1.论文介绍
PA-SAM: Prompt Adapter SAM for High-Quality Image Segmentation
PA-SAM:用于高质量图像分割的提示适配器SAM
2.摘要
Segment Anything Model,SAM在各种图像分割任务中表现出了优异的性能。尽管SAM接受了超过10亿个mask的训练,但在许多场景中,尤其是在现实世界的背景下,SAM在面具预测质量方面面临着挑战。本文在SAM中引入了一种新颖的提示驱动适配器,即Prompt Adapter Segment Any Model(PA-SAM),旨在提高原有SAM的分割掩码质量。通过专门训练提示适配器,PA-SAM从图像中提取详细信息,并在稀疏和密集提示级别优化掩码解码特征,提高SAM的分割性能,以生成高质量的掩码。
Keywords:
3.Introduction
SAM能够根据提示为任意图像生成多个准确而合理的掩码,展示了分割任务中的实质性影响和潜在的进步。随后的研究已经将SAM的应用扩展到不同的领域。然而,实际应用揭示了SAM在高质量分割性能方面的局限性,其显著特征是网球拍和椅子等对象的掩码边界粗糙,以及对风筝线和昆虫触角等细节的错误预测。为了解决上述问题,HQ-SAM引入了一个高质量的令牌来捕获图像中的更多细节,通过只添加几个参数来极大地提高SAM的分割质量。然而,HQ-SAM中使用的隐式学习方法使得提高SAM的分割能力具有挑战性,因为它主要专注于提取SAM的掩码译码特征来进行分割训练,而该特征是独立于SAM的整体框架的。一些基于提示查询的方法利用图像特征生成固定的稀疏提示,可以有效地获取目标对象的位置,但难以捕获详细的对象信息。此外,集成或扩充方法重复使用原始的输入稀疏提示,在具有挑战性的领域产生有限的收益。因此,开发一种能够直接向SAM提供详细信息并提高掩码译码性能的网络是非常必要的。直觉上,实现这一目的的最直接方法是提供更详细的注释 ,例如附加点或更精确的掩码。受到这种天真直觉的启发,作者想知道该模型是否可以自动提取细节并将其传达给SAM,从而显著提高SAM的分割质量,而不需要额外的用户输入。
作者在本文中引入了Prompt Adapter Segment Anything Model(PA-SAM),这是一个旨在调查图像中不确定区域并将低级别详细信息纳入密集和稀疏提示 中的网络,以增强SAM对细节的学习能力。为了捕捉细节,提出了一种提示驱动的适配器 来执行自适应细节增强和硬点挖掘。与传统适配器不同,提示适配器不优化图像特征,而是优化提示特征以提取关于网络焦点区域的详细信息。将模板求精的过程转化为求精令牌和不确定令牌的学习,使模型对具有挑战性的区域中的图像细节更敏感。此外,还提出了一种基于Gumbel top-k操作的硬点挖掘方法,为模型提供了直接详细的指导。在训练过程中,PA-SAM冻结SAM组件,只训练提示适配器,从而在生成高质量分割图的同时保留了原始SAM强大的目标定位能力。
4.模型结构详解
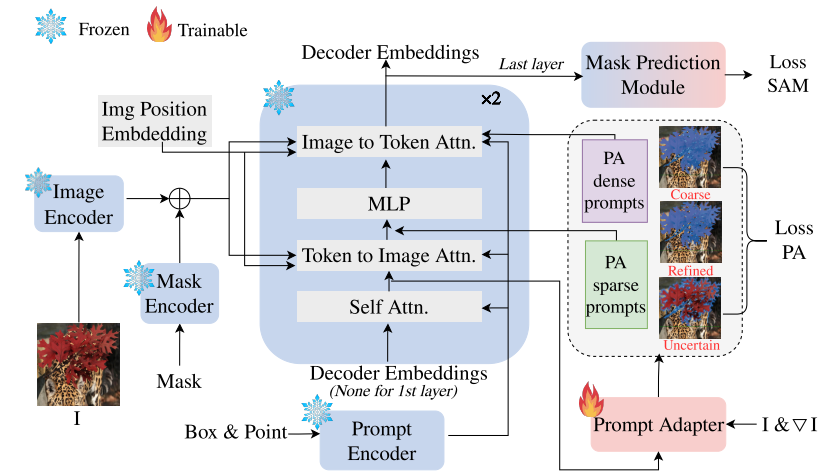
为了捕捉高质量的细节信息,本文将图像细节转换为多粒度的提示特征,并将它们传递给掩码解码器。也就是说,以即时驱动的方式对SAM进行微调。基于这一思想,本文提出了一种可训练的提示驱动适配器,并将其集成到SAM中,形成了提示适配器SAM(PA-SAM)。PA-SAM的总体架构如图所示。PA-SAM将图像特征与密集提示相结合,并将其与稀疏提示一起发送到掩码解码器,在掩码解码器中,所提出的提示适配器根据每个块的自注意将图像特征和稀疏提示分别转换为密集和稀疏适配器提示。随后,将输出的提示特征以残差的方式重新整合到PA-SAM中,以优化掩码解码器的特征表示。
提示适配器(PA) :

