AI大模型应用(1)OpenAi API快速入门
- 2022 年 11 月,ChatGPT 成功面世,成为历史上用户增长最快的消费者应用。与 Google、FaceBook等公司不同,OpenAI 从初代模型 GPT-1 开始,始终贯彻只有解码器(Decoder-only)的技术路径,不断迭代升级。
| 模型 | 发布日期 |
|---|---|
| GPT | 2018-11-14 |
| GPT-2 | 2019-11-27 |
| GPT-3 | 2020-6-11 |
| InstructGPT | 2022-3-4 |
| ChatGPT | 2022-11-30 |
| GPT-4 | 2023-3-14 |
| ChatGPT Plugin | 2023-5-12 |
-
可以看到,2022 年是 GPT 系列模型围绕 GPT-3、GPT-3.5 加速版本迭代的年份;
- 2022 年 3 月,基于 GPT-3 微调的 InstructGPT 发布,验证了人类反馈强化学习RLHF对模型输出对齐(alignment)的重要作用;
- 2022年4-6月,基于Codex、InstructGPT,OpenAI 加速迭代形成 GPT-3.5 模型;
- 2022 年 11 月,基于 GPT-3.5 微调的 ChatGPT 发布,成为 Instruction-tuning、RLHF、思维链等 LLM 相关技术的集大成者。
- ChatGPT与InstructGPT的训练方法基本一致,区别在于InstructGPT、ChatGPT分别基于GPT-3、GPT-3.5进行模型微调。
- InstructGPT具体可分为有监督微调、奖励模型训练、PPO 强化学习三个步骤。
- ChatGPT技术原理解析可参考:https://blog.csdn.net/v_JULY_v/article/details/128579457
- 2023年3月中旬,OpenAI正式对外发布GPT-4,增加了多模态(支持图片的输入形式),且ChatGPT底层的语言模型直接从GPT3.5升级到了GPT4。
-
ChatGPT 的发展不仅得益于 GPT 模型参数、训练数据的持续优化,也得益于各类 LLM 新技术的融会贯通,OpenAI 博采众长,加速 Instruction-tuning、RLHF、思维链等新技术在 GPT 系列模型中的深度应用,ChatGPT 是现有技术的集大成者。
-
我们今天从应用的角度,利用Open AI提供的API,学习下Prompt(提示词)、Function Calling(外部函数调用)、RAG(检索增强生成)等相关内容。
1 OpenAi API的Hello World
1.1 API的获取
- 由于众所周知的原因,OpenAI是不对国内用户正式开放的。所以如果你想使用ChatGPT或调用OpenAI的接口,要么搭梯子翻墙,要么使用国内代理。
- 为了方便,我这里使用国内的代理。代理网站会提供给你一个虚拟的API key,我们只需要把使用代理网站提供的url和key就行了,使用起来和原生的区别不大。
- 这里提供两个代理网站,可以自己注册下(首次注册应该会赠送一定的免费次数或金额,用多了之后可能就需要花钱了):
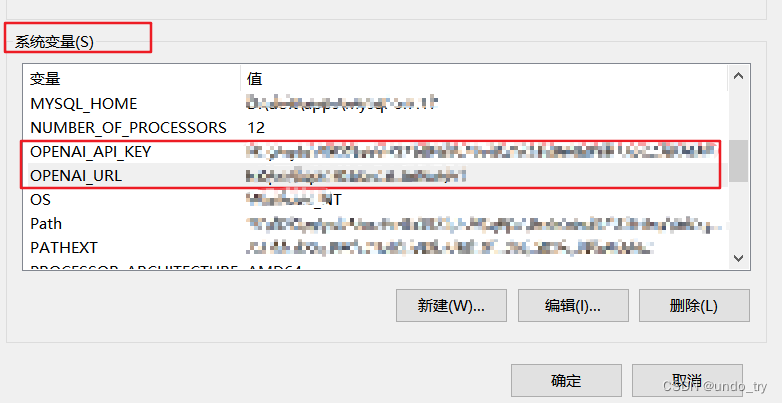
- 我们把相关信息配置到系统环境变量中,避免暴露在代码中:
1.2 OpenAi API的Hello World
- 然后,我们就可以进行OpenAi API的Hello World了:
python
from openai import OpenAI
import os
# pip install --upgrade openai
# 加载环境变量
api_key = str(os.getenv('OPENAI_API_KEY'))
api_url = str(os.getenv('OPENAI_URL'))
# 注意:这里需要填上代理的url和key
client = OpenAI(base_url=api_url, api_key=api_key)
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁?"}
]
)
print(completion)
print(completion.choices[0].message.content)
shell
ChatCompletion(
id='chatcmpl-bYXeb6IMk7vrgoHKUm64EuNRpCoAk'
, choices=[Choice(
finish_reason='stop'
, index=0
, logprobs=None
, message=ChatCompletionMessage(
content='我是一个由OpenAI开发的语言模型,可以帮助您回答各种问题和提供信息。您有什么需要帮忙的吗?\n'
, role='assistant'
, function_call=None
, tool_calls=None)
)
]
, created=1718347832
, model='gpt-3.5-turbo'
, object='chat.completion'
, system_fingerprint=None
, usage=CompletionUsage(completion_tokens=46, prompt_tokens=27, total_tokens=73)
)
我是一个由OpenAI开发的语言模型,可以帮助您回答各种问题和提供信息。您有什么需要帮忙的吗?- 从下图可以看到(https://platform.openai.com/docs/quickstart),和原生API几乎一样。
1.3 关键参数解释
python
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁?"}
]
)
@required_args(["messages", "model"], ["messages", "model", "stream"])
def create(
self,
*,
messages: Iterable[ChatCompletionMessageParam],
model: Union[str, ChatModel],
max_tokens: Optional[int] | NotGiven = NOT_GIVEN,
temperature: Optional[float] | NotGiven = NOT_GIVEN,
tool_choice: ChatCompletionToolChoiceOptionParam | NotGiven = NOT_GIVEN,
tools: Iterable[ChatCompletionToolParam] | NotGiven = NOT_GIVEN,
top_p: Optional[float] | NotGiven = NOT_GIVEN,
)重要参数解释下:
-
model:用来指定使用哪个模型,例如:gpt-3.5-turbo
-
messages:传入大模型的prompt,prompt有三种角色:
- system:系统指令,用于初始化GPT行为,以及规定GPT的角色、背景和后续行为模式。system是主提示,可以进行更加详细的设置。
- user: 用户输入的信息。
- assistant: 机器回复,由 API 根据 system 和 user 消息自动生成的。
-
max_token:控制了输入和输出的总的token上限
-
temperature:在0和2之间选择采样温度。
- 值越高,如0.8,会使输出更随机;而值越低,如0.2,会使输出更集中和确定性更强。
- 通常建议修改这个值或
top_p,但不要同时修改两者。 - Temperature 用于调整模型的softmax输出层中预测词的概率。温度参数定义为在应用 softmax 函数之前用于调整 logits 的比例因子的倒数。
- 当temperature 设置为较低的值时,预测词的概率会变尖锐,这意味着选择最有可能的词的概率更高。这会产生更保守和可预测的文本,因为模型不太可能生成意想不到或不寻常的词。
- 另一方面,当temperature 设置为较高值时,预测词的概率被拉平,这意味着所有词被选择的可能性更大。这会产生更有创意和多样化的文本,因为模型更有可能生成不寻常或意想不到的词。
-
top_p:与 temperature 一起称为核采样的技术,如:0.1 表示仅考虑组成顶部 10% 概率质量的标记。
下面两个属于函数调用,我们后面再讲:
- tools: 模型可能调用的工具列表:
- 目前只支持函数作为工具。
- 用 JSON 描述函数,可以定义多个,由模型决定调用谁
- 最多支持 128 个函数。
- tool_choice: 控制模型是否调用工具(如果有的话):
none意味着模型将不会调用任何工具,而是生成一条消息。auto意味着模型可以选择生成消息或调用一个或多个工具。required意味着模型必须调用一个或多个工具。通过指定{"type": "function", "function": {"name": "my_function"}}可以强制模型调用该工具。- 默认情况下,none 在没有工具存在时生效,auto 在存在工具时生效。
2 外部函数调用(Function Calling)
大模型目前存在下面的局限性:
- 训练数据不全面。由于训练数据的局限性,大模型无法涵盖所有信息,尤其是一些垂直或非公开数据。
- 知识更新滞后。大模型的训练周期很长,更新成本高昂,因此难以实时更新知识,通常滞后于最新信息。以GPT-3.5为例,其知识库截止于2022年1月,而GPT-4的则为2023年4月。
- 缺乏真正的逻辑推理能力。大模型表现出的逻辑和推理能力,实质上是基于训练文本的统计规律,而非真正的符合逻辑的思维。
- 这意味着其输出结果存在一定的不确定性,对于需要精确和确定结果的领域(如数学等)来说,可能难以满足要求。
- 例如,对于加法运算,大模型可能通过记忆100以内加法算式的统计规律,能够正确回答100以内的加法问题。但对于更大数字的加法,其结果就可能不准确,因为它并未真正理解加法的概念和原理。
2.1 调用本地函数
python
from openai import OpenAI
import os
import json
# 从环境变量中获取API密钥和URL
api_key = str(os.getenv('OPENAI_API_KEY'))
