【验证码识别】Yolov8实战某验3空间推理点选验证码,目标检测,语义分割,颜色分类。
文章目录
声明
本文章中所有内容仅供研究、学习交流使用,不能用作其他任何目的,严禁用于商业用途和非法用途,否则一切后果自负,与作者无关。如有侵权请联系作者删除文章
1.空间推理验证码:
根据提示信息,点击图片中对应的元素,主要是逻辑解题能力 结合3D立体元素识别能力
以下是一些主流的空间推理验证码:

我们可以看到其实大体都差不多,基本方法都可以通用,本文将以某验的空间推理点选验证码为例子介绍如何解决空间推理
2.验证码图片下载
某验图片下载可以刷新5次 每个challenge都请求打满。

sign和图片直接一顿下载。。。。
3.sign文本分析
python
import jieba
def split_prompt():
# jieba分词
prompt_path = "../sign.txt"
prompt_list = []
with open(prompt_path, "r", encoding="utf-8") as f:
for line in f.readlines():
prompt_list.append(line.strip().replace("请_点击_", ""))
# 分词,每一行,统计词频
word_dict = {}
for line in prompt_list:
words = jieba.cut(line)
for word in words:
if word in word_dict.keys():
word_dict[word] += 1
else:
word_dict[word] = 1
# 排序
# word_dict = sorted(word_dict.items(), key=lambda x: x[1], reverse=True)
# 删除无用词
delete_list = ["在", "的", "有", "。", "与"]
for word in delete_list:
del word_dict[word]
# 排序
word_dict = sorted(word_dict.items(), key=lambda x: x[0], reverse=False)
print(word_dict)
if __name__ == '__main__':
split_prompt()
# 球体 : 球,球体
# 正方体 : 方块,正方体,立方体
# 圆锥 : 圆锥体,圆锥
# 圆柱体 : 圆柱体
# 多面体 : 多面体
# 相同形状,相同大小,相同颜色通过分析可以看出有这几种关键词,
球体,正方体,圆锥,圆柱体,多面体 其实物品只有5种
"绿色", "红色", "灰色", "黄色", "蓝色" 颜色有5种

由于物体种类比较少,这里我们使用 目标检测+颜色分类。
然后就是进行打标,这里要注意一点比如这个只露出一半的这个多面体,经过后面的模型效果来看,尽量将他的高拉长一点。
因为我们后期的计算大小的方式不是安装面积来算的,按照他的高度(可能也不太准确)。

4.划分数据集
按照tarin85% test14% valid1%划分的
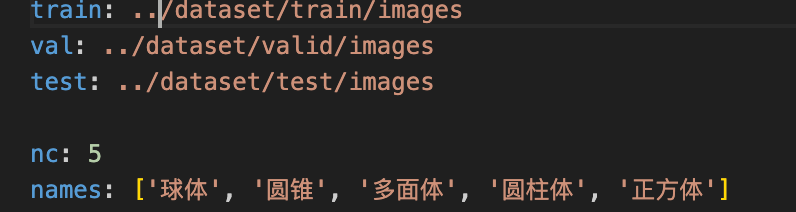
训练结果

