摘要
本文探讨了扩散模型在时间序列预测中的应用。扩散模型在生成式人工智能的各个领域展示了最先进的成果。本文包括扩散模型的全面背景资料,详细说明了它们的调节方法,并回顾了它们在时间序列预测中的应用。分析涵盖了11个具体的时间序列实现,它们背后的直觉和理论,在不同数据集上的有效性,以及彼此之间的比较。这项工作的主要贡献是对扩散模型在时间序列预测中的应用进行了深入的探索,并按时间顺序对这些模型进行了概述。此外,本文还对该领域的现状进行了深刻的讨论,并概述了潜在的未来研究方向。这为人工智能和时间序列分析的研究人员提供了宝贵的资源,为扩散模型的最新进展和未来潜力提供了清晰的视图。
论文:
The Rise of Diffusion Models in Time-Series Forecasting
作者:代尔夫特理工大学
Caspar Meijer, Lydia Y. Chen生成式人工智能(AI)的出现已经在各个领域产生了变革,从教育2,3,4到工作场所5,6和日常活动7。这种转变的核心是深度学习,这是使人工智能能够分析和综合复杂数据模式的关键支柱。最初,生成人工智能的定义是它能够创建新的、原始的数据样本,这些样本反映了指定数据集的统计特征,数学上表示为:给定分布q(x)中的样本x,生成模型产生的输出x^似乎是从q(x)中提取的8。

在时间序列预测领域,解决方案空间随着时间的推移发生了相当大的变化。最初的进步标志着长短期记忆(LSTM)变体的引入,特别是Seq2Seq自动编码器-LSTM20。然而,随着Transformer结构的引入,2017年发生了重大的范式转变,该结构纳入了注意力机制21。这一创新解决了lstm的关键限制,即在扩展序列上丢失先前的信息22。基于transformer的模型的后续发展23,24,25,26,27,28进一步推动了该领域的发展。在生成建模领域,变分自编码器(VAEs)、归一化流(NFs)和生成对抗网络(GANs)等建模结构的引入取得了重大进展29,30。
然而,扩散模型的出现标志着一个革命性的时期,它有望提供高质量的输出,推动最先进的技术31,32,33。扩散模型的特点是,顾名思义,它们模拟了一个扩散过程,将数据转换为白噪声,然后将其反转回数据,如图1所示。这些模型能够近似原始数据分布,在图像34,31,35,36、文本37,38,39、语音40,41和视频合成42,43,44,45等多个领域都取得了优异的成绩。
时间序列
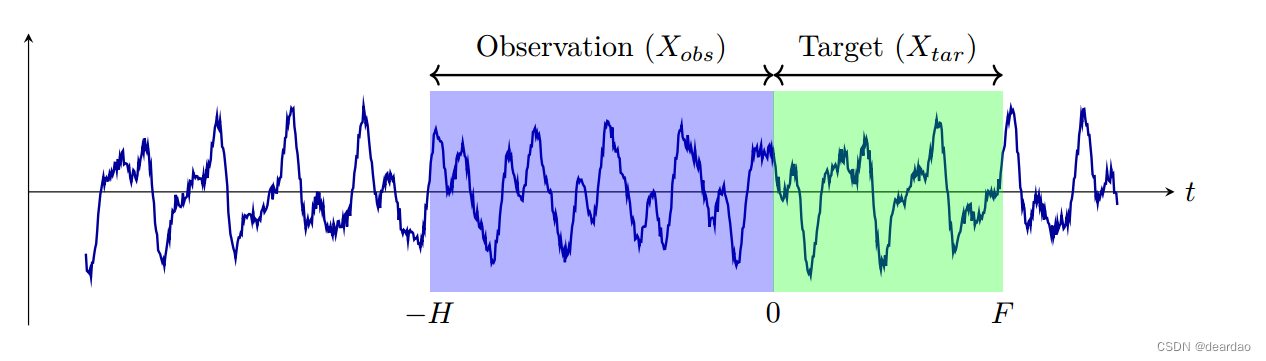
正如Koo和Kim47以及Lin等人46所强调的那样,时间序列建模是条件生成建模的一种特殊形式,其中时间序列的片段用于生成其他片段。这一领域包括三种关键类型:生成、估算和预测。生成是关于创建合成的时间序列数据;代入处理的是填补现有数据的空白,而预测是对未来值的预测。这些类型是相互关联的,预测是一种特定形式的归因,归因和预测都是生成的方面。本节将深入研究时间序列预测和评估度量的问题定义,以评估模型的性能。
扩散模型
扩散模型的基础工作由Ho等人50和Song等人51建立。这些基础是无条件生成数据,这意味着不依赖于特定条件(如文本提示)来创建数据样本。形式上,无条件生成可以被描述为将训练数据x视为一个分布q(x),从中可以提取由x 2 Rd描述的样本。现在的目标是将该分布近似为pθ(x),并能够从这个近似中采样新的未见过的数据8。
扩散模型通过学习数据在扩散到纯噪声后如何恢复来近似分布。该模型试图将高斯分布转换回图4所示的数据分布。这个过程使模型能够从噪声中生成数据样本,将噪声转化为类似于训练数据集的数据。