api_url = str(os.getenv('OPENAI_URL'))
# 创建OpenAI客户端
client = OpenAI(base_url=api_url, api_key=api_key)
# 定义获取模型回复的函数
def get_completion(messages, model="gpt-4-turbo", tools_arr=None):
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0,
max_tokens=1024,
tools=tools_arr
)
return response.choices[0].message
# 定义初始提示
prompt = "桌上有2个苹果,四个桃子和 3 本书,一共有几个水果?"
# 创建消息列表,包含系统和用户的消息
messages = [
{"role": "system", "content": "你是一个数学家,你可以计算任何算式。"},
{"role": "user", "content": prompt}
]
# 不使用tools进行第一次模型调用
response = get_completion(messages)
print(response)
shell
ChatCompletionMessage(
content='桌上共有2个苹果和4个桃子,所以一共有:\n\n2 + 4 = 6个水果。'
, role='assistant'
, function_call=None
, tool_calls=None
)然后,我们利用tools添加模型可能调用的工具列表
python
# 定义工具数组,包含sum函数
tools_arr = [
{
"type": "function", # 定义工具的类型为函数
"function": {
"name": "sum", # 函数的名称
"description": "sum函数可以用来计算一组数的和", # 函数的描述信息
"parameters": { # 函数的参数定义
"type": "object", # 参数类型为对象
"properties": { # 对象的属性定义
"numbers": { # 属性名称为numbers
"type": "array", # numbers属性的类型为数组
"items": { # 数组的每个元素的类型
"type": "number" # 每个元素为数字类型
}
}
}
}
}
},
]
# 使用工具进行第二次模型调用
response = get_completion(messages, tools_arr=tools_arr)
print(response)
shell
# 此时没有返回content,而是返回了tool_calls
ChatCompletionMessage(
content=None
, role='assistant'
, function_call=None
, tool_calls=[
ChatCompletionMessageToolCall(
id='call_Iswjguap2SQh1IogVEFVBi2c'
, function=Function(
# 可以看到返回了函数的名称和函数的参数
arguments='{"numbers":[2,4]}', name='sum')
, type='function'
)
]
)当大模型返回了需要调用的名称和参数之后,我们可以通过本地代码解析出来,然后再去调用相应函数
python
# 将模型的响应加入到消息列表中
messages.append(response)
# 如果返回的是函数调用结果,则打印出来
if (response.tool_calls is not None):
for tool_call in response.tool_calls:
print(f"调用 {tool_call.function.name} 函数,参数是 {tool_call.function.arguments}")
if tool_call.function.name == "sum":
# 调用sum函数(本地函数或库函数,非chatgpt),打印结果
args = json.loads(tool_call.function.arguments) # {"numbers":[2,4]}
result = sum(args["numbers"])
print("=====函数返回=====")
print('函数返回值为:', result)
# 把函数调用结果加入到对话历史中
messages.append(
{
"tool_call_id": tool_call.id,
"role": "tool",
"name": "sum",
"content": str(result)
}
)
# 再次调用大模型,获取最终回复
print('messages: \n', messages)
print(get_completion(messages).content)
shell
调用 sum 函数,参数是 {"numbers":[2,4]}
=====函数返回=====
函数返回值为: 6
messages:
[
{'role': 'system', 'content': '你是一个数学家,你可以计算任何算式。'},
{'role': 'user', 'content': '桌上有2个苹果,四个桃子和 3 本书,一共有几个水果?'}, ChatCompletionMessage(content=None
, role='assistant'
, function_call=None
, tool_calls=[ChatCompletionMessageToolCall(
id='call_Iswjguap2SQh1IogVEFVBi2c'
, function=Function(arguments='{"numbers":[2,4]}', name='sum')
, type='function'
)
]),
{
'tool_call_id': 'call_Iswjguap2SQh1IogVEFVBi2c',
'role': 'tool',
'name': 'sum',
'content': '6'
}
]
桌上一共有6个水果。2.2 调用外部接口(多函数调用)
这里这使用高德地图的开放接口
- get_location_coordinate用于查询某个地点的地理坐标。
- search_nearby_pois用于查询地理坐标附近的某些信息(取决于用户输入的Keyword)
python
from openai import OpenAI
import os
import json
import requests
# 从环境变量中获取API密钥和URL
api_key = str(os.getenv('OPENAI_API_KEY'))
api_url = str(os.getenv('OPENAI_URL'))
# 高德地图注册平台:https://console.amap.com/dev/key/app
amap_key = 'xxx'
# 创建OpenAI客户端
client = OpenAI(base_url=api_url, api_key=api_key)
# 定义获取模型回复的函数
def get_completion(messages, model="gpt-4-turbo", tools_arr=None):
response = client.chat.completions.create(
model=model,
messages=messages,
tools=tools_arr
)
return response.choices[0].message
# 定义初始提示
prompt = "上海市人民广场附近的咖啡店信息"
# 创建消息列表,包含系统和用户的消息
messages = [
{"role": "system", "content": "你是一个地图专家,你可以找到任何地址"},
{"role": "user", "content": prompt}
]
def get_location_coordinate(location, city="上海"):
url = f"https://restapi.amap.com/v5/place/text?key={amap_key}&keywords={location}®ion={city}"
print(url)
r = requests.get(url)
result = r.json()
if "pois" in result and result["pois"]:
return result["pois"][0]
return None
def search_nearby_pois(longitude, latitude, keyword):
url = f"https://restapi.amap.com/v5/place/around?key={amap_key}&keywords={keyword}&location={longitude},{latitude}"
print(url)
r = requests.get(url)
result = r.json()
ans = ""
if "pois" in result and result["pois"]:
for i in range(min(3, len(result["pois"]))):
name = result["pois"][i]["name"]
address = result["pois"][i]["address"]
distance = result["pois"][i]["distance"]
ans += f"{name}\n{address}\n距离:{distance}米\n\n"
return ans
# 定义工具数组
tools_arr = [
{
"type": "function",
"function": {
"name": "get_location_coordinate",
"description": "根据POI名称,获得POI的经纬度坐标",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "POI名称,必须是中文",
},
"city": {
"type": "string",
