1.理解文件系统
1.1.ls与stat
磁盘文件由两部分构成,分别是文件内容和文件属性。
文件内容就是文件当中存储的数据,文件属性就是文件的一些基本信息,
例如文件名、文件大小以及文件创建时间等信息都是文件属性,文件属性又被称为元信息
ls -l,可显示当前目录下各文件的属性信息。
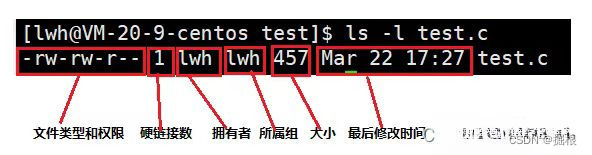
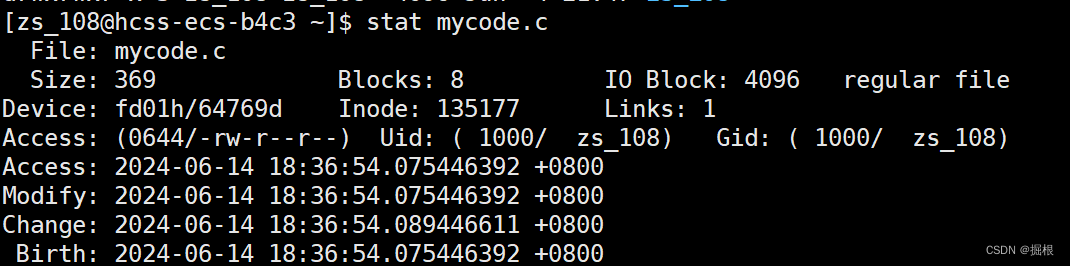
也可以使用stat查看更多属性。
1.1.初识inode
在Linux操作系统中,文件的元信息和内容是分离存储的,其中保存元信息的结构称之为inode,因为系统当中可能存在大量的文件,所以我们需要给每个文件的属性集起一个唯一的编号,即inode号。
也就是说,inode是一个文件的属性集合,Linux中几乎每个文件都有一个inode,为了区分系统当中大量的inode,我们为每个inode设置了inode编号。
我们可以通过下面这个指令来查看inode编号
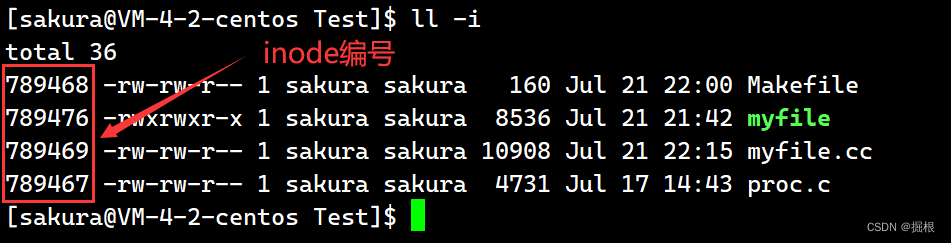
注意: 无论是文件内容还是文件属性,它们都是存储在磁盘当中的。
磁盘文件是如何进行管理的?
- 磁盘文件的管理类似于菜鸟驿站,其中的包裹就像待访问的文件,而
inode就是取件码 - 得益于这种规范化的存储模式,我们可以做到对文件的快速定位、快速读取和快速写入

以上的 "管理" 只是抽象概念,具体动作还得对磁盘结构学习后,才能更好的理解
2. 文件系统特性
2.1、磁盘概念
现在市面上的磁盘主要分为 机械硬盘 和 固态硬盘,
- 前者读取速度慢,但便宜、稳定
- 后者读取速度快,但价格高昂且数据易损
两者各有其应用场景,本文主要介绍的是 机械硬盘


2.1.1、基本结构
机械硬盘是我们电脑中的唯一一个机械设备,并且它还是一个外设 ,根据 冯诺依曼体系结构 ,机械硬盘 在速度上远远慢于 CPU 和 内存
举例机械硬盘有多慢
- 假设
CPU运行速度是纳秒级,那么内存就是微秒级,而机械硬盘只不是是毫秒级
为何 机械硬盘 如此慢?这与它的结构有很大关系
机械硬盘 的结构主要包括以下几种:
- 盘片:一片两面,每一面都可以存储数据,有一摞盘片
- 磁头:一面配备一个磁头,专门用于读取盘面中的数据
- 主轴:用于控制整块盘的转动
- 音圈马达:控制磁头的进退
