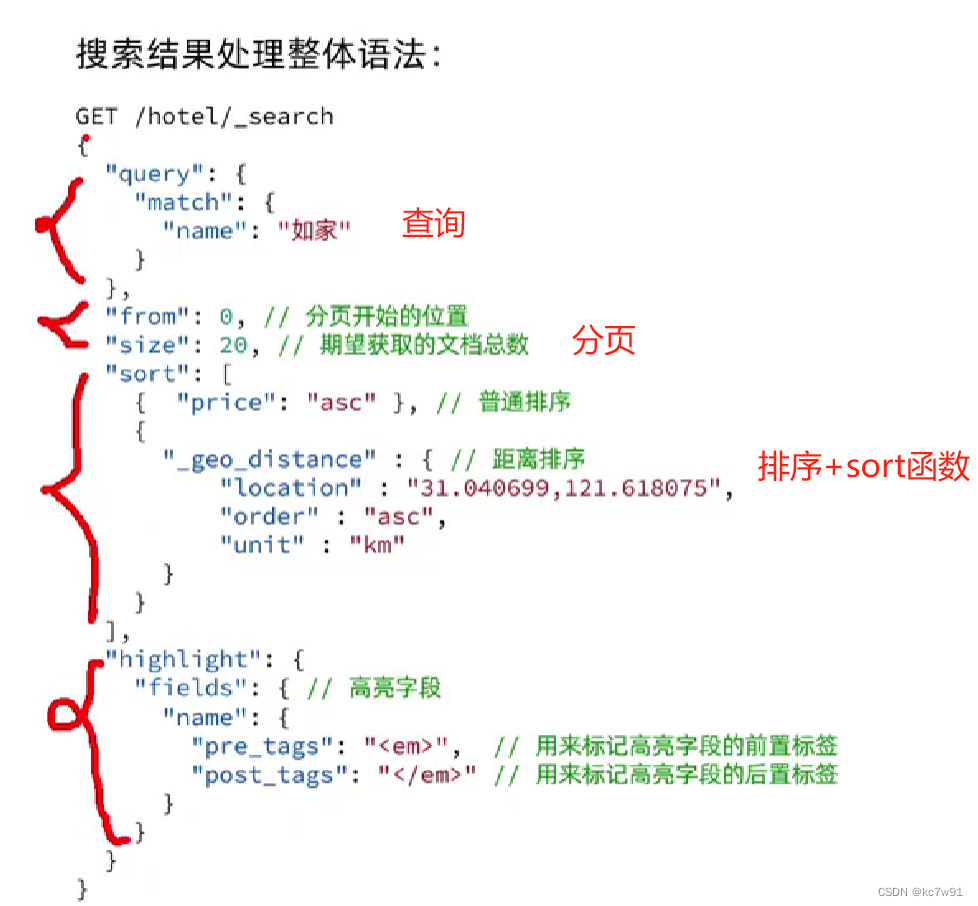
3.5 分页
深度分页问题:
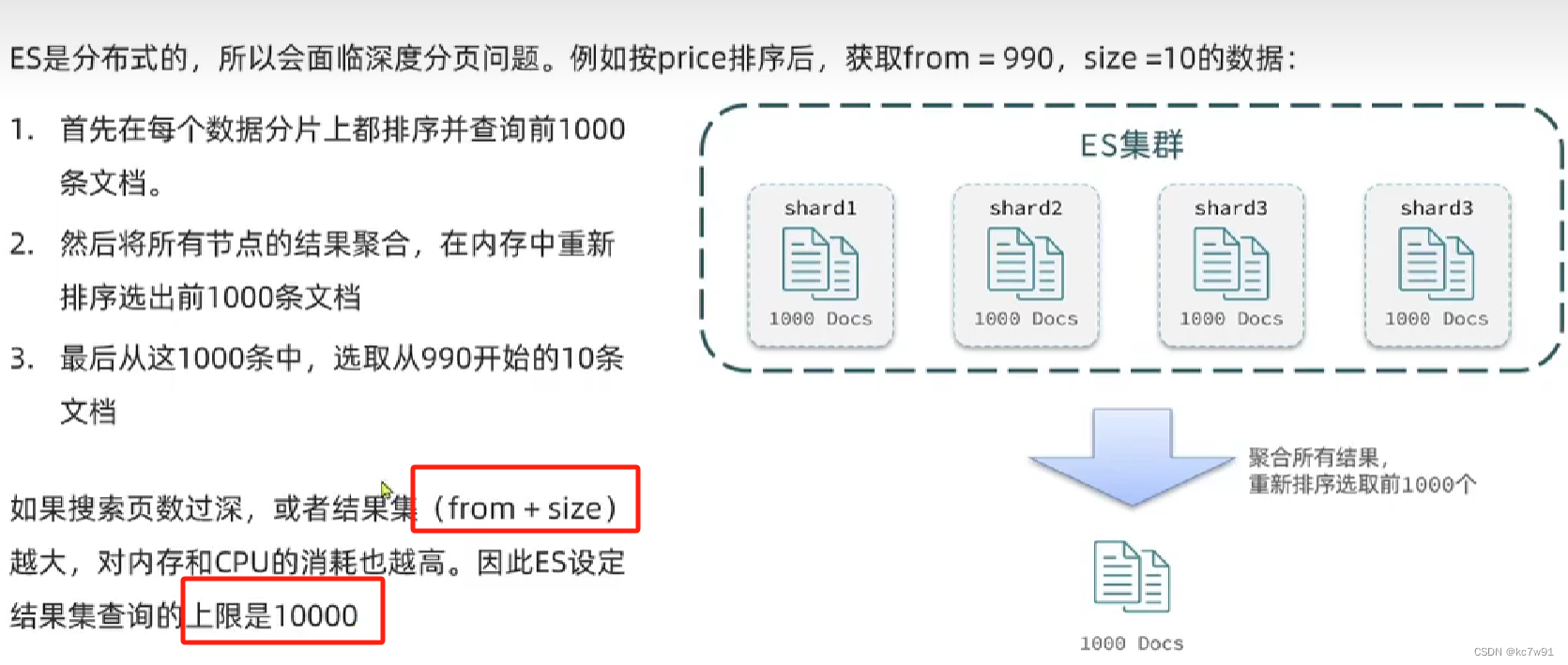
from+size超过1w会直接报错,如果非要查一万条,不太现实,实际生产应用中会从业务层面避免查询1w条(从业务上拒绝),比如百度就是默认最多查70页,每页显示10条数据