"description": "POI所在的城市名,必须是中文",
}
},
"required": ["location", "city"],
}
}
},
{
"type": "function",
"function": {
"name": "search_nearby_pois",
"description": "搜索给定坐标附近的poi",
"parameters": {
"type": "object",
"properties": {
"longitude": {
"type": "string",
"description": "中心点的经度",
},
"latitude": {
"type": "string",
"description": "中心点的纬度",
},
"keyword": {
"type": "string",
"description": "目标poi的关键字",
}
},
"required": ["longitude", "latitude", "keyword"],
}
}
}
]
print("=====GPT回复1=====")
response = get_completion(messages, tools_arr=tools_arr)
if (response.content is None):
response.content = ""
print(response)
shell
=====GPT回复1=====
ChatCompletionMessage(
content=''
, role='assistant'
, function_call=None
, tool_calls=[
ChatCompletionMessageToolCall(
id='call_1lhvJzCPQ0YWmM96qRj3Adt8'
,function=Function(
arguments='{"city":"上海市","location":"人民广场"}'
,name='get_location_coordinate'
, parameters={'type': '', 'properties': None, 'required': None})
,type='function')
]
)- 可以看到tool_calls已经识别到通过get_location_coordinate函数获取人民广场的经纬度
- 我们把回复信息加入到messages中,然后执行get_location_coordinate函数,获取相关接口结果
- 然后,get_location_coordinate执行结果给到大模型,大模型识别到下一步应该调用search_nearby_pois
- search_nearby_pois执行结果给到大模型,大模型识别到不需要调用其它函数,用自然语言组织了最终答案。
python
# 将模型的响应加入到消息列表中
messages.append(response)
# 如果返回的是函数调用结果,则打印出来
while (response.tool_calls is not None):
for tool_call in response.tool_calls:
args = json.loads(tool_call.function.arguments)
print("参数:\n", args)
if (tool_call.function.name == "get_location_coordinate"):
print("Call: get_location_coordinate")
result = get_location_coordinate(**args)
elif (tool_call.function.name == "search_nearby_pois"):
print("Call: search_nearby_pois")
result = search_nearby_pois(**args)
print("=====函数返回=====")
print(result)
messages.append({
"tool_call_id": tool_call.id, # 用于标识函数调用的 ID
"role": "tool",
"name": tool_call.function.name,
"content": str(result) # 数值result 必须转成字符串
})
response = get_completion(messages, tools_arr=tools_arr)
if (response.content is None): # 解决 OpenAI 的一个 400 bug
response.content = ""
print("=====GPT回复2=====")
print(response)
messages.append(response) # 把大模型的回复加入到对话中
print("=====最终回复=====")
print(response.content)
shell
参数:
{'city': '上海市', 'location': '人民广场'}
Call: get_location_coordinate
https://restapi.amap.com/v5/place/text?key=xxx&keywords=人民广场®ion=上海市
=====函数返回=====
{
'parent': ''
, 'address': '人民大道185号'
, 'distance': ''
, 'pcode': '310000'
, 'adcode': '310101'
, 'pname': '上海市'
, 'cityname': '上海市'
, 'type': '风景名胜;公园广场;城市广场'
, 'typecode': '110105'
, 'adname': '黄浦区'
, 'citycode': '021'
, 'name': '上海人民广场'
, 'location': '121.475164,31.228816'
, 'id': 'B00157917M'
}
=====GPT回复2=====
ChatCompletionMessage(
content=''
, role='assistant'
, function_call=None
, tool_calls=[
ChatCompletionMessageToolCall(
id='call_gnnfU4h47rk4BYdeH2Qn42ia'
,function=Function(
arguments='{
"keyword":"咖啡店
,"latitude":"31.228816"
,"longitude":"121.475164"
}'
, name='search_nearby_pois'
, parameters={'type': '', 'properties': None, 'required': None})
, type='function')
]
)
参数:
{'keyword': '咖啡店', 'latitude': '31.228816', 'longitude': '121.475164'}
Call: search_nearby_pois
https://restapi.amap.com/v5/place/around?key=xxx&keywords=咖啡店&location=121.475164,31.228816
=====函数返回=====
星巴克(迪美广场店)
人民大道221号B1层236-238号单元
距离:164米
Crave Bakery&Coffee
西藏中路88号(人民广场地铁站1号口步行270米)
距离:285米
咖啡吧(上海数据大厦店)
武胜路333号上海数据大厦F3层
距离:296米
=====GPT回复2=====
ChatCompletionMessage(content='在上海市人民广场附近的咖啡店包括:\n\n1. 星巴克(迪美广场店)\n - 地址:人民大道221号B1层236-238号单元\n - 距离人民广场:164米\n\n2. Crave Bakery&Coffee\n - 地址:西藏中路88号(人民广场地铁站1号口步行270米)\n - 距离人民广场:285米\n\n3. 咖啡吧(上海数据大厦店)\n - 地址:武胜路333号上海数据大厦F3层\n - 距离人民广场:296米\n\n这些咖啡店都在人民广场周围的步行距离内。', role='assistant', function_call=None, tool_calls=None)
=====最终回复=====
在上海市人民广场附近的咖啡店包括:
1. 星巴克(迪美广场店)
- 地址:人民大道221号B1层236-238号单元
- 距离人民广场:164米
2. Crave Bakery&Coffee
- 地址:西藏中路88号(人民广场地铁站1号口步行270米)
- 距离人民广场:285米
3. 咖啡吧(上海数据大厦店)
- 地址:武胜路333号上海数据大厦F3层
- 距离人民广场:296米
这些咖啡店都在人民广场周围的步行距离内。2.3 外部函数查询数据库
- 我们先创建一张mysql表,并插入几条数据:
sql
CREATE TABLE orders (
id INT PRIMARY KEY NOT NULL, -- 主键,不允许为空
customer_id INT NOT NULL, -- 客户ID,不允许为空
product_id VARCHAR(255) NOT NULL, -- 产品ID,不允许为空,假设最大长度为255
price DECIMAL(10,2) NOT NULL, -- 价格,不允许为空
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 创建时间
pay_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- 支付时间
);
INSERT INTO orders (id, customer_id, product_id, price, create_time, pay_time)
VALUES
(1, 101, 'P001', 49.99, '2024-06-16 10:00:00', '2024-06-16 10:30:00'),
(2, 102, 'P002', 29.99, '2024-06-16 11:00:00', '2024-06-16 11:30:00'),