- 磁头臂:链接磁头与音圈马达
- 伺服电路板:控制读取数据的流向及各种结构的运行
- ......
注意: 多个盘片、多个磁头都是共进退的
机械设备 控制是需要时间的,因此导致 机械硬盘 读写数据速度相对于 CPU 和 内存 来说比较慢

真实的盘片

2.1.2、数据存储
我请大家先看个视频,来了解一下机械硬盘的结构和工作原理
机械硬盘的工作原理
总所周知,数据是以 0 和 1 的方式进行存储的,常见的存储介质有:强信号与弱信号 、高电平与低电平 、波峰与波谷 、南极与北极 等,而盘面上比较适合的是 南极与北极
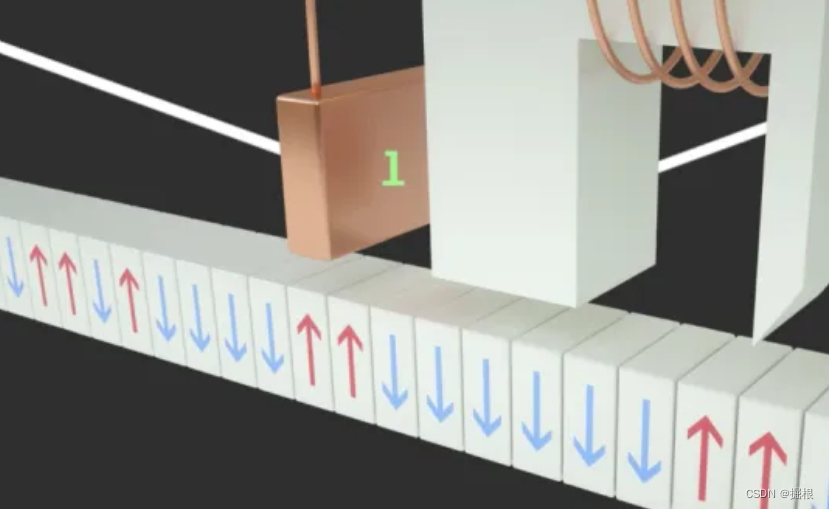
当磁头移动到指定位置时
- 向磁盘写入数据:
N->S - 删除磁盘中的数据:
S->N
磁盘中读写的本质:更改基本元素的南北极、读取南北极
注意: 磁头并非与盘面进行直接接触,而是以 15 纳米的超低距离进行磁场更改
这个距离相当于一架波音747距离地面1米进行超低空飞行,所以如果磁头制作工艺不够精湛,可能会导致磁头在写入/读取数据时,与盘面发生摩擦(高速旋转)发热,从而导致磁场消失,该扇区失效, 数据丢失

机械硬盘 不能在其运行时随意移动,因为角度的偏转也有可能导致发生摩擦,造成数据丢失,更不能用力拍打 机械硬盘
关于 机械硬盘 写入数据时的工作原理可以观看以下视频
机械硬盘工作的原理
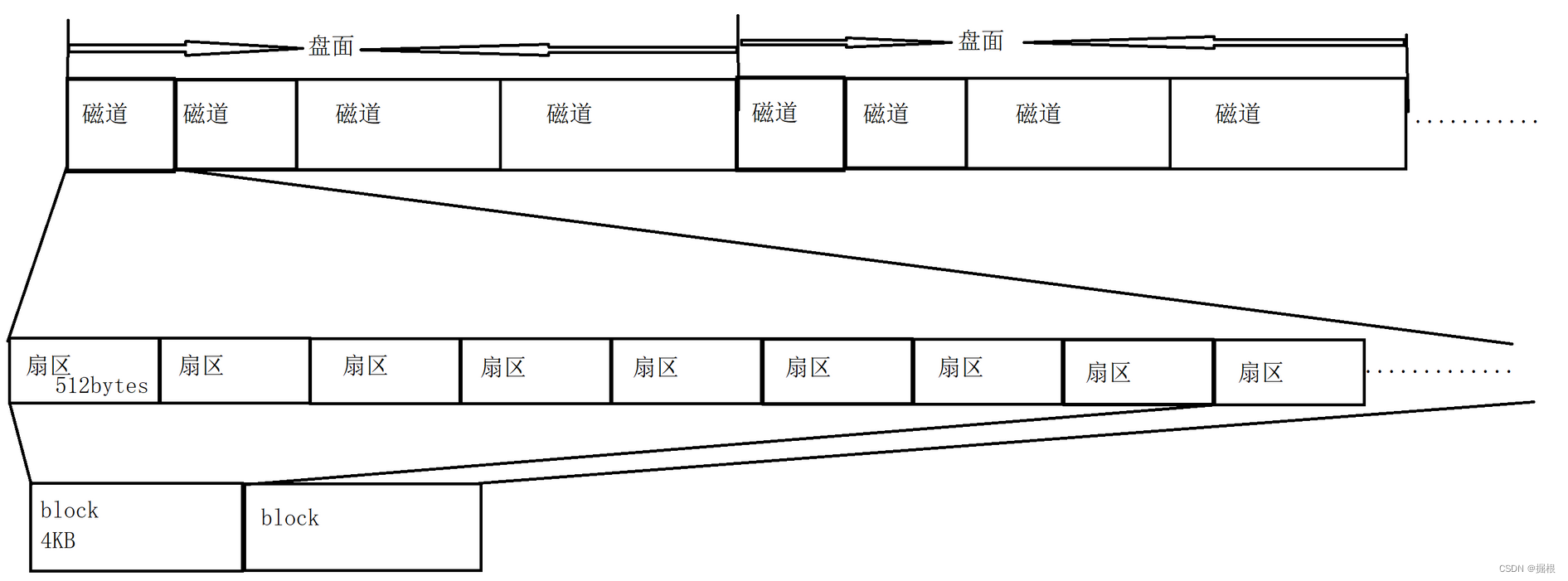
在盘面设计上,一个盘面被切割若干个扇区,单个扇区大小为 512 字节(或者 4 kb),这些扇区用来存储数据,同一半径中的所有扇区组成扇面;而半径相同的扇区组成磁道(柱面)
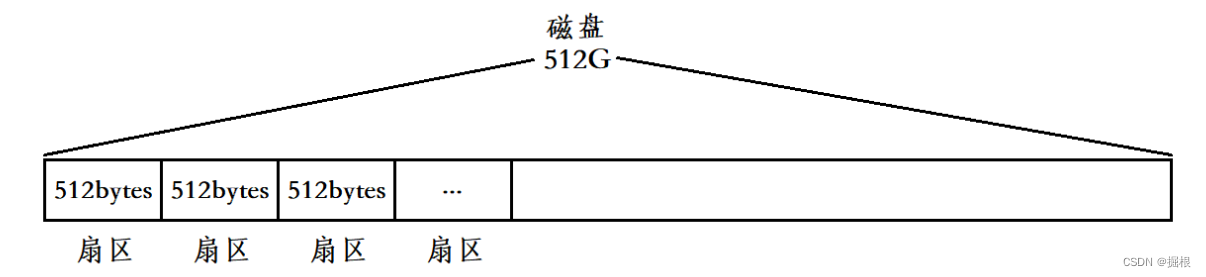
我们可以先根据磁头(head)确定盘面,再根据半径定位磁道(柱面 cylinder),最后根据块号确定扇区(sector)
- 这种寻址方法称为
CHS定位法,是机械设备查找具体扇区时的方法
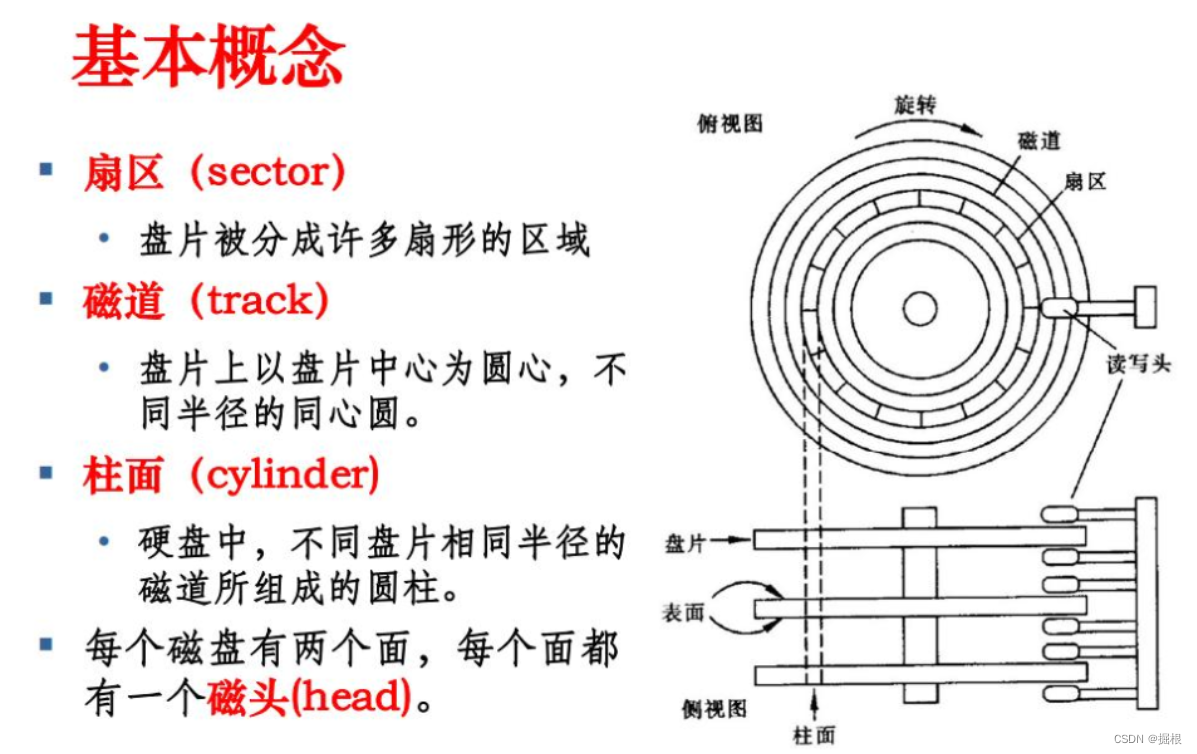

文件(数据+属性)在存储时,占用一个或多个扇区进行 数据存储
虽然 CHS 定位法很妙,但它太依赖于具体硬件信息了,假设其中的硬件参数有所不同,那么 OS 就得使用另一套 CHS 定位法,于是为了做到 解耦 ,OS 使用的并非 CHS 定位法进行文件定位,而是采用 LBA****逻辑地址块进行寻址
