文章目录
-
- [2.1、LR回归 & FTRL优化算法](#2.1、LR回归 & FTRL优化算法)
- 2.2、FM:因子分解机,显式二阶交叉
- [2.3、Wide & Deep:兼顾记忆与扩展,隐式交叉](#2.3、Wide & Deep:兼顾记忆与扩展,隐式交叉)
- 2.4、DeepFM:wide&deep基础上融合了二阶显式交叉的FM
- 2.5、DCN+DNN:DNN基础上增加不同阶数的显式交叉
- 2.6、AutoInt:基于transformer的特征交叉
-
本文参考《互联网大厂推荐算法实战》一书,撰写相关总结与笔记。
-
在推荐系统中,模型需要满足如下技术要求:
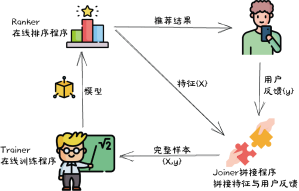
1)模型需要实时、在线学习,在线学习的流程如下:
(1)用户 在APP前端的动作 将触发后台 向排序服务Ranker 发送一条请求,输入将包括当前用户的信息和当前所有候选物料的信息
(2)Ranker从上述输入提取特征 ,喂入排序模型 ,生成排序结果 发往APP展示 给用户
(3)与此同时,提取好的特征 组成特征快照,发送给拼接服务Joiner
(4)用户产生反馈,反馈结果 发送给拼接服务Joiner
(5)Joiner 将新产生的特征和用户反馈拼接起来 ,组成一批新样本发送给训练服务Trainer
(6)Trainer 利用新样本,更新模型 参数
(7)更新后的模型参数推送给Ranker,以服务用户的下次请求
2)模型参数需要尽可能稀疏:
1、推荐算法的5个维度
- 第一维:记忆与扩展
记忆与扩展是推荐系统的两大永恒主题。记忆:是要能记住高频、常见模式;扩展:能够扩展出低频、小众模式
- 第二维:Embedding(扩展)
通过Embedding为稠密的向量,可以增强模型的扩展能力,Embedding是推荐系统中所有深度学习模型的基础
- 第三维:高维稀疏的类别特征
高维稀疏的类别特征是推荐系统中最重要的特征,也是训练难点,例如:
- 为了加速高维稀疏特征的训练,可以采用基于PS的分布式训练架构
- 为解决稀疏特征受训机会不均衡的问题,优化算法可对不同特征采用不同学习率和正则系数
- 第四维:交叉结构(扩展)
在模型中采用交叉结构可以增强表达能力,例如DNN隐式交叉、一阶、二阶、多阶的显示交叉等
- 第五维:用户行为序列建模
基于用户行为序列的兴趣建模时推荐模型的重中之重,例如短视频中,有用户的短播记录、长播记录等,需要对这些短期/长期的行为序列进行建模
2、交叉结构
- 精排算法发展的一条主线就是交叉结构的演进。
2.1、LR回归 & FTRL优化算法
- 最初的精排算法可采用Logistic Regression算法,例如预测是否点击,得到的概率值就是CTR:
C T R p r e d i c t = s i g m o i d ( w T x ) = s i g m o i d ( ∑ i w i x i ) CTR_{predict} = sigmoid(w^Tx) = sigmoid(\sum_{i}w_ix_i ) CTRpredict=sigmoid(wTx)=sigmoid(i∑wixi) - LR算法有如下特点:
1)LR强于记忆,即把每个特征的重要性(权重)都牢牢记住
2)LR弱于扩展,没有Embedding,不存在交叉结构,因此扩展性很弱
- 而在推荐系统中,模型需要满足如下技术要求:
1)模型需要实时、在线学习:LR很容易实现在线学习,因为优化算法SGD天生就是支持增量更新的
2)模型参数需要尽可能稀疏:因为特征高维稀疏,在LR中,如果每个特征都占据一项权重参数,那么将面临巨大的性能压力。因此希望在保证精度的同时,尽可能生成稀疏的解,即某个特征不重要,其权重直接为0,而不是一个非常小的数
但是,业界在预测精度和稀疏解两方面也很难取得平衡。
- 于是,Google引入了FTRL优化算法,可以兼顾预测精度和解的稀疏性(P65-66)
1)FTL:可以避免单个样本的随机扰动,即第t步,不是最小化第t步的损失,而是最小化之前所有步骤的损失之和
2)正则化:防止过于迎合新样本,损失函数中加入当前权重w和每个历史版本权重ws的L2范数,即w和之前权重不能相距过远
3)为每个特征单独设置步长:对于频繁出现的特征,学习率较低;较少出现的特征,学习率更大
2.2、FM:因子分解机,显式二阶交叉
- FM基于LR算法,引入了二阶特征交叉,但会增加训练难度:
1)模型的参数量增加,即模型过于复杂,但数据并未增加,容易过拟合
2)特征高维稀疏,导致很多二阶交叉特征的权重不能得到充分训练
-
于是引入FM算法,对二阶权重进行分解,使得每个特征都学习一个Embedding向量
原始二阶交叉: l o g i t F M = b + ∑ i = 1 n w i x i + ∑ i = 1 n ∑ j = i + 1 n w i j x i x j logit_{FM} = b+\sum_{i=1}^{n}w_ix_i+\sum_{i=1}^{n}\sum_{j=i+1}^{n}w_{ij}x_ix_j logitFM=b+i=1∑nwixi+i=1∑nj=i+1∑nwijxixj
FM算法: l o g i t F M = b + ∑ i = 1 n w i x i + ∑ i = 1 n ∑ j = i + 1 n ( v i ⋅ v j ) x i x j logit_{FM} = b+\sum_{i=1}^{n}w_ix_i+\sum_{i=1}^{n}\sum_{j=i+1}^{n}(v_i\cdot v_j)x_ix_j logitFM=b+i=1∑nwixi+i=1∑nj=i+1∑n(vi⋅vj)xixj
-
通过这种方式,要学习的参数量减少,训练更加充分,同时有效提升了模型的扩展性
简单来说,如果用LR,那么 x i x j x_ix_j xixj的特征组合未曾出现,权重只能为0;而FM可以训练出 v i v j v_iv_j vivj,就能预测出该特征组合的权重,为小众模式提供了发挥作用的机会,因此具备了扩展性。
2.3、Wide & Deep:兼顾记忆与扩展,隐式交叉
- Wide & Deep网络由线性模型Wide和深层网络Deep两部分组成。

