python查缺补漏
底板除
还有一种除法是//,称为地板除,两个整数的除法仍然是整数:
>>> 10 // 3
3你没有看错,整数的地板除//永远是整数,即使除不尽。要做精确的除法,使用/就可以。
因为//除法只取结果的整数部分,所以Python还提供一个余数运算,可以得到两个整数相除的余数:
>>> 10 % 3
1无论整数做//除法还是取余数,结果永远是整数,所以,整数运算结果永远是精确的。
字符串输出
如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串:
>>> 'Age: %s. Gender: %s' % (25, True)
'Age: 25. Gender: True'有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表示一个%:
>>> 'growth rate: %d %%' % 7
'growth rate: 7 %'format()
另一种格式化字符串的方法是使用字符串的format()方法,它会用传入的参数依次替换字符串内的占位符{0}、{1}......,不过这种方式写起来比%要麻烦得多:
>>> 'Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125)
'Hello, 小明, 成绩提升了 17.1%'f-string
最后一种格式化字符串的方法是使用以f开头的字符串,称之为f-string,它和普通字符串不同之处在于,字符串如果包含{xxx},就会以对应的变量替换:
>>> r = 2.5
>>> s = 3.14 * r ** 2
>>> print(f'The area of a circle with radius {r} is {s:.2f}')
The area of a circle with radius 2.5 is 19.62上述代码中,{r}被变量r的值替换,{s:.2f}被变量s的值替换,并且:后面的.2f指定了格式化参数(即保留两位小数),因此,{s:.2f}的替换结果是19.62。
小明的成绩从去年的72分提升到了今年的85分,请计算小明成绩提升的百分点,并用字符串格式化显示出'xx.x%',只保留小数点后1位:
python
# -*- coding: utf-8 -*-
s1 = 72
s2 = 85
r = (s2-s1)/100.00
print('%.1f%%\n' % r)#只有这个里面用到%时候,%才需要写成%%
print(f'{r:.1f}%\n')
print('{0},{1:.1f}%\n'.format('小狗比',r))tuple
如果要定义一个空的tuple,可以写成():
>>> t = ()
>>> t
()但是,要定义一个只有1个元素的tuple,如果你这么定义:
>>> t = (1)
>>> t
1定义的不是tuple,是1这个数!这是因为括号()既可以表示tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python规定,这种情况下,按小括号进行计算,计算结果自然是1。
所以,只有1个元素的tuple定义时必须加一个逗号,,来消除歧义:
>>> t = (1,)
>>> t
(1,)Python在显示只有1个元素的tuple时,也会加一个逗号,,以免你误解成数学计算意义上的括号。
tuple 指向不可变
条件判断
elif
循环
如果要计算1-100的整数之和,从1写到100有点困难,幸好Python提供一个range()函数,可以生成一个整数序列,再通过list()函数可以转换为list。比如range(5)生成的序列是从0开始小于5的整数:
>>> list(range(5))
[0, 1, 2, 3, 4]range(101)就可以生成0-100的整数序列,计算如下:
# -*- coding: utf-8 -*-
sum = 0
for x in range(101):
sum = sum + x
print(sum)函数
默认参数放后面,可变参数放前面
可见,默认参数降低了函数调用的难度,而一旦需要更复杂的调用时,又可以传递更多的参数来实现。无论是简单调用还是复杂调用,函数只需要定义一个。
有多个默认参数时,调用的时候,既可以按顺序提供默认参数,比如调用enroll('Bob', 'M', 7),意思是,除了name,gender这两个参数外,最后1个参数应用在参数age上,city参数由于没有提供,仍然使用默认值。
也可以不按顺序提供部分默认参数。当不按顺序提供部分默认参数时,需要把参数名写上。比如调用enroll('Adam', 'M', city='Tianjin'),意思是,city参数用传进去的值,其他默认参数继续使用默认值。
原因解释如下:
Python函数在定义的时候,默认参数L的值就被计算出来了,即[],因为默认参数L也是一个变量,它指向对象[],每次调用该函数,如果改变了L的内容,则下次调用时,默认参数的内容就变了,不再是函数定义时的[]了。
定义默认参数要牢记一点:默认参数必须指向不变对象!
