一直对LLaMA 名下的各个模型关系搞不清楚,什么羊驼、考拉的,不知所以。幸好看到两篇综述,有个大致了解,以及SEBASTIAN RASCHKA对LLaMa 3的介绍。做一个记录。
一、文章《Large Language Models: A Survey》中对LLaMa的介绍
论文:Large Language Models: A Survey
https://arxiv.org/html/2402.06196v2
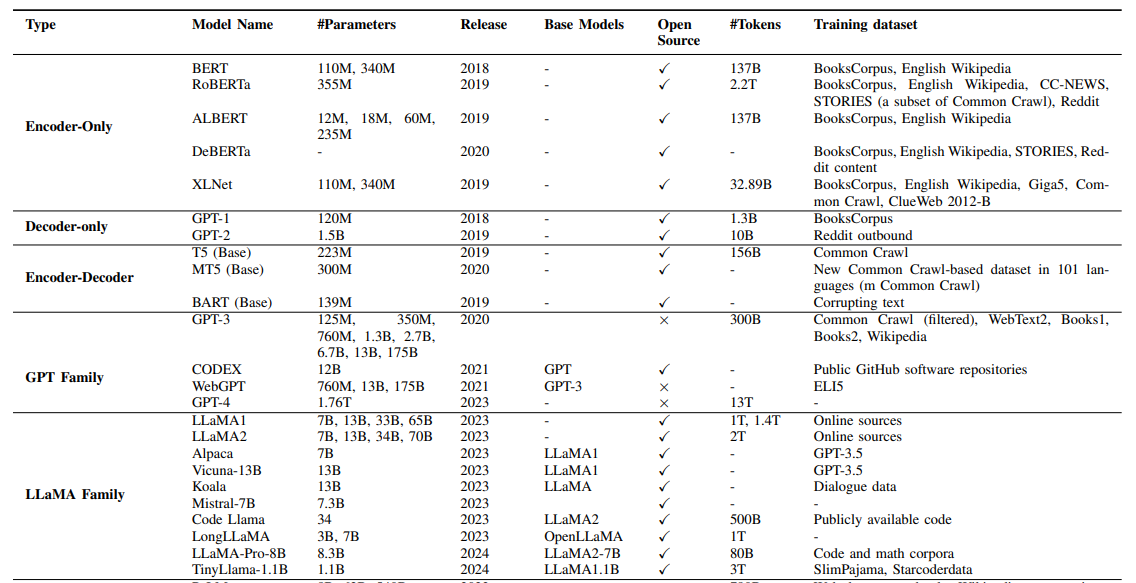
LLaMA家族
LLaMA 是 Meta 发布的基础语言模型集合。 与 GPT 模型不同,LLaMA 模型是开源的,即模型权重在非商业许可下发布给研究社区。 因此,LLaMA 系列迅速发展,因为这些模型被许多研究小组广泛使用,以开发更好的开源 LLM 以竞争闭源 LLM,或为关键任务应用程序开发特定任务的 LLM。
LLaMA的第一组模型于2023年2月发布,参数范围从7B到65B。这些模型是在公开可用数据集收集的数万亿个token上预训练的。LLaMA使用GPT-3的Transformer架构,但有一些小的架构修改,包括(1)使用SwiGLU激活函数代替ReLU,(2)使用旋转位置嵌入代替绝对位置嵌入,以及(3)使用均方根层归一化(root-mean-squared layer-normalization )代替标准层归一化。
开源 LLaMA-13B 模型在大多数基准测试中优于专有的 GPT-3 (175B) 模型,使其成为 LLM 研究的良好基线。
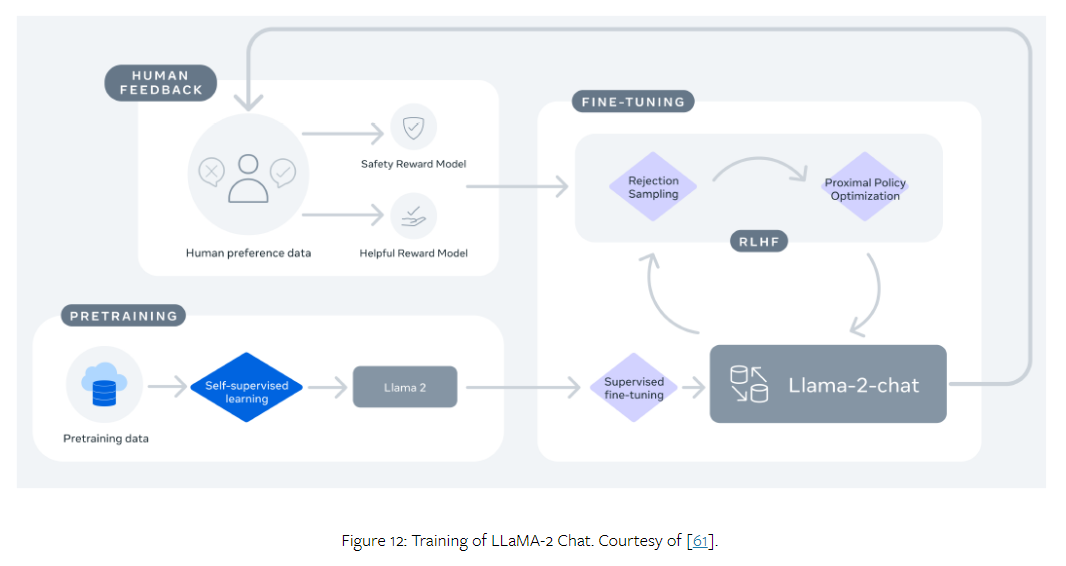
2023年7月,Meta与Microsoft合作发布了LLaMA-2系列,其中包括基础语言模型和针对对话进行微调的Chat模型,称为LLaMA-2 Chat。LLaMA-2 Chat模型在许多公共基准测试中的表现超过了其他开源模型。图12展示了LLaMA-2 Chat的训练过程。该过程首先使用公开可用的在线数据预训练LLaMA-2。然后,通过监督微调构建LLaMA-2 Chat的初始版本。随后,模型使用RLHF、拒绝采样和近端策略优化(rejection
sampling and proximal policy optimization)进行迭代细化。在RLHF阶段,积累人类反馈以修订奖励模型至关重要,以防止奖励模型发生太大变化,这可能会损害LLaMA模型训练的稳定性。
Alpaca是从LLaMA-7B模型微调而来,使用了52K条遵循指令的示例,这些示例以自我指导(self-instruct)的方式使用GPT-3.5(text-davinci-003)生成。Alpaca在训练上非常划算,特别是对于学术研究。在自我指导评估集上,Alpaca的表现与GPT-3.5相似,尽管Alpaca要小得多。
