第三个我们比较常用的NOSQL类型的数据库 --- ES
介绍:
ES的全称(Elasticsearch)
- ES是一个分布式全文搜索的引擎
也就是我们平常在购物, 搜索东西的时候常用的, 就是一个ES的类型, 分布式全文搜索引擎
查询原理:
1>分词:
在查询之前, 其会将一些数据拆分开, 按照词进行拆分, 而不是按照单个的字母进行分开, 因为后者是没有意义的.......

2>设置ID:
在拆分了之后, 其会将各个单词, 在我们所有的数据当中, 哪一个数据当中出现过, 记录其所有的ID值

3>加载部分数据:
在对应好了各个的词在那一数据ID当中出现过之后, 它会记录有关这个关键词的部分数据, 注意, 是保留部分数据, 而不是全部的数据, 从而保证我们能够获取到一些有用的数据

概念区分:
倒排索引:
跟我们之前学习的, 使用索引来加快对应的查询的速度不一样的是, 在这里, 我们的ES是将去反过来进行了, 先通过对应的数据, 之后查询对应的ID, 再使用对应的ID获取对应的部分关键语句, 这种反过来查询的方式就叫做是倒排索引
创建文档:
在获取了对应的关键词在数据库当中出现的ID之后, ES就可以根据这些ID来创建对应的文档, 一个文档当中就包含了对应的数据
比方说
Spring --> 1,2,3 --> 1xxx ...