我们把函数的参数改为可变参数:
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum定义可变参数和定义一个list或tuple参数相比,仅仅在参数前面加了一个*号。在函数内部,参数numbers接收到的是一个tuple,因此,函数代码完全不变。
Python允许你在list或tuple前面加一个*号,把list或tuple的元素变成可变参数传进去:
>>> nums = [1, 2, 3]
>>> calc(*nums)
14*nums表示把nums这个list的所有元素作为可变参数传进去。这种写法相当有用,而且很常见。
关键参数
可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。而关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。请看示例:
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)关键字参数有什么用?它可以扩展函数的功能。比如,在person函数里,我们保证能接收到name和age这两个参数,但是,如果调用者愿意提供更多的参数,我们也能收到。试想你正在做一个用户注册的功能,除了用户名和年龄是必填项外,其他都是可选项,利用关键字参数来定义这个函数就能满足注册的需求。
和可变参数类似,也可以先组装出一个dict,然后,把该dict转换为关键字参数传进去:
>>> extra = {'city': 'Beijing', 'job': 'Engineer'}
>>> person('Jack', 24, city=extra['city'], job=extra['job'])
name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}当然,上面复杂的调用可以用简化的写法:
>>> extra = {'city': 'Beijing', 'job': 'Engineer'}
>>> person('Jack', 24, **extra)
name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}**extra表示把extra这个dict的所有key-value用关键字参数传入到函数的**kw参数,kw将获得一个dict,注意kw获得的dict是extra的一份拷贝,对kw的改动不会影响到函数外的extra。
参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
参数组合
在Python中定义函数,可以用必选参数、默认参数、可变参数、关键字参数和命名关键字参数,这5种参数都可以组合使用。但是请注意,参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
比如定义一个函数,包含上述若干种参数:
def f1(a, b, c=0, *args, **kw):
print('a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw)
def f2(a, b, c=0, *, d, **kw):
print('a =', a, 'b =', b, 'c =', c, 'd =', d, 'kw =', kw)最神奇的是通过一个tuple和dict,你也可以调用上述函数:
>>> args = (1, 2, 3, 4)
>>> kw = {'d': 99, 'x': '#'}
>>> f1(*args, **kw)
a = 1 b = 2 c = 3 args = (4,) kw = {'d': 99, 'x': '#'}
>>> args = (1, 2, 3)
>>> kw = {'d': 88, 'x': '#'}
>>> f2(*args, **kw)
a = 1 b = 2 c = 3 d = 88 kw = {'x': '#'}所以,对于任意函数,都可以通过类似func(*args, **kw)的形式调用它,无论它的参数是如何定义的。
高级特性
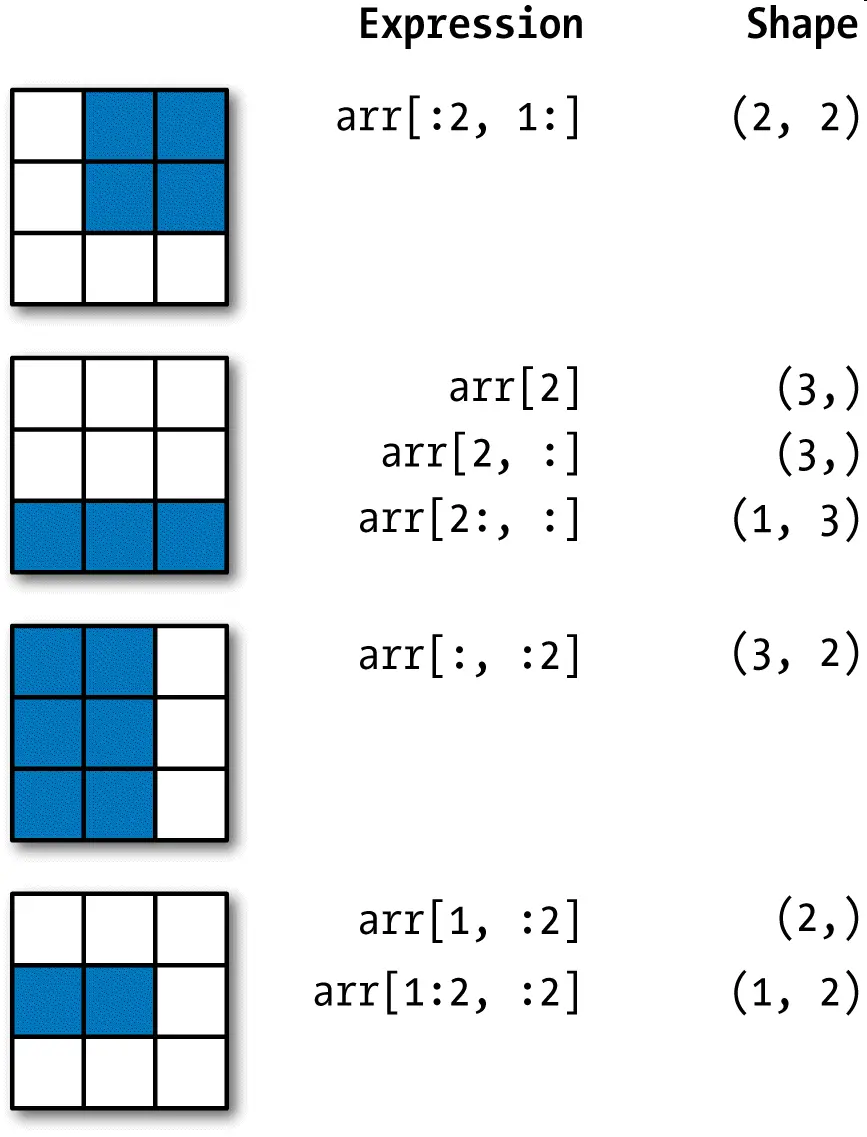
切片
L[0:3]表示,从索引0开始取,直到索引3为止,但不包括索引3。即索引0,1,2,正好是3个元素。
如果第一个索引是0,还可以省略:
>>> L[:3]
['Michael', 'Sarah', 'Tracy']也可以从索引1开始,取出2个元素出来:
>>> L[1:3]
['Sarah', 'Tracy']类似的,既然Python支持L[-1]取倒数第一个元素
利用切片操作,实现一个trim()函数,去除字符串首尾的空格,注意不要调用str的strip()方法:
def trim(s):
while s[:1] == ' ':
s = s[1:]
while s[-1:] == ' ':
s = s[:-1]
return s
##独特机制
s = ''
print(s[0]) # 会报错------IndexError: string index out of range
print(s[:1]) # 不会报错