Ho等人50将扩散和去噪过程描述为离散步骤,Song等人51使用随机微分方程(SDE)将这些过程推广到连续时间。离散实现将在2.1节中描述,连续实现将在2.2节中描述。然而,如果需要特定的数据样本,无条件生成是没有用的。例如,生成包含通过文本提示描述的特定内容的图像35。第2.3节将进一步解释这种有条件的数据生成。


TSDiff
扩散模型在各种领域的生成建模任务中取得了最先进的性能。先前的时间序列扩散模型的研究主要集中在开发适合特定预测或估算任务的条件模型上。在这项工作中,我们探索了任务不可知的、无条件扩散模型在几个时间序列应用中的潜力。我们提出了TSDiff,一个无条件训练的时间序列扩散模型。我们提出的自引导机制能够在推理过程中为下游任务调节TSDiff,而不需要辅助网络或改变训练过程。我们在三个不同的时间序列任务上证明了我们的方法的有效性:预测、改进和合成数据生成。首先,我们证明了TSDiff与几种特定任务的条件预测方法(predict)是竞争的。其次,我们利用TSDiff学习的隐式概率密度来迭代地改进基本预测者的预测,减少了反向扩散的计算开销(改进)。值得注意的是,该模型的生成性能保持不变------使用来自TSDiff的合成样本训练的下游预测者的表现优于使用其他最先进的生成时间序列模型样本训练的预测者,有时甚至优于使用真实数据(合成)训练的模型。
这就提出了一个自然的研究问题:我们能否用一个无条件扩散模型来解决多个(甚至是有条件的)下游任务?具体来说,我们研究了任务不可知的无条件扩散模型用于预测任务的可用性。本文介绍了时间序列的无条件扩散模型TSDiff,并提出了两种利用该模型进行预测的推理方案。基于最近对引导扩散模型的研究10,19,我们提出了一种自引导机制,可以在推理过程中调节模型,而不需要辅助网络。这使得无条件模型适用于本质上有条件的任意预测(和估算)任务3。我们进行了全面的实验,证明我们的自我指导方法在多个数据集和多个预测场景上与特定任务模型竞争,而不需要条件训练。此外,我们提出了一种方法,通过将TSDiff学习的隐式概率密度解释为基于能量的先验,迭代地改进基础预报员的预测,与反向扩散相比,计算开销减少。最后,我们证明了TSDiff的生成能力保持不变。我们在来自TSDiff的合成样本上训练了多个下游预测者,并表明在TSDiff样本上训练的预测者优于那些在变分自编码器9和生成对抗网络57样本上训练的预测者,有时甚至优于在真实样本上训练的模型。为了量化生成性能,我们引入了线性预测分数(LPS),我们将其定义为在合成样本上训练的线性脊回归模型的测试预测性能。TSDiff在几个基准数据集的LPS方面明显优于竞争生成模型。图1突出显示了TSDiff的三个用例:预测、改进和综合。
DIFFUSION-TS
摘要
消噪扩散概率模型(ddpm)正在成为生成模型的主要范式。它最近在音频合成、时间序列输入和预测方面取得了突破。在本文中,我们提出了一种新的基于扩散的框架Diffusion-TS,它通过使用具有解纠缠时间表示的编码器-解码器变压器来生成高质量的多变量时间序列样本,其中分解技术指导Diffusion-TS捕获时间序列的语义,而变压器从噪声模型输入中挖掘详细的顺序信息。与现有的基于扩散的方法不同,我们结合基于傅立叶的损失项,训练模型在每个扩散步骤中直接重构样本而不是重构噪声。扩散- ts被期望生成既满足可解释性又满足真实性的时间序列。此外,研究表明,该方法可以很容易地扩展到条件生成任务,如预测和imputation,而不需要改变模型。这也促使我们进一步探索扩散- ts在不规则设置下的性能。最后,通过定性和定量实验,结果表明扩散- ts在各种现实时间序列分析上取得了最先进的结果。