(3, 103, 'P003', 19.99, '2024-06-16 12:00:00', '2024-06-16 12:10:00'),
(4, 104, 'P001', 49.99, '2024-06-16 13:00:00', '2024-06-16 13:30:00'),
(5, 105, 'P002', 29.99, '2024-06-16 14:00:00', '2024-06-16 14:02:00');- 定义获取模型回复的函数
python
from openai import OpenAI
import os
import json
import pymysql
# 从环境变量中获取API密钥和URL
api_key = str(os.getenv('OPENAI_API_KEY'))
api_url = str(os.getenv('OPENAI_URL'))
# 创建OpenAI客户端
client = OpenAI(base_url=api_url, api_key=api_key)
# 定义获取模型回复的函数
def get_completion(messages, model="gpt-4-turbo", tools_arr=None):
response = client.chat.completions.create(
model=model,
messages=messages,
tools=tools_arr
)
return response.choices[0].message- 定义tools_arr,利用json描述外部函数功能
- 定义外部函数,执行sql语句获取结果
python
# 描述数据库表结构
database_schema_string = """
CREATE TABLE orders (
id INT PRIMARY KEY NOT NULL, -- 主键,不允许为空
customer_id INT NOT NULL, -- 客户ID,不允许为空
product_id VARCHAR(255) NOT NULL, -- 产品ID,不允许为空,假设最大长度为255
price DECIMAL(10,2) NOT NULL, -- 价格,不允许为空
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 创建时间
pay_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- 支付时间
);
"""
# 定义工具数组
tools_arr = [
{
# https://github.com/openai/openai-cookbook/blob/main/examples/How_to_call_functions_with_chat_models.ipynb
"type": "function",
"function": {
"name": "query_from_mysql",
"description": "此函数可以回答用户有关业务查询、数据分析的问题。输出应该是完全格式的SQL查询。",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": f"""
SQL查询提取信息以回答用户的问题。
SQL应该使用以下mysql数据库中表的结构编写:
{database_schema_string}
查询应以纯文本形式返回,而不是以JSON形式返回。
查询应该只包含mysql支持的语法。
""",
}
},
"required": ["query"],
}
}
}
]
# 定义提示词
prompt = "2024年6月的销售额"
# 创建消息列表,包含系统和用户的消息
messages = [
{"role": "system", "content": "你是一个数据开发人员,能够写sql分析用户的问题"},
{"role": "user", "content": prompt}
]
# 定义外部函数query_from_mysql
def query_from_mysql(query):
# 数据库连接参数
db_params = {
'host': 'localhost',
'user': 'root',
'password': 'root',
'db': 'test',
'charset': 'utf8mb4'
}
# 创建连接
connection = pymysql.connect(**db_params)
try:
# 创建游标对象
with connection.cursor() as cursor:
# 执行SQL语句
cursor.execute(query)
# 获取查询结果
records = cursor.fetchall()
finally:
# 关闭数据库连接
connection.close()
return records- 最后,我们使用外部函数查询数据库,获取最终的结果
python
print("=====GPT回复1=====")
response = get_completion(messages, tools_arr=tools_arr)
if (response.content is None): # 解决 OpenAI 的一个 400 bug
response.content = ""
print(response)
# 将模型的响应加入到消息列表中
messages.append(response)
if response.tool_calls is not None:
tool_call = response.tool_calls[0]
if tool_call.function.name == "query_from_mysql":
arguments = tool_call.function.arguments
args = json.loads(arguments)
print("====SQL====")
print(args["query"])
# 执行外部函数
result = query_from_mysql(args["query"])
print("====DB Records====")
print(result)
# 讲外部函数的结果放到messages中
messages.append({
"tool_call_id": tool_call.id,
"role": "tool",
"name": "query_from_mysql",
"content": str(result)
})
# 再次调用模型
response = get_completion(messages, tools_arr=tools_arr)
print("====最终回复====")
print(response.content)
shell
=====GPT回复1=====
ChatCompletionMessage(
content=''
, role='assistant'
, function_call=None
, tool_calls=[
ChatCompletionMessageToolCall(id='call_4La31ge1kZSTSiUEl3wqjshW'
,function=Function(arguments='{"query":"SELECT SUM(price) AS total_sales FROM orders WHERE MONTH(create_time) = 6 AND YEAR(create_time) = 2024;"}'
,name='query_from_mysql')
,type='function')
]
)
====SQL====
SELECT SUM(price) AS total_sales FROM orders WHERE MONTH(create_time) = 6 AND YEAR(create_time) = 2024;
====DB Records====
((Decimal('179.95'),),)
====最终回复====
2024年6月的销售额为179.95元。3 Prompt engineering中的6大策略
官网:https://platform.openai.com/docs/guides/prompt-engineering/prompt-engineering
-
OpenAI的文本生成模型(通常被称为大型语言模型)已经接受过自然语言、代码和图像的训练。这些模型根据输入生成文本输出。
-
这些模型的文本输入也被称为
提示(Prompt)。设计提示本质上就是如何"编程"一个大型语言模型,通常通过提供说明或一些示例来实现。 -
这里介绍下OpenAI官网中提到的6大策略,这里描述的方法可以组合使用以获得更好效果。鼓励尝试实验,找到最适合的方法。
-
各类Prompt最佳实践可以参考:各类Prompt最佳实践
3.1 清晰的指令
▶具体操作:
- 在查询中包含细节以获得更相关的答案(Include details in your query to get more relevant answers)
python
"""
简单来说就是把话说的详细些,尽量多的去提供些细节和上下文,否则就是在让模型猜测我们的意图。
比如:不要说:谁是总统?
而是说:谁是 2021 年的墨西哥总统,选举多久举行一次?
"""
from openai import OpenAI
import os
api_key = str(os.getenv('OPENAI_API_KEY'))
api_url = str(os.getenv('OPENAI_URL'))
client = OpenAI(base_url=api_url, api_key=api_key)
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "谁是 2021 年的墨西哥总统,选举多久举行一次?"}
]
)
print(completion.choices[0].message.content)
# 2021年的墨西哥总统是安德烈斯·曼努埃尔·洛佩斯·奥夫拉多尔。墨西哥总统的选举每六年举行一次。- 要求模型采用特定的角色或风格(Ask the model to adopt a persona)
python
"""
我们可以把大模型当成一个演员,自己当导演,给它某个角色剧本进行表演,这样,它就会更专业。
"""
......