为了提高网络在不确定领域学习细节的能力,PA-SAM在SAM的掩码解码器中提出了一种可训练的提示驱动适配器,如图所示。该模块通过自适应细节增强和硬点挖掘将详细信息集成到网络中,以基于原始提示自适应地捕获相关细节信息。
自适应细节增强 :为了捕获高质量的细节信息,Prompt适配器执行自适应细节增强,通过密集提示补偿 和稀疏提示优化 从图像及其梯度中探索细节信息。
密集提示补偿 。在图像编码过程中,由于其16×16的下采样,SAM经历了大量细节信息的损失。为了解决这个问题,本文设计了一个简单的补偿模块,它将原始图像I及其梯度∇I(如坎尼算子)编码misc.generalized_image_grad为引导信息。然后,通过使用一致表示模块(CRM)作为交叉注意或引导门,它可以保持输出特征和图像特征之间的一致性。通常,PA密集提示xpa可以由以下公式来表示:
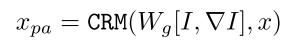
其中,CRM是一致表示模块,并且Wg表示卷积运算。
这里密集提示通过原始图像I和特征梯度∇I补偿。首先cat两者,然后经过卷积,再通过交叉注意力或者引导门控机制(即文中的一致表示模块CRM)对齐密集提示x与卷积后的信息。
稀疏提示优化 。PA-SAM进一步优化了稀疏提示特征,使详细信息能够流向稀疏提示,增强了模型对高质量图像分割的指导性。给定原始稀疏提示TIN,通过令牌到图像的交叉注意将它们转换为详细的稀疏提示Tpa:
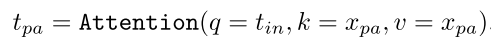
这使得可以在保留原始的弱标记指导的同时优化稀疏提示表示。
稀疏提示优化的主要思路是使用稀疏提示作为查询(query),图像特征作为键(key)和值(value),通过注意力机制(attention)来更新稀疏提示,使其能够更好地指导分割任务。基于token-to-image跨注意力机制,将稀疏提示与图像特征结合。
此外,本文定义了不确定令牌UPA来识别具有挑战性的领域,并精炼令牌RPA来分割它们。这些令牌是在将掩码令牌与其各自的静态令牌连接起来之后通过MLP获得的。然后得到了三种不同的掩码:粗掩码MC、精化掩码MR和不确定掩码MU。用于监督PA-SAM的中间掩码Mpa如下:
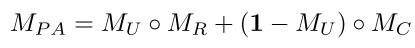
掩码令牌是通过图像编码器和掩码编码器生成的特征表示,包含了图像中的初步分割信息。
静态令牌是一些固定的特征表示,用于辅助掩码令牌的处理。
生成不确定令牌和精炼令牌:通过一个多层感知机(MLP),将掩码令牌和静态令牌结合起来,生成不确定令牌和精炼令牌。
不确定令牌用于标识图像中不确定区域。精炼令牌用于对这些不确定区域进行进一步处理和优化。
困难点挖掘 :在自适应细节增强的基础上,本文进一步提出将纹理细节的直接指导与稀疏提示结合起来。为此,提出了困难点挖掘,它利用稀疏提示优化中提到的MC、MR和MU来构造对挑战点进行采样的指导。以正点抽样为例,首先构造了初始抽样制导ϕ0。在训练阶段,为了确保采样点的多样性,将Gumbel-Softmax操作扩展到Gumbel top-k操作。在采样N个正点的情况下,具体过程如下:
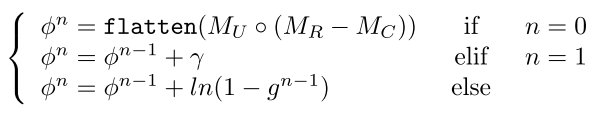
其中γ∼Gumbel(0,1)、n∈N Sample和Gn表示当前样本的Softmax输出,定义如下:
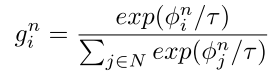
将所有gn相加以获得g'(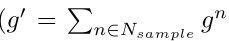 ),其表示前k个softmax。然后,使用直通技巧获得最终的Gumbel top-k输出,如下所示:
),其表示前k个softmax。然后,使用直通技巧获得最终的Gumbel top-k输出,如下所示:
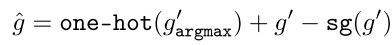