5.颜色和大小分类
AlexNet颜色分类 最后导出onnx使用。
python
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from tqdm import tqdm
from model import AlexNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
batch_size = 32
# torchvision自带的图片预处理
# transforms.Resize()将图片调整为指定大小
# transforms.RandomHorizontalFlip()图片随机水平翻转
# ......参考torchvision官网教学
data_transform = {
"train": transforms.Compose([transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])}
# torchvison中的datasets加载训练集
train_dataset = datasets.ImageFolder(root="train/", transform=data_transform["train"])
train_num = len(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# {'blue': 0, 'cyan': 1, 'green': 2, 'purple': 3, 'red': 4, 'white': 5, 'yellow': 6}
flower_list = train_dataset.class_to_idx
# 将字典进行编码,最终生成class_indices.json文件
cla_dict = dict((val, key) for key, val in flower_list.items())
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
# torchvison中的datasets加载验证集
validate_dataset = datasets.ImageFolder(root='val', transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=batch_size, shuffle=False)
print("using {} images for training, {} images for validation.".format(train_num, val_num))
# # 训练集图像可视化,可注释
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.__next__()
# def imshow(img):
# img = img / 2 + 0.5 # unnormalize
# print(img.shape)
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
# print(' '.join('%5s' % cla_dict[test_label[j].item()] for j in range(4)))
# # make_grid的作用是将若干幅图像拼成一幅图像,在需要展示一批数据时很有用
# imshow(utils.make_grid(test_image))
# num_classes=分类个数 init_weights=初始化权重
net = AlexNet(num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss() # 多分类常用的损失函数
optimizer = optim.Adam(net.parameters(), lr=0.0002) # 优化器
epochs = 20
best_acc = 0.0 # 更新准确率最高的数值
best_loss = 1.0 # 更新损失最低的数值
train_steps = len(train_loader)