s2 = s[:1] # 合法迭代
因为dict的存储不是按照list的方式顺序排列,所以,迭代出的结果顺序很可能不一样。
字典的迭代
默认情况下,dict迭代的是key。如果要迭代value,可以用for value in d.values(),如果要同时迭代key和value,可以用for k, v in d.items()。
判断一个对象是可迭代对象
方法是通过collections.abc模块的Iterable类型判断:
>>> from collections.abc import Iterable
>>> isinstance('abc', Iterable) # str是否可迭代实现下标循环
最后一个小问题,如果要对list实现类似Java那样的下标循环怎么办?Python内置的enumerate函数可以把一个list变成索引-元素对,这样就可以在for循环中同时迭代索引和元素本身:
>>> for i, value in enumerate(['A', 'B', 'C']):
... print(i, value)
...
0 A循环创建列表
这是因为for前面的部分是一个表达式,它必须根据x计算出一个结果。因此,考察表达式:x if x % 2 == 0,它无法根据x计算出结果,因为缺少else,必须加上else:
>>> [x if x % 2 == 0 else -x for x in range(1, 11)]
[-1, 2, -3, 4, -5, 6, -7, 8, -9, 10]上述for前面的表达式x if x % 2 == 0 else -x才能根据x计算出确定的结果。
可见,在一个列表生成式中,for前面的if ... else是表达式,而for后面的if是过滤条件,不能带else。
这里就是看需求了,你是需要使用数组里面每一个数(进行变换呢),还是需要使用数组里面的一些特殊的数字。
前者的话就把if else 写在for前面,后者的话就把这个写在后面
isinstance
判断类型
isinstance(x, str)生成器
\[\]列表
()生成器
注意,赋值语句:
a, b = b, a + b相当于:
t = (b, a + b) # t是一个tuple
a = t[0]
b = t[1]也就是说,上面的函数和generator仅一步之遥。要把fib函数变成generator函数,只需要把print(b)改为yield b就可以了:
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'调用该generator函数时,首先要生成一个generator对象,然后用next()函数不断获得下一个返回值:
>>> o = odd()
>>> next(o)
step 1
1
>>> next(o)
step 2
3
>>> next(o)
step 3
5
>>> next(o)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration请务必注意:调用generator函数会创建一个generator对象,多次调用generator函数会创建多个相互独立的generator。
迭代器
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
Python的for循环本质上就是通过不断调用next()函数实现的,例如:
for x in [1, 2, 3, 4, 5]:
pass实际上完全等价于:
# 首先获得Iterator对象:
it = iter([1, 2, 3, 4, 5])
# 循环:
while True:
try:
# 获得下一个值:
x = next(it)
except StopIteration:
# 遇到StopIteration就退出循环
break成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
>>> isinstance(iter([]), Iterator)
True
>>> isinstance(iter('abc'), Iterator)
True面向对象高级编程
使用元类
元类是更深层的魔术,99%的用户永远不必担心。如果您想知道是否需要它们,则不需要(实际上需要它们的人肯定会知道他们需要它们,并且不需要解释原因)。
错误
调试
断言
凡是用print()来辅助查看的地方,都可以用断言(assert)来替代:
def foo(s):
n = int(s)
assert n != 0, 'n is zero!'
return 10 / n
def main():
foo('0')assert的意思是,表达式n != 0应该是True,否则,根据程序运行的逻辑,后面的代码肯定会出错。
如果断言失败,assert语句本身就会抛出AssertionError:
$ python err.py
Traceback (most recent call last):
...
AssertionError: n is zero!
$ python -O err.py
Traceback (most recent call last):
...
