Flask+MySQL+Vue
基于Python+Flask +MySQL +HTML 的B站数据可视化分析系统
-
项目采用前后端分离技术,项目包含完整的前端HTML,以及Flask构成完整的前后端分离系统
-
爬虫文件基于selenium,需要配合登录账号
简介
主页
登录页面,用户打开浏览器并访问系统的登录页面,可以看到主要功能包括:
-
用户登录:通过输入用户名和密码登录系统。
-
创建新用户:提供跳转链接,允许新用户注册账号。
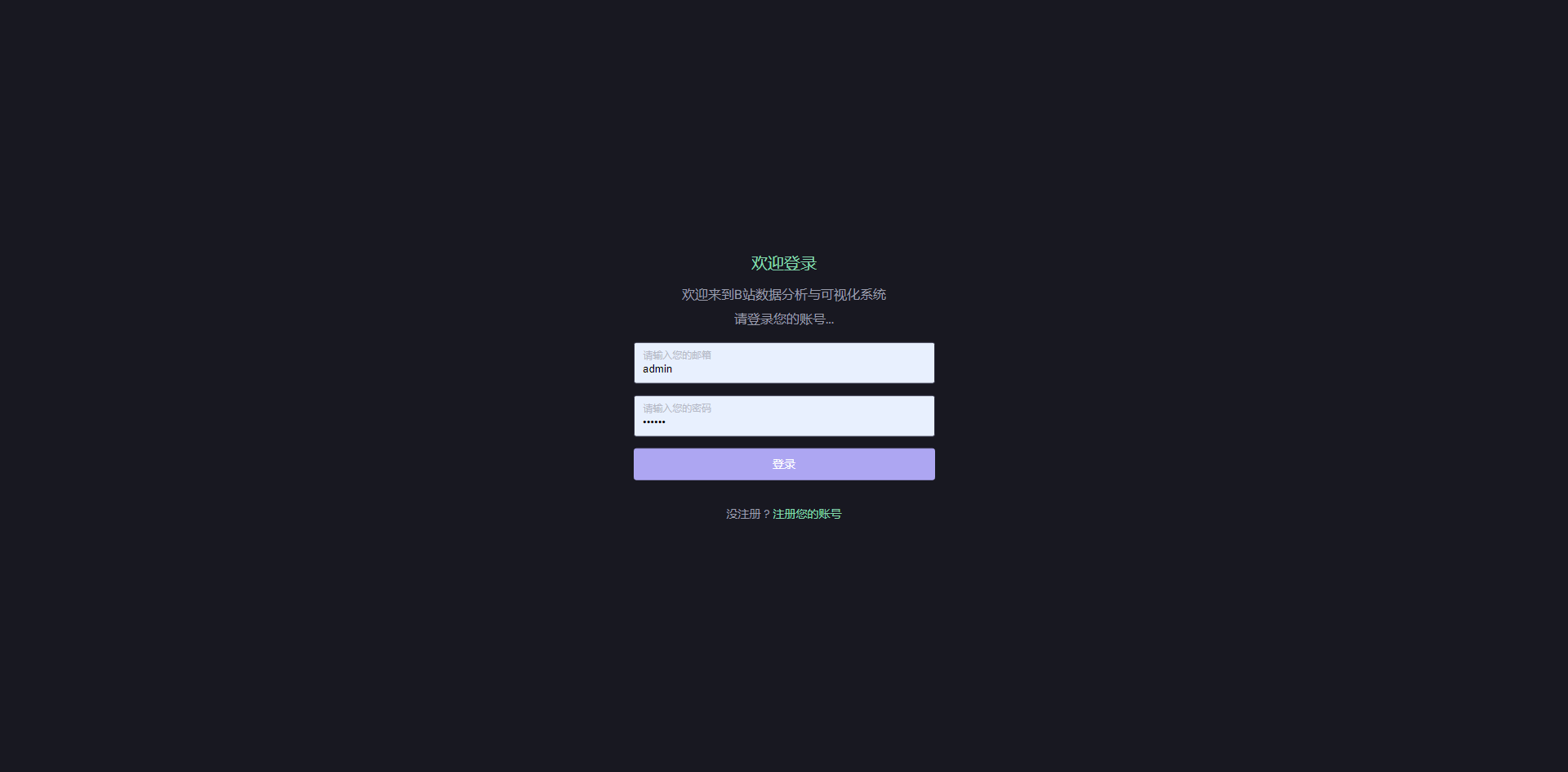
UP主数据查看,查看各个UP主的视频个数以及评论个数的信息,对最多个数的进行排名,查看播放量,作者列表,最火评论
搜索UP信息,显示搜索结果
搜索结果
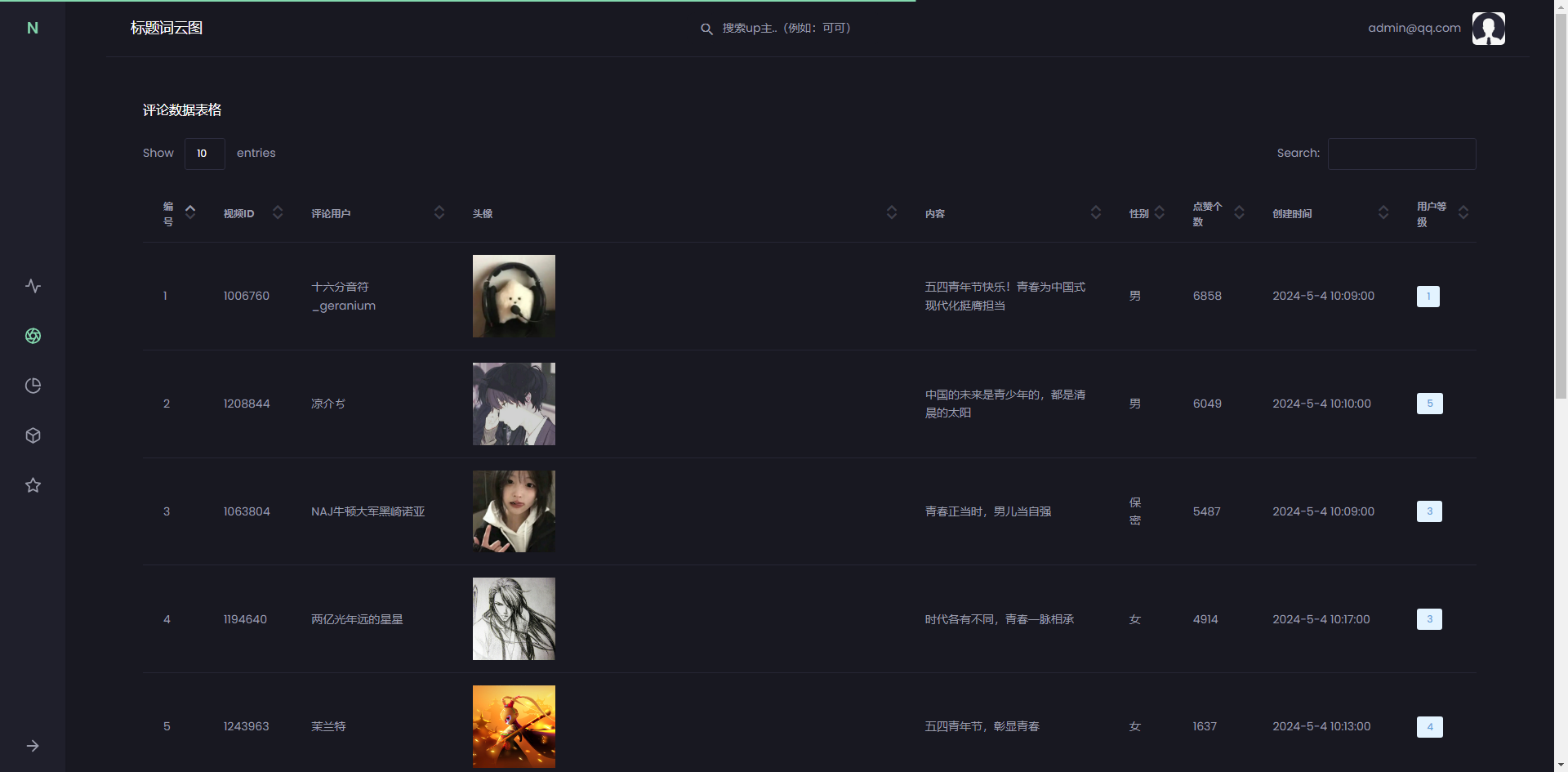
在评论数据表格页面中,可以查看全部数据,包括编号、视频ID、评论用户、头像、内容、性别、点赞个数、创建时间以及用户等级,还可以进行筛选。
B站作者分析
查看UP详情页面,可以查看第一个UP主的简介,视频等信息。

UP主的简介
B站作者分析页面,主要包含以下几个部分:首先是作者粉丝量关系图,它展示了不同粉丝数量的作者分布情况;其次是作者等级占比,这个部分通过饼图或柱状图的形式,展示了不同等级作者在所有作者中所占的比例;最后是作者视频发布柱状图,它用柱状图的形式展示了作者发布视频的数量分布情况。这些图表和数据可以帮助用户更直观地了解B站上作者的整体情况。
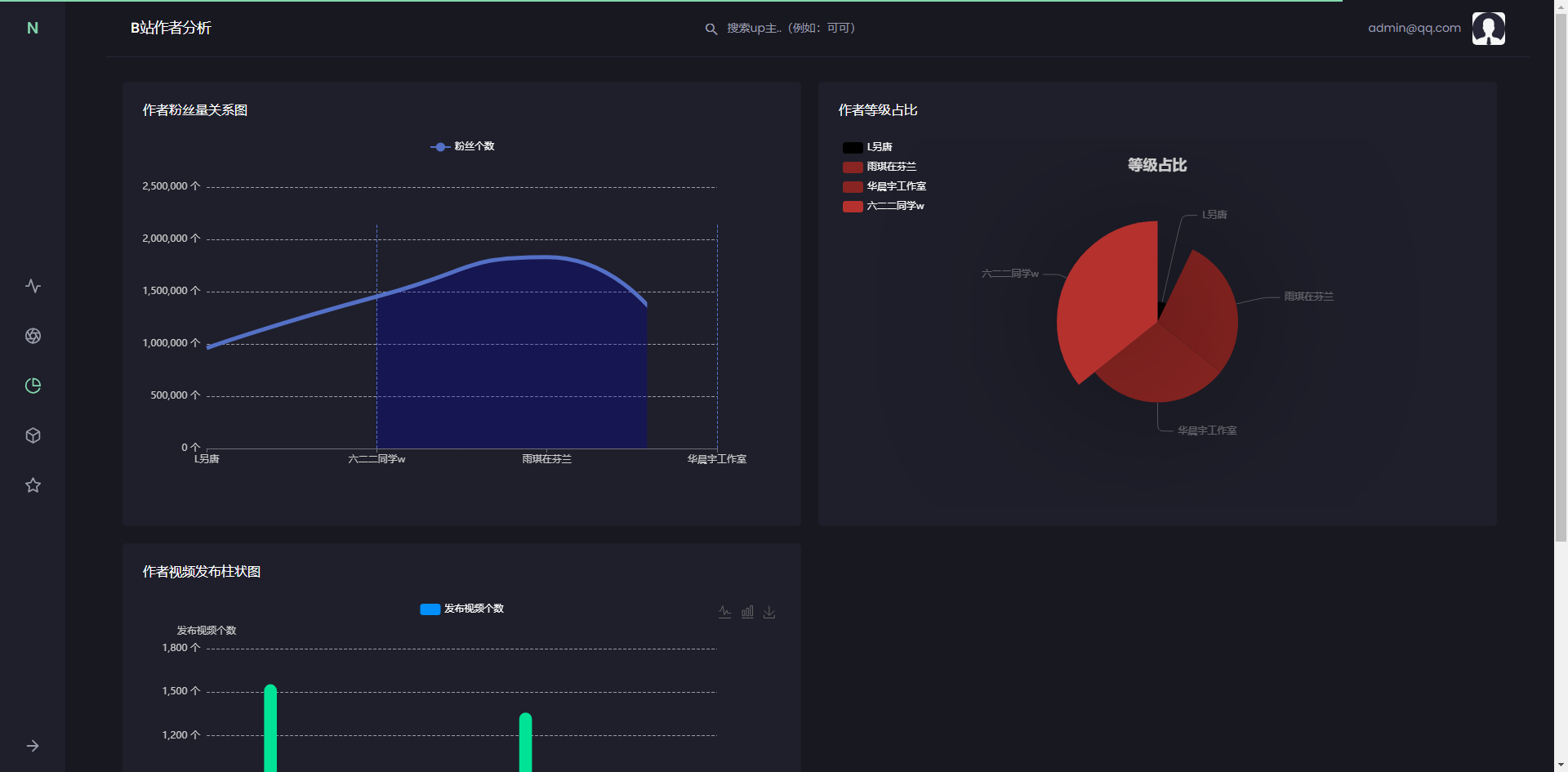
视频评论/弹幕分析页面,用户深入了解观众的互动和反馈。通过这个功能,用户可以查看到用户评论点赞Top表,即最受观众欢迎的评论列表,这些评论通常获得了较高的点赞数。此外,还可以查看用户性别占比,了解不同性别观众在评论中的活跃度和参与度。
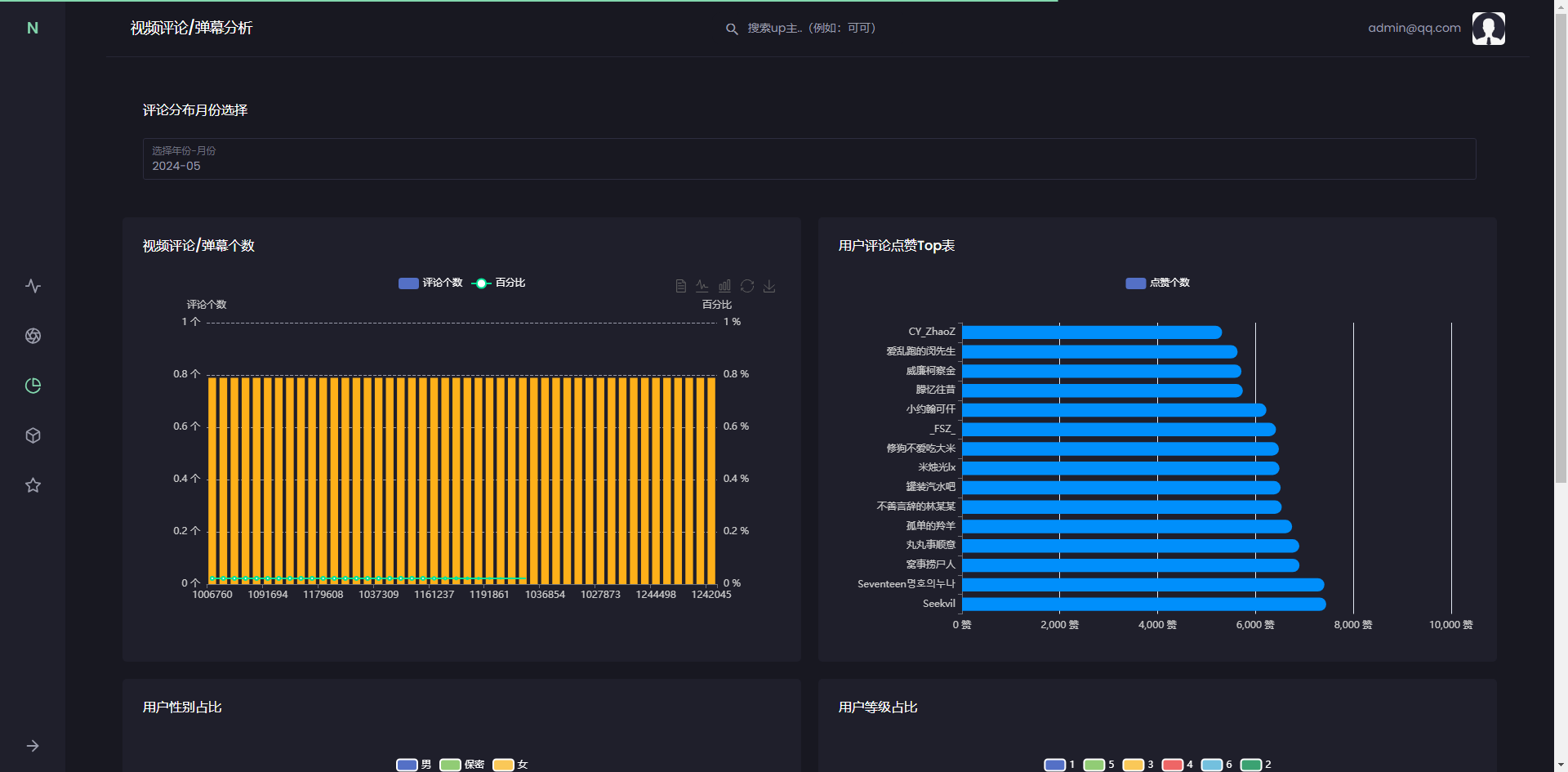
选择不同月份的视频,进行查看,可以直观看到不同长度的视频和观看人数的关系
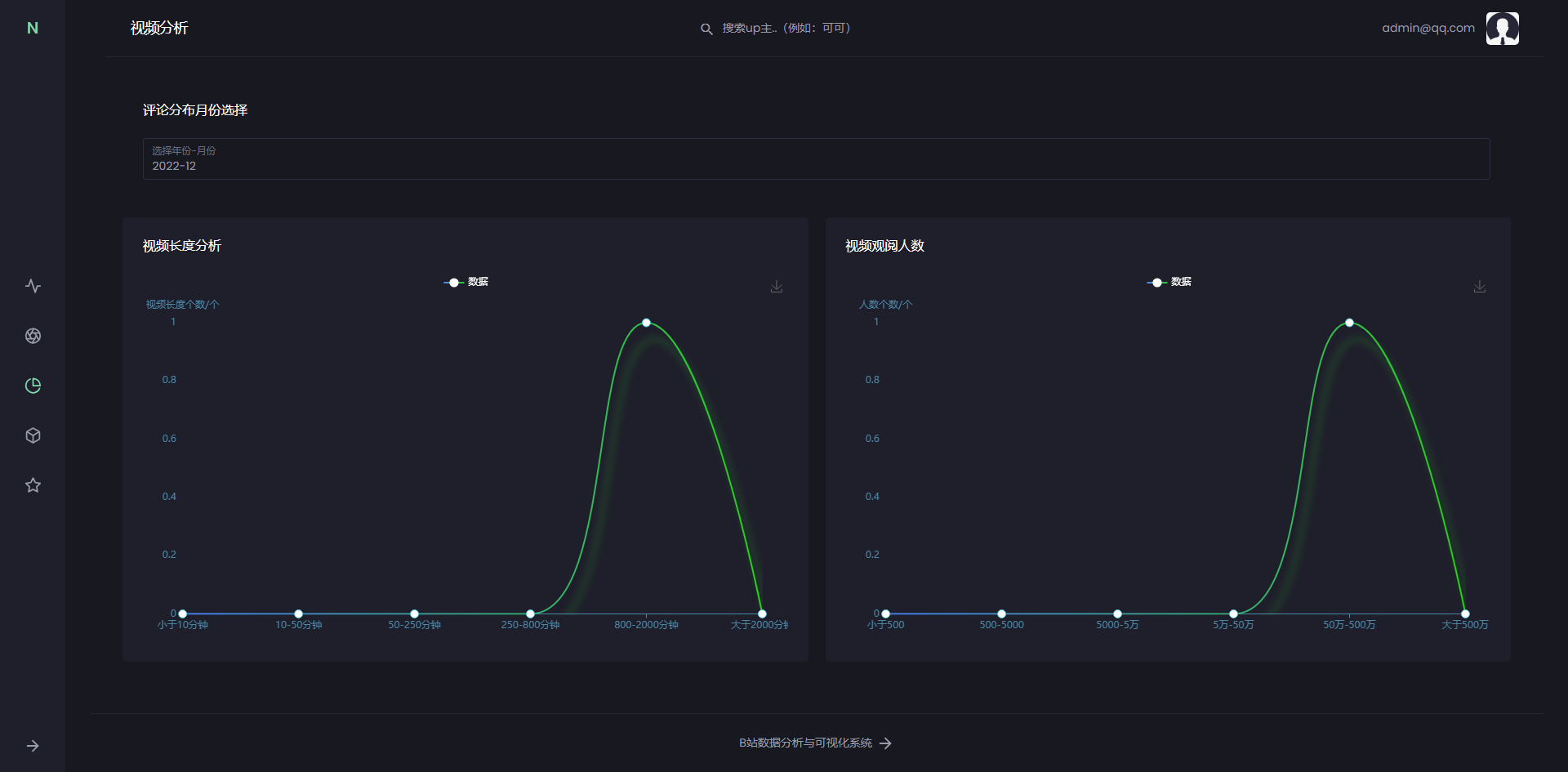
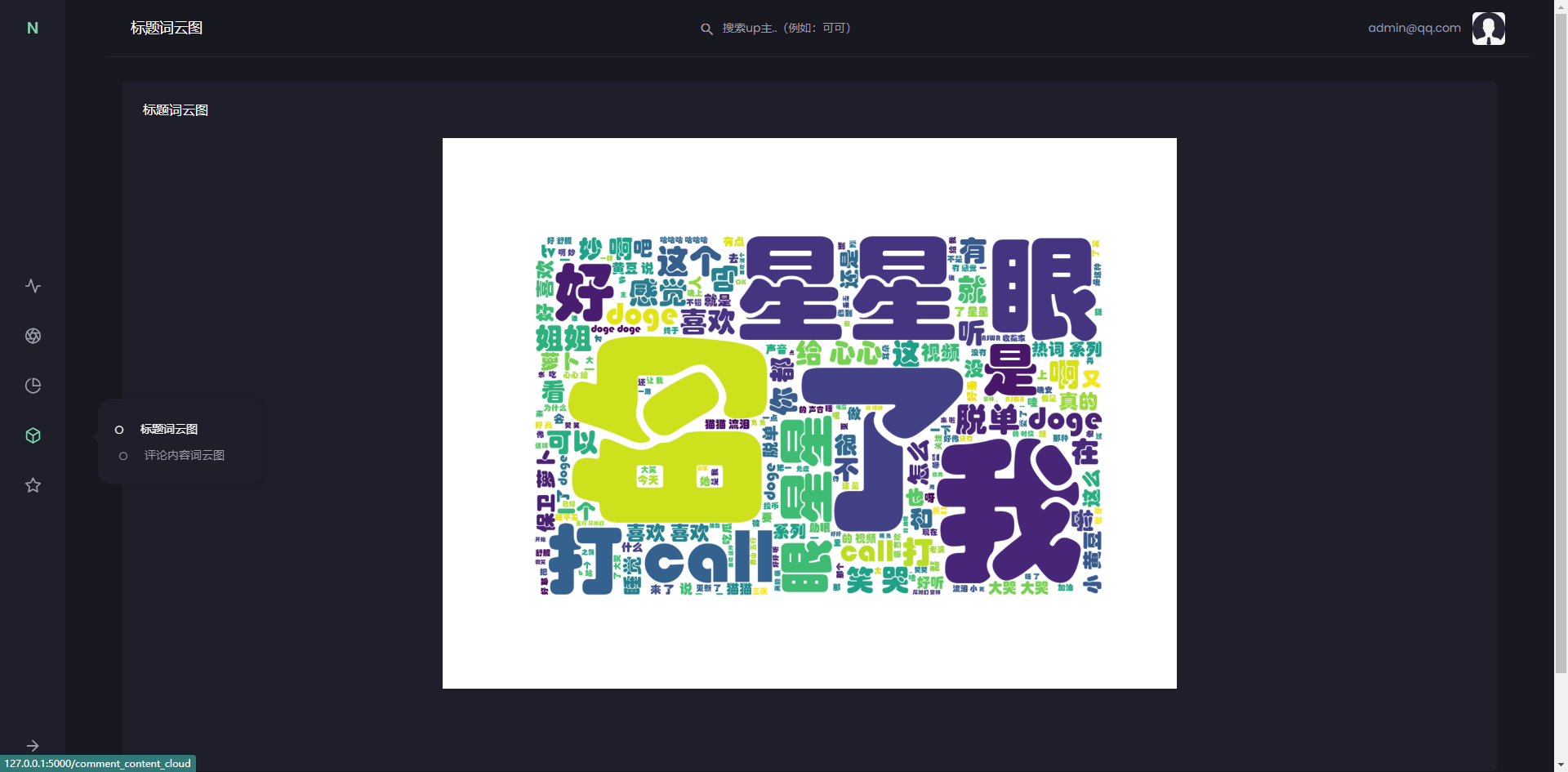
标题词云图
评论内容词云图
安装与使用
本项目在python3.7下通过测试,具体可以查看requirements.txt(或者r.txt)中的环境要求,在这里出一个简单的项目使用教程,一般项目中的requirements.txt中包含了项目的python依赖环境,在安装好python的前提下只需要在cmd窗口中
pip install -r requirements.txt有时候因为路径问题会提示requirements这个文件不存在,可以改为完整的路径,比如c:\requirements.txt,对于本项目只需要运行app.py,然后再浏览器打开地址就好啦。在pycharm的配置更为方便,可以不用每次都在终端输入命令使用。为了加快安装下载速度可以更换为国内源,使用命令为pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
获取方式
有需要的小伙伴可以通过后台联系方式获取,如果加不上可以后台留言留下联系方式,不经常看后台,但是看到了会回复的~,源码获取只收取很少的钱钱,除非是标记了For Free的。