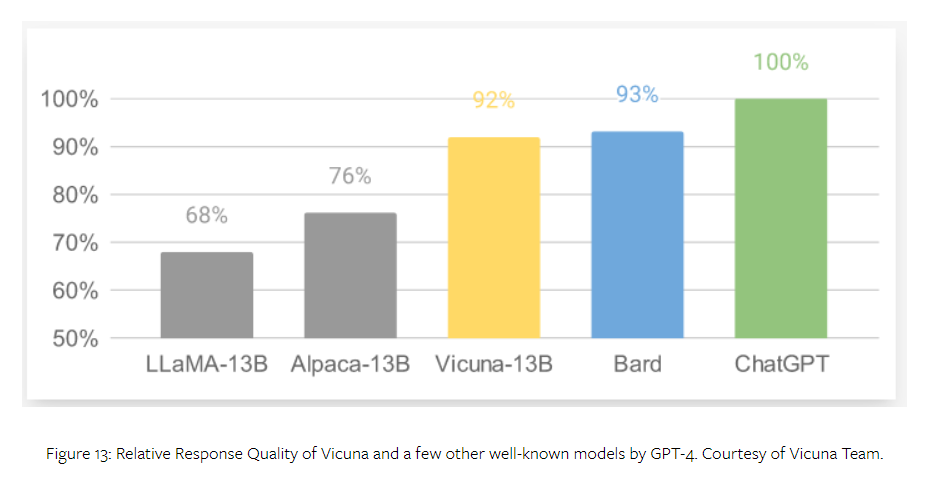
Vicuna团队通过在ShareGPT上收集的用户共享对话对LLaMA进行微调,开发了一个13B的聊天模型,Vicuna-13B。使用GPT-4作为评估者进行初步评估表明,Vicuna-13B在超过90%的情况下实现了与OpenAI的ChatGPT和Google的Bard相似的质量,并且在超过90%的情况下优于其他模型,如LLaMA和Stanford Alpaca。图13通过GPT-4展示了Vicuna和其他一些知名模型的相对响应质量。Vicuna-13B的另一个优势是其相对有限的模型训练计算需求。Vicuna-13B的训练成本仅为300美元。
像Alpaca和Vicuna一样,Guanaco模型也是使用指令跟随数据对LLaMA进行微调的模型。但是,微调是通过QLoRA非常高效地完成的,以至于可以在单个48GB GPU上微调一个65B参数的模型。QLoRA通过冻结的4位量化预训练语言模型将梯度反向传播到低秩适配器(LoRA)中。最佳Guanaco模型在Vicuna基准测试上的表现超过了所有以前发布的模型,达到了ChatGPT性能水平的99.3%,同时仅需要在单个GPU上微调24小时。
Koala是另一个建立在LLaMA上的指令跟随语言模型,但专注于交互数据,包括用户输入和由高度能力的封闭源聊天模型(如ChatGPT)生成的响应。根据基于真实用户提示的人工评估,Koala-13B模型与最先进的聊天模型具有竞争力。
Mistral-7B是一个为卓越性能和效率而设计的7B参数语言模型。Mistral-7B在所有评估的基准测试中都优于最佳的开源13B模型(LLaMA-2-13B),在推理、数学和代码生成方面优于最佳的开源34B模型(LLaMA-34B)。该模型利用分组查询注意力实现更快的推理,结合滑动窗口注意力以有效处理任意长度的序列,降低推理成本。
LLaMA家族正在迅速发展,因为更多的指令跟随模型已经建立在LLaMA或LLaMA-2之上,包括Code LLaMA、Gorilla、Giraffe、Vigogne、Tulu 65B、Long LLaMA和Stable Beluga2,仅举几例。
二、《大语言模型》中对LLaMa的介绍
来自《大语言模型》一书(赵鑫 李军毅 周昆 唐天一 文继荣 著),
LLaMA 变体系列
自 2023 年 2 月发布以来,LLaMA 系列模型在学术界和工业界引起了广泛的关注,对于推动大语言模型技术的开源发展做出了重要贡献。