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是一个翻译专家,能够将英文翻译为中文。"},
{"role": "user", "content": "The system message can be used to specify the persona used by the model in its replies"}
]
)
print(completion.choices[0].message.content)
# 系统消息可以用于指定模型在回复中使用的角色。- 使用分隔符清楚地指示输入的不同部分(Use delimiters to clearly indicate distinct parts of the input)
python
"""
使用三引号、XML 标记、章节标题等分隔符可以帮助划分要区别对待的文本部分,可以帮助大模型更好的理解文本内容。
"""
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": """
下面用XML标记的内容是新闻内容,请总结下新闻的内容,用json形式返回,仅返回json内容,json的key只有news_title:
<article>
"足球从未高于生死",这是3年前欧洲杯赛场上丹麦球员埃里克森心脏骤停时,各路媒体报道该事件用的最多的表达。
而在经历了那段惊心动魄但又充满人情味的艰难时刻后,32岁的埃里克森时隔1100天再次为国征战欧洲杯,而且奉献了进球。
17日凌晨的欧洲杯小组赛,埃里克森进球的那一刻,感动和欣慰扑面而来。最终丹麦和斯洛文尼亚队1比1战平,各取1分。
丹麦队对垒斯洛文尼亚,这场热度并不算高的小组赛首轮争夺因为一个人的出现得到了外界的关注,他就是埃里克森。
曼联中场在在第17分钟的进球帮助祖国球队取得了领先,他也在经历上届欧洲杯的心脏骤停的遭遇之后,实现了"王者归来"。
尽管这次破门遗憾没能帮助丹麦队最终获得胜利,但绰号"爱神"的埃里克森依然得到了全场乃至全世界球迷的祝福,愿他一切平安。
</article>
"""}
]
)
print(completion.choices[0].message.content)
json
{
"news_title": "埃里克森在欧洲杯上再次出场并进球,感动了球迷"
}- 指定完成任务所需的步骤(Specify the steps required to complete a task)
python
"""
有些任务能拆就拆,最好指定为一系列步骤,然后明确的写出这些步骤可以使模型更容易遵循它们。
"""
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": """
下面用XML标记的内容是新闻内容,请先总结下新闻的内容,然后再把总结后的新闻内容翻译为英文和日文。
用json形式返回,仅返回json内容,json的key仅有news_title,english_news_title,japanese_news_title:
<article>
"足球从未高于生死",这是3年前欧洲杯赛场上丹麦球员埃里克森心脏骤停时,各路媒体报道该事件用的最多的表达。
而在经历了那段惊心动魄但又充满人情味的艰难时刻后,32岁的埃里克森时隔1100天再次为国征战欧洲杯,而且奉献了进球。
17日凌晨的欧洲杯小组赛,埃里克森进球的那一刻,感动和欣慰扑面而来。最终丹麦和斯洛文尼亚队1比1战平,各取1分。
丹麦队对垒斯洛文尼亚,这场热度并不算高的小组赛首轮争夺因为一个人的出现得到了外界的关注,他就是埃里克森。
曼联中场在在第17分钟的进球帮助祖国球队取得了领先,他也在经历上届欧洲杯的心脏骤停的遭遇之后,实现了"王者归来"。
尽管这次破门遗憾没能帮助丹麦队最终获得胜利,但绰号"爱神"的埃里克森依然得到了全场乃至全世界球迷的祝福,愿他一切平安。
</article>
"""}
]
)
print(completion.choices[0].message.content)
json
{
"news_title": "埃里克森在欧洲杯赛场上复出并进球",
"english_news_title": "Eriksen makes a comeback and scores in the European Championship",
"japanese_news_title": "エリクセン、ヨーロッパ選手権で復帰し、得点"
}- 提供示例(Provide examples)
python
"""
先给大模型例子,让大模型按照我给的例子进行输出,这就是所谓的少样本提示。
"""
completion = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": """
按下面内容(用三个反引号分隔)的书写风格为2024年高考的考生写下高考祝福语句,仅输出文字:
```
传承国风,砥砺前行,顶流之选,闪耀时代。
```
"""}
]
)
print(completion.choices[0].message.content)
# 承继智慧,坚毅前进,未来之星,辉映新纪元。2024年高考之际,祝福诸位得胜无数,书写光耀篇章。- 指定输出的期望长度(Specify the desired length of the output)
- 要求模型按照我们指定的长度输出答案。
- 这个长度可以是单词、句子、段落、项目符号等的数量。
- 由于tokenizer的原因,中文的效果不是很准确,通常只是个大概,具体多少个字肯定是不精准的,但多少段这种效果就比较好。
3.2 提供参考文本
语言模型可能会创造虚假答案,尤其是在询问特定主题或要求引用和URL时。提供参考文本可以帮助模型提供更准确的答案。
▶具体操作:
• 指导模型使用参考文本来回答问题。
• 要求模型在回答时引用参考文本中的内容。
python
completion = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": """
使用提供的文章(用三反引号分隔)来分别回答下面几个问题。如果在文章中找不到答案,请写"我找不到答案"。如果找到答案,需要给出引用文章中的具体内容:
例如:
问题:Eriksen的现在效力于哪个联赛?
回答:Eriksen的效力于英格兰足球超级联赛。引用内容为"现效力于英格兰足球超级联赛的曼彻斯特联足球俱乐部"
问题1:Eriksen的出生日期?
问题2:Eriksen的出生国家?
问题3:Eriksen有几个孩子?
```
克里斯蒂安·埃里克森(Christian Eriksen),1992年2月14日出生于丹麦米泽尔法特,丹麦职业足球运动员,司职中场,现效力于英格兰足球超级联赛的曼彻斯特联足球俱乐部。
2010年,埃里克森被提拔进阿贾克斯一线队。在阿贾克斯效力期间,帮助球队夺得3次荷甲冠军、1次荷兰杯冠军以及1次荷兰超级杯冠军。
```
"""}
]
)
print(completion.choices[0].message.content)
shell
问题1:Eriksen的出生日期?
答案:Eriksen的出生日期是1992年2月14日。引用内容为"克里斯蒂安·埃里克森(Christian Eriksen),1992年2月14日出生于丹麦米泽尔法特"
问题2:Eriksen的出生国家?
答案:Eriksen的出生国家是丹麦。引用内容为"克里斯蒂安·埃里克森(Christian Eriksen),1992年2月14日出生于丹麦米泽尔法特"
问题3:Eriksen有几个孩子?