3.6 高亮
高亮的结果解析是与_source同级的,需要额外注意:

3.7 总结
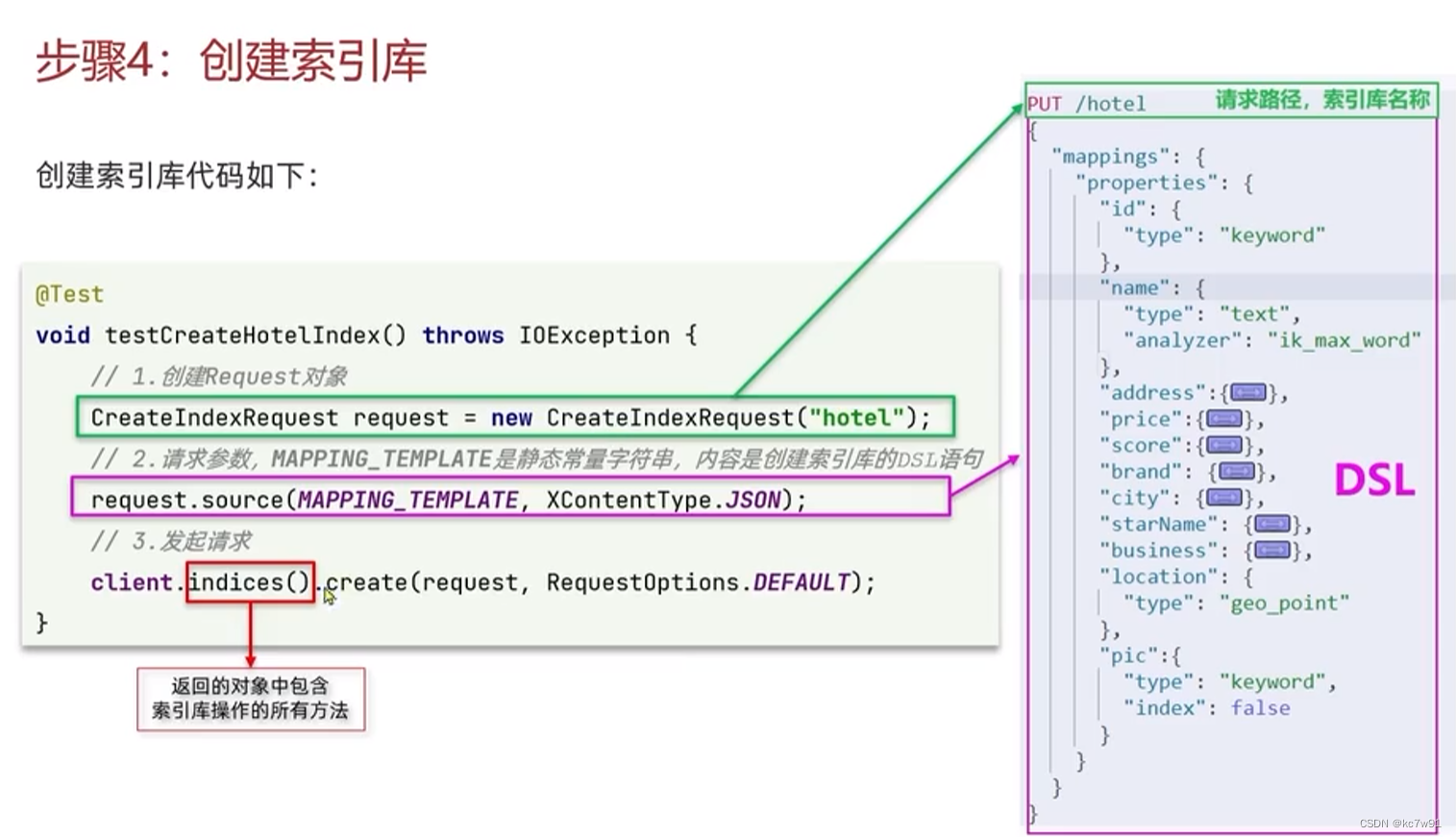
2. RestClient
将dsl语句对应到Java

上图中涉及了两个核心api:
source .query()/source()等:
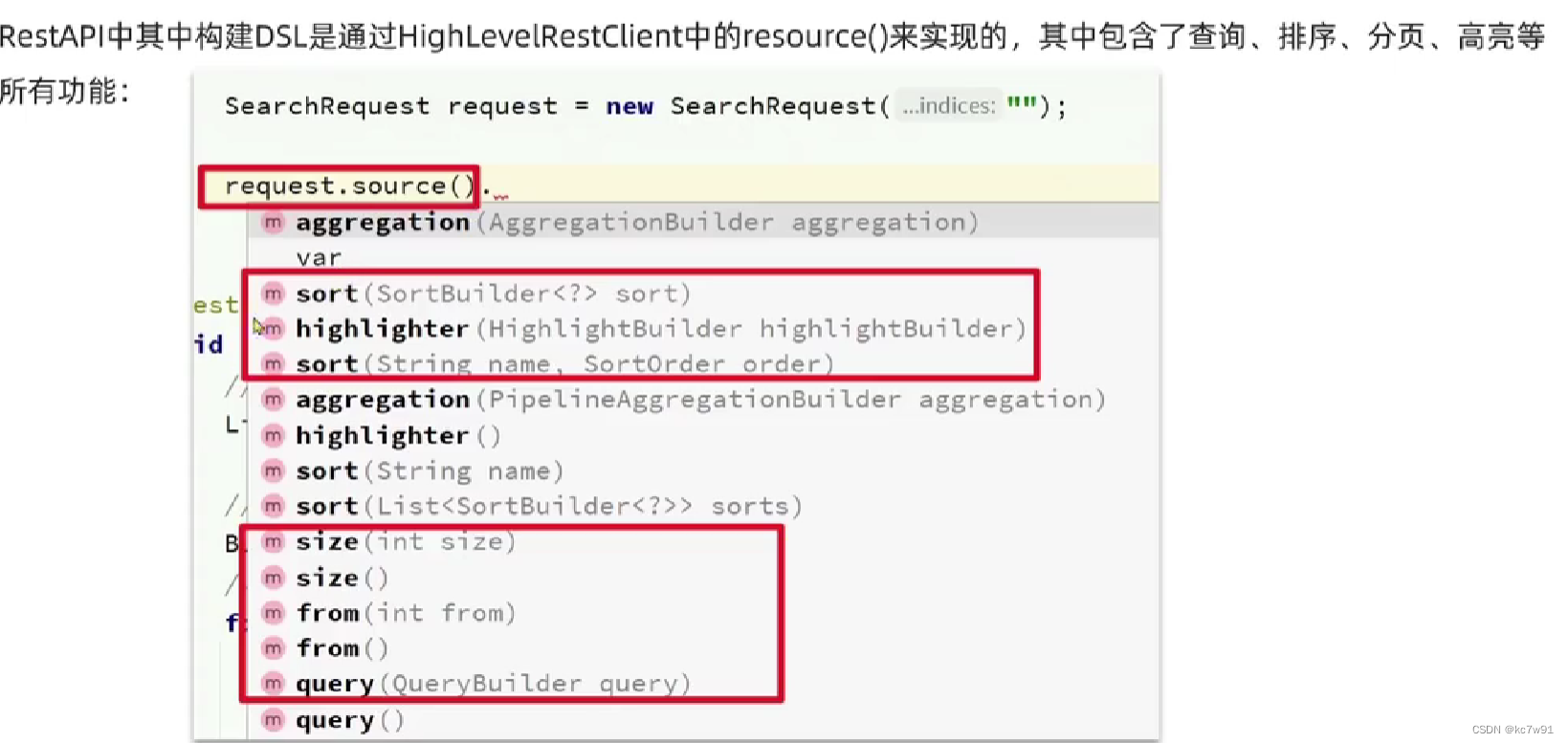
QueryBuilders .各种查询query:

解析查询响应结果:
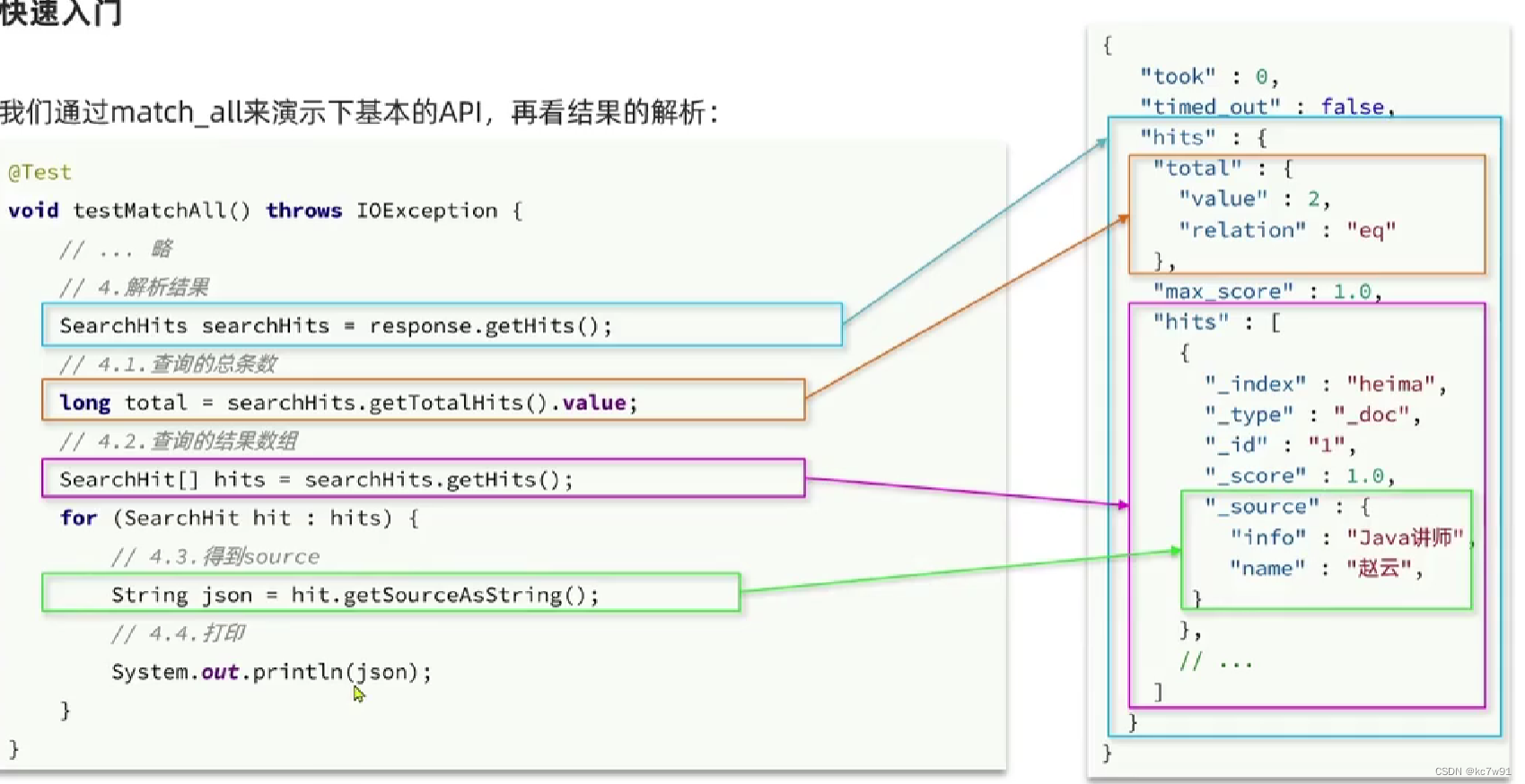

常见查询:
全文检索查询:

精确查询:





聚合:

4. aggs聚合
聚合操作与query同级,用于对文档进行统计、分析、计算(min/max/avg...)
常见聚合方式:
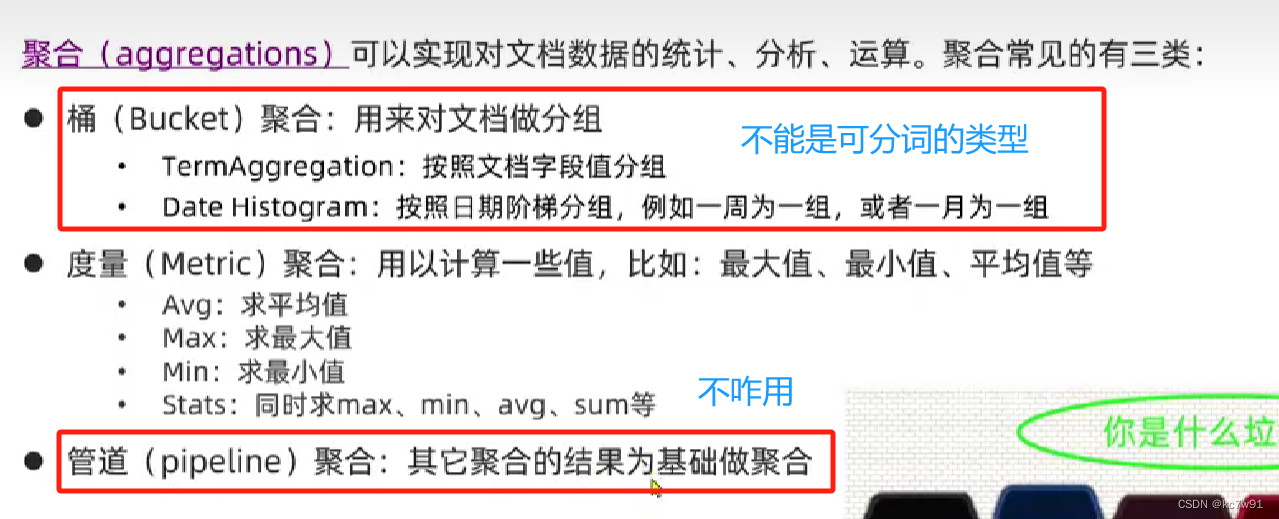
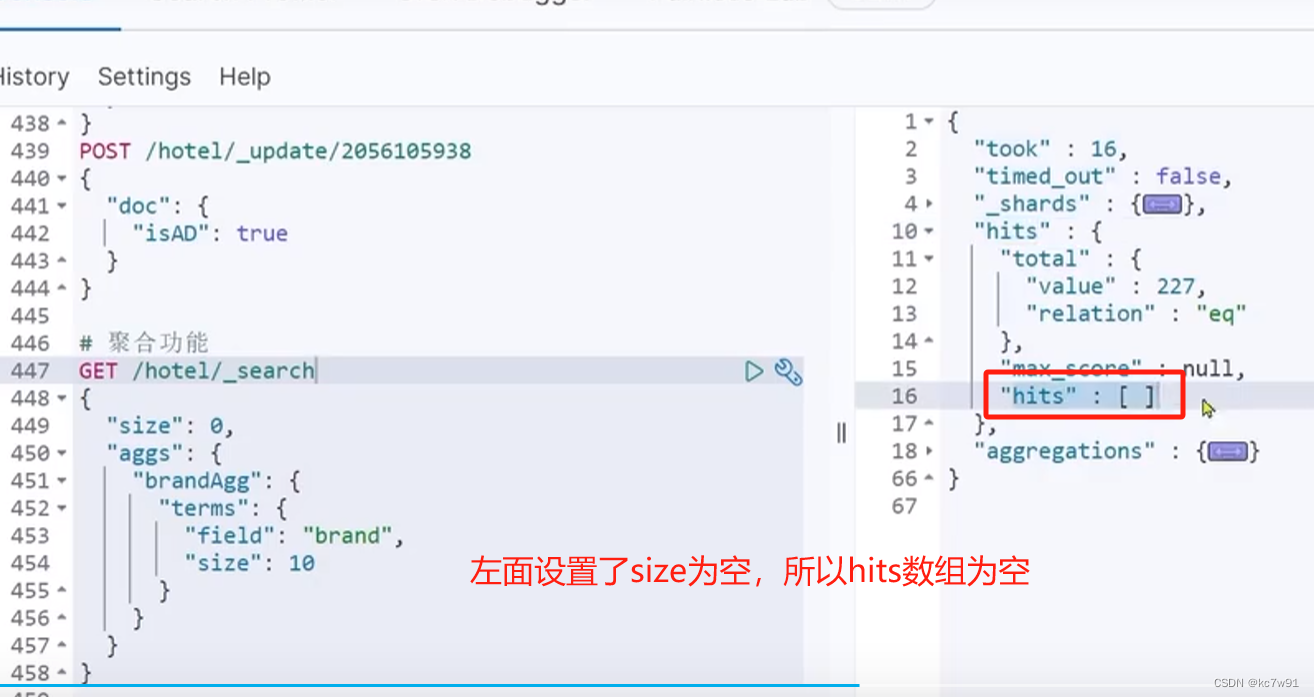
4.1 bucket(分桶)聚合

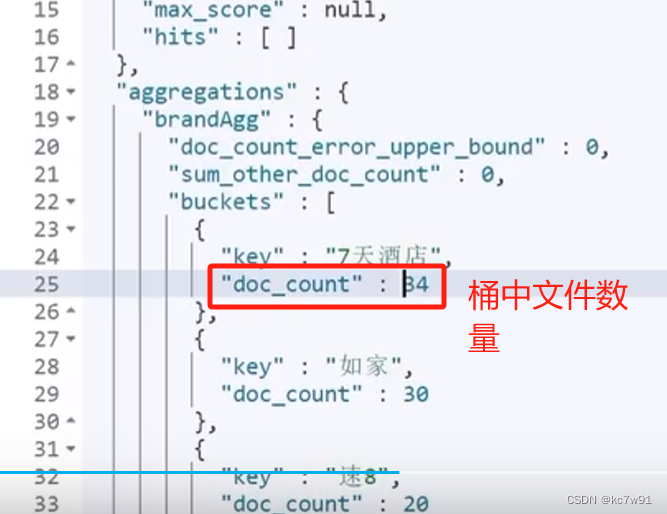
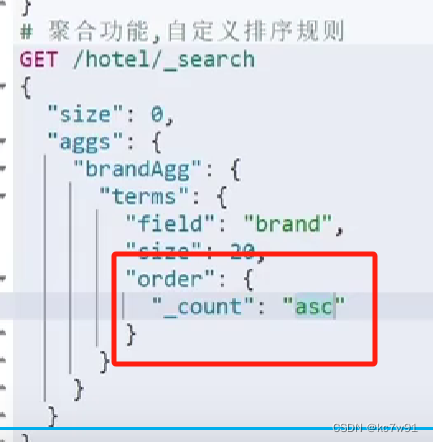
默认按照doc_count降序排序,如若修改排序方式:

4.2 metrics聚合

红框:
聚合名称:scoreAgg
聚合类型:stats
聚合字段:score
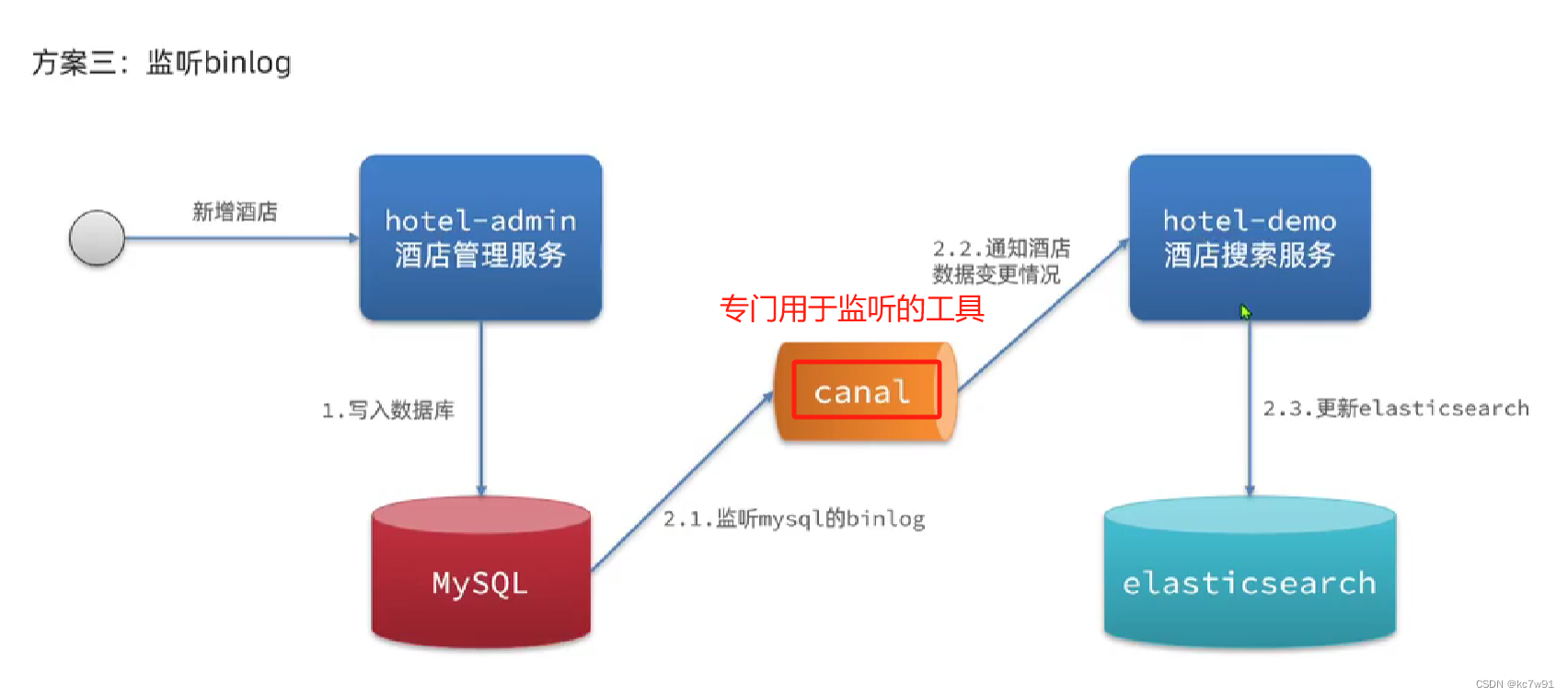
5. mysql与es数据同步