ZeroDivisionError: division by zero注意:断言的开关"-O"是英文大写字母O,不是数字0。
关闭后,你可以把所有的assert语句当成pass来看。
读写
路径问题
文件路径不能用反斜杠'\'。举个例子,如果我传入的文件路径是这样的:
sys.path.append('c:\Users\mshacxiang\VScode_project\web_ddt')
则会报错SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: tr
原因分析:在windows系统当中读取文件路径可以使用,但是在python字符串中\有转义的含义,如\t可代表TAB,\n代表换行,所以我们需要采取一些方式使得\不被解读为转义字符。目前有3个解决方案
1、在路径前面加r,即保持字符原始值的意思。
sys.path.append(r'c:\Users\mshacxiang\VScode_project\web_ddt')
2、替换为双反斜杠
sys.path.append('c:\Users\mshacxiang\VScode_project\web_ddt')
3、替换为正斜杠
sys.path.append('c:/Users/mshacxiang/VScode_project/web_ddt')
numpy查缺补漏
灵魂四问
what
Python的面向数组计算可以追溯到1995年,Jim Hugunin创建了Numeric库。接下来的10年,许多科学编程社区纷纷开始使用Python的数组编程,但是进入21世纪,库的生态系统变得碎片化了。2005年,Travis Oliphant从Numeric和Numarray项目整了出了NumPy项目,进而所有社区都集合到了这个框架下。
why
- NumPy是在一个连续的内存块中存储数据,独立于其他Python内置对象。NumPy的C语言编写的算法库可以操作内存,而不必进行类型检查或其它前期工作。比起Python的内置序列,NumPy数组使用的内存更少。
- NumPy可以在整个数组上执行复杂的计算,而不需要Python的for循环。
where
- 用于数据整理和清理、子集构造和过滤、转换等快速的矢量化数组运算。
- 常用的数组算法,如排序、唯一化、集合运算等。
- 高效的描述统计和数据聚合/摘要运算。
- 用于异构数据集的合并/连接运算的数据对齐和关系型数据运算。
- 将条件逻辑表述为数组表达式(而不是带有if-elif-else分支的循环)。
- 数据的分组运算(聚合、转换、函数应用等)。。
数组
数组创建
python
In [37]: arr = np.array([1, 2, 3, 4, 5])
In [38]: arr.dtype
Out[38]: dtype('int64')
In [39]: float_arr = arr.astype(np.float64)
In [40]: float_arr.dtype
Out[40]: dtype('float64')
In [44]: numeric_strings = np.array(['1.25', '-9.6', '42'], dtype=np.string_)
In [45]: numeric_strings.astype(float)
Out[45]: array([ 1.25, -9.6 , 42. ])会新建一个的
使用numpy.string_类型时,一定要小心,因为NumPy的字符串数据是大小固定的,发生截取时,不会发出警告。pandas提供了更多非数值数据的便利的处理方法。
数组运算
矢量化(vectorization)------你不用编写循环即可对数据执行批量运算
跟列表最重要的区别在于,数组切片是原始数组的视图。这意味着数据不会被复制,视图上的任何修改都会直接反映到源数组上。
作为例子,先创建一个arr的切片:
python
In [66]: arr_slice = arr[5:8]
In [67]: arr_slice
Out[67]: array([12, 12, 12])现在,当我修改arr_slice中的值,变动也会体现在原始数组arr中:
python
In [68]: arr_slice[1] = 12345
In [69]: arr
Out[69]: array([ 0, 1, 2, 3, 4, 12, 12345, 12, 8,
9])切片 : 会给数组中的所有值赋值:
python
In [70]: arr_slice[:] = 64
In [71]: arr
Out[71]: array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])由于NumPy的设计目的是处理大数据,所以你可以想象一下,假如NumPy坚持要将数据复制来复制去的话会产生何等的性能和内存问题。
注意:如果你想要得到的是ndarray切片的一份副本而非视图,就需要明确地进行复制操作,例如arr[5:8].copy()。
切片
要选择除"Bob"以外的其他值,既可以使用不等于符号(!=),也可以通过~对条件进行否定:
python
In [106]: names != 'Bob'
Out[106]: array([False, True, True, False, True, True, True], dtype=bool)
In [107]: data[~(names == 'Bob')]
Out[107]:
array([[ 1.0072, -1.2962, 0.275 , 0.2289],
[ 1.3529, 0.8864, -2.0016, -0.3718],
[ 3.2489, -1.0212, -0.5771, 0.1241],
[ 0.3026, 0.5238, 0.0009, 1.3438],
[-0.7135, -0.8312, -2.3702, -1.8608]])~操作符用来反转条件很好用:
python
In [108]: cond = names == 'Bob'
In [109]: data[~cond]
Out[109]:
array([[ 1.0072, -1.2962, 0.275 , 0.2289],
[ 1.3529, 0.8864, -2.0016, -0.3718],
[ 3.2489, -1.0212, -0.5771, 0.1241],
[ 0.3026, 0.5238, 0.0009, 1.3438],
[-0.7135, -0.8312, -2.3702, -1.8608]])选取这三个名字中的两个需要组合应用多个布尔条件,使用&(和)、|(或)之类的布尔算术运算符即可:
python