答案:我找不到答案。3.3 将复杂任务分解为简单子任务
一件复杂的任务交给我们来作,出错的概率也很大,模型也不例外。但如果把复杂的任务拆解一个个简单的子任务,那么出错的概率就会骤然降低。
▶具体操作:
- 使用意图分类来识别用户查询的最相关指令。
- 通过分析用户提问的目的,将这些提问分到不同的类别里。
- 这样做可以帮助系统更准确地理解用户想要什么,并给出更合适的回答。
python
"""
比如,假设对于客户服务应用程序,查询可以按如下方式进行有用的分类。
根据客户查询的分类,可以向模型提供一组更具体的指令,以便其处理后续步骤。
"""
from openai import OpenAI
import os
api_key = str(os.getenv('OPENAI_API_KEY'))
api_url = str(os.getenv('OPENAI_URL'))
client = OpenAI(base_url=api_url, api_key=api_key)
prompt = """
下面是客户服务查询的主要类别和次要类别,您将获得客户服务查询。
将每个查询分类为主要类别和次要类别。以json 格式提供输出,其中包含以下键: primary和secondary。
例如:
用户输入:我想升级VIP的等级。
输出:
```json
{
"primary": "计费",
"secondary": "取消订阅或升级",
}
```
主要类别:计费、技术支持、帐户管理或一般查询
计费次要类别:
-取消订阅或升级
-添加付款方式
-收费说明
-对收费提出异议
技术支持次要类别:
-故障排除
-设备兼容性
-软件更新
账户管理次要类别:
-密码重置
-更新个人信息
-关闭账户
-账户安全
一般查询次要类别:
-产品信息
-定价
-反馈
-与人交谈
```
"""
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt},
{"role": "user", "content": "我想重置我的密码"}
]
)
print(completion.choices[0].message.content)
json
{
"primary": "帐户管理",
"secondary": "密码重置"
}-
对于需要长时间对话的应用,总结或过滤之前的对话。
- 模型的上下文长度有限,因此模型只能记住有限的内容。
- 可以用总结或过滤的方法处理以前的对话。这就像是把之前的长篇大论压缩成几句话的要点,或者挑出几个重要的信息点。
- 这样做能帮助保持对话的连贯性,同时避免因为对话太长而超出模型的记忆范围。
-
分段总结长文档,并递归地构建完整摘要。
- 模型具有固定的上下文长度,因此不能用于汇总长度超过上下文长度减去单个查询中生成的摘要长度的文本。
- 比如让模型总结一本书,基本都是超 Token 上限了,所以可以使用一系列查询来总结文档的每个部分
- 这个过程可以递归地进行,直到总结整个文档。
3.4 给模型时间"思考"
模型在立即回答问题时可能会犯更多的推理错误。要求模型在给出答案之前进行"思考链"可以帮助模型更可靠地推理出正确答案。
▶具体操作:
-
指导模型在急于得出结论之前先自行找出解决方案。
- 比如做数学题,我们都知道模型的数学能力很差,一会对一会错的,答案很随机,但是如果你让它先自己做一遍,再去判断对与不对,结果就会准确多了。
-
使用内部独白或一系列查询来隐藏模型的推理过程。
- 这个就像是模型在"心里"默默地思考问题,然后只告诉你最后的答案,而不是把思考的每一步都展示出来。
- 这样做的目的是让交流更简洁,只给你最重要的信息,避免让你看到复杂的思考过程而感到困惑。
- 简单来说,就是模型在给出答案之前先自己"思考",但只跟你分享最终结论。
-
在之前的回答中询问模型是否遗漏了什么。
3.5 使用外部工具
有时候结合使用AI和其他工具(比如数据搜索工具)可以得到更好的结果。利用其他工具的输出来补偿模型的不足。我们已经在外部函数调用时候,体会到了此功能。
例如,文本检索系统可以向模型提供相关文档信息,代码执行引擎可以帮助模型进行数学计算和运行代码。
▶具体操作:
-
使用基于嵌入的搜索来实现高效的知识检索。
-
使用代码执行来进行更准确的计算或调用外部API。
-
让模型访问特定的功能。
3.6 测试和调整
尝试不同的指令和方法,看看哪种效果最好,然后根据结果进行调整。
注:
随着大语言模型(LLMs)能⼒的巨大进步,现阶段它们已经被实际采⽤并集成到许多系统中。这些能力的本质是一个自动化程序将从互联网等不可信来源获取输入和内置的prompt组合,交由GPT等大模型处理。这个过程的安全性,也值得我们关注。
提示词破解:绕过 ChatGPT 的安全审查 (selfboot.cn)
ChatGPT安全风险 | 基于LLMs应用的Prompt注入攻击
4 检索增强生成(RAG)
RAG 是一个增强大模型垂直领域能力和减少幻觉的通用方法论。
具体可以参考:大模型检索增强生成(RAG)最全综述
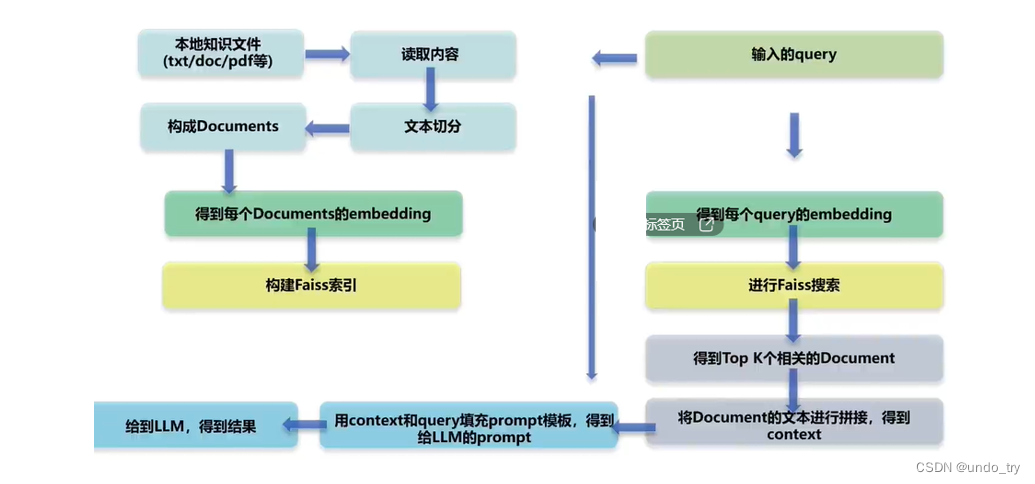
RAG的流程如下所示:
(1)本地知识通过切分、向量化保存到向量数据库中,供后续使用
(2)用户提问时,将用户提问用同样的方式向量化,然后去向量数据库中检索
(3)检索出相似度最高的k个切分段落
(4)将检索结果和用户的提问放到Prompt模板中,组装成一个完整的Prompt
(5)组装好的Prompt给大模型,让大模型生成回答
- 我们这里为了简单,使用了langchain框架,这样处理离线部分就很简单了
- 离线部分,可提前生成好
(1)文档加载与分块
(2)分块数据灌入向量数据库 - 在线部分
(3)解析用户提问,用户提问向量化
(4)查询向量数据库,得到最相似的k个文本块
(5)使用得到的k个文本块和用户提问组装Prompt模板
(6)询问大模型得到最终答案
python
from openai import OpenAI
import bs4
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma # 导入Chroma库,用于文档向量表示
from langchain_openai import OpenAIEmbeddings # 导入OpenAIEmbeddings库,用于词嵌入
import os
api_key = str(os.getenv('OPENAI_API_KEY'))
api_url = str(os.getenv('OPENAI_URL'))
client = OpenAI(base_url=api_url, api_key=api_key)
def store_embedding2chroma():
# 创建一个SoupStrainer对象,用于指定要提取的HTML元素
bs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content"))
# 创建一个WebBaseLoader对象,加载指定的网页路径,并设置解析参数
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs={"parse_only": bs4_strainer},
)
docs = loader.load()
# 创建一个RecursiveCharacterTextSplitter对象,用于文本分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000
, chunk_overlap=200
, add_start_index=True
)
# 将文档分割成较小的片段,并将结果存储在all_splits变量中
all_splits = text_splitter.split_documents(docs)
print(f'len(all_splits) = {len(all_splits)}')
# 使用Chroma将文档转换为向量表示
vectorstore = Chroma.from_documents(
documents=all_splits
, embedding=OpenAIEmbeddings(model="text-embedding-3-small", base_url=api_url, api_key=api_key)
)
return vectorstore
def get_doc_from_retrieved_docs(query):
# 获取retriever
vectorstore = store_embedding2chroma()
# 使用相似性搜索,返回前3个相关文档
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 3})
# 执行检索,返回与查询相关的文档
retrieved_docs = retriever.invoke(query)
result_docs = "\n\n".join(doc.page_content for doc in retrieved_docs)
print(result_docs)
return result_docs
def get_completion(prompt, model="gpt-3.5-turbo-1106"):
messages = [
{"role": "user", "content": prompt}
]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0,
)
print('=========最终回复===========')
return response.choices[0].message.content
if __name__ == '__main__':
# 1、获取用户query相似的相关文档
query = 'What are the approaches to Task Decomposition?'