- 将盘面分割为多个线性分区,通过下标
N计算出CHS地址,然后进行文件访问
将磁道拉长,会得到一串线性空间(数组),其中的每个单位(扇区)为 512 字节(或者 4 kb)
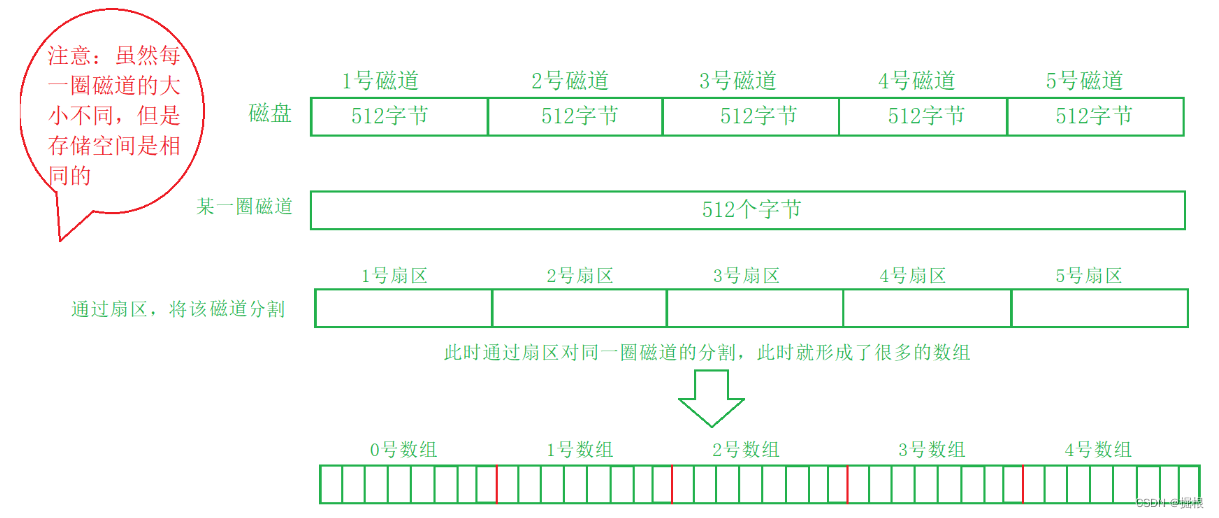
现在 OS 想访问具体的扇区时,只需通过 起始扇区的地址 + 偏移量 就可以获取 LBA 地址,然后通过特定手段转为 CHS 地址,交给外设进行访问即可 LBA和CHS转换
因此对于外设中文件的管理,经过 先描述,再组织 后,变成了对数组的管理,这个数据就是 task_struct 中的 struct block
最后我们就能理解为什么 IO 的基本单位是 4 kb 了,因为直接读取一个数据块(4 kb),这样可以提高 IO 效率(内存对齐)
2.2、磁盘信息
一般电脑中会存在多个分区,比如 C盘、D盘,那么为何需要存在这些分区呢?
2.2.1、分区意义
磁盘空间是巨大的,如果不加以划分,会导致 OS 的管理成本提高,对应到现实生活中,学校需要将不同专业的学生及老师分为不同学院,比如管理学院、信息工程学院等,分院后的好处不言而喻,最重要的是上层管理者更好的调用管理资源 ,这种思想称为 分治思想
在文件系统中,OS 先将整个大文件系统分为不同的区,存入 struct disk 数组中进行管理
cpp
struct disk
{
struct part[2];
//......
};可以通过 ll /dev/vda* -i 查看当前系统中的 分区数 及 详细信息
系统在分区后,需要对区块进行格式化
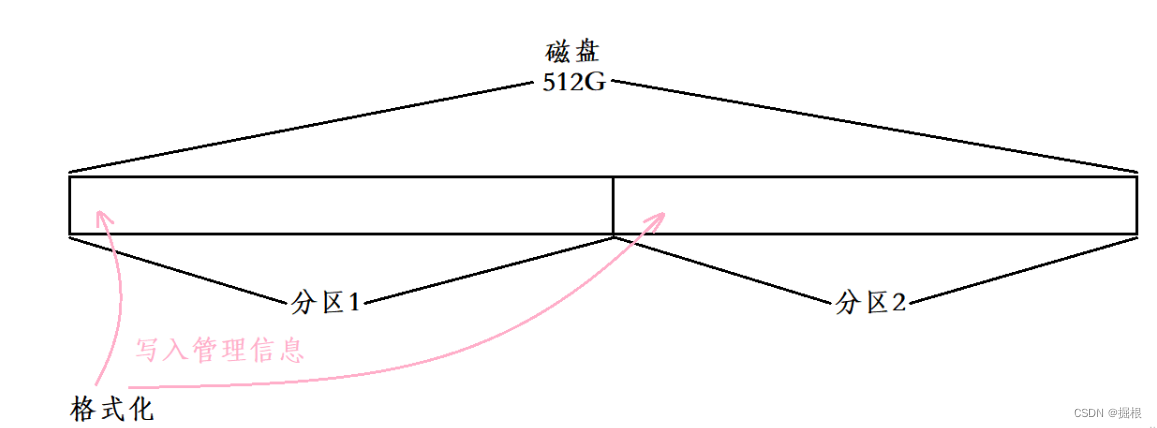
不同的文件系统在格式化时写入的数据是不同的,这里讨论的是 EXT 文件系统
- 磁盘分区后,分组、填写系统属性是
OS做的事 - 为了使分区能被正常使用,需要对分区进行格式化
- 分区格式化:
OS向分区写入文件系统的管理属性信息 - 在具体分区内,还可以细分为 块组
由 块组 构成的线性空间亦可称为 组线 (代表一个 分区)
cpp
struct part
{
struct part group[100]; //分为100个块组
int lba_start; //起始与结束位置
int lba_end;
//......