In [110]: mask = (names == 'Bob') | (names == 'Will')
In [111]: mask
Out[111]: array([ True, False, True, True, True, False, False], dtype=bool)
In [112]: data[mask]
Out[112]:
array([[ 0.0929, 0.2817, 0.769 , 1.2464],
[ 1.3529, 0.8864, -2.0016, -0.3718],
[ 1.669 , -0.4386, -0.5397, 0.477 ],
[ 3.2489, -1.0212, -0.5771, 0.1241]])通过布尔型索引选取数组中的数据,将总是创建数据的副本,即使返回一模一样的数组也是如此。
注意:Python关键字and和or在布尔型数组中无效。要使用&与|。
花式索引
最终选出的是元素(1,0)、(5,3)、(7,1)和(2,2)。无论花式索引的数组是多少维,索引得到的结果都是一维的。
这个花式索引的行为可能会跟某些用户的预期不一样(包括我在内),选取矩阵的行列子集应该是矩形区域的形式才对。下面是得到该结果的一个办法:
python
In [125]: arr[[1, 5, 7, 2]][:, [0, 3, 1, 2]]
Out[125]:
array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]])记住,花式索引跟切片不一样,它总是将数据复制到新数组中。
数组转置和轴对换
在进行矩阵计算时,经常需要用到该操作,比如利用np.dot计算矩阵内积:
python
In [129]: arr = np.random.randn(6, 3)
In [130]: arr
Out[130]:
array([[-0.8608, 0.5601, -1.2659],
[ 0.1198, -1.0635, 0.3329],
[-2.3594, -0.1995, -1.542 ],
[-0.9707, -1.307 , 0.2863],
[ 0.378 , -0.7539, 0.3313],
[ 1.3497, 0.0699, 0.2467]])
In [131]: np.dot(arr.T, arr)
Out[131]:
array([[ 9.2291, 0.9394, 4.948 ],
[ 0.9394, 3.7662, -1.3622],
[ 4.948 , -1.3622, 4.3437]])对于高维数组,transpose需要得到一个由轴编号组成的元组才能对这些轴进行转置(比较费脑子):
python
In [132]: arr = np.arange(16).reshape((2, 2, 4))
In [133]: arr
Out[133]:
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7]],
[[ 8, 9, 10, 11],
[12, 13, 14, 15]]])
In [134]: arr.transpose((1, 0, 2))
Out[134]:
array([[[ 0, 1, 2, 3],
[ 8, 9, 10, 11]],
[[ 4, 5, 6, 7],
[12, 13, 14, 15]]])这里,第一个轴 0 被换成了第二个 1,第二个轴 1被换成了第一个 0,最后一个轴不变2 2。
函数
通用函数(即ufunc)是一种对ndarray中的数据执行元素级运算的函数。你可以将其看做简单函数(接受一个或多个标量值,并产生一个或多个标量值)的矢量化包装器。



将条件逻辑表述为数组运算
numpy.where函数是三元表达式x if condition else y的矢量化版本。假设我们有一个布尔数组和两个值数组:
python
In [165]: xarr = np.array([1.1, 1.2, 1.3, 1.4, 1.5])
In [166]: yarr = np.array([2.1, 2.2, 2.3, 2.4, 2.5])
In [167]: cond = np.array([True, False, True, True, False])假设我们想要根据cond中的值选取xarr和yarr的值:当cond中的值为True时,选取xarr的值,否则从yarr中选取。列表推导式的写法应该如下所示:
python
In [168]: result = [(x if c else y)
.....: for x, y, c in zip(xarr, yarr, cond)]
In [169]: result
Out[169]: [1.1000000000000001, 2.2000000000000002, 1.3, 1.3999999999999999, 2.5]这有几个问题。第一,它对大数组的处理速度不是很快(因为所有工作都是由纯Python完成的)。第二,无法用于多维数组。若使用np.where,则可以将该功能写得非常简洁:
python
In [170]: result = np.where(cond, xarr, yarr)
In [171]: result
Out[171]: array([ 1.1, 2.2, 1.3, 1.4, 2.5])np.where的第二个和第三个参数不必是数组,它们都可以是标量值。在数据分析工作中,where通常用于根据另一个数组而产生一个新的数组。假设有一个由随机数据组成的矩阵,你希望将所有正值替换为2,将所有负值替换为-2。若利用np.where,则会非常简单:
python
In [172]: arr = np.random.randn(4, 4)
In [173]: arr
Out[173]:
array([[-0.5031, -0.6223, -0.9212, -0.7262],
[ 0.2229, 0.0513, -1.1577, 0.8167],
[ 0.4336, 1.0107, 1.8249, -0.9975],
[ 0.8506, -0.1316, 0.9124, 0.1882]])
In [174]: arr > 0
Out[174]:
array([[False, False, False, False],
[ True, True, False, True],
[ True, True, True, False],
[ True, False, True, True]], dtype=bool)
In [175]: np.where(arr > 0, 2, -2)
Out[175]:
array([[-2, -2, -2, -2],
[ 2, 2, -2, 2],
[ 2, 2, 2, -2],