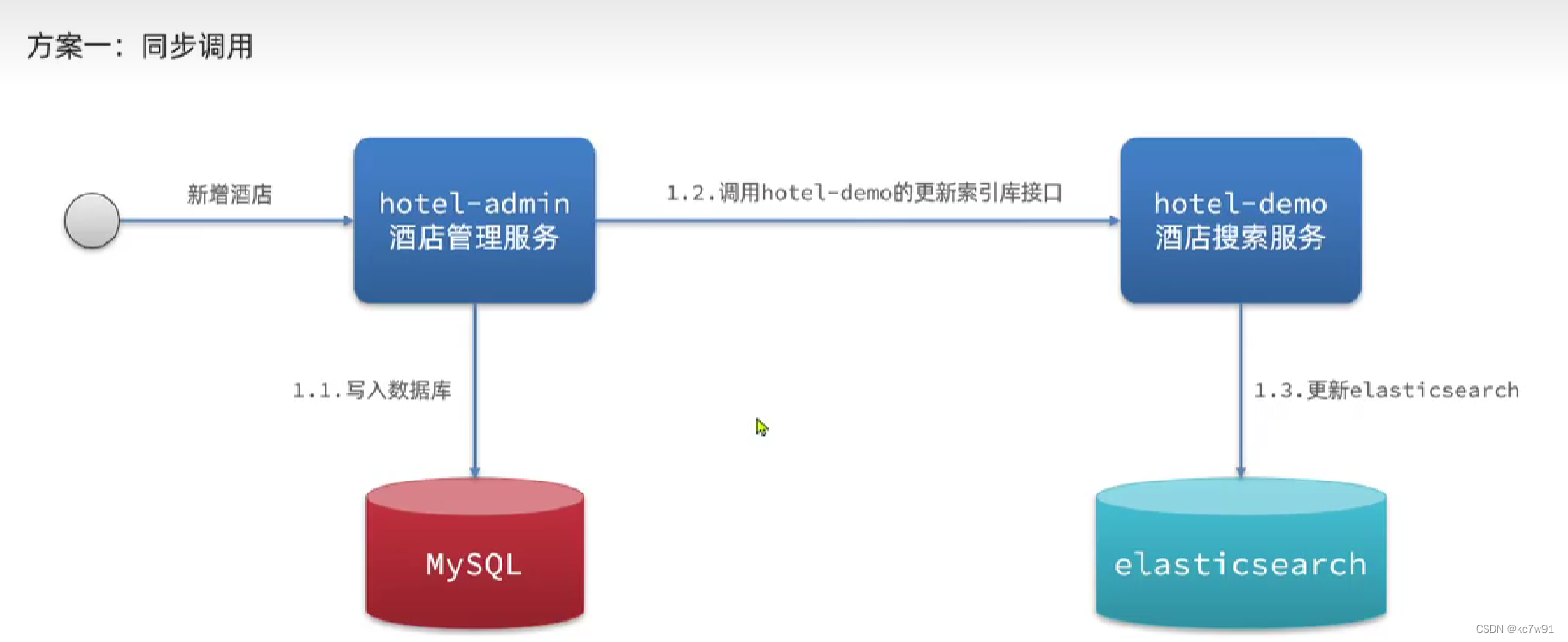
方案一缺点:业务之间耦合度强,调用耗时
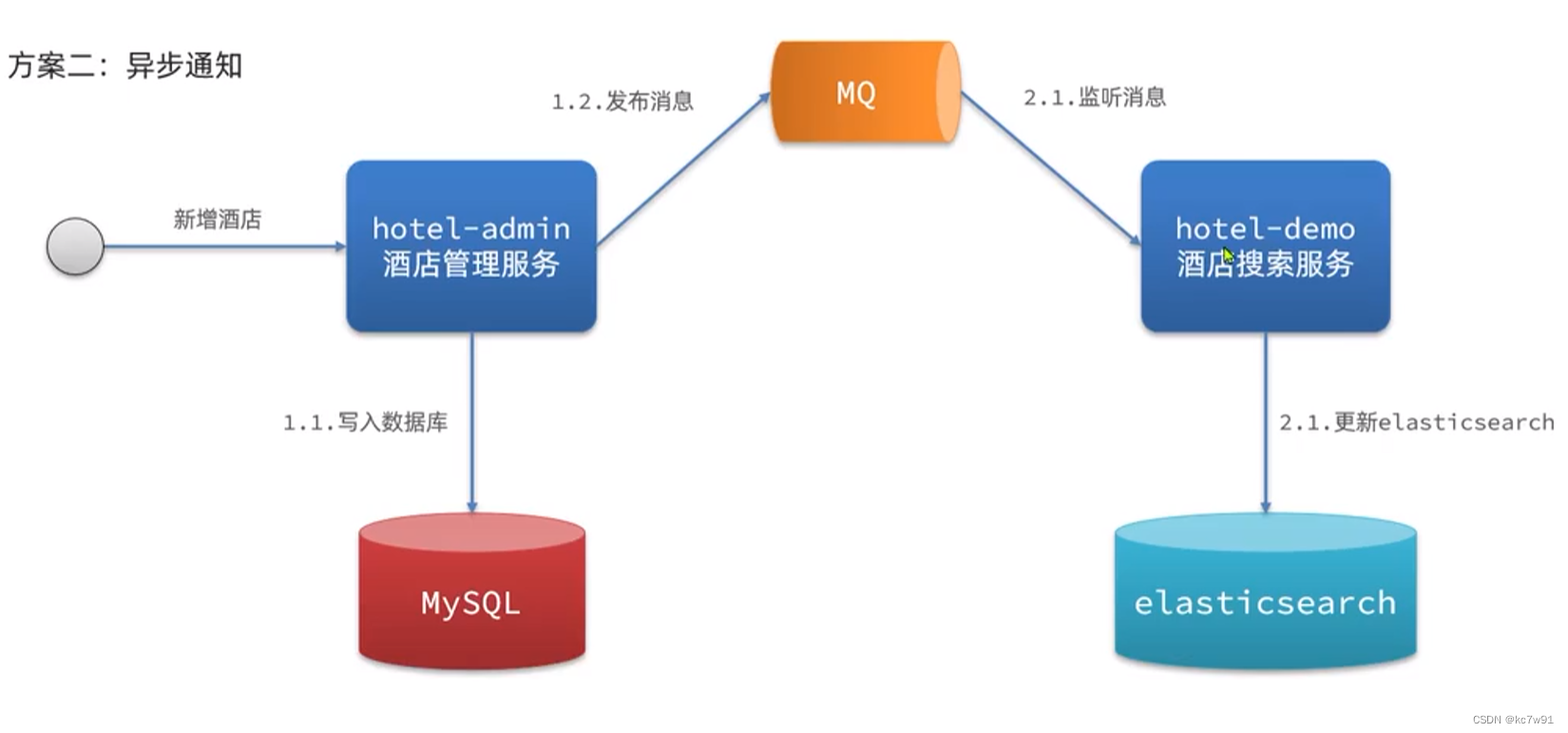
方案二缺点:依赖mq的可靠性