}将现有资源再分配后,可以 最大化利用资源,避免造成浪费及拖慢效率
块组(Block Group)是本文的重点内容
2.2.2、块组信息
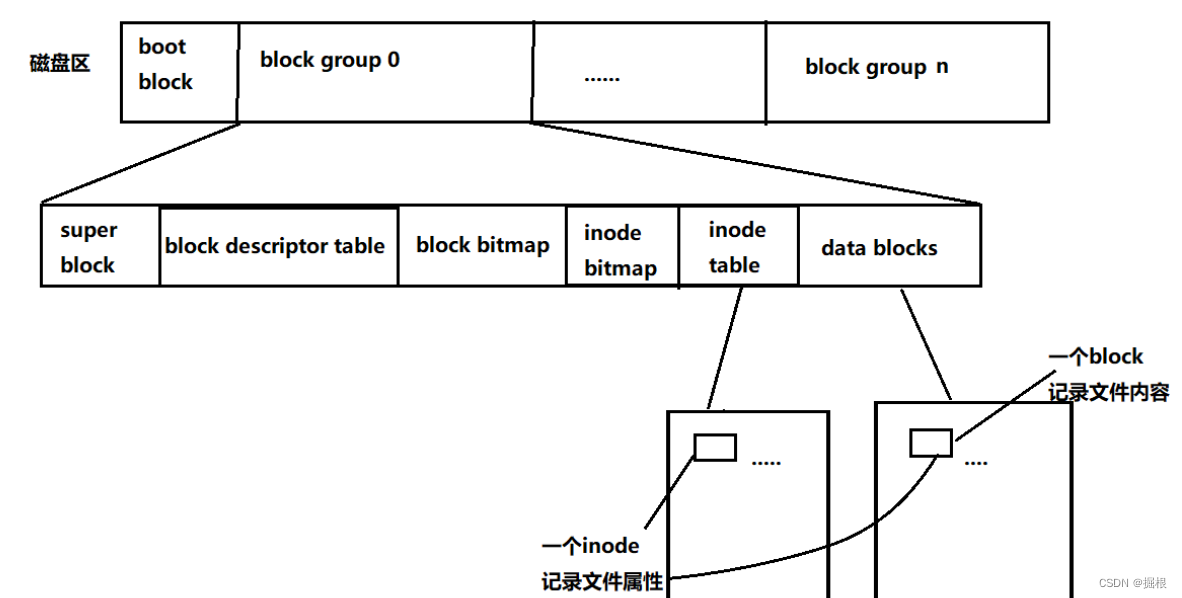
块组 是由 分区 细分出的产物,它与分区的关系如图所示:
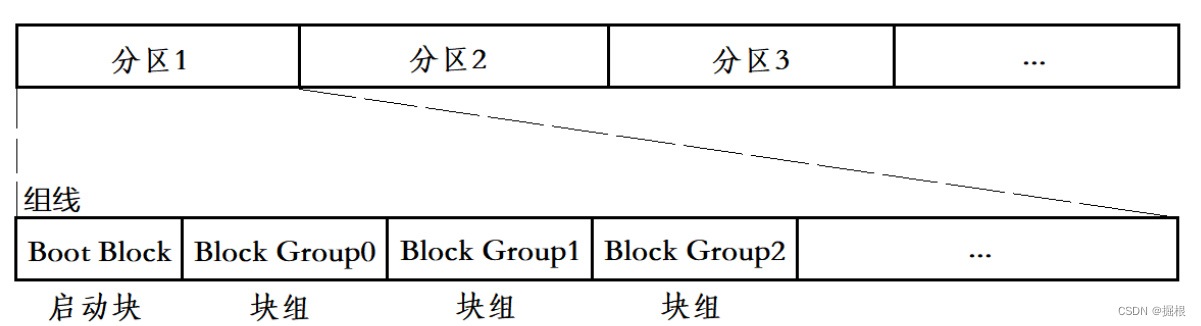
其中, Boot Block 是 启动块 ,大小固定为 1 kb,在每一条 组线 前都有此 块组 ,它用来 存储分区信息和系统启动,属于被保护的内容,不允许用户私自修改
至于其他 块组,它们有着统一的格式,具体内容如图所示:
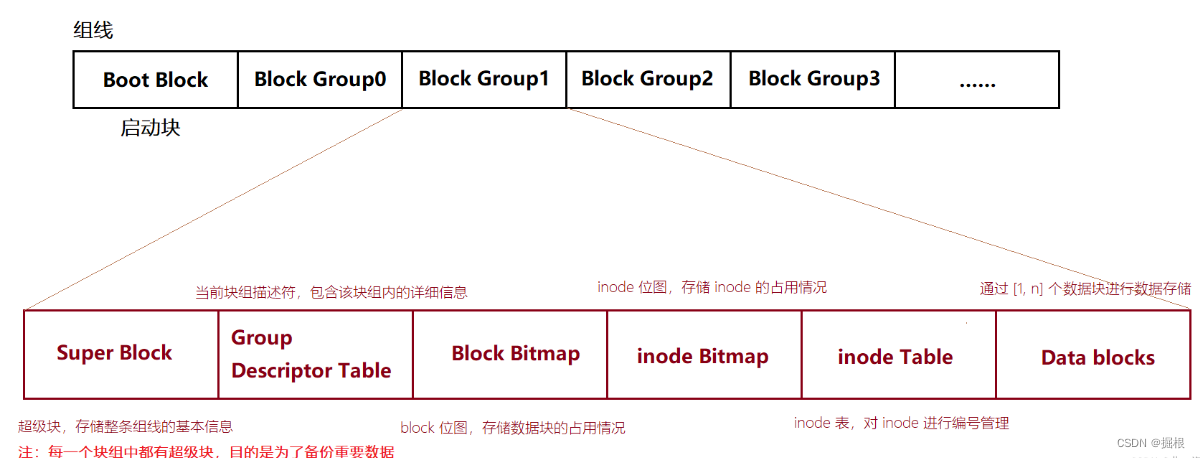
其中一个文件对应一个 inode,而 inode 中存储了该文件的所有属性,包括所使用的数组块信息,因为文件很多,所以需要 先描述,再组织,即通过 inode Table 对 inode 进行管理
注意:
- inode 属性中并不包含文件名,文件名只是给用户用的
- 目录文件也有 inode,目录中的数据块保存的是该目录下的 文件名 和 inode 编号对应的映射关系,而且在此目录内,文件名和 inode 互为 key 值
- inode 确定分组,inode 值只在一个分区内有效,不能跨分区
2.3.理解文件操作
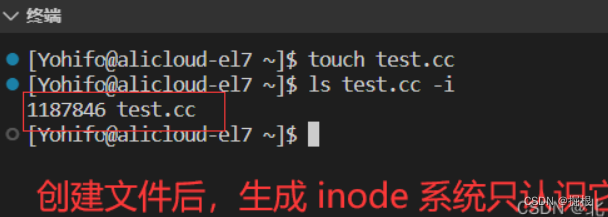
2.3.1.创建一个空文件的步骤
-
遍历
inode位图,找到一个空闲的inode -
在inode表当中找到对应的inode,将文件的属性信息填入inode结构中
-
将该文件的文件名和inode指针添加到目录文件的数据块中
每个
inode和Data block只对应一个文件
注意: 每使用一个 inode 和一个 Data block,需要把它们对应位图中的信息改为已占用
2.3.2. 文件访问
文件创建后,如何根据 inode 访问文件呢?
