论文名:Deep Residual Learning for Image Recognition
论文作者:Kaiming He et.al.
期刊/会议名:CVPR 2016
发表时间:2015-10
论文地址:https://arxiv.org/pdf/1512.033851.什么是ResNet
ResNet是一种残差网络,咱们可以把它理解为一个子网络,这个子网络经过堆叠可以构成一个很深的网络。下面是ResNet的结构。

2.为什么要引入ResNet
理论上来说,堆叠神经网络的层数应该可以提升模型的精度。但是现实中真的是这样吗?
我们知道,网络越深,咱们能获取的信息越多,而且特征也越丰富。但是根据实验表明,随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了。这是由于网络的加深会造成梯度爆炸和梯度消失的问题。
为了让更深的网络也能训练出好的效果,何凯明大神提出了一个新的网络结构------ResNet。这个网络结构的想法主要源于VLAD(残差的想法来源)和Highway Network(跳跃连接的想法来源)。
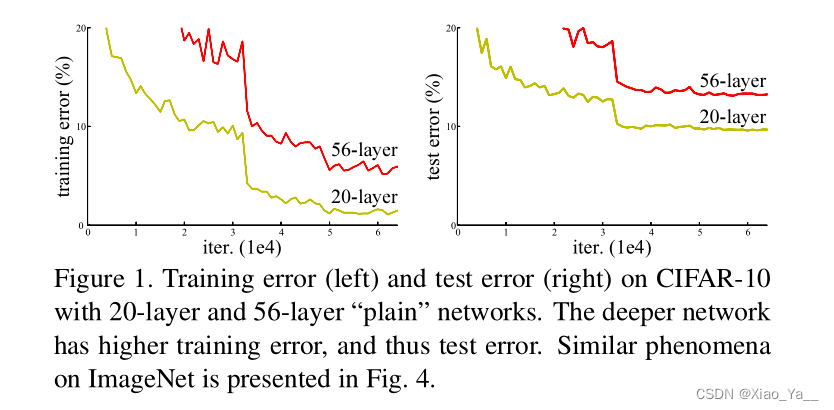
实验数据证明了一开始随着模型层数的增加,模型的精度会达到饱和。如果再增加网络的层数的话,就会开始退化了。从这个实验数据中,我们可以看到在训练轮次相同的情况下,56层的网络误差,居然比20层的网络还要高。这个现象是由于深层网络训练难度太高导致的。我们给这个现象起名叫做退化。这个现象经常被和过拟合搞混淆,但是过拟合其实是会让训练误差变得越来越小,而测试误差变高。退化则是让训练误差和测试误差都变高。

与此同时,深度神经网络还有一个难题:我们以一个最简单的神经网络为例,在反向传播的过程中我们可以推导出每一层的误差项都依赖它后面一层的误差项,在层数很多的情况下,我们很难保证每一层的权值和梯度的大小。举一个最经典的例子,如果我们用sigmoid函数作为我们的激活函数,它的导数的最大值只有0.25,梯度在传播的过程中越来越趋近于零。误差就没有办法传播到底层的参数了,这就是梯度消失。虽然batch normalization和layer normalization,可以缓解梯度消失的问题,但是我们有没有什么办法,既可以解决退化的问题,又能顺便给梯度开个后门。
3.ResNet详读

先来想一想为什么深层神经网络会出现退化的问题呢?假设我们的神经网络在层数为L的时候达到了最优的效果。这个时候我们把这个网络构建的更深,那么第L层之后的每一层理论上来说应该是一个恒等映射,但是拟合一个恒等映射是很难的,所以我们可不可以考虑换一个思路。如果我们用H(x)来表示我们想让这个神经网络学到的映射。用x来表示我们已经学到的内容,那么现在我们可不可以让我们的神经网络去拟合H(x)和x之间的残差呢?也就是说如果我们选择优化的不是H(x),而是把H(x)拆分为x和H(x)-x两个部分,我们选择去优化H(x)-x,我们给这个残差取名叫F(x),F(x)通常包含着卷积和激活之类的操作。我们把F(x)和x相加之后,仍然能得到我们想要的HX,我们把这样从输入额外连一条线到输出来,表示将输入输出相加的操作叫做skip connection。如果让F(x)趋近于零,那么就相当于我们构造了一个恒等映射,那为什么这种方法可以有效解决退化和梯度消失的问题呢?我们假设第L层的输入是xl,那它这一层的输出就是f(xl)+xl,同时它也是第l+1层的输入xl+1。那我们现在可以根据这个规律去推导一下第l+2层的输入,到了这一步我们是不是就不难发现,我们可以得到任意一个更深的层数L和一个更浅的层数l之间的关系的表达式。

首先是任意一层的输入xL可以写成比它更浅的任意层的输入xl和两层之间所有参差的和,我们这样是不是可以初步推测出和普通的神经网络相比,残差网络在前向传播的时候可以让任意低层的信息更容易传播到高层。根据这个式子,我们也可以推导出损失函数。关于xL的梯度,我们从这里可以发现损失函数关于xL的梯度可以直接传播到任意一个更浅的层,后面的这一堆不可能一直等于-1,也就是说残差网络中不会出现梯度消失的问题。作者何凯明的观点是这样的属性。让残差网络无论是正向传播还是反向传播都可以将信号直接传播到任意一层。
注意:如果残差映射(F(x))的结果的维度与跳跃连接(x)的维度不同,那咱们是没有办法对它们两个进行相加操作的,必须对x进行升维操作,让他俩的维度相同时才能计算。
升维的方法有两种:
- 全0填充;
- 采用1*1卷积
4.深度残差学习
在堆叠的几层网络上使用残差连接。整个网络的架构如图:

其中,左边是VGG-19的模型,中间是原始网络,右边是残差网络。残差网络的参数比VGG-19要少。
5.实现
在ImageNet上的测试设置如下: 图片使用欠采样放缩到 256∗480 256\*480,以提供尺寸上的数据增强。对原图作水平翻转,并且使用 224∗224 224\*224的随机采样,同时每一个像素作去均值处理。在每一个卷积层之后,激活函数之前使用BN。使用SGD,mini-batch大小为256。学习率的初始值为0.1,当训练误差不再缩小时降低学习率为原先的1/10继续训练。训练过程进行了600000次迭代。
6.实验部分
Table1中给出了不同层数的ResNet架构。

ImageNet Classification
Plain Networks
分别使用18层的plain nets和34层的plain nets,结果显示34层的网络有更高的验证误差。下图比较了整个过程的训练和测试误差:

注:细实线代表训练误差,粗实线代表验证误差。左侧为plain nets,右侧为ResNet。 这种优化上的困难不是由于梯度消失造成的,因为在网络中已经使用了BN,保证了前向传播的信号有非零的方差。猜想深层的神经网络的收敛几率随着网络层数的加深,以指数的形式下降,导致训练误差很难降低。
Residual Networks
测试18层和34层的ResNet。注意到34层的训练和测试误差都要比18层的小。这说明网络退化的问题得到了部分解决,通过加深网络深度,可以提高正确率。注意到18层的plain net和18层的ResNet可以达到相近的正确率,但是ResNet收敛更快。这说明网络不够深的时候,SGD还是能够找到很好的解。
Identity vs. Projection Shortcuts
比较了三种选择: (A)zero-padding shortcuts用来增加维度(Residual block的维度小于输出维度时,使用0来进行填充),所有的shortcut无参数。 (B)projection shortcuts用来增加维度(维度不一致时使用),其他的shortcut都是恒等映射(identity)类型。 (C)所有的shortcut都是使用projection shortcuts。Table3中给出了实验结果:

结果表明,这三种选择都有助于提高正确率。其中,B比A效果好,原因可能是A中zero-padded的维度没有使用残差学习。C比B效果好,原因可能是projection shortcuts中引入的参数。但是ABC中的结果表明,projection shortcuts对于解决网络的退化问题是没有作用的,对于正确率的提升作用也十分有限。所以,从减少模型参数,降低复杂度的角度考虑,使用Identity shortcuts就已经足够了。
Deeper Bottleneck Architectures.
在探究更深层网络性能的时候,处于训练时间的考虑,我们使用bottleneck design的方式来设计building block。对于每一个残差函数 F F,使用一个三层的stack代替以前的两层。这三层分别使用1x1,3x3,1x1的卷积。其中,1 × 1卷积用来降维然后升维,即利用1 × \times1卷积解决维度不同的问题。3 × 3对应一个瓶颈(更少的输入、输出维度)。Fig.5 展示了这种设计。

50、101和152层的ResNet相对于32层网络有更高的准确率。Table3和4中给出了测试结果。
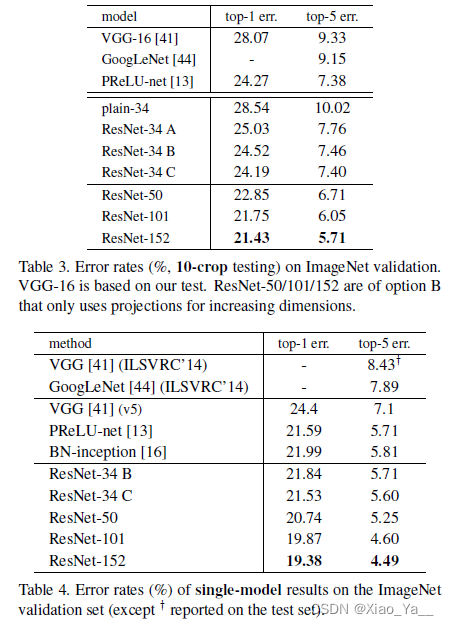
注:使用集成方法的152层网络能达到3.75%的错误率。
CIFAR10 and Analysis
在CIFAR10数据集上的测试表明,ResNet的layer对于输入信号具有更小的响应。

对于更深的网络,比如超过1000层的情况,虽然能够进行训练,但是测试的正确率并不理想。原因可能是过拟合,因为超过1000层的网络对于这个小数据集来说,容量还是过大。
总结
ResNet和Highway Network的思路比较类似,都是将部分原始输入的信息不经过矩阵乘法和非线性变换,直接传输到下一层。这就如同在深层网络中建立了许多条信息高速公路。ResNet通过改变学习目标,即不再学习完整的输出 F(x) ,而是学习残差 H(x)−x ,解决了传统卷积层或全连接层在进行信息传递时存在的丢失、损耗等问题。通过直接将信息从输入绕道传输到输出,一定程度上保护了信息的完整性。同时,由于学习的目标是残差,简化了学习的难度。根据Schmidhuber教授的观点,ResNet类似于一个没有gates的LSTM网络,即旁路输入 x 一直向之后的层传递,而不需要学习。有论文表示,ResNet的效果类似于对不同层数网络进行集成方法。
Inplimentation
这里简单分析一下ResNet152在PyTorch上的实现。 源代码:https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py