LLaMA 拥有较优的模型性能,并方便用户公开获取,因此一经推出就迅速成为了最受欢迎的开放性语言模型之一。众多研究人员纷纷通过指令微调或继续预训练等方法来进一步扩展 LLaMA 模型的功能和应用范围。其中,指令微调由于相对较低的计算成本,已成为开发定制化或专业化模型的首选方法,也因此出现了庞大的 LLaMA 家族。根据指令微调所使用的指令类型,对现有的 LLaMA 变体模型进行简单的梳理介绍。
• 基础指令 . 在 LLaMA 的扩展模型中,Stanford Alpaca 是第一个基于LLaMA (7B) 进行微调的开放式指令遵循模型。通过使用 Self-Instruct 方法借助大语言模型进行自动化的指令生成,Stanford Alpaca 生成了 52K 条指令遵循样例数据(Alpaca-52K)用于训练,其指令数据和训练代码在随后的工作中被广泛采用。Vicuna作为另一个流行的 LLaMA 变种,也受到了广泛关注。它并没有使用合成指令数据,主要是使用 ShareGPT 收集的用户日常对话数据进行训练,展现了基于 LLaMA 的语言模型在对话生成任务中的优秀实力。
• 中文指令 . 原始的 LLaMA 模型的训练语料主要以英语为主,在中文任务上的表现比较一般。为了使 LLaMA 模型能够有效地支持中文,研究人员通常会选择扩展原始词汇表,在中文数据上进行继续预训练,并用中文指令数据对其进行微调。经过中文数据的训练,这些扩展模型不仅能更好地处理中文任务,在跨语言处理任务中也展现出了强大的潜力。目前常见的中文大语言模型有 Chinese LLaMA、Panda、Open-Chinese-LLaMA、Chinese Alpaca、YuLan-Chat 等。
• 垂域指令 . LLaMA 虽然展现出了强大的通用基座模型能力,但是在特定的垂直领域(例如医学、教育、法律、数学等)的表现仍然较为局限。为了增强 LLaMA模型的垂域能力,很多工作基于搜集到的垂域相关的指令数据,或者采用垂域知识库以及相关专业文献等借助强大的闭源模型 API(例如 GPT-3.5、GPT-4 等)构建多轮对话数据,并使用这些指令数据对 LLaMA 进行指令微调。常见的垂域 LLaMA模型有 BenTsao(医学)、LAWGPT(法律)、TaoLi(教育)、Goat(数学)、Comucopia(金融)等。
• 多模态指令 . 由于 LLaMA 模型作为纯语言模型的强大能力,许多的多模态模型都将其(或将其衍生模型)作为基础语言模型,搭配视觉模态的编码器,使用多模态指令对齐视觉表征与文本。与其他语言模型相比,Vicuna 在多模态语言模型中受到了更多的关注,由此形成了一系列基于 Vicuna 的多模态模型,包括LLaVA 、MiniGPT4 、InstructBLIP 和 PandaGPT 。
