环境按照尚硅谷的配置的。
在运行hive的时候,报错代码为30041,无法执行insert语句。
在运行spark-shell的时候,报错,无法进入到shell脚本中。
可能的问题:
对集群设置的域名与集群的主机名称不一致。
例如:
我的集群的域名为hadoopxx,但是我的集群的主机名均为ubuntu,导致集群中Node Address均为ubuntu:8042。
解决方案:
将集群的主机名称修改为与集群的域名相匹配的名称。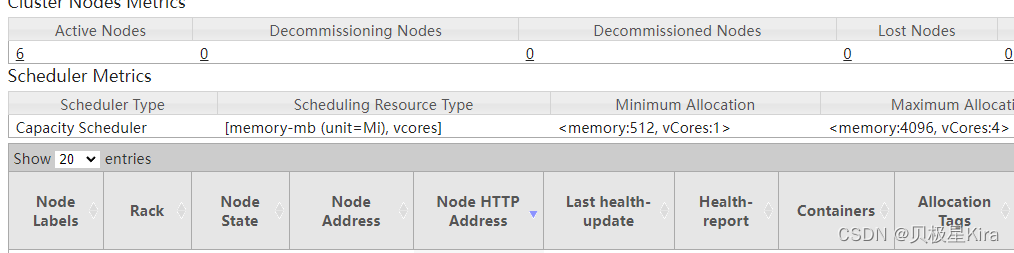
此图片需要在ResourceManager的IP的8088端口才能看见。