[ 2, -2, 2, 2]])使用np.where,可以将标量和数组结合起来。例如,我可用常数2替换arr中所有正的值:
python
In [176]: np.where(arr > 0, 2, arr) # set only positive values to 2
Out[176]:
array([[-0.5031, -0.6223, -0.9212, -0.7262],
[ 2. , 2. , -1.1577, 2. ],
[ 2. , 2. , 2. , -0.9975],
[ 2. , -0.1316, 2. , 2. ]])传递给where的数组大小可以不相等,甚至可以是标量值。
数学和统计方法
sum、mean以及标准差std等聚合计算(aggregation,通常叫做约简(reduction)
这里,arr.mean(1)是"计算行的平均值",arr.sum(0)是"计算每列的和"。


布尔数组
python
In [211]: values = np.array([6, 0, 0, 3, 2, 5, 6])
In [212]: np.in1d(values, [2, 3, 6])
Out[212]: array([ True, False, False, True, True, False, True], dtype=bool)
用于数组的文件输入输出
NumPy能够读写磁盘上的文本数据或二进制数据。这一小节只讨论NumPy的内置二进制格式,因为更多的用户会使用pandas或其它工具加载文本或表格数据(见第6章)。
np.save和np.load是读写磁盘数组数据的两个主要函数。默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为.npy的文件中的:
python
In [213]: arr = np.arange(10)
In [214]: np.save('some_array', arr)如果文件路径末尾没有扩展名.npy,则该扩展名会被自动加上。然后就可以通过np.load读取磁盘上的数组:
python
In [215]: np.load('some_array.npy')
Out[215]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])通过np.savez可以将多个数组保存到一个未压缩文件中,将数组以关键字参数的形式传入即可:
python
In [216]: np.savez('array_archive.npz', a=arr, b=arr)加载.npz文件时,你会得到一个类似字典的对象,该对象会对各个数组进行延迟加载:
python
In [217]: arch = np.load('array_archive.npz')
In [218]: arch['b']
Out[218]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])如果要将数据压缩,可以使用numpy.savez_compressed:
python
In [219]: np.savez_compressed('arrays_compressed.npz', a=arr, b=arr)线性代数
线性代数(如矩阵乘法、矩阵分解、行列式以及其他方阵数学等)是任何数组库的重要组成部分。不像某些语言(如MATLAB),通过*对两个二维数组相乘得到的是一个元素级的积,而不是一个矩阵点积。因此,NumPy提供了一个用于矩阵乘法的dot函数(既是一个数组方法也是numpy命名空间中的一个函数):
python
In [223]: x = np.array([[1., 2., 3.], [4., 5., 6.]])
In [224]: y = np.array([[6., 23.], [-1, 7], [8, 9]])
In [225]: x
Out[225]:
array([[ 1., 2., 3.],
[ 4., 5., 6.]])
In [226]: y
Out[226]:
array([[ 6., 23.],
[ -1., 7.],
[ 8., 9.]])
In [227]: x.dot(y)
Out[227]:
array([[ 28., 64.],
[ 67., 181.]])x.dot(y)等价于np.dot(x, y):
python
In [228]: np.dot(x, y)
Out[228]:
array([[ 28., 64.],
[ 67., 181.]])一个二维数组跟一个大小合适的一维数组的矩阵点积运算之后将会得到一个一维数组:
python
In [229]: np.dot(x, np.ones(3))
Out[229]: array([ 6., 15.])@符(类似Python 3.5)也可以用作中缀运算符,进行矩阵乘法:
python
In [230]: x @ np.ones(3)
Out[230]: array([ 6., 15.])numpy.linalg中有一组标准的矩阵分解运算以及诸如求逆和行列式之类的东西。它们跟MATLAB和R等语言所使用的是相同的行业标准线性代数库,如BLAS、LAPACK、Intel MKL(Math Kernel Library,可能有,取决于你的NumPy版本)等:
python
In [231]: from numpy.linalg import inv, qr
In [232]: X = np.random.randn(5, 5)
In [233]: mat = X.T.dot(X)
In [234]: inv(mat)
Out[234]:
array([[ 933.1189, 871.8258, -1417.6902, -1460.4005, 1782.1391],
[ 871.8258, 815.3929, -1325.9965, -1365.9242, 1666.9347],
[-1417.6902, -1325.9965, 2158.4424, 2222.0191, -2711.6822],
[-1460.4005, -1365.9242, 2222.0191, 2289.0575, -2793.422 ],
[ 1782.1391, 1666.9347, -2711.6822, -2793.422 , 3409.5128]])
In [235]: mat.dot(inv(mat))
Out[235]:
array([[ 1., 0., -0., -0., -0.],
[-0., 1., 0., 0., 0.],
[ 0., 0., 1., 0., 0.],
[-0., 0., 0., 1., -0.],
[-0., 0., 0., 0., 1.]])
