🧑💻作者: @情话0.0
📝专栏:《Linux从入门到放弃》
👦个人简介:一名双非编程菜鸟,在这里分享自己的编程学习笔记,欢迎大家的指正与点赞,谢谢!

进程地址空间
- 前言
- 一、地址空间
-
- [1.1 地址空间的问题引入](#1.1 地址空间的问题引入)
- [1.2 什么是地址空间?](#1.2 什么是地址空间?)
- [1.3 地址空间、物理内存的关系](#1.3 地址空间、物理内存的关系)
- 二、地址空间的意义
-
- [2.1 防止地址随意访问,保护物理内存与其他进程](#2.1 防止地址随意访问,保护物理内存与其他进程)
- [2.2 将进程管理和内存管理进行解耦合](#2.2 将进程管理和内存管理进行解耦合)
- [2.3 让进程以统一的视角看待自己的代码和数据](#2.3 让进程以统一的视角看待自己的代码和数据)
- [扩展1 malloc的本质](#扩展1 malloc的本质)
- [扩展2 重新理解地址空间](#扩展2 重新理解地址空间)
- 总结
前言
在之前的学习当中,我们肯定关于数据的存储有一定的了解,比如全局变量应该存储在什么位置,动态申请的空间又在什么位置等等。此篇博客就关于在Linux环境中对地址空间作以详细讲解。
下图我们之前学习C语言应该了解的空间布局图,那么有一个问题:这块空间是不是我们所说的内存呢?带着这个问题进入到此篇博客中。
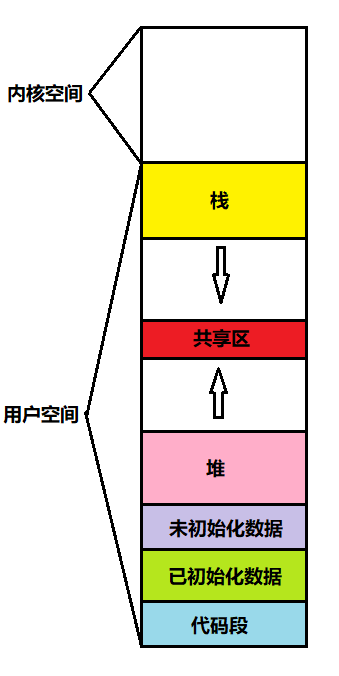
一、地址空间
1.1 地址空间的问题引入
关于进程地址空间的学习我们先看一段代码:有一个全局变量num,通过fork创建子进程,在父子进程打印全局变量以及它的地址,在父进程里5秒之后对这个全局变量进行修改。
cpp
int num=10;
int main()
{
int id=fork();
assert(id>=0);
if(id==0)
{
//子进程
while(1)
{
printf("i am child,num:%d,&num:%p\n",num,&num);
sleep(1);
}
}
else
{
//父进程
int cnt=5;
while(1)
{
printf("i am father,num:%d,&num:%p\n",num,&num);
if(--cnt==0)
num=20;
sleep(1);
}
}
return 0;
}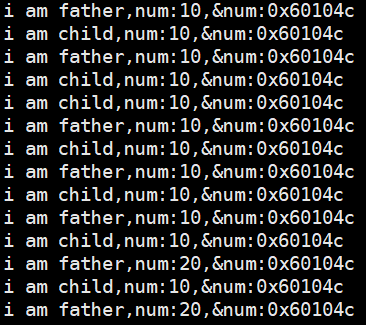
父进程对全局数据做修改,并不会影响子进程,这是因为进程具有独立性,而进程的概念是内核数据结构+代码和数据,其实在数据修改的时候发生了写时拷贝。
通过这段代码的运行结果可以发现:五秒之前,父子进程的num值都是10,当然对应的数据地址也是一样的,但是在5秒之后,父进程的num值发生了改变,可是奇怪的是num对应的地址怎么还是一样的,怎么在同一份地址空间里存放着不同的数据呢?这些显然不可能。
这也就说明了这里打印出来的地址并不是物理地址,它的名字而是虚拟地址或者线性地址。
1.2 什么是地址空间?