- 首先根据文件的inode编号,在目录分组中进行查找
- 通过 inode和Data block 的映射关系,找到文件的数据块,并加载至内存中即可
这就解释了在file 对象中有 inode 信息的原因
2.3.3、对文件进行增删查改
文件创建后,如何删除?删除并不是真删除,而是将 inode Bitmap 和 Block Bitmap 中位图信息进行修改即可(只要访问不到,就是删除)
- 根据文件名找到 inode 编号
- 再根据 inode 属性中的映射关系,设置 Block Bitmap 对应的比特位,设置为 0 (删内容)
- 最后根据 inode 编号设置 inode Bitmap 中对应的比特位为 0 (删属性)
将位图信息置为 0 后,创建新文件时,系统可以直接使用
至于文件的查找与修改,通过 inode 修改其内部属性即可
注意: inode 和 Data blcok 可能存在失衡的情况
- 一直创建空文件,导致 inode 满载,而 Data block 空余很多
- 不断往同一个文件中写入数据,导致 Data block 被占用,后续创建文件时,inode 无法再分配到 Data block
2.3.4 删除文件
删除文件的步骤
- 首先根据文件名找到
inode编号 - 再将该文件对应的
inode,在inode位图当中置为无效(置0) - 最后将该文件申请的数据块,在块位图当中置为无效(置0)
此删除操作并不会真正将文件对应的信息删除,而只是将其inode号和数据块号置为了无效,起到了访问不到就等于删除的效果
当我们删除文件后短时间内是可以恢复的
为什么说是短时间内呢,因为该文件对应的inode号和数据块号已经被置为了无效,因此后续创建其他文件或是对其他文件进行写入操作申请inode号和数据块号时,可能会将该置为无效了的inode号和数据块号分配出去,此时删除文件的数据就会被覆盖,也就无法恢复文件了。
2.3.5.为什么拷贝文件的时候很慢,而删除文件的时候很快?
因为拷贝文件需要先创建文件,然后再对该文件进行写入操作,该过程需要先申请inode号并填入文件的属性信息,之后还需要再申请数据块号,最后才能进行文件内容的数据拷贝,而删除文件只需将对应文件的inode号和数据块号置为无效即可,无需真正的删除文件,因此拷贝文件是很慢的,而删除文件是很快的。
2.3.6、文件误删后的解决方案
磁盘中的数据被删除后,还可以再恢复吗?
答案是可以的,但不能完全恢复,并且越早断电、送修越好
前面说过,删除并不是真删除,访问不到就行了,所以只要在删除后,根据 inode 找到 Data block,其中的内容没有被覆盖,数据就可以找回来
应急方案:
- 不要轻举妄动,避免 Data block 被覆盖
- 通过 inode 将 inode Bitmap 中的位图置 1,使文件复活,再根据属性进行数据恢复
- 如果自己不知道 inode,那就尽早断电,送给厂家恢复(专业)
如何避免误删文件?
- 学习 Windows 中的回收站,删除不是真删除,而是先将文件移入回收站(目录)中,留给用户反悔的时间
2.3.7、大文件存储
单个数据块大小有限(4 kb),如何做到一个数据块存储大量数据?
答案是 套娃 ,Data block 中存储其他 Data block 信息,此时称为多级索引,可以做到一个数据块中存储大量数据
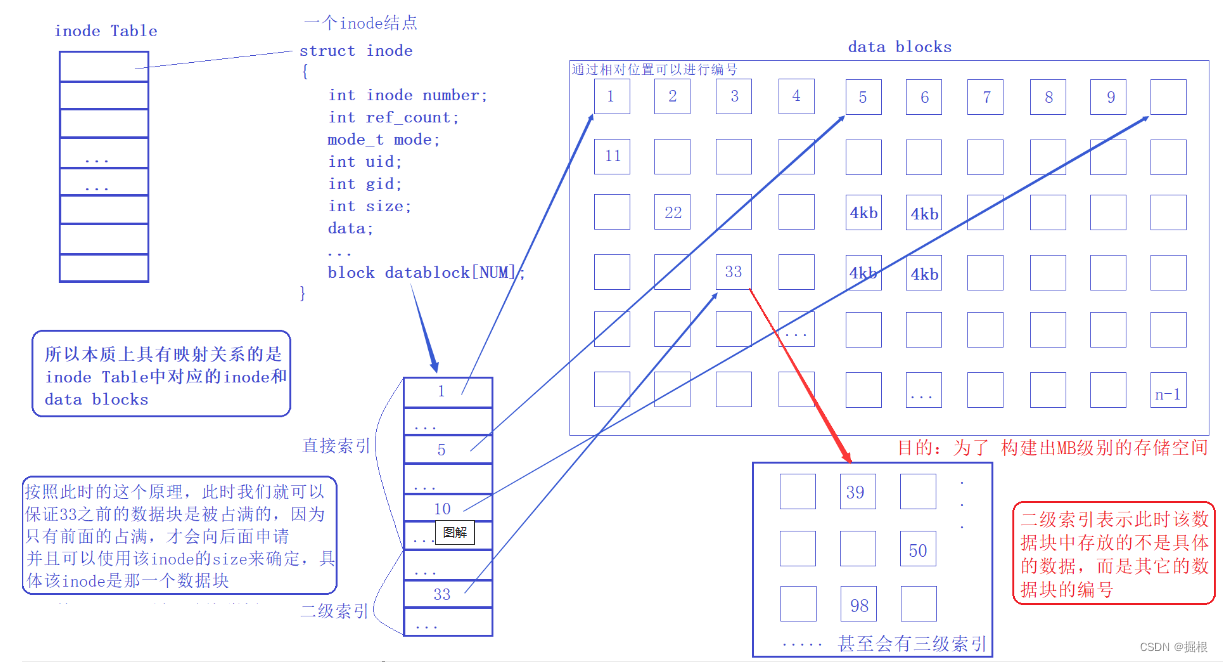
3.了解文件系统
为了更好的理解inode,我们得来了解一下文件系统
Linux的正规文件系统是Ext2
- 传统磁盘和文件系统应用中,一个分区就是只能被格式化成一个文件系统,所以说一个文件系统就是一个分区,但是由于新技术的应用可以将一个分区格式化为多个文件系统,也能将多个分区合成一个文件系统,所以可以称呼一个被挂载的数据为一个文件系统而不是一个分区
文件系统是如何运行的呢?