In [236]: q, r = qr(mat)
In [237]: r
Out[237]:
array([[-1.6914, 4.38 , 0.1757, 0.4075, -0.7838],
[ 0. , -2.6436, 0.1939, -3.072 , -1.0702],
[ 0. , 0. , -0.8138, 1.5414, 0.6155],
[ 0. , 0. , 0. , -2.6445, -2.1669],
[ 0. , 0. , 0. , 0. , 0.0002]])表达式X.T.dot(X)计算X和它的转置X.T的点积。
表4-7中列出了一些最常用的线性代数函数。

伪随机数生成
numpy.random模块对Python内置的random进行了补充,增加了一些用于高效生成多种概率分布的样本值的函数。例如,你可以用normal来得到一个标准正态分布的4×4样本数组:
python
In [238]: samples = np.random.normal(size=(4, 4))
In [239]: samples
Out[239]:
array([[ 0.5732, 0.1933, 0.4429, 1.2796],
[ 0.575 , 0.4339, -0.7658, -1.237 ],
[-0.5367, 1.8545, -0.92 , -0.1082],
[ 0.1525, 0.9435, -1.0953, -0.144 ]])而Python内置的random模块则只能一次生成一个样本值。从下面的测试结果中可以看出,如果需要产生大量样本值,numpy.random快了不止一个数量级:
python
In [240]: from random import normalvariate
In [241]: N = 1000000
In [242]: %timeit samples = [normalvariate(0, 1) for _ in range(N)]
1.77 s +- 126 ms per loop (mean +- std. dev. of 7 runs, 1 loop each)
In [243]: %timeit np.random.normal(size=N)
61.7 ms +- 1.32 ms per loop (mean +- std. dev. of 7 runs, 10 loops each)我们说这些都是伪随机数,是因为它们都是通过算法基于随机数生成器种子,在确定性的条件下生成的。你可以用NumPy的np.random.seed更改随机数生成种子:
python
In [244]: np.random.seed(1234)numpy.random的数据生成函数使用了全局的随机种子。要避免全局状态,你可以使用numpy.random.RandomState,创建一个与其它隔离的随机数生成器:
python
In [245]: rng = np.random.RandomState(1234)
In [246]: rng.randn(10)
Out[246]:
array([ 0.4714, -1.191 , 1.4327, -0.3127, -0.7206, 0.8872, 0.8596,
-0.6365, 0.0157, -2.2427])表4-8列出了numpy.random中的部分函数。在下一节中,我将给出一些利用这些函数一次性生成大量样本值的范例。


示例:随机漫步
我们通过模拟随机漫步来说明如何运用数组运算。先来看一个简单的随机漫步的例子:从0开始,步长1和-1出现的概率相等。
下面是一个通过内置的random模块以纯Python的方式实现1000步的随机漫步:
python
In [247]: import random
.....: position = 0
.....: walk = [position]
.....: steps = 1000
.....: for i in range(steps):
.....: step = 1 if random.randint(0, 1) else -1
.....: position += step
.....: walk.append(position)
.....:图4-4是根据前100个随机漫步值生成的折线图:
python
In [249]: plt.plot(walk[:100])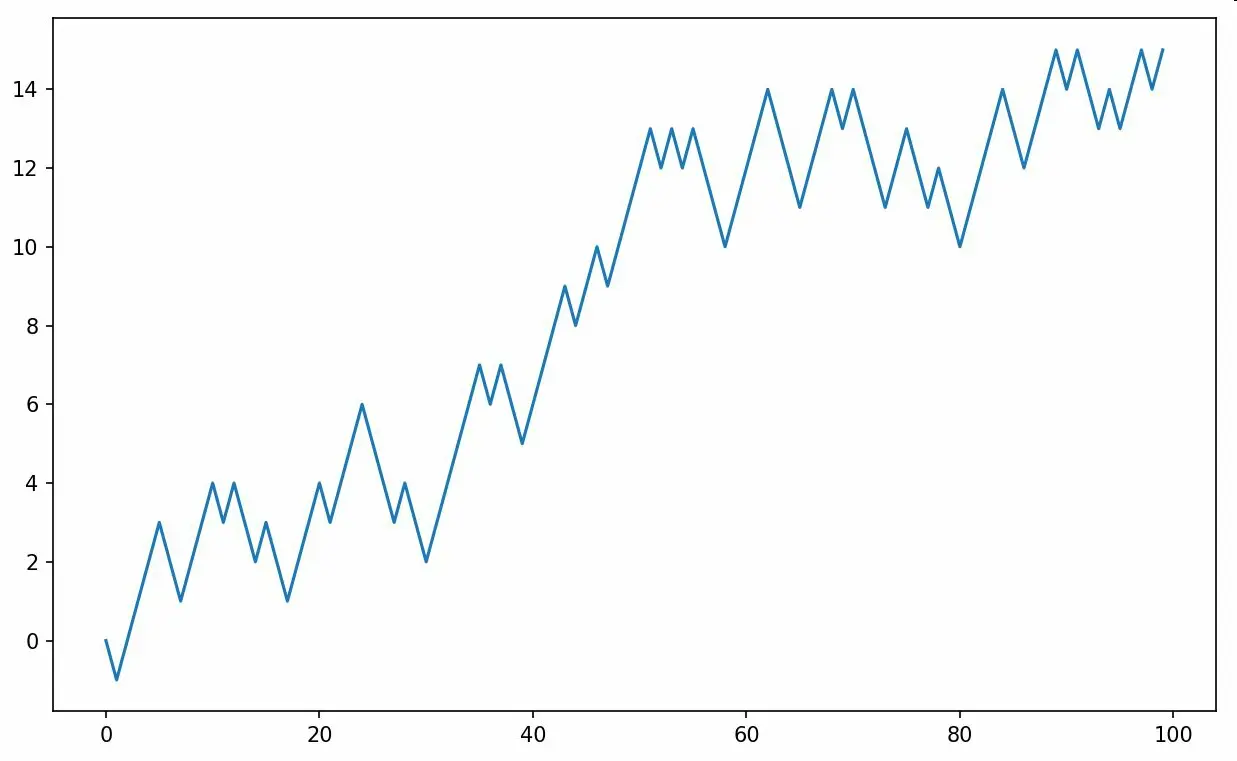