除了使用不同种类的指令数据进行全参数微调外,研发人员还经常使用轻量化微调的技术训练 LLaMA 模型变体,以降低训练成本,方便用户部署。例如,AlpacaLoRA 使用 LoRA 复现了 Stanford Alpaca。LLaMA 模型系列的发布有力地推动了大语言模型技术的发展。为了更直观地展示 LLaMA 系列模型的研究进展以及衍生模型之间的关系,下图展示了一个 LLaMA 系列模型的简要演化图,
呈现了 LLaMA 模型系列从发布到快速发展以及在各个领域中的广泛应用。由于衍生模型的数量庞大,这里无法将所有相关模型纳入到图中。

三、SEBASTIAN RASCHKA对LLaMa 3的介绍
来自SEBASTIAN RASCHKA的博客文章《How Good Are the Latest Open LLMs? And Is DPO Better Than PPO?》
LLaMa 3: Larger data is better
Meta AI 于 2023 年 2 月发布了第一个 Llama 模型,这是公开可用的 LLM 的一大突破,也是开放(源代码)LLM 的关键时刻。因此,自然而然地,每个人都对去年发布的 Llama 2 感到兴奋。现在,Meta AI 已经开始推出的 Llama 3 模型同样令人兴奋。
虽然 Meta 仍在训练一些最大的模型(例如 400B 变体),但他们发布了熟悉的 8B 和 70B 尺寸范围的模型。下图将官方 Llama 3 博客文章中的 MMLU 分数添加到之前分享的 Mixtral 图中。
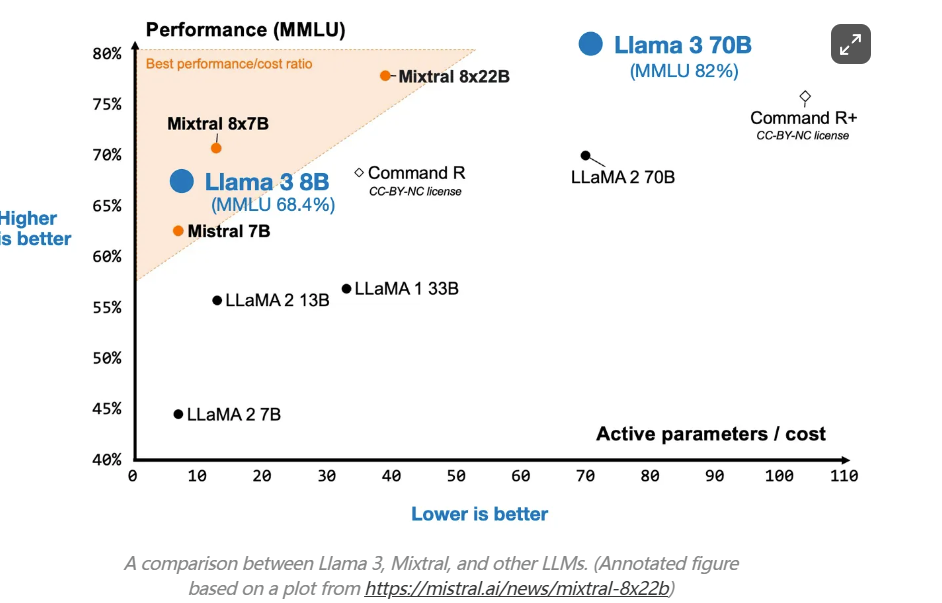
总体而言,Llama 3 架构与 Llama 2 几乎相同。主要区别在于词汇量增加,以及 Llama 3 还对较小规模的模型使用分组查询注意力。
以下是用于在 LitGPT 中实现 Llama 2 和 Llama 3 的配置文件,有助于一目了然地显示主要区别。

训练数据大小
与 Llama 2 相比,性能明显提高的主要原因是数据集要大得多。Llama 3 的训练是用 15 万亿个Token训练的,而 Llama 2 "只有"2 万亿个Token。
这是一个非常有趣的发现,因为正如 Llama 3 博客文章所指出的那样,根据 Chinchilla 缩放定律,80 亿参数模型的最佳训练数据量要小得多,大约 2000 亿个Token。此外,Llama 3 的作者观察到,即使在 15 万亿尺度上,80 亿和 700 亿参数模型也表现出对数线性改进。这表明我们(即一般的研究人员)可以通过超过 15 万亿个Token的更多训练数据来进一步增强模型。
指令微调和对齐
对于指令微调和对齐,研究人员通常选择通过近端策略优化 (PPO) 或无奖励模型的直接偏好优化 (DPO) 使用具有人工反馈的强化学习 (RLHF)。有趣的是,Llama 3 的研究人员并没有偏爱其中一种;他们两者都用了!