- 文件包含内容和属性,那么文件系统通常会将内容和属性这两部分的数据分别存在不同的块中,权限和属性放在
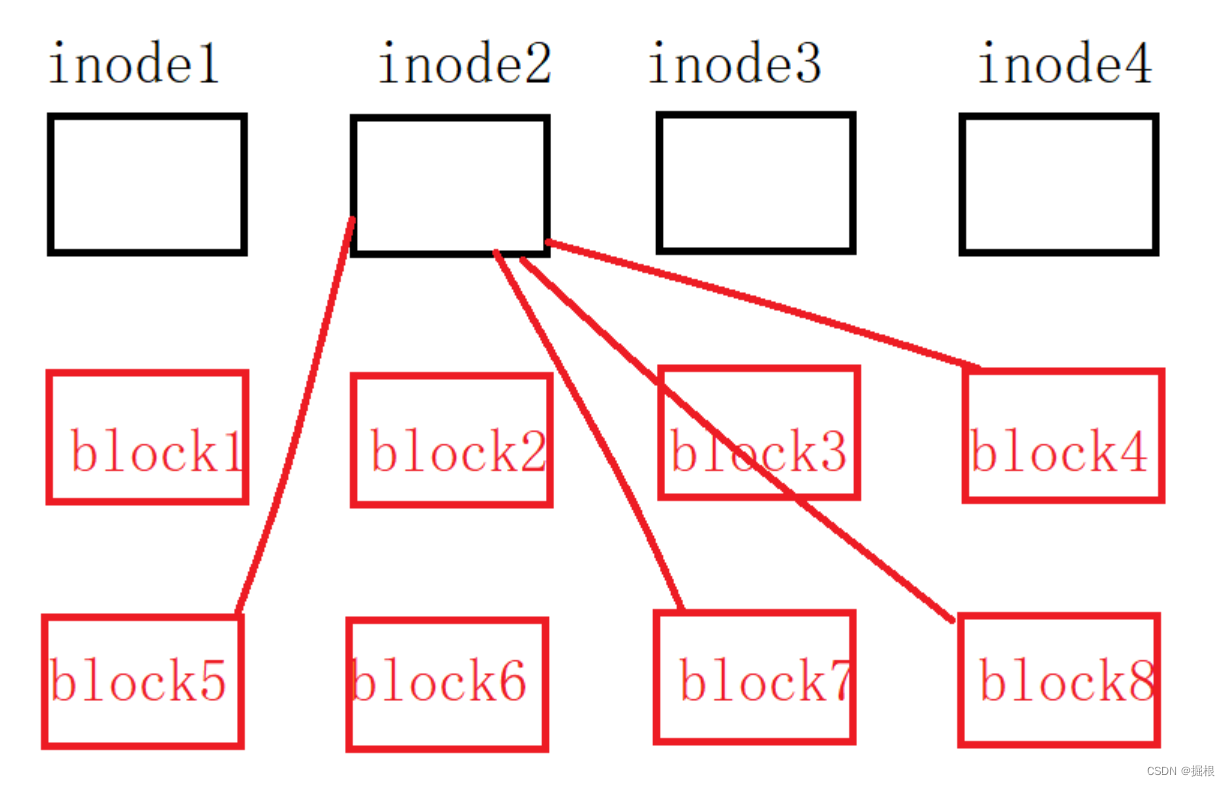
inode中,内容放在data block块中。另外还有一个super block块会记录文件系统的整个信息,包括inode和block的总量、使用量等等。 - 每一个
inode和block都有编号方便管理。其中inode记录文件属性,一个文件占用一个inode,同时记录此文件的数据所在的data block号;block是记录文件内容,如果文件太大时,会占用多个block。既然我们知道inode中包含data block号,那么也就是说只要找到文件的inode就可以通过inode中data block编号读写数据,性能比较。如下图:
3.1 EXT2文件系统
Linux文件系统EXT2就是使用inode为基础的文件系统
inode是记录权限和属性,data block是记录文件内容。文件系统一开始就将inode和block规划好了,除非重新格式化,否则inode和block固定后就不再变动。- 如果文件系统非常大时,将所有的
inode和block放置在一起很不明智,为了更好的管理磁盘,会对磁盘进行分区。而对于每一个分区来说,分区的头部会包括一个启动块(Boot Block),对于该分区的其余区域,EXT2文件系统会根据分区的大小将其划分为一个个的块组(Block Group) - 每个组块都有着相同的组成结构,每个组块都由各自独立的超级块(
Super Block)、块组描述符表(Group Descriptor Table)、块位图(Block Bitmap)、inode位图(inode Bitmap)、inode表(inode Table)和数据表(Data Block)组成
下面以单个盘片来说,磁道上的扇区全部拿下来就变成了一个数组,第一个扇区中有主引导分区和一个分区表,八个扇区也就是一个block(这样更方便管理),块中存放数据:
把区、块分组,再对每个块组做管理:
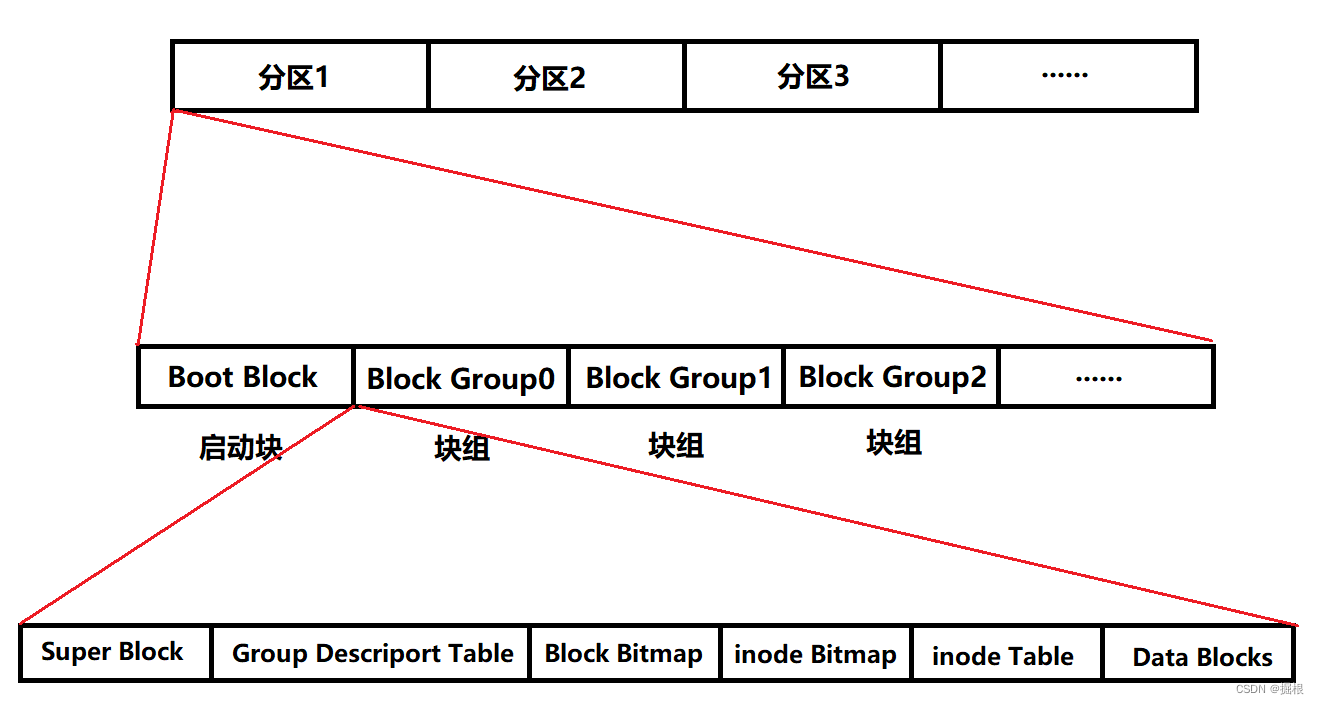
各区域作用

- 其他块组当中可能会存在冗余的Super Block,当某一Super Block被破坏后可以通过其他Super Block进行恢复。
- 磁盘分区并格式化后,每个分区的inode个数就确定了。
3.2.理解磁盘分区与格式化
磁盘通常被称为块设备,一般以扇区为单位,一个扇区的大小通常为512字节。我们若以大小为512G的磁盘为例,该磁盘就可被分为十亿多个扇区。
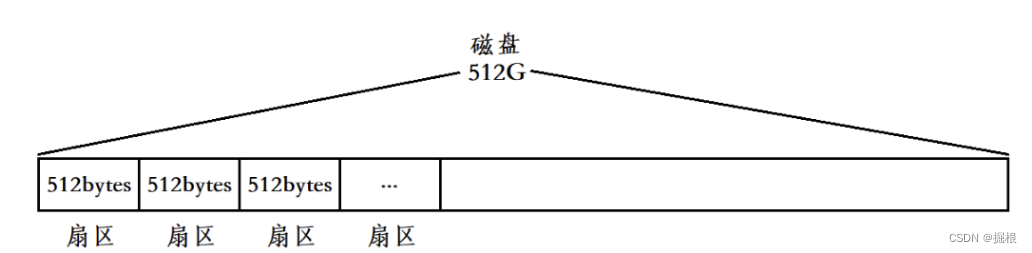
计算机为了更好的管理磁盘,于是对磁盘进行了分区。
磁盘分区就是使用分区编辑器在磁盘上划分几个逻辑部分,盘片一旦划分成数个分区,不同的目录与文件就可以存储进不同的分区,分区越多,就可以将文件的性质区分得越细,按照更为细分的性质,存储在不同的地方以管理文件,例如在Windows下磁盘一般被分为C盘和D盘两个区域。
命令:ls /dev/vda* -l 查看磁盘分区信息

一个磁盘的分区的结构可以看做下图这样。inode可以直接看作是文件编号,操作系统是通过inode来确定文件,而不是文件名(文件名是给用户看的)。block存放文件内容,indode属性中记录了对应的block编号,这样就将文件属性和内容联系在了一起,就组成了一个完整的文件。
4.硬链接
我们看到,真正找到磁盘上文件的并不是文件名,而是inode。 其实在linux中可以让多个文件名对应于同一个inode。
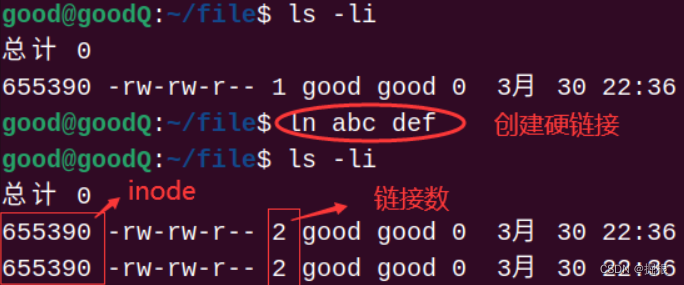
abc和def的链接状态完全相同,他们被称为指向文件的硬链接。内核记录了这个连接数inode263466的硬连接数为2。
我们在删除文件时干了两件事情:1.在目录中将对应的记录删除,2.将硬连接数-1,如果为0,则将对应的磁盘释放。
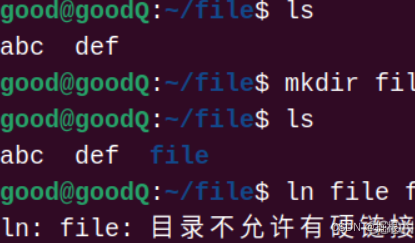
注意:硬链接不可以链接文件夹,如图所示:
4.1.创建硬链接
我们可以通过以下命令创建一个文件的硬连接。
cpp
ln test test.hard.link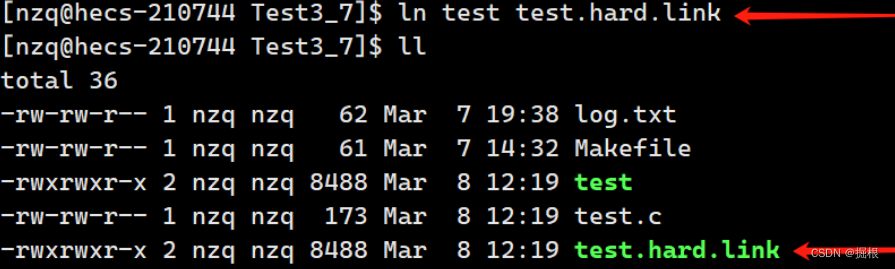
通过ls -i -l命令我们可以看到,硬链接文件的inode号与源文件的inode号是相同的,并且硬链接文件的大小与源文件的大小也是相同的,特别注意的是,当创建了一个硬链接文件后,该硬链接文件和源文件的硬链接数都变成了2。
 **硬链接文件就是源文件的一个别名,**一个文件有几个文件名,该文件的硬链接数就是几,这里inode号为2235074的文件有test和test.hard.link两个文件名,因此该文件的硬链接数为2。
**硬链接文件就是源文件的一个别名,**一个文件有几个文件名,该文件的硬链接数就是几,这里inode号为2235074的文件有test和test.hard.link两个文件名,因此该文件的硬链接数为2。
注意:与软连接不同的是,当硬链接的源文件被删除后,硬链接文件仍能正常执行,只是文件的链接数减少了一个,因为此时该文件的文件名少了一个。
5.软链接
硬链接是通过inode引用另外一个文件,软链接是通过名字引用另外一个文件
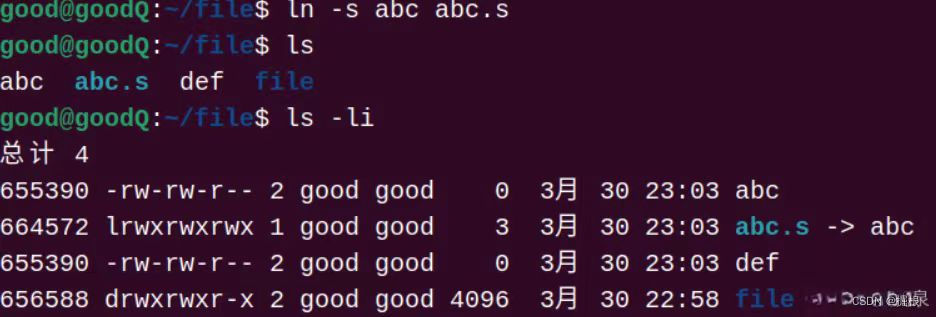
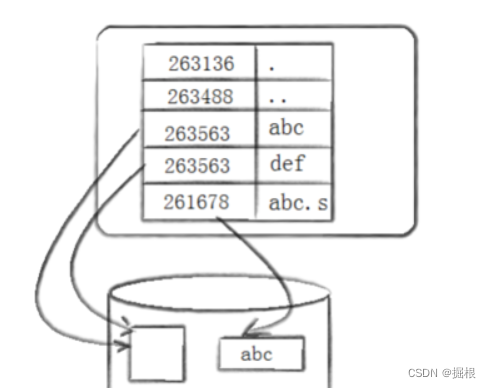
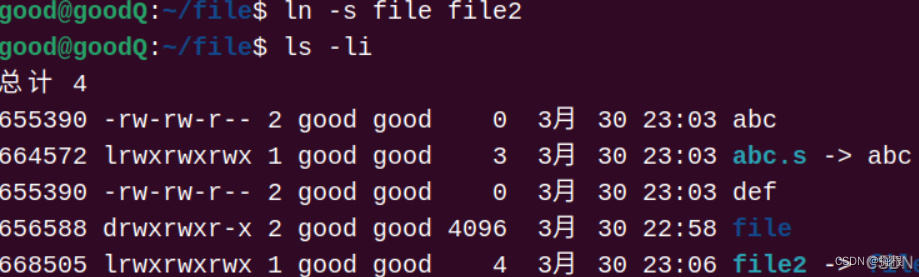
那么硬链接不可以链接文件夹,软链接可以嘛?答案是可以的!
5.1.创建软链接
我们可以通过以下命令创建一个文件的软链接。
cpp
ln -s test test.soft.link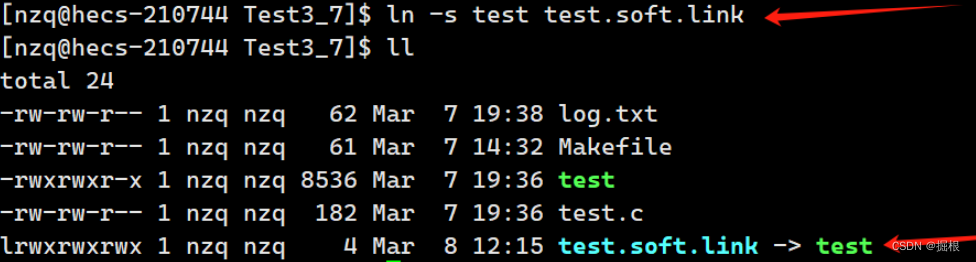
通过ls -i -l命令我们可以看到,软链接文件的inode号与源文件的inode号是不同的,并且软链接文件的大小比源文件的大小要小得多。
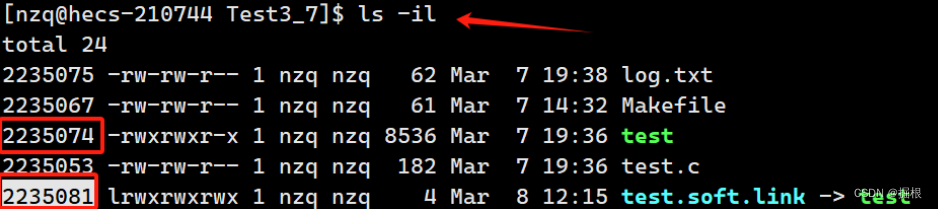
软链接又叫做符号链接,软链接文件相对于源文件来说是一个独立的文件,该文件有自己的inode号,但是该文件只包含了源文件的路径名,所以软链接文件的大小要比源文件小得多。软链接就类似于Windows操作系统当中的快捷方式.
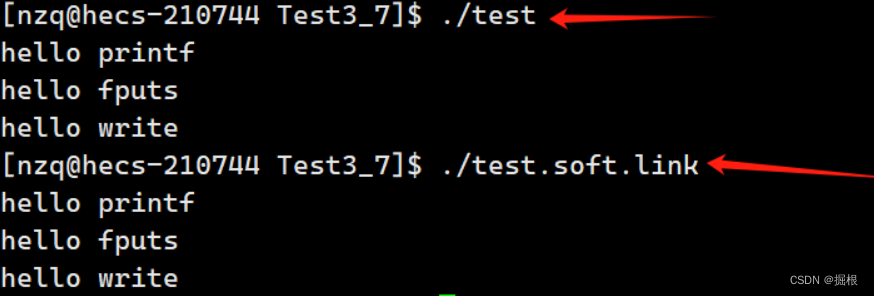
注意 :但是软链接文件只是其源文件的一个标记,当删除了源文件后,链接文件不能独立存在,虽然仍保留文件名,但却不能执行或是查看软链接的内容了。
6.软硬链接的区别
- 1.软链接相当于快捷方式,硬链接本质没有创建文件,只是建立了一个文件名和已有的inode的映射关系,并写入当前目录。
- 2.软链接形成的是一个独立的文件,有独立的inode,文件的内容是对应文件的路径,硬链接则是同一个文件,文件名和Inode的映射,而硬链接没有独立的inode。
- 3.软链接的引用计数不会改变,硬链接则会改变。