不难看出,这其实就是随机漫步中各步的累计和,可以用一个数组运算来实现。因此,我用np.random模块一次性随机产生1000个"掷硬币"结果(即两个数中任选一个),将其分别设置为1或-1,然后计算累计和:
python
In [251]: nsteps = 1000
In [252]: draws = np.random.randint(0, 2, size=nsteps)
In [253]: steps = np.where(draws > 0, 1, -1)
In [254]: walk = steps.cumsum()有了这些数据之后,我们就可以沿着漫步路径做一些统计工作了,比如求取最大值和最小值:
python
In [255]: walk.min()
Out[255]: -3
In [256]: walk.max()
Out[256]: 31现在来看一个复杂点的统计任务------首次穿越时间,即随机漫步过程中第一次到达某个特定值的时间。假设我们想要知道本次随机漫步需要多久才能距离初始0点至少10步远(任一方向均可)。np.abs(walk)>=10可以得到一个布尔型数组,它表示的是距离是否达到或超过10,而我们想要知道的是第一个10或-10的索引。可以用argmax来解决这个问题,它返回的是该布尔型数组第一个最大值的索引(True就是最大值):
python
In [257]: (np.abs(walk) >= 10).argmax()
Out[257]: 37注意,这里使用argmax并不是很高效,因为它无论如何都会对数组进行完全扫描。在本例中,只要发现了一个True,那我们就知道它是个最大值了。
一次模拟多个随机漫步
如果你希望模拟多个随机漫步过程(比如5000个),只需对上面的代码做一点点修改即可生成所有的随机漫步过程。只要给numpy.random的函数传入一个二元元组就可以产生一个二维数组,然后我们就可以一次性计算5000个随机漫步过程(一行一个)的累计和了:
python
In [258]: nwalks = 5000
In [259]: nsteps = 1000
In [260]: draws = np.random.randint(0, 2, size=(nwalks, nsteps)) # 0 or 1
In [261]: steps = np.where(draws > 0, 1, -1)
In [262]: walks = steps.cumsum(1)
In [263]: walks
Out[263]:
array([[ 1, 0, 1, ..., 8, 7, 8],
[ 1, 0, -1, ..., 34, 33, 32],
[ 1, 0, -1, ..., 4, 5, 4],
...,
[ 1, 2, 1, ..., 24, 25, 26],
[ 1, 2, 3, ..., 14, 13, 14],
[ -1, -2, -3, ..., -24, -23, -22]])现在,我们来计算所有随机漫步过程的最大值和最小值:
python
In [264]: walks.max()
Out[264]: 138
In [265]: walks.min()
Out[265]: -133得到这些数据之后,我们来计算30或-30的最小穿越时间。这里稍微复杂些,因为不是5000个过程都到达了30。我们可以用any方法来对此进行检查:
python
In [266]: hits30 = (np.abs(walks) >= 30).any(1)
In [267]: hits30
Out[267]: array([False, True, False, ..., False, True, False], dtype=bool)
In [268]: hits30.sum() # Number that hit 30 or -30
Out[268]: 3410然后我们利用这个布尔型数组选出那些穿越了30(绝对值)的随机漫步(行),并调用argmax在轴1上获取穿越时间:
python
In [269]: crossing_times = (np.abs(walks[hits30]) >= 30).argmax(1)
In [270]: crossing_times.mean()
Out[270]: 498.88973607038122请尝试用其他分布方式得到漫步数据。只需使用不同的随机数生成函数即可,如normal用于生成指定均值和标准差的正态分布数据:
python
In [271]: steps = np.random.normal(loc=0, scale=0.25,
.....: size=(nwalks, nsteps))