demo:基于mq的实现方式
mq的消息模式:其中交换机用于将消息路由
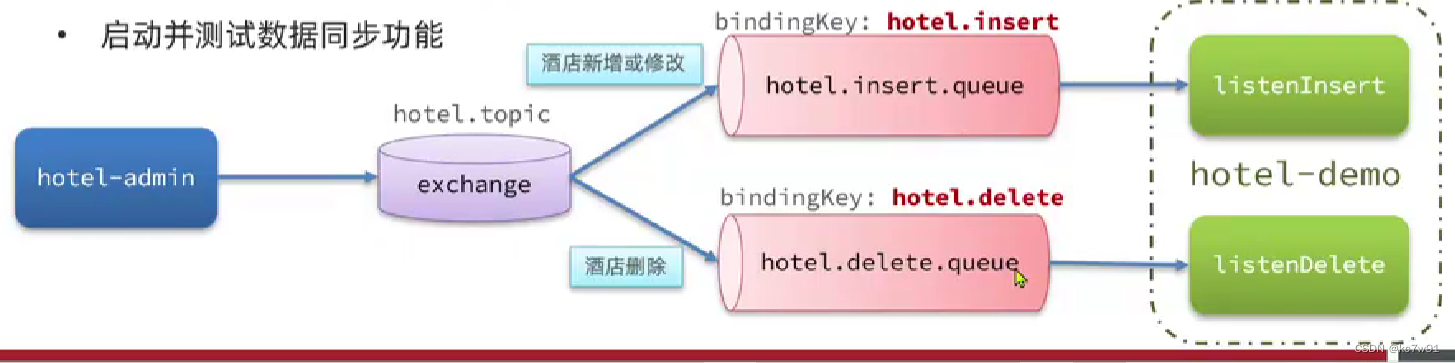
定义模式:

然后定义绑定关系:将某个队列绑定到指定交换机、用哪个routingKey:

消息发送(两种消息:增改(公用一个key)和删(另一个key)):


消息监听与消费:
定义监听:
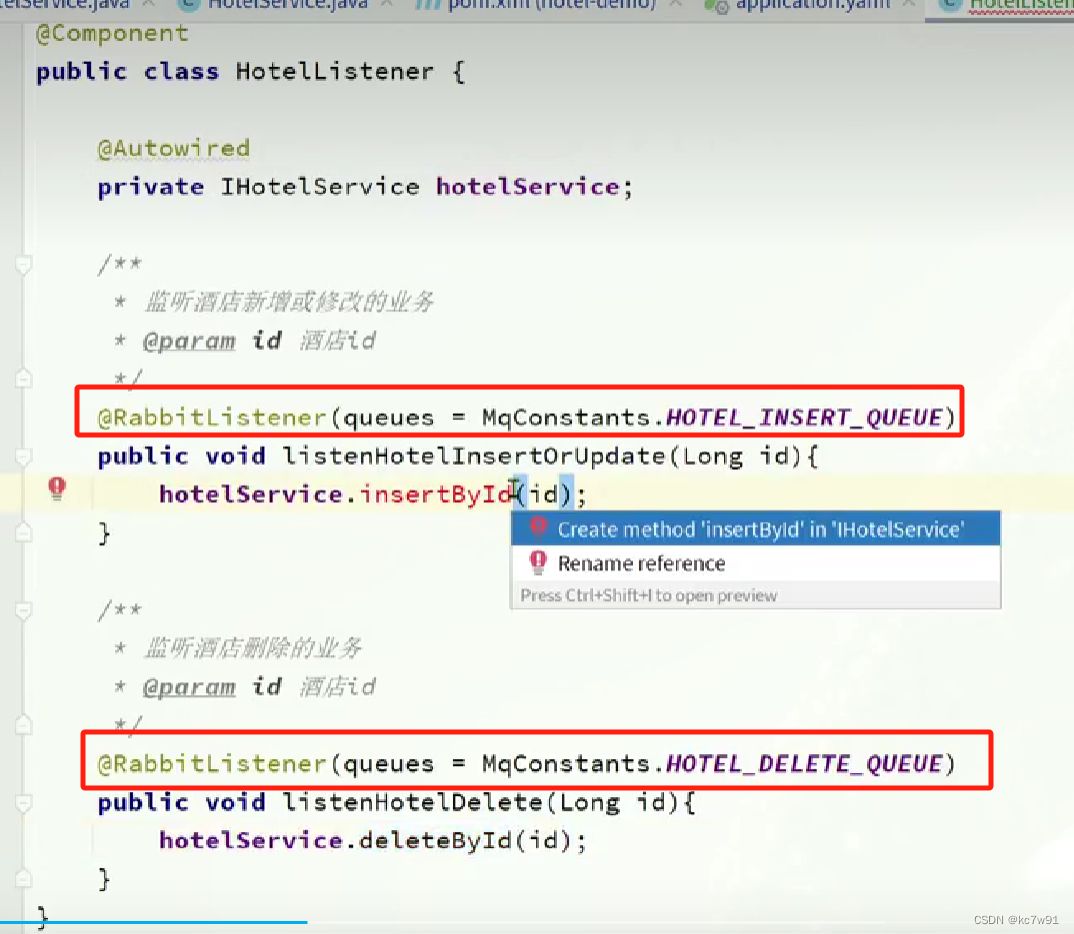
具体实现: