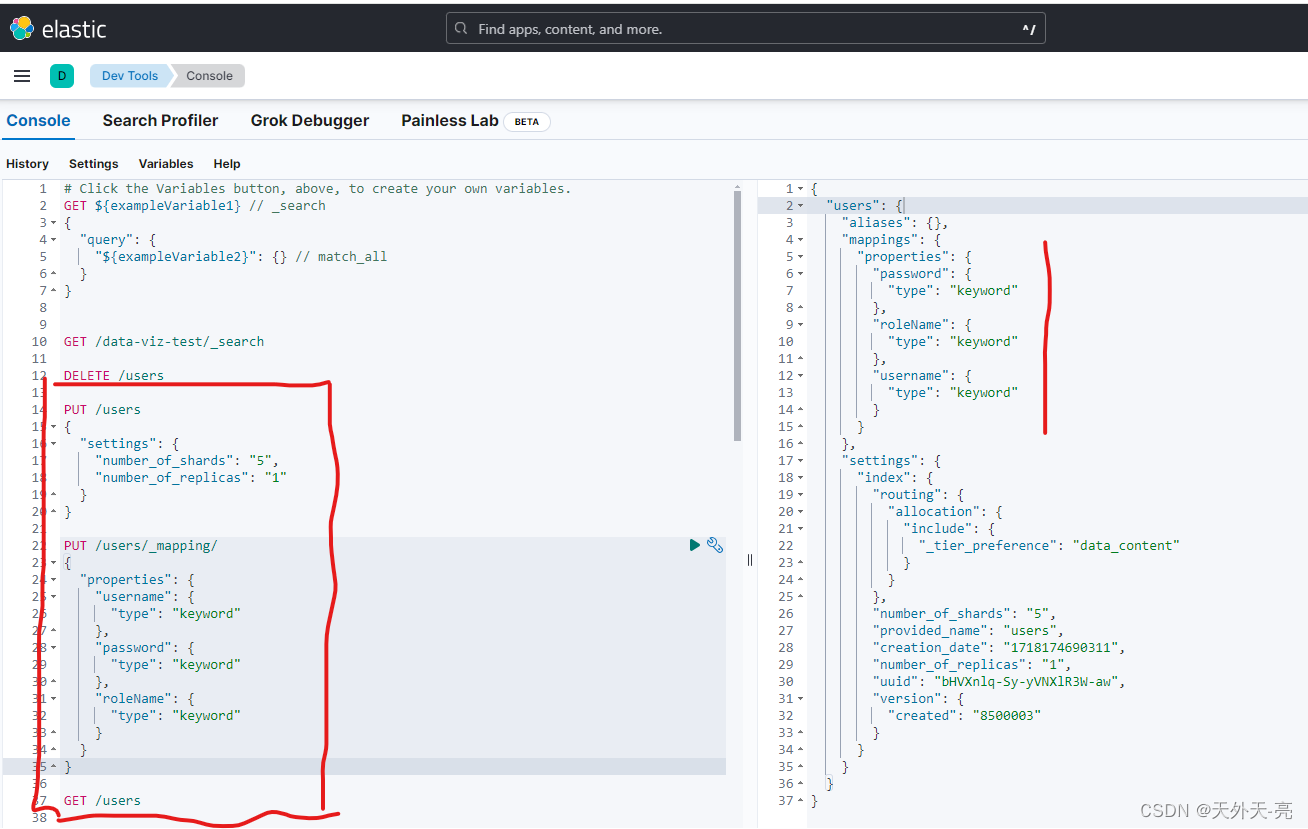
当我们使用 kibana 创建索引时,如果不申明数据类型,默认字符串赋予 text类型,如下图所示
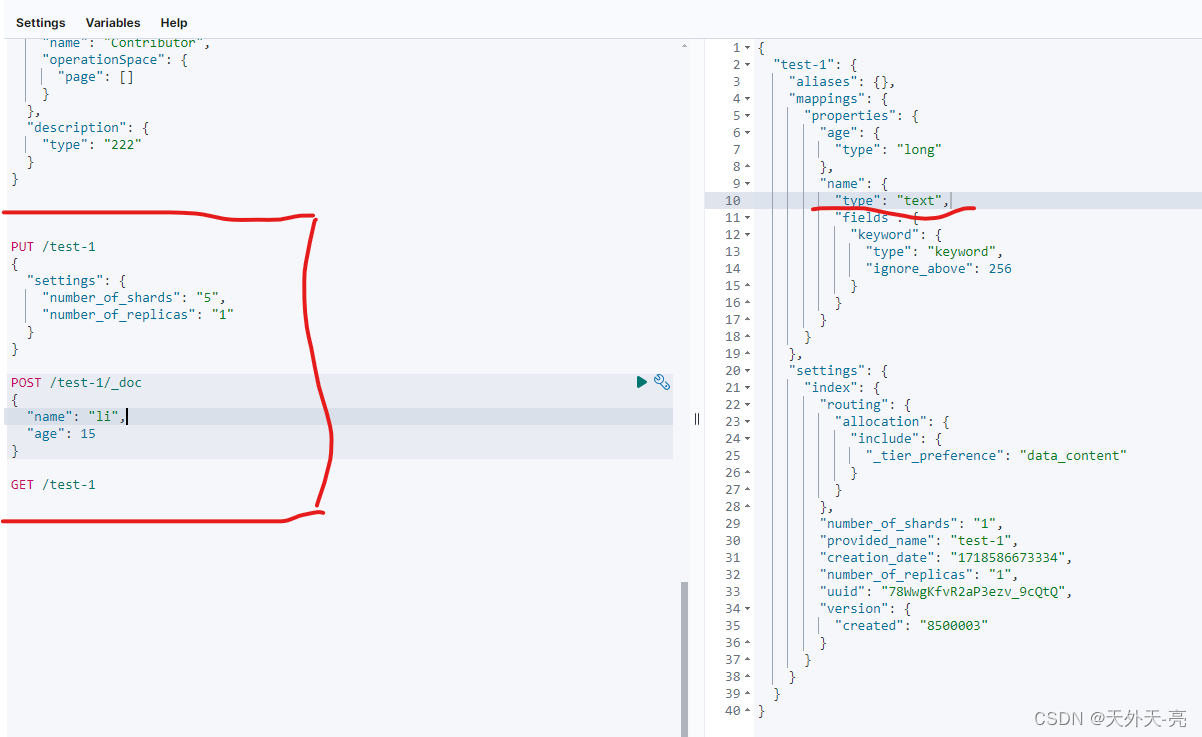
接下来我们继续创建多条数据如下:
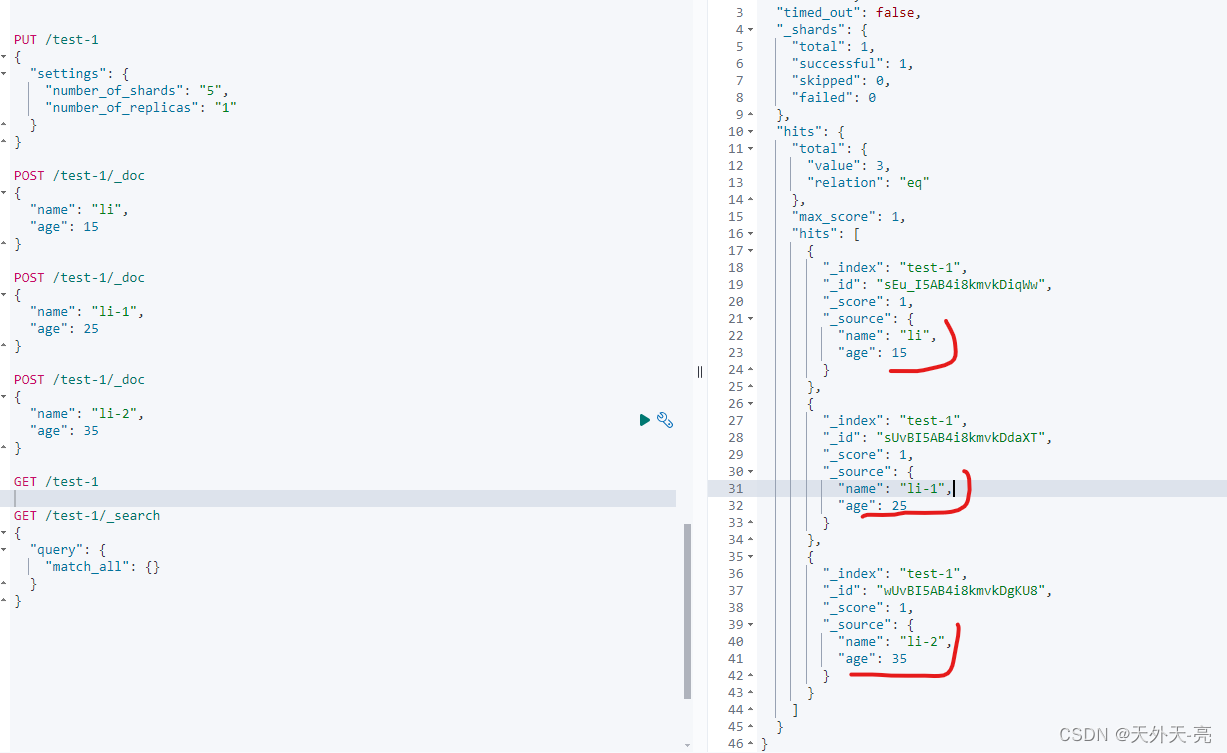
下面我们来检索下:
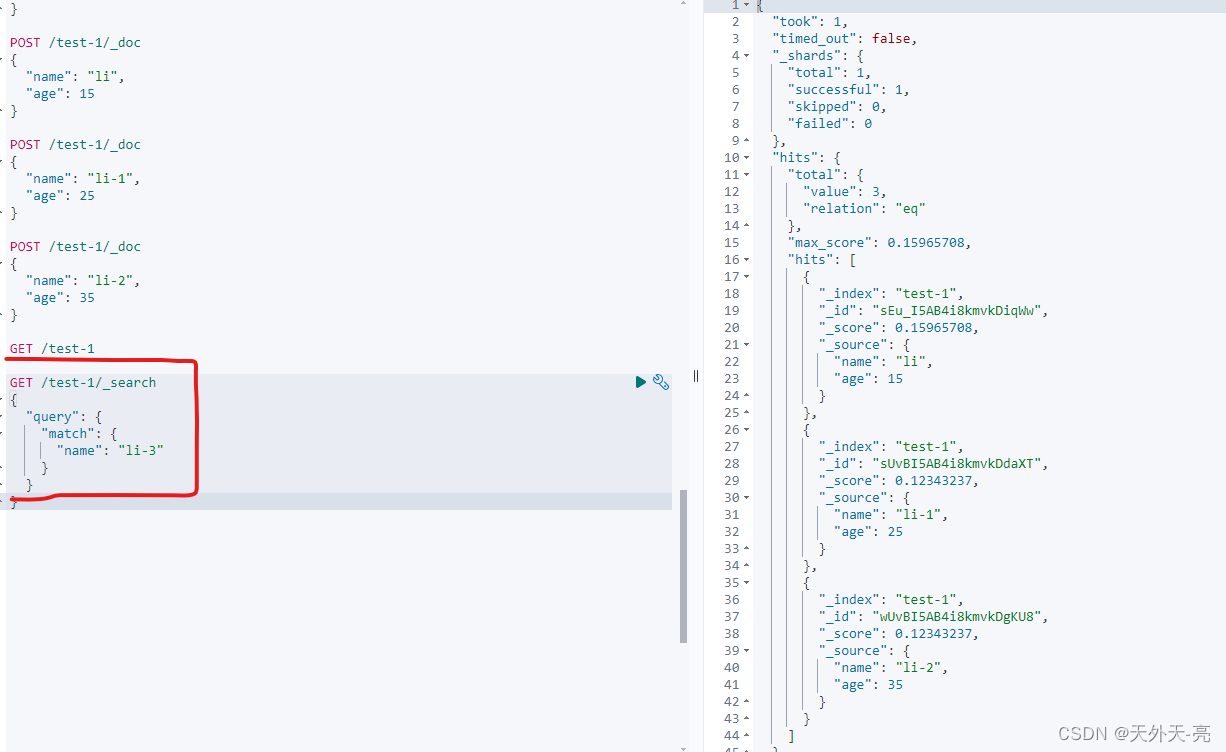
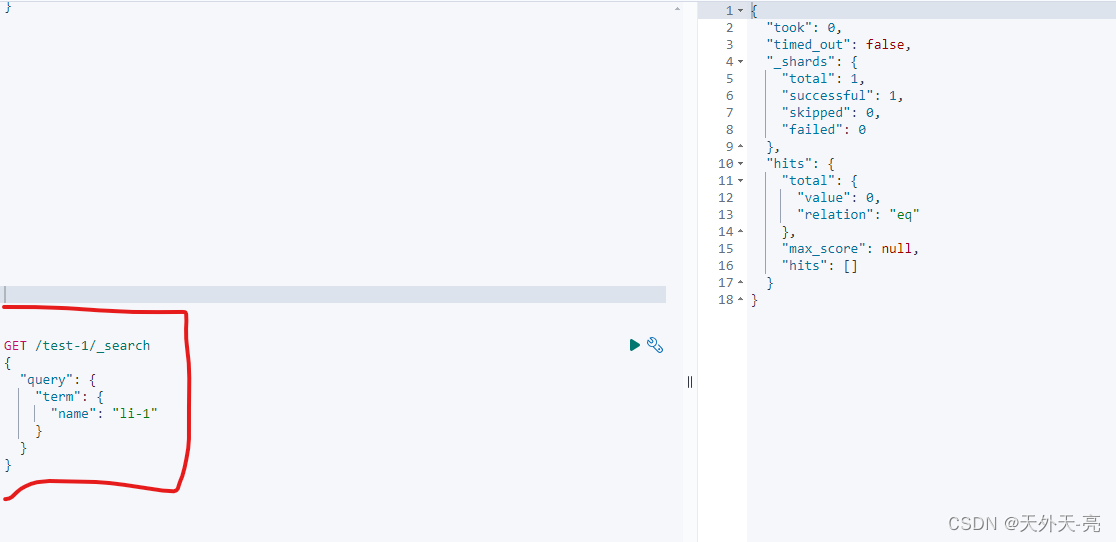
通过以上两个案例我们发现,使用 match 模糊查询 li-3 明明没有对应数值确检索出了结果,而使用 term 精准匹配,"li-1" 明明有对应数据,确检索不出来,这些问题都是我们没有申明数据类型,默认数据类型 text 导致的。
es 核心数据类型
1、text类型:
当一个字段需要用于全文搜索(会被分词),比如产品名称、产品描述信息, 就应该使用text类型。该类型字段会通过分析器转成terms list,然后存入索引。该类型字段不用于排序、聚合操作。
2、keyword类型:
当一个字段需要按照精确值进行过滤、排序、聚合等操作时, 就应该使用keyword类型。该类型的字段值不会被分析器处理(分词)
通过定义我们知道因为 text类型会被分词,所以 "li-3" 能检索出数据,如果需要精准匹配还是用 keyword类型
当然 text 使用 term 也不是完全不能检索:
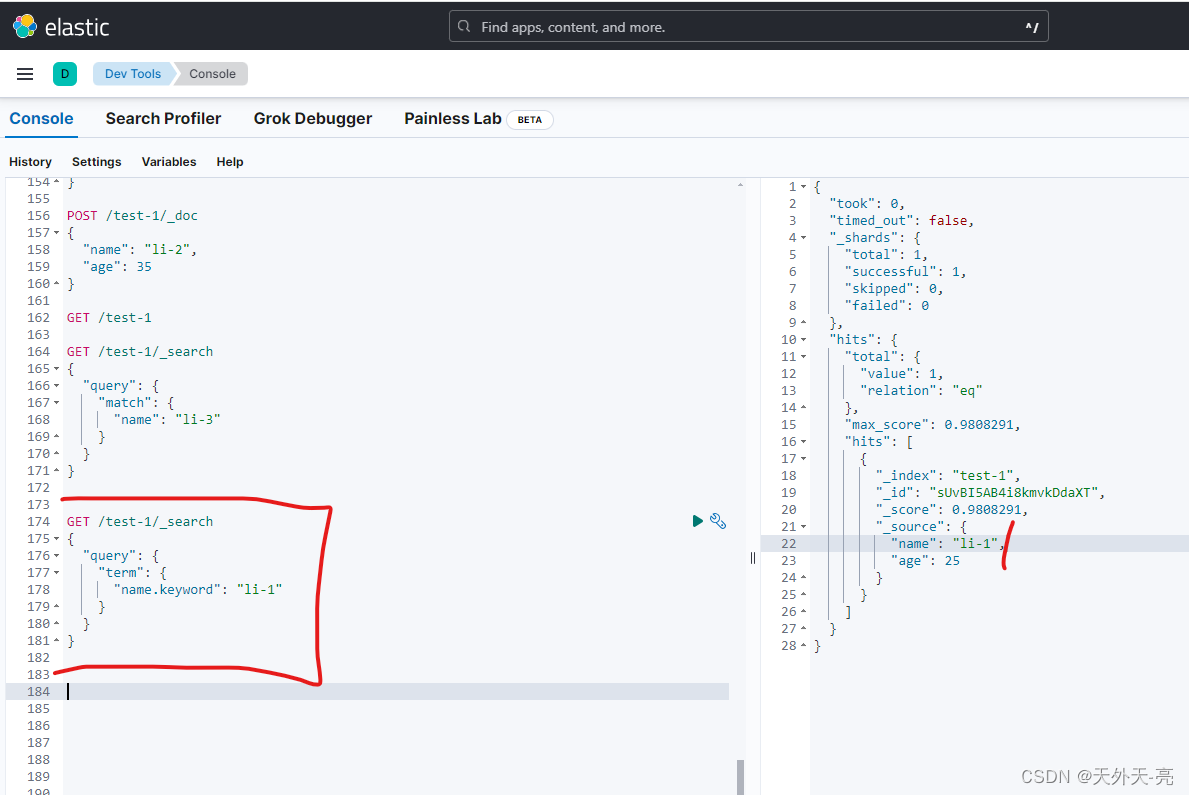
是的,根据数据类型,加上 keyword 即可
3、 数字类型
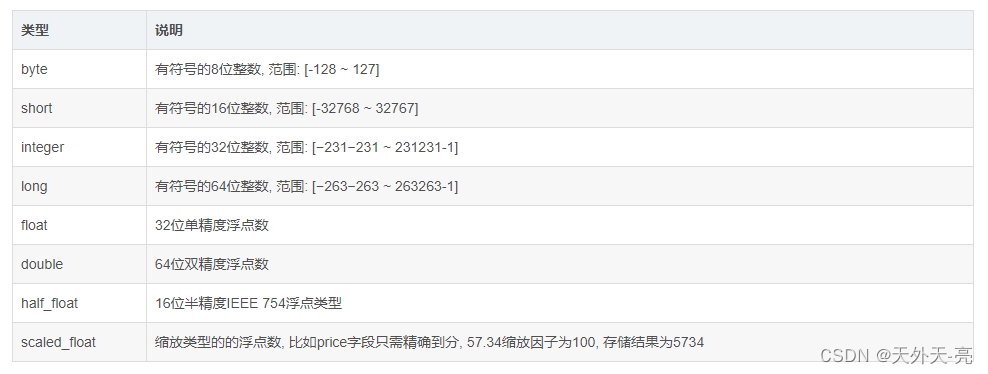
尽可能选择范围小的数据类型, 字段的长度越短, 索引和搜索的效率越高
4、boolean
可以使用boolean类型的(true、false)也可以使用string类型的("true"、"false")。
5、binary类型:
二进制类型是Base64编码字符串的二进制值,不以默认的方式存储,且不能被搜索。
6、日期类型:
JSON没有日期数据类型, 所以在ES中, 日期可以是:
包含格式化日期的字符串, "2018-10-01", 或"2018/10/01 12:10:30".
代表时间毫秒数的长整型数字.
代表时间秒数的整数.
1)使用format指定格式:
若未指定格式,则使用默认格式: strict_date_optional_time||epoch_millis
2)指定多个format:
使用双竖线||分隔指定多种日期格式,每个格式都会被依次尝试,直到找到匹配的。
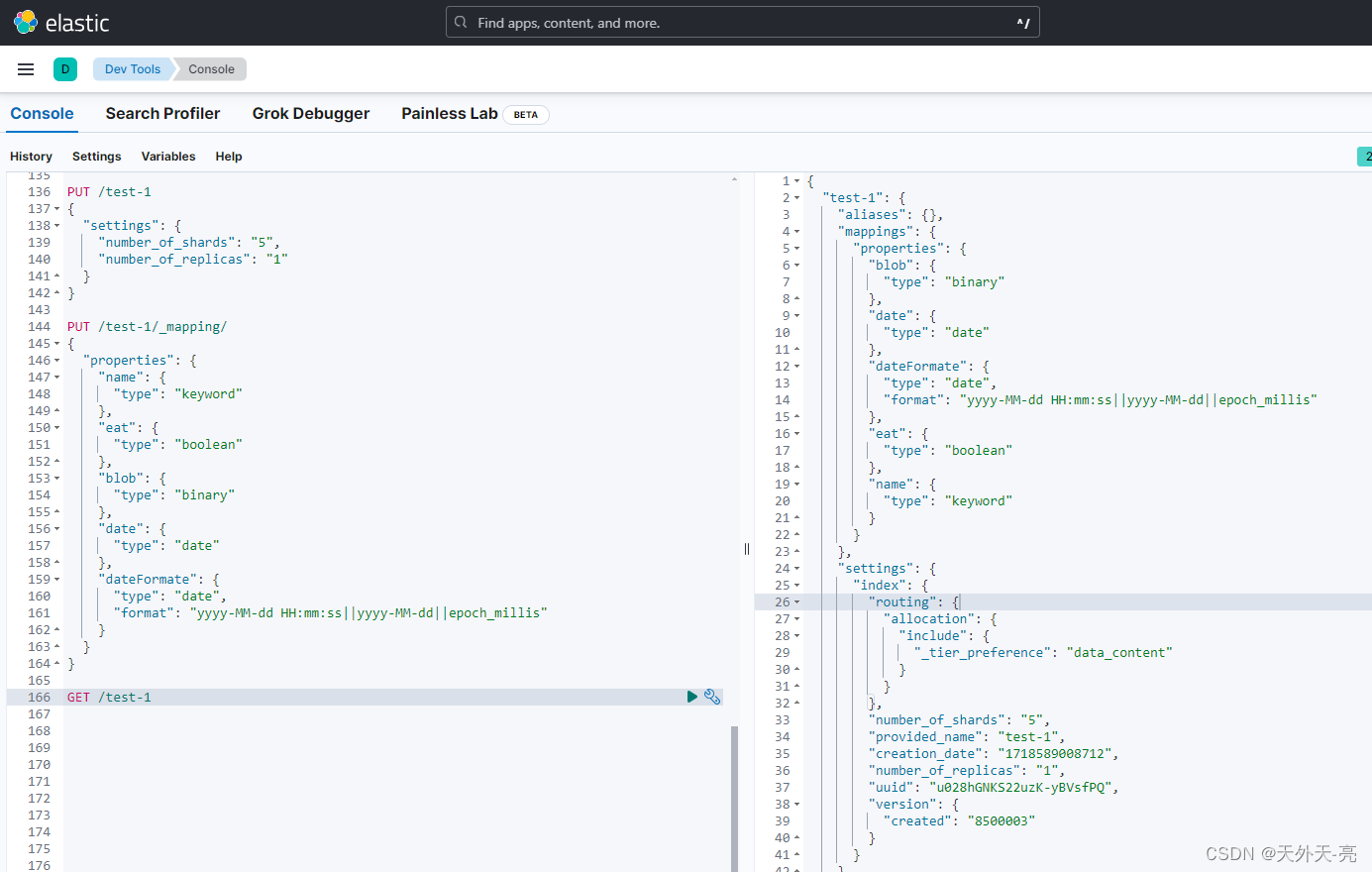
7、复杂数据类型
es支持复杂的数据类型,包括:object、array、nested。举个实例:
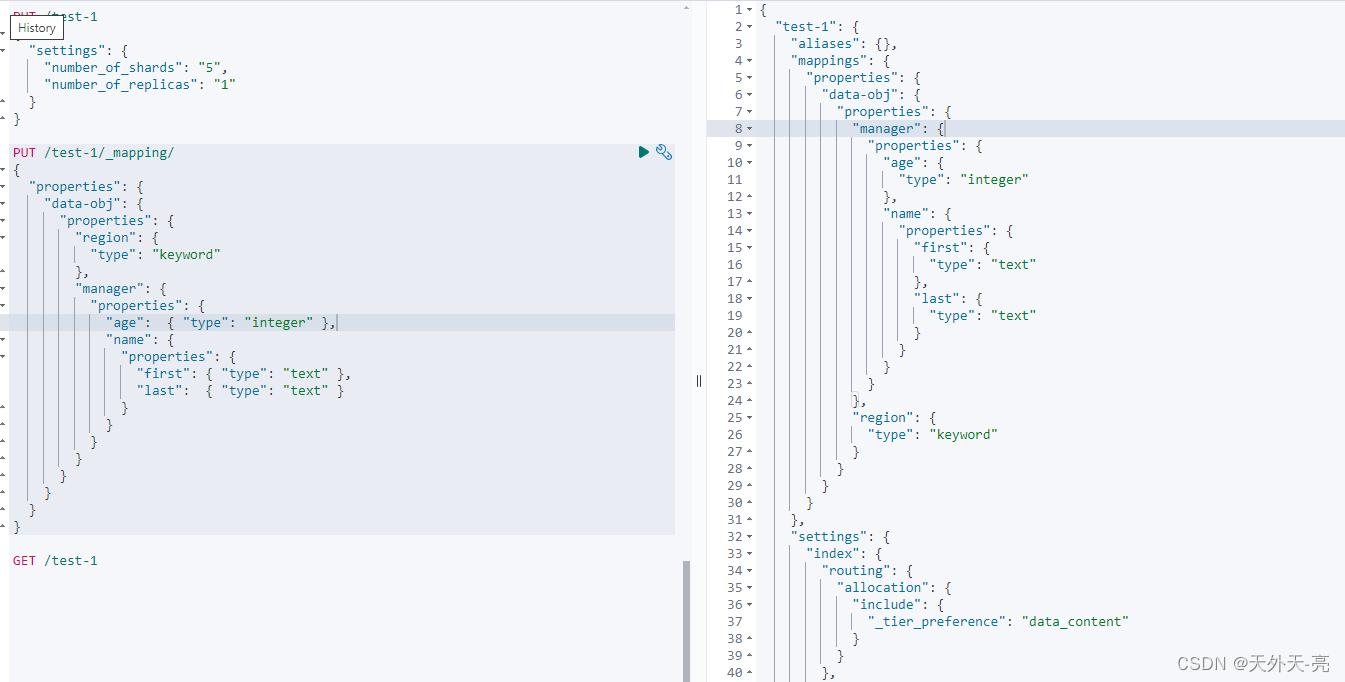
查看映射关系
GET /索引库名/_mapping
查看某个索引库中的所有类型的映射。如果要查看某个类型映射,可以在路径后面跟上类型名称。即:
GET /索引库名/_mapping/类型名
当然也可以直接用
GET /索引库名 查看当前索引的全部数据结构