sim_docs = get_doc_from_retrieved_docs(query=query)
# 2、构造提示词
prompt = f"""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Context: {sim_docs}
Question: {query}
Answer:
"""
# 3、从知识库中回答用户问题
response_content = get_completion(prompt)
print(response_content)
shell
=========最终回复===========
Task decomposition can be done by LLM with simple prompting, task-specific instructions, or human inputs. CoT is a standard prompting technique that transforms big tasks into smaller, manageable steps. The model is instructed to "think step by step" to decompose hard tasks effectively.5 图像、语音相关API
5.1 Image generation的API快速入门
Open AI的图像生成API提供了三种与图像交互的方法:
- 根据文本提示从头开始创建图像(DALL·E 3和DALL·E 2)
- 可以从文本提示中编辑现有图片(仅限DALL·E 2)
- 创建现有图像的变体(仅限DALL·E 2)
官网:https://platform.openai.com/docs/guides/images/image-generation
- 图像生成允许根据文本提示创建图像。使用DALL·E 3时,图像可以具有1024x1024、1024x1792或1792x1024像素的大小。
- 默认情况下,图像以标准质量生成(standard),使用DALL·E 3时,您可以设置质量为
hd以获得增强的细节。不过,方形、标准质量的图像生成速度最快。 - 使用DALL·E 3一次获取1张图像
- 而使用DALL·E 2,可以通过参数n一次请求最多10张图像。
python
from openai import OpenAI
import os
# pip install --upgrade openai
api_key = str(os.getenv('OPENAI_API_KEY'))
api_url = str(os.getenv('OPENAI_URL'))
client = OpenAI(base_url=api_url, api_key=api_key)
# 使用文生图模型dall-e
# 注意:这里不是使用client.chat.completions.create
response = client.images.generate(
model="dall-e-2", # 文生图模型
prompt="a white siamese cat", # 提示词
size="1024x1024", # 图像大小
quality="standard", # 图像质量
n=2, # 一次生成2张图像
)
for element in response.data:
print(element)
shell
# 可以看到revised_prompt中相对自己的提示词添加了更多的细节
# url就是生成图像的地址
Image(
b64_json=None
, revised_prompt="a white Siamese cat with blue almond-shaped eyes, short coat, elegant and sleek body, sitting gracefully with a poised expression. The background is a soft, light color to emphasize the cat's features."
, url='https://filesystem.site/cdn/20240617/oivaww0u08WZaPUTkMweNknkaJqOSp.webp'
)
Image(
b64_json=None
, revised_prompt="a white Siamese cat with blue almond-shaped eyes, short coat, elegant and sleek body, sitting gracefully with a poised expression. The background is a soft, light color to emphasize the cat's features."
, url='https://filesystem.site/cdn/20240617/98MBsE0bJRMr77LT9Ad5LEHrA5zorc.webp'
)
注:
-
模型现在会接受提供的默认提示,并出于安全原因自动重写它,并添加更多细节(通常更详细的提示会产生更高质量的图像)。
-
虽然目前无法禁用这个功能,但可以使用提示功能,通过在提示中添加以下内容来获得更接近请求的图像输出:
I NEED to test how the tool works with extremely simple prompts. DO NOT add any detail, just use it AS-IS:。 -
更新后的提示可在数据响应对象的revised_prompt字段中看到。
-
每个图像可以通过response_format参数返回为URL或Base64数据。
-
URL将在一小时后过期。
python
from openai import OpenAI
import os
# pip install --upgrade openai
api_key = str(os.getenv('OPENAI_API_KEY'))
api_url = str(os.getenv('OPENAI_URL'))
client = OpenAI(base_url=api_url, api_key=api_key)
# 使用文生图模型dall-e 2
# 以图生图
# 目前会报错:当前分组default下对于模型无可用渠道
response = client.images.create_variation(
model="dall-e-2",
image=open("corgi_and_cat_paw.png", "rb"),
n=1,
size="1024x1024"
)
image_url = response.data[0].url
for element in response.data:
print(element)5.2 使用视觉能力来理解图像
-
历史上,语言模型系统受限于只能接收单一输入模态,即文本。
-
而GPT-4o和GPT-4 Turbo都具有视觉能力,这些模型可以接收图像并回答有关它们的问题。
python
"""
图像可以通过两种主要方式提供给模型:
通过传递图像链接或直接在请求中传递base64编码的图像。
图像可以在用户消息中传递
"""
from openai import OpenAI
import os
api_key = str(os.getenv('OPENAI_API_KEY'))
api_url = str(os.getenv('OPENAI_URL'))
client = OpenAI(base_url=api_url, api_key=api_key)
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "图片里面有什么?"},
{
# 这里使用url
"type": "image_url",
"image_url": {
"url": "https://photo.16pic.com/00/78/13/16pic_7813372_b.jpg",
},
},
],
}
],
max_tokens=300,
)
print(response.choices[0])
shell
Choice(
finish_reason='stop'
, index=0
, logprobs=None
, message=ChatCompletionMessage(content='这张图片展示了一朵向日葵。向日葵的花瓣是鲜艳的黄色,花心部位有螺旋状排列的种子。背景是模糊的绿色,可能是拍摄时的自然环境。整个画面给人一种明亮而愉快的感觉。', role='assistant'