这里的1xx就是一个对应的文档
使用文档:
在创见完了对应的文档之后, 我们就可以将其拿出来进行使用, 就叫做是使用文档
使用, 测试:
在下载完成之后, 我们就可启动了
进入对应的 bin 文件当中:
双击这个文件
等待一会, 在我们的浏览器当中搜索9200的网址
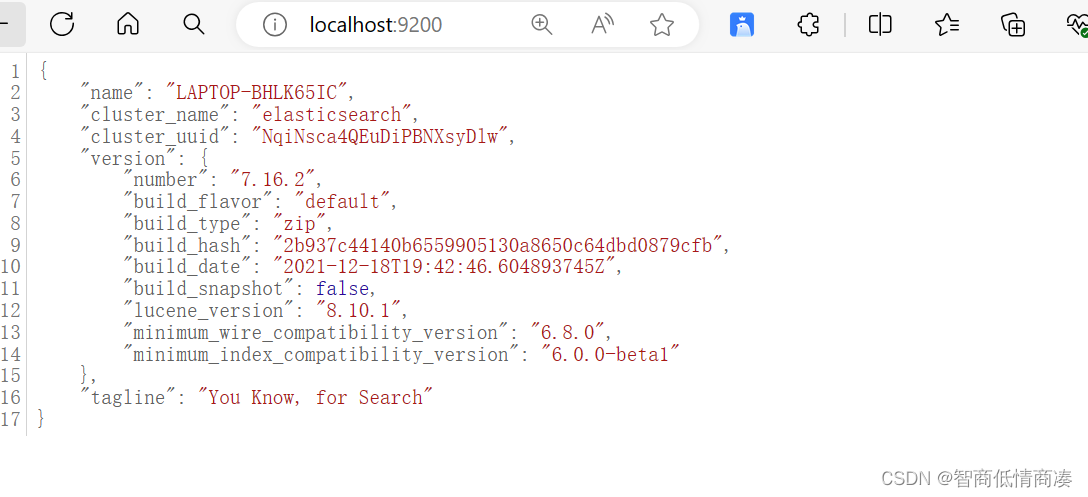
显示这样, 就代表最后成功了
向ES当中添加索引:
实际上 ES跟我们的MYSQL数据库很像, MYSQL需要添加对应的数据库, 之后在向其中设置对应的表等操作
在这里, 对应的创建数据库的操作, 实际上就是相对应的创建索引的操作
但是, 在ES当中, 添加数据库的操作是通过我们向其中发送对应的请求, 来实现的, 发送请求的默认地址就是9800这一个端口号
TIPS:
ES支持REST风格的书写方式
添加索引:(PUT)
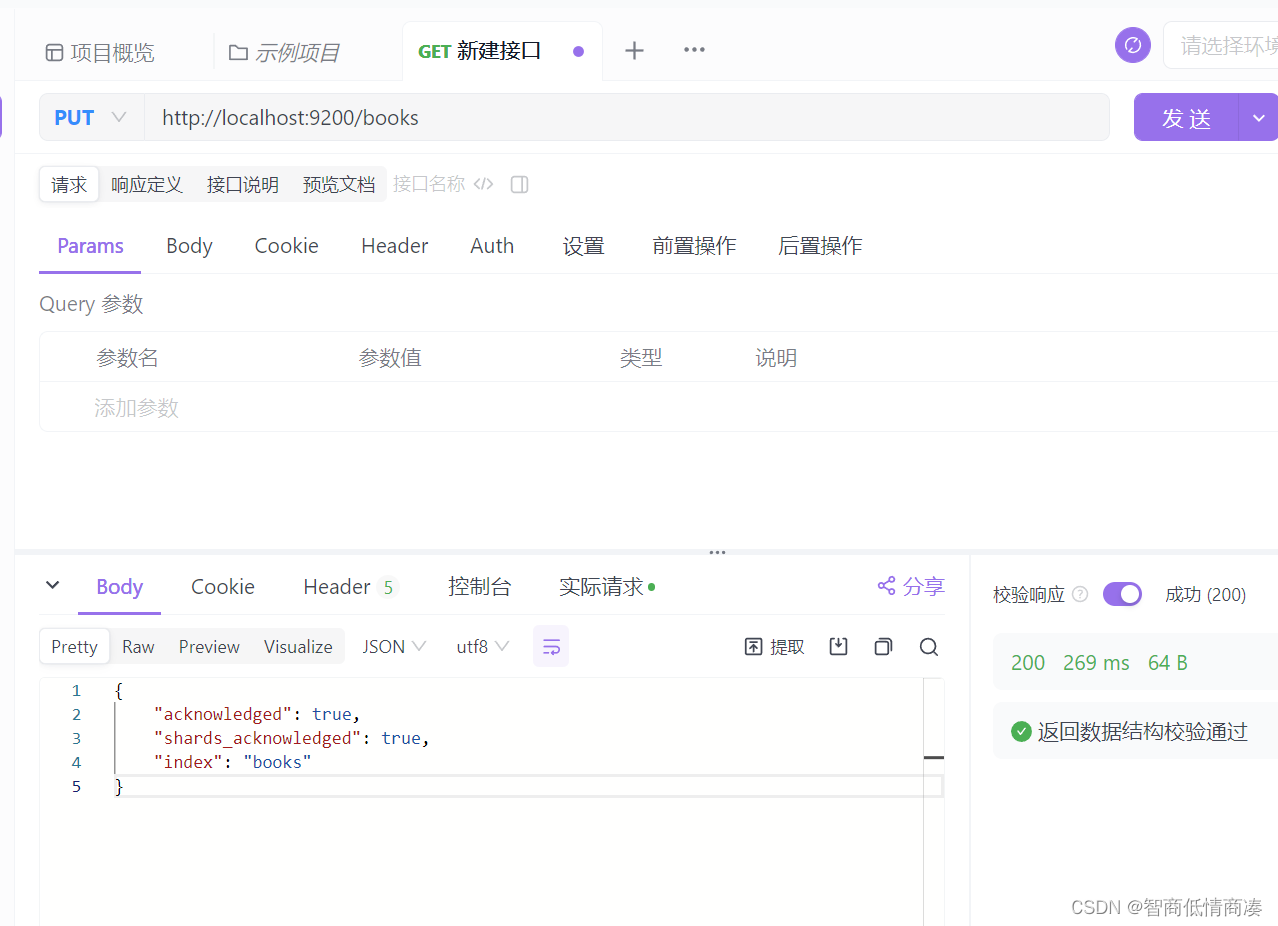
需要注意的一点是, 这里我们添加索引的方式, 是通过对应的PUT的方式, 跟我们平常选择使用 put 进行添加的操作是大不一样的
查看索引:(GET)
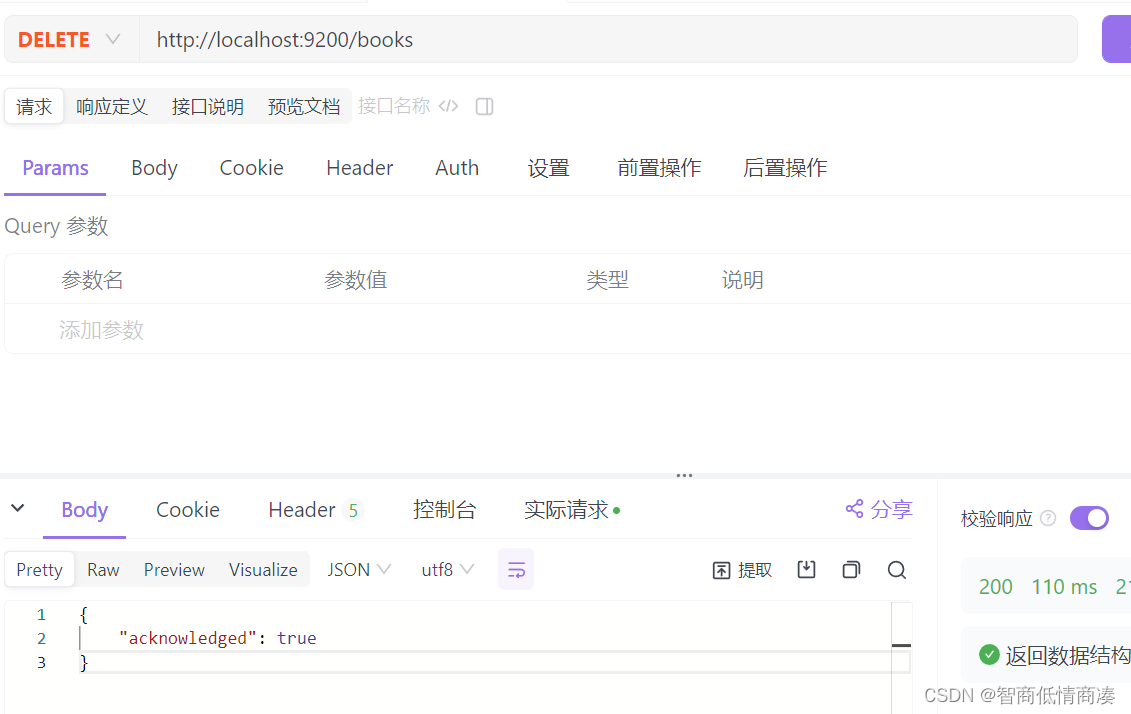
删除索引:(delete)