* 先讲个小故事,从前有一个大富豪,可谓是富甲一方,假设说有RMB十个亿,一个人有了钱就容易花天酒地,于是就有了好几个私生子,但是这个孩子都是生活在不同的地方,彼此并不知道对方的存在。这个富豪就给这几个孩子说等我到时候没了,我的这些资产都是你的。如果这几个孩子给他老爸要上个几千几万,这个富豪肯定就毫不犹豫地给了,但要是说:"老爸,给我五个亿,我想自己创业办个公司",这种情况富豪肯定是不会将钱给他孩子的。
可以这么说,这个富豪给他每个孩子的承诺将相当于是在画饼,而这个饼就是进程地址空间,大富豪是操作系统,资产是内存,那这几个私生子是进程。*
对于大富豪来说,他给每个孩子画着不同的饼,那么他就应该将这些"饼"管理起来,以便以后更好的去给孩子画饼。而管理的方式就是先描述,再组织。
而饼的本质就是一个内核数据结构,是一个struct mm_struct{}这样的一个结构体。
每当创建了一个进程,相应也会有自己的独一份内核数据结构,进程就会通过一个指针指向这块结构体,对于我们来说看到的"内存地址"其实是这个进程地址空间的某一位的地址---虚拟地址。
- 说到三八线我想每一个人都不陌生,可能我们每个人小的时候都和同桌在课桌上画过这样的线,我们当时画三八线的初衷肯定就是限定对方的活动区域,其本质就是区域划分。那在计算机里对一线性区域进行划分指定好区域空间的起始处和终止处即可完成区域的划分。
- 地址空间的本质就是线性区域,我们考虑在32位计算机环境下,地址空间的地址大小是从全0到全F(16进制)的,整个地址空间是以一个字节为最小单位划分的。 之所以称这段空间为线性区域是因为地址是线性的,若是十进制的话就是从0到42亿多。
如果说我们定义一个int类型的数据,在地址空间就会占四个字节,按道理来说我们应该有四个地址,但是当对这个变量取地址时就会发现拿到的只是这段空间的起始地址,那仅仅通过这一个地址怎能将本来四个字节所存放的数据拿到呢?其实除了起始地址之外,还有就是这个数据的类型起到关键的作用。
- 从最上面的图可以看到,地址空间被划分成了一个个小的区域,这些区域的起始地址和终止地址会存放到mm_struct结构体中,通过这一对一对的地址将地址空间进行了划分。
- 如果通过一对对的地址限定了区域,那么这段区域中间存放的是什么东西呢?虚拟地址。
- 区域的大小调整的本质就是对起始地址和终止地址大小的调整。
1.3 地址空间、物理内存的关系
我们所看到的地址其实是虚拟地址,而真正的数据是存放在物理内存中的,既然我们能够从这个虚拟地址拿到我们所需要的数据,那就说明了在这两者之间肯定存在这一种映射关系,能够将虚拟地址转化为物理地址,从而拿到所需要的数据,这种映射关系存放在一个叫页表 的空间当中,而虚拟地址和物理地址的映射关系相当于K-V关系。
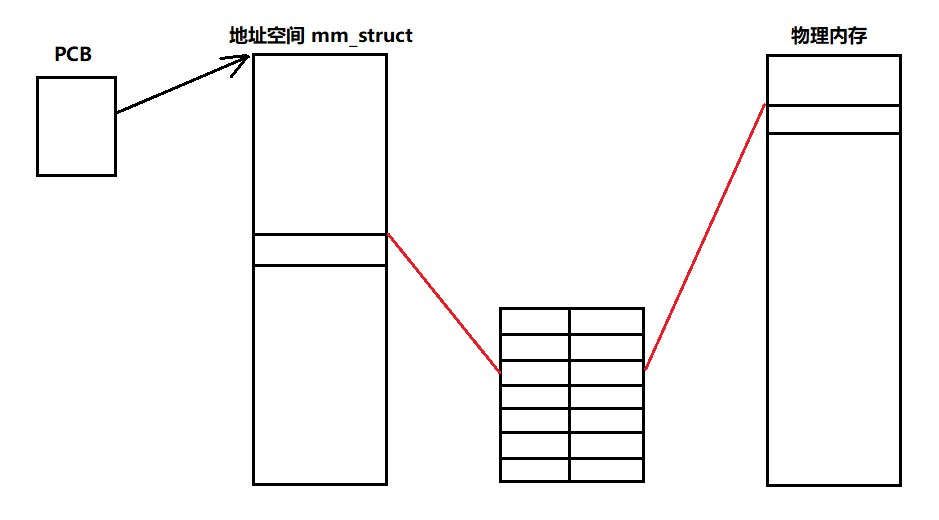
通过地址空间中的虚拟地址找到页表对应的位置,然后根据页表的映射关系获取到物理地址,从而拿到想要的数据。
接下来再对那段代码所遗留下来的问题作以解释:每创建一个进程,操作系统都会为每个进程创建所对应的地址空间和页表,而在fork之后,同样会和父进程一样创建内容一样的地址空间和页表,也就是相同的地址和相同的数据,如下图。
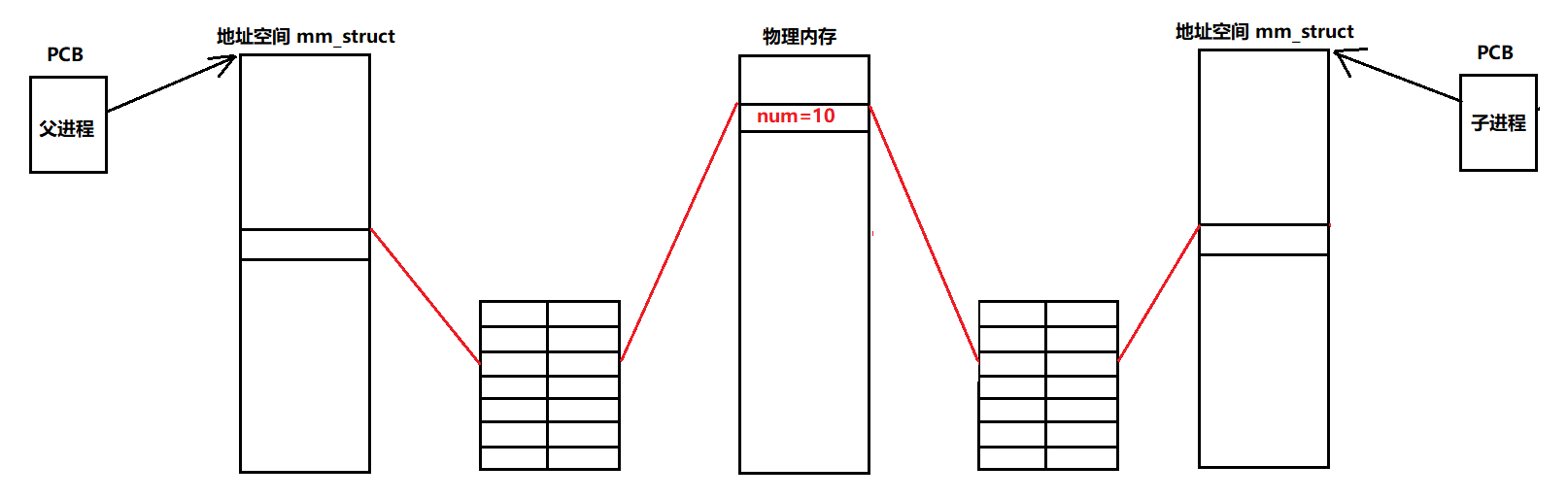
然而当父进程对全局变量修改之后,就会发生写时拷贝,是怎么回事呢?
- 因为进程之间具有独立性,父进程修改数据肯定是不会影响到子进程的,当父进程修改数据就会在物理内存中重新找一块空间将改变后的数据存放其中,然后父进程对应的页表的映射关系就会发生改变。
- 当然虚拟地址不会发生变化,变化的只是改变后的数据的物理地址需要在页表中重新映射。
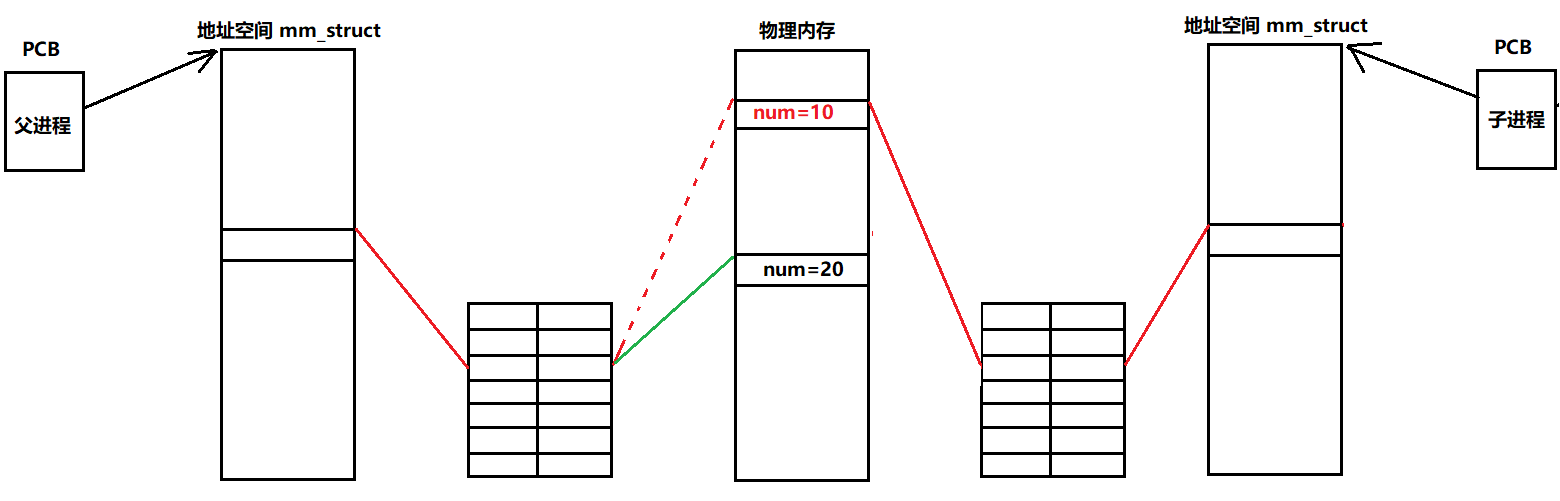
从这幅图就能明白为什么相同的地址对应的数据竟然不一样,原因就是我们所看到的地址并不是真正存放数据的地址,是将这个我们所看到虚拟地址经过父子进程不同的页表映射拿到了不同的物理地址,进而获取的数据不同。
- 同样,在父子进程的返回值当中也发生了写时拷贝。fork在返回时,父子进程都被创建出来了,而fork函数会return两次,因此表现出了会有两个执行流。而返回的本质就是写入,谁先返回,谁就让操作系统发生写时拷贝。
二、地址空间的意义
2.1 防止地址随意访问,保护物理内存与其他进程
如果没有地址空间的存在,进程就会直接与物理内存打交道,假设磁盘中自己写的A、B代码拿到了物理内存中,那么当执行A代码时因为代码的问题而产生了野指针问题,恰好会对B代码产生影响,显然这样是不安全的,而正是因为地址空间的存在,在与物理内存沟通时得先经过页表的映射,如果有野指针问题或者其他一些会影响其他进程的问题操作系统就会直接终止你的行为,保证你不会影响到其他进程。
举个例子: 一个小孩子过年领了好多压岁钱,但是他对于钱的概念并不是头脑很清晰,有一个良心不好的商家看他是一个孩子,故意高价卖一些东西或者骗这个孩子买了一些他根本不需要的东西,最后他父母知道这件事后认为孩子拿钱不行,于是就给他孩子说:"你的压岁钱妈妈替你保管,你想要买啥你给我妈妈要",但这个孩子说我要买棒棒糖,那么他妈妈就给了他两块钱去买,但是当他说我想要两千块买个手机玩一玩,那么家长肯定不同意。
在没有家长替孩子保管钱之前就相当于没有地址空间的存在,孩子就可能会乱花钱,而家长的存在就起到了保护的作用。
- 除此之外,通过页表进行地址转换的时候从CPU拿到的不仅仅是虚拟地址,还包括这次操作是读还是写。这样就可以在页表转换前在mm_struct中进行操作验证,假设你要访问的是代码区的地址,但是发现其配套的地址是栈区,所以操作系统就会直接拦截你的操作。
- 如果在mm_struct这里的虚拟地址是正确的,在页表里的除了进行地址转换,页表中还包含一项为权限标志位 ,表示该数据是读还是写。
char *str="hello"; *str='H';这两行的代码目的是想将str对应字符串的'h'改成'H',但是这样的做法是不可以的,原因就在于通过指针访问的时候会有权限的约束,只读而不可写。
2.2 将进程管理和内存管理进行解耦合
先看扩展1
- 在整个地址空间和物理内存的框架中,以页表中间为分隔线,以地址空间为主的为进程管理,以物理内存为主的为内存管理。
- 因为有地址空间以及页表的存在,所以进程是不会关心访问物理内存的哪个位置。也就是说无论数据被保存在物理内存哪个位置都是可以的。作为进程来说,我只需要知道虚拟地址即可,具体数据在物理内存哪个位置我不关心,通过页表的地址转换我都是可以在物理内存中找到的。
- 如果说没有地址空间,那么数据每次被加载到物理空间的地址会发生改变。因为有了地址空间和页表,无论物理内存的地址怎么变,变得只是页表的映射关系,进程能拿到得地址是不会发生变化的。
2.3 让进程以统一的视角看待自己的代码和数据
先看扩展2
- 进程的代码和数据被编译后被加载到物理内存时,每条指令的内容都包含着下一条指令对应的虚拟地址,每当CPU执行完一条指令后都会拿到下条指令的虚拟地址,通过虚拟地址的转换找到对应的物理地址,拿到对应的指令在CPU执行,周而复始。
- 可以看出来每次CPU拿到的都是虚拟地址,保证进程每次都通过地址空间来执行下一步的任务。
扩展1 malloc的本质
通过malloc这样的方式动态申请空间,操作系统会在申请之后立马在物理内存中开辟一段空间给你使用吗?
- 在你申请了一段空间之后,站在计算机的角度可以认为你是无法做到立马使用的。如果说在申请之后立马在物理内存中开辟出相应的空间那么必然会导致在你使用这段空间之前会有一段时间窗口,在这段时间里这段空间是无法被别的进程使用,处于闲置状态。
- 但是在操作系统的世界里,它是不允许不高效的使用和任何浪费,因此物理内存不会在你申请的时候而是在你需要的时候给你。
- 作为操作系统,它真实的做法是在你申请了空间之后,会在地址空间开辟出相应大小的空间,然后再将这块空间的首地址存放在页表的相应位置处,但是其对应的物理地址此时并不在页表中给出,操作系统会在你需要的时候在物理内存中开辟相应的空间,再将对应的物理地址填在页表中。
扩展2 重新理解地址空间
我们的程序在被编译的时候,没有被加载到内存,那么我们的程序内部有没有地址呢?
答案是有的。
- 源代码被编译的时候,就是按照虚拟地址空间的方式对代码和数据早就已经编好了对应的编址。
- 当程序被编译后还没有被加载到内存,它会被放在磁盘中。假设有两条指令,其中一条为call指令(call 0x1122),另一条为被call指令( 0x1122 xxxx)。先将这两条指令加载到内存中,之后进程通过虚拟地址、页表转换拿到call指令对应的物理地址的内容至CPU执行,此时进程就拿到了地址0x1122,这个地址是虚拟地址,再次通过页表转换拿到被call指令的物理地址处的内容(xxxx)再去执行。
- 每次CPU读到的地址都是虚拟地址。
总结
虚拟地址空间是一种在操作系统内部为进程创建出来的一种具体的数据结构对象,用来让进程统一的视角看待物理内存,因为有了虚拟地址空间的存在,可以让内存管理和进程管理独立开来,并且因为有地址空间的存在,我们在磁盘中编译程序时,就可以把编译好的程序以地址空间的方式排布好,这样当程序加载到内存时,CPU在进行读取识别时拿到的地址都是虚拟地址,再通过页表地址转换找到对应程序并且拿到下条指令的虚拟地址。