简介
时间序列在现实世界的问题中无处不在,在金融、医学、生物、零售和气候建模等广泛领域发挥着至关重要的作用(Lim & Zohren, 2021)。然而,在数据共享可能导致隐私泄露的某些情况下,缺乏对这些动态数据的访问是机器学习解决方案开发的关键障碍(Alaa等人,2021)。合成真实的时间序列数据被视为一种很有前途的解决方案,并且在深度学习的推动下受到越来越多的关注。 具有优于gan的感知质量,同时避免了对抗性训练的优化挑战,基于分数的扩散模型(Song et al., 2021;2020),特别是去噪扩散概率模型(ddpm) (Ho et al., 2020),已经占据了图像、视频和文本生成的世界(Ho et al., 2022;Li et al., 2022a;Dhariwal & Nichol, 2021;Harvey et al., 2022)比以往任何时候都受到风暴的影响。
扩散模型有希望推广到时间序列领域,以解决高质量时间序列生成的难题。尽管最近的一些研究率先将扩散模型扩展到时间序列相关的应用中,但几乎所有的扩散模型都是为任务不可知的生成(例如,imputation)而设计的(Tashiro等人,2021;Alcaraz & Strodthoff, 2022)和预测(Li et ., 2022b;Shen & Kwok, 2023b)),用附加信息训练和采样。与此同时,利用扩散模型进行无条件时间相关综合的罕见工作主要集中在单变量综合(Kong et al., 2021;Kollovieh et al., 2023)或短时间序列Lim et al.(2023)。但首先,这些基于扩散的方法(Lim et al., 2023;Das等人,2023)通常使用递归神经网络(rnn)作为主干来联合建模时间动态和复杂相关性。由于误差累积和推理速度慢,这些自回归方法的长期性能受到限制。第二个挑战在于,现实世界时间序列的趋势、季节性和局部特性等独立成分的大量组合通常会在扩散过程中逐渐向数据中添加噪声而被破坏。
CT 生成的作用
CT生成主要用于模拟基站、物联网设备或移动终端的流量生成模式,优化其通信资源,提高服务质量。具体来说,为了校准底层层次模型,在29中提出了LiTGen。这个开环流量生成器以每个用户和应用程序为基础对无线流量进行统计建模。已经证明,LiTGen在大范围的时间尺度上再现了捕获的流量的爆炸性和内部属性。为了估计传感器网络的网络寿命,30中的作者提出了一种不规则表面的流量生成模型,该模型集成了Elfes感知模型和事件生成模型。为了评估额外的模拟流量对移动无线网络性能的潜在影响,作者在31中展示了在塞尔维亚电信移动网络上使用TCP协议的多人实时游戏和M2M应用的流量建模和仿真结果。
我们首先关注web,邮件和P2P流量,并使用我们的生成器的简单版本生成三个独立的合成轨迹。使用这种所谓的基本LiTGen,所有流量实体都是使用从捕获的跟踪中提取的经验分布从更新过程中生成的。在随机变量之间没有引入其他附加依赖项。然后将三个合成路径合并为一个,并与由相同三个应用程序组成的过滤捕获流量进行比较。图2(a)显示了得到的LDE光谱。显然,基本LiTGen生成的合成轨迹(细曲线)与捕获的流量频谱(粗灰色曲线)不匹配。这个简单版本的LiTGen底层模型并不能很好地复制捕获的流量缩放结构。