- Wide侧是一个LR
- Deep侧是一个DNN,遵从:Embedding+MLP的方式,即是用Embedding的扩展+DNN的隐式交叉,增强了模型的扩展性
- Wide和Deep侧共同训练,Wide侧一般用FTRL优化器,Deep侧采用DNN的优化算法,例如Adam等
2.4、DeepFM:wide&deep基础上融合了二阶显式交叉的FM
- 在Wide侧增加了FM,自动进行二阶特征交叉

2.5、DCN+DNN:DNN基础上增加不同阶数的显式交叉
- Wide&Deep使用一阶LR作为Deep侧的补充
- DeepFM使用FM实现二阶交叉作为Deep侧的补充
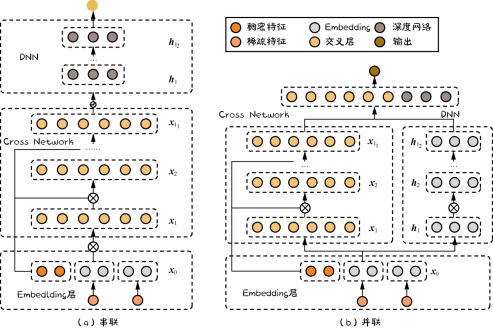
- DCN可以指定任意阶数的显式交叉
- DCNv1中,每个Cross Layer都增加了当前输入与原始输入x0的交叉,包含了原始输入中所有d个元素之间小于或等于L+1阶的交叉
- 前向传播公式如下:
x l + 1 = x 0 x l T w l + b l + x l x_{l+1} = x_0x_l^Tw_l+b_l+x_l xl+1=x0xlTwl+bl+xl - DCNv2 中,认为DCNv1中每层要学习的参数只有 w l , b l w_l, b_l wl,bl两个向量,参数量有限,限制了模型的表达能力,因此DCNv2中使用一个 W l W_l Wl代替了 w l w_l wl:
x l + 1 = x 0 ⊙ ( W l x l + b l ) + x l x_{l+1} = x_0 \odot (W_lx_l+b_l)+x_l xl+1=x0⊙(Wlxl+bl)+xl - 显式交叉的DCN和隐式交叉的DNN有两种融合方式:
串联:原始特征先经过DCN,再输入DNN
并联:同时沿DCN和DNN传递,最终二者相加
2.6、AutoInt:基于transformer的特征交叉
- AutoInt与Transformer结构类似