其中sg是停止梯度运算符。
使用ˆg对PA密集提示xpa进行点采样,得到N个采样正点。同样,负点采样也使用Gumbel top-k操作,通过将ϕ0替换为Flatten(MU◦(MC−MR))来指导初始采样。这最终会产生新的点提示pSample。
通过稀疏提示优化和困难点挖掘,将PA稀疏提示TPA更新为:TPA=[ioupa,rpa,ppa,pSample,bpa],其中rpa表示精化的标记,pSample表示新的点提示。
硬点挖掘的核心思想是在训练过程中找到那些难以预测或误差较大的区域,并通过重点学习这些区域来提升模型的整体性能。1.首先通过模型生成不确定掩码(Uncertain Mask)和精炼掩码(Refined Mask),这些掩码帮助模型识别和处理图像中不确定和精细的区域。
2.使用不确定掩码和精炼掩码计算误差图(Error Map),误差图标识了模型在分割任务中预测误差较大的区域。误差图的计算公式如下:error_map=𝑀𝑈⋅∣𝑀𝑅−𝑀𝐶∣ 其中,𝑀𝐶是初步生成的粗略掩码(Coarse Mask)。
3.将误差图展平,以便于后续的采样操作。展平后,误差图变成一维张量,每个元素代表一个像素的误差。
Gumbel Top-k采样:使用Gumbel-Softmax或Gumbel Top-k操作,从展平后的误差图中采样那些误差较大的点(即"困难点")。
4.在后续的训练过程中,对采样到的困难点给予更高的权重或更多的关注,以帮助模型更好地学习和处理这些复杂区域。
说明
代码写得好复杂。。
这篇文章通过image和image-encoder中的特征生成提示,入mask-decoder中。
生成提示的模块叫Prompt adapter。它将图像梯度和图像与密集提示通过交叉注意力对齐,使用token-to-image跨注意力机制将稀疏提示与图像特征结合。还定义了不确定token和精炼token辅助不确定区域生成。在稀疏提示上,还使用了困难点挖掘,计算出误差高的点,对密集提示进行点采样和Gumbel top-k操作生成新的点提示,以更新点提示。
代码太复杂了看得不是特别懂,可以结合代码阅读文章。
在encoder中:
early embedding:vit中在第一个全局注意力块(global attention block)之后提取早期层的特征
guiding embedding:图像梯度与图像cat后卷积
final embedding:image-encoder中输出结果
image record:图像信息 (有mask生成的边界框,所以它是有提示的)
mask decoder:
传入上面的信息和Prompt adapter和prompt encoder。
在decoder中,保留原来的结构,在transformer块的token to image计算中,再计算prompt adapter得到一系列结果。
prompt adapter会更新transformer块的atten、key 和 value。
计算网络输出的掩码与真实标签之间的损失(包括掩码损失和Dice损失),初步损失为掩码损失和Dice损失之和。
计算粗略掩码、精炼掩码和不确定性地图的损失(包括掩码损失和Dice损失),将最终掩码损失和Dice损失加到总损失中。
计算不确定性地图与真实标签之间的损失,将不确定性地图损失加到总损失中。
prompt adapter:
通过对 guiding_embedding 和 keys 进行乘法操作来生成新的指导嵌入;
使用交叉注意力机制将令牌和图像特征结合起来,更新查询张量;
通过连接静态嵌入令牌和查询张量的特定部分,并使用MLP生成不确定性令牌和精炼令牌;
计算不确定性掩码、精炼掩码和粗略掩码,并结合它们生成最终的掩码;
计算点的采样参考图:使用Gumbel-Softmax或Top-k操作来采样正点和负点,生成这些点的位置信息和内容,并更新查询张量和位置编码。