for epoch in range(epochs):
# 通过net.train()可以保证dropout/BatchNormal只在训练时候起作用
net.train()
running_loss = 0.0 # 统计训练过程中的损失
train_bar = tqdm(train_loader) # 119
for step, data in enumerate(train_bar):
# images: (batchsize,3,224,224)
# labels: batchsize
images, labels = data
optimizer.zero_grad()
# outputs: (batchsize,classes)
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device)) # 计算预测值与真实值
loss.backward() # 损失反向传播
optimizer.step() # 更新参数
# 计算一共多少损失
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1, epochs, loss)
# 验证
net.eval()
acc = 0.0 # 计算精度公式 number / epoch
with torch.no_grad(): # 进制pytorch对参数跟踪
val_bar = tqdm(validate_loader)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' % (epoch + 1, running_loss / train_steps, val_accurate))
val_loss = running_loss / train_steps
if val_loss < best_loss:
best_loss = val_loss
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), './epoch%d_train_loss_%.2fval_accuracy_%.2f.pth'
% (epoch + 1, running_loss / train_steps, val_accurate))
print('Finished Training')
if __name__ == '__main__':
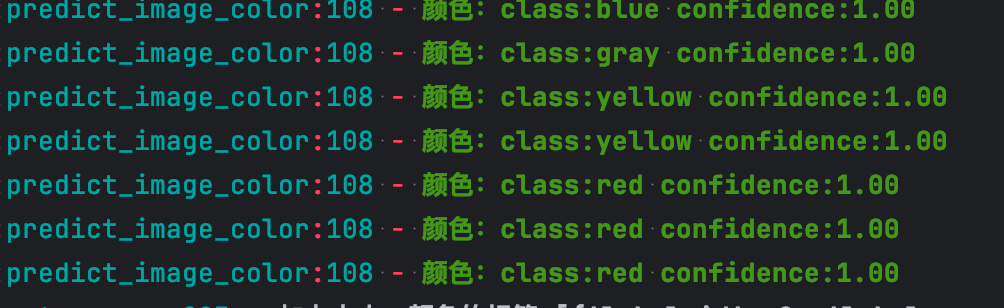
main()这个非常准确,置信度基本都是1
6.语义分割
python
color_keywords = ["绿色", "红色", "灰色", "黄色", "蓝色"]
size_keywords = ["大", "小"]
shape_keywords = ["方块", "正方体", "立方体", "圆锥体", "圆锥", "圆柱体", "球体", "球", "多面体"]
position_keywords = ["右", "左", "前", "后"]
same_keywords = ["相同形状", "相同颜色", "相同大小"]我们主要根据这些关键词进行处理,position_keywords,same_keywords对于这几个条件的关键词来区分参照物和目标物。
然后对于物体添加对于的标签 颜色,根据坐标来区分位置,根据高度来区分大小,相同条件就拿到识别的参照物进行对比,最后得出目标物的坐标。
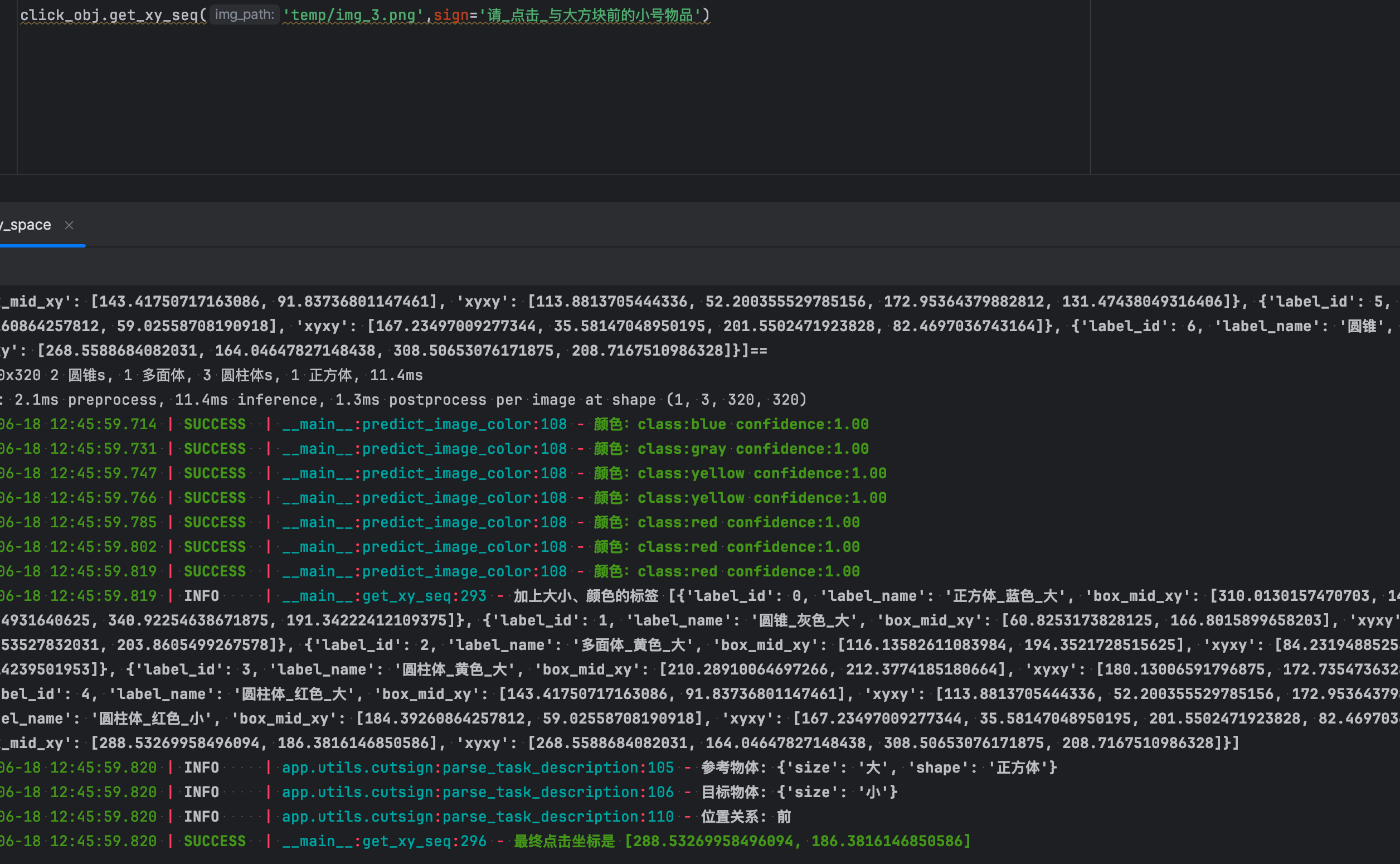
7.识别结果
将两个模型和推理算法结合:
- 1.目标检测,根据识别结果把对应图片切割
- 2.颜色分类,对每个小图进行颜色分类,将结果加入label_name
- 3.大小判断,这里没有使用面积判断大小,有些大物体只露出一半很容易误判,使用使用物体高度判断
- 4.语义推理,拿到坐标,然后输出图像查看结果
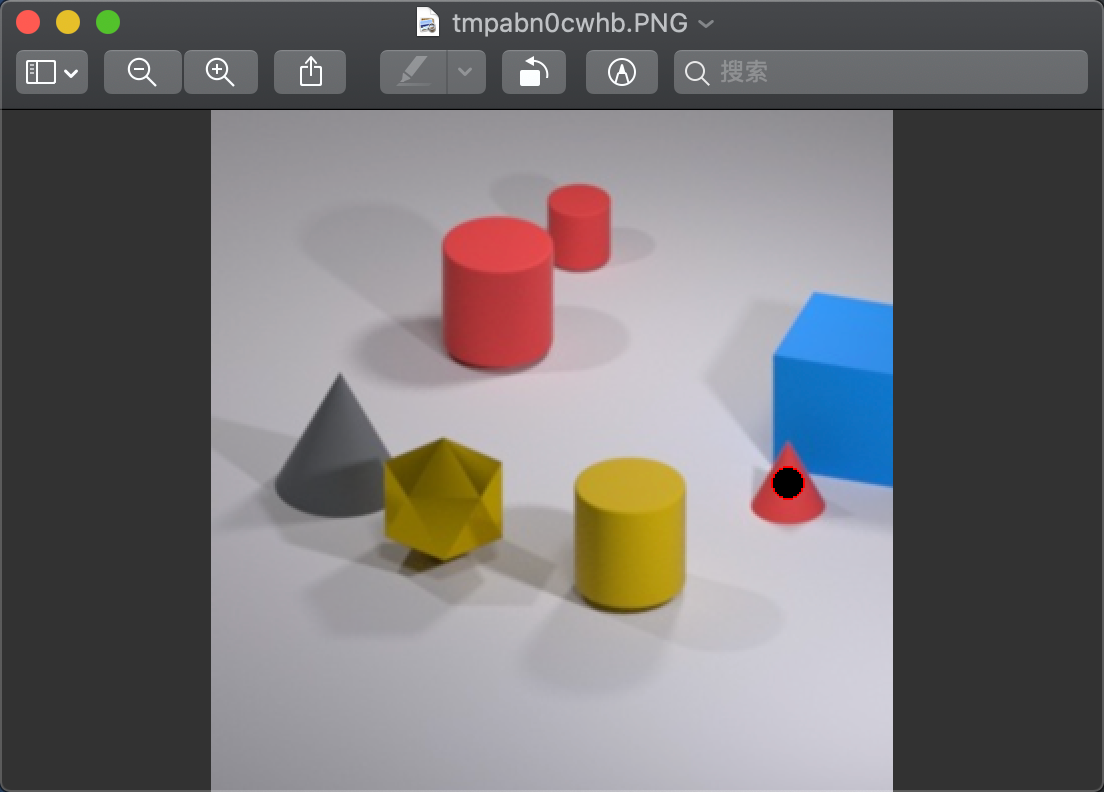
说在后面:
很多朋友来加博主很多时候不是为了交流,只是想要成品,所以为了避免大家的时间,我和朋友合伙开了个星球
后续这些成品都会放到星球,如果有需要的可以直接加入星球(ios的话可以联系博主)