- AutoInt存在两个缺点:1)要求Embedding长度必须相等,显然不现实并且死板;2)每层transformer只进行交叉不压缩,时间开销大
- 实践中,一般将它作为一个特征交叉模块嵌入更大的推荐模型中,选择一部分重要特征输入AutoInt做交叉
3、用户行为序列建模
- 本节将讨论如何将一个行为序列Embedding为反映用户兴趣的向量
3.1、行为序列信息的构成
- 以"用户最近观看的50个视频"为例,序列中的每个元素的Embedding由以下几部分拼接而成:
1)每个视频ID进行Embedding得到的向量
2)时间差信息:计算观看该视频的时刻距离本次请求时刻的时间差,再桶化为一个整数并进行Embedding,因为存在时间衰减效应,即近期视频影响更大
3)视频的属性信息等
3.2、简单Pooling获取兴趣向量
- 可通过求和、平均、加权Pooling的方式提取用户兴趣,但是这种方式提取的兴趣是固定的
- 对于精排,这算是缺点,因此DIN、双层Attention、SIM都进行了改进,以使能够随当前候选物料的变化而变化
- 但是对于召回、粗排这种用户、物料必须解耦建模的场景,提取用户兴趣的时候也无法拿到候选物料信息,因此简单Pooling是常见的选择。
3.3、DIN:针对每个候选物料对用户序列进行加权
- 从用户行为序列中提取出的兴趣向量应该随当前候选物料的变化而变化,即"千物千面"
- DIN结构如下:

- 公式如下:

3.4、双层Attention:DIN基础上建模序列内的依赖关系
- DIN存在不足:只刻画了候选物料与序列元素的交叉,忽略了行为序列各元素之间的依赖关系,例如一个用户买过Macbook和iPad,这两个的交叉会产生很强的信号,但在DIN中未体现
- 因此,采用双层Attention进行行为序列的建模

- 先采用Self-Attention进行行为序列内部依赖关系的建模
- 再将候选物料和当前Self-Attention产生的新序列上使用DIN,提取用户兴趣向量
3.5、长期序列建模:SIM的在线提取+双塔模型的离线预训练
- 推荐系统是有对长期行为序列建模的需求的,如果建模的序列太短,可能会有临时起意的行为,算是噪声,而且也无法反映用户的周期性行为,例如每周的习惯性采购
- 用户兴趣向量的提取可分为动态在线和静态离线。
3.5.1、SIM在线提取用户兴趣
- SIM(Search-based Interest Model,基于搜索的兴趣模型)结构如下:

- DIN相当于通过加权的方式 对历史行为序列做软过滤,其缺点在于时间复杂度过大,因为与序列长度L呈线性关系
- SIM就是在长序列中筛选出与候选物料t相关的短序列(一般长度在200以下),称为Subuser Behavior Sequence(SBS),即通过搜索的方式进行硬过滤,成为General Search Unit(GSU,通用搜索单元)
- 后续在SBS的基础上使用DIN,这个过程就是Exact Search Unit(ESU,精确搜索单元)
1)硬搜索
- 硬搜索:拿候选物料t的某个属性,在用户完整的长期序列历史中搜索与其具有相同属性的历史物料,组成SBS
- 具体实现中,采用了双层哈希表进行搜索,即User Behavior Tree(UBT),通过两层哈希查找,就能找到当前候选物料的SBS

- 据SIM原论文所述,硬搜索的效果与软搜索差不多,实时性能更优
2)软搜索
- 硬搜索是拿候选物料进行精确匹配,不如用Embedding进行模糊查找的扩展性好
- 因此软搜索:计算候选物料的EMbedding和历史序列的Embedding的相似性,通过近似最近邻(Approximate Nearest Neighbor,ANN)搜索算法,查找与之距离最近的前K个历史物料,组成SBS
- 而Embedding可以通过双塔模型、Item2Vec算法获取Embedding
3.5.2、离线预训练用户兴趣
- SIM这种模型提取用户兴趣,耗时很多,适用于精排这种候选集规模有限的环节
- 那么想在召回、粗排环节引入用户兴趣,可以离线将用户兴趣挖掘好,缓存起来供在线模型调用。
- 一般来说,除了手工统计长期兴趣以外,可以离线预训练出一个辅助模型:
1)预训练一个模型,例如双塔模型,输入长期行为序列,输出一个Embedding代表用户长期兴趣
2)提取用户长期兴趣的Embedding,存入Redis之类的KV数据库
3)在线预测或训练时,检索Redis,获取长期兴趣的Embedding,喂入推荐主模型
- 一种方法是,用同一个用户的长期行为序列预测短期行为序列