, function_call=None
, tool_calls=None
)
)- 如果您在本地拥有一张或一组图像,可以用base64编码格式将其传递给模型
python
import base64
import requests
import os
api_key = str(os.getenv('OPENAI_API_KEY'))
api_url = str(os.getenv('OPENAI_URL'))
# Function to encode the image
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Path to your image
# 我们依然使用https://photo.16pic.com/00/78/13/16pic_7813372_b.jpg
image_path = "sunflower.jpg"
# Getting the base64 string
base64_image = encode_image(image_path)
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "图片里面有什么?"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
"max_tokens": 300
}
# response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload)
response = requests.post(f"{api_url}/chat/completions", headers=headers, json=payload)
print(response.json())
json
{
'id': 'chatcmpl-jv06de13OtIWJlIlqt5rzm3pAbFUp'
, 'model': 'gpt-4o'
, 'object': 'chat.completion'
, 'created': 1718606928
, 'choices': [{'index': 0, 'message': {'role': 'assistant', 'content': '这张图片展示了一朵向日葵的特写镜头。黄色的花瓣和中心部分的种子图案非常清晰,背景则模糊成一片绿色,使花朵在图片中显得格外突出和鲜艳。'}, 'finish_reason': 'stop'}]
, 'usage': {'prompt_tokens': 638, 'completion_tokens': 58, 'total_tokens': 696}
}- 模型能够
接受和处理多个图像输入,两种形式都是base64编码格式或图像URL。 - 模型将处理每个图像,并使用来自所有图像的信息来回答问题。
python
from openai import OpenAI
import os
api_key = str(os.getenv('OPENAI_API_KEY'))
api_url = str(os.getenv('OPENAI_URL'))
client = OpenAI(base_url=api_url, api_key=api_key)
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "这些图片里面有什么?图片之间有什么差别?"},
{
"type": "image_url",
"image_url": {
"url": "https://photo.16pic.com/00/78/13/16pic_7813372_b.jpg",
}
},
{
"type": "image_url",
"image_url": {
"url": "https://photo.16pic.com/00/31/50/16pic_3150659_b.jpg",
}
}
],
}
],
max_tokens=300,
)
print(response.choices[0].message.content)
shell
第一张图片是一朵向日葵的特写。画面主要集中在向日葵的花盘和花瓣上,背景是绿色的模糊图案。
第二张图片是一个现代化装饰的客厅。房间里有一个白色的沙发,沙发上有两个黑白图案的靠垫。沙发后面是黑色带有复杂纹理的墙纸,墙边还有一盆植物。
这两张图片之间的主要区别在于它们的内容和主题。第一张是自然主题,专注于一朵向日葵,而第二张则是室内装饰主题,展示了一间设计独特的客厅。-
通过控制具有三个选项(
low、high、auto)的细节参数,您可以控制模型处理图像并生成其文本理解的方式。默认情况下,模型将使用auto设置,它将查看图像输入大小并决定是否应该使用low或high设置。 -
low将启用"low res"模式。模型将接收图像的低分辨率512px x 512px版本,并使用85个tokens表示图像。这使API能够返回更快的响应,并为不需要高细节的用例消耗更少的输入令牌。 -
high将启用"high res"模式,该模式首先允许模型查看低分辨率图像(使用85个tokens),然后使用170个tokens对每个512px x 512px的区域进行详细的裁剪。
python
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
# 添加控制参数
"detail": "high"
}5.3 文本、语音转换
5.3.1 文本转语音
-
可以通过提供所选语言的输入文本来生成这些语言的口头语音。
-
TTS 模型通常遵循 Whisper 模型的语言支持,具体支持的语言如下:
南非荷兰语、阿拉伯语、亚美尼亚语、阿塞拜疆语、白俄罗斯语、波斯尼亚语、保加利亚语、加泰罗尼亚语、中文、克罗地亚语、捷克语、丹麦语、荷兰语、英语、爱沙尼亚语、芬兰语、法语、加利西亚语、德语、希腊语、希伯来语、印地语、匈牙利语、冰岛语、印度尼西亚语、意大利语、日语、卡纳达语、哈萨克语、韩语、拉脱维亚语、立陶宛语、马其顿语、马来语、马拉地语、毛利语、尼泊尔语、挪威语、波斯语、波兰语、葡萄牙语、罗马尼亚语、俄语、塞尔维亚语、斯洛伐克语、斯洛文尼亚语、西班牙语、斯瓦希里语、瑞典语、他加禄语、泰米尔语、泰语、土耳其语、乌克兰语、乌尔都语、越南语和威尔士语。
python
from openai import OpenAI
import os
api_key = str(os.getenv('OPENAI_API_KEY'))
api_url = str(os.getenv('OPENAI_URL'))
client = OpenAI(base_url=api_url, api_key=api_key)
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input="这两张图片之间的主要区别在于它们的内容和主题。第一张是自然主题,专注于一朵向日葵,而第二张则是室内装饰主题,展示了一间设计独特的客厅。",
)
response.stream_to_file("output.mp3")5.3.2 语音转文本
- 我们将刚才的output.mp3转为文本
- 文件上传目前限制为 25 MB,支持以下输入文件类型:mp3、mp4、mpeg、mpga、m4a、wav 和 webm。
- 可以将音频转录成音频本身的任何语言
python
from openai import OpenAI
import os
api_key = str(os.getenv('OPENAI_API_KEY'))
api_url = str(os.getenv('OPENAI_URL'))
client = OpenAI(base_url=api_url, api_key=api_key)
audio_file= open("output.mp3", "rb")
transcription = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file
)
print(transcription.text)
# 这两张图片之间的主要区别在于它们的内容和主题 第一张是自然主题,专注于一朵向日葵 而第二张则是室内装饰主题,展示了一间设计独特的客厅6 GPT4o
GPT4o使用可以参考官网:Introduction to gpt-4o | OpenAI Cookbook
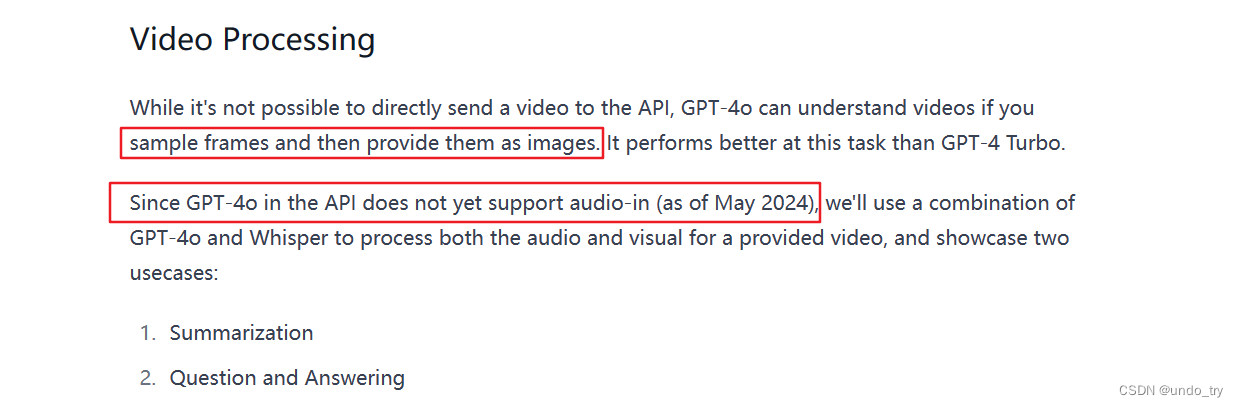
可以看到,对于视频的处理目前还是需要三步走:
- Visual Summary
- Audio Summary
- Visual + Audio Summary