
大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。
Stability AI最近因正式开源 Stable Diffusion 3 Medium而成为头条新闻,这是一种图像生成模型,在大多数情况下,该模型在生成更复杂和更具视觉吸引力的细节方面优于其前身 SD2。此外,它展示了对冗长提示的理解力,然而,尽管有这些进步,SD3在人体生成方面还是会存在一些缺陷,经常产生怪诞的图片。
Stability AI在一份官方声明中表示:"Stable Diffusion 3 Medium是Stability AI迄今为止最先进的文本到图像开放模型,包含20亿个参数,该模型的较小尺寸使其非常适合在消费类PC和笔记本电脑以及企业级GPU上运行。它的尺寸合适,可以成为文本到图像模型的下一个标准。
SD3的主要功能包括照片级真实感、及时遵守、排版、资源效率和微调功能。它克服了手部和面部的常见伪影,无需复杂的工作流程即可提供高质量的图像。

扩散模型
Stable Diffusion和DALL·E3是目前可用的两个最好的AI图像生成模型,它们的工作方式大致相同。这两个模型都是在数百万或数十亿个文本-图像对上训练的。这使他们能够理解狗、猎鹿者帽子和黑暗的喜怒无常的灯光等概念,这也是他们如何理解像"一幅梵高派画作,一个道长倒骑着毛驴,边抽着旱烟,边路过一片白桦林"这样的提示,然后创作出对应的图像。
对于图像生成,Stable Diffusion和DALL·E3都依赖于称为扩散的过程。图像生成器从随机的噪声场开始,然后通过一系列步骤对其进行编辑以匹配对应的提示。

扩散模型通过添加噪音平滑地扰动数据,然后反向这一过程以从噪音中生成新数据。在反向过程中的每个去噪步骤通常需要估计得分函数(见右侧示意图),该函数的梯度优化是朝着可能性更高且噪音更少的方向行进。
尽管这两种型号具有相似的技术基础,但它们之间存在很多差异。Stability AI(Stable Diffusion的制造商)和OpenAI(DALL·E3)对人工智能工具的工作方式存在不同的哲学认知,包括采用的训练数据集也不一致,并在此训练过程中做了不同的设计和决策。
|------------------------------------------------------------------------------------|------------------------------------------------------------------------------------|
|  |
|  |
|
DALL·E3只能通过 ChatGPT、Bing Image Creator、Microsoft Paint 和其他使用其 API 的服务使用。Stable Diffusion是开源模型,可以通过 Stability AI的DreamStudio应用程序(或者以更基本的形式,通过 Clipdrop)访问它,但您也可以下载最新版本的 Stable Diffusion,将其安装在您自己的计算机上,甚至可以根据定制化的数据对其进行训练。

能力不先上下
Stable Diffusion和DALL·E3能够生成令人难以置信的 AI 生成的图像。实际上,这两种模式在客观上,甚至在主观上都不比另一种模式好。至少不是一致的。
如果被迫强调模型的不同之处,使用过的读者都会深有感触Stable Diffusion 倾向于更逼真的图像,尽管它可能会巧妙地弄乱面部等内容,而 DALL·E3使事物看起来更抽象或计算机生成。DALL·E3感觉"对齐"更好,因此会看到不那么刻板的结果。DALL·E3有时可以从较短的提示中产生比 Stable Diffusion更好的结果。
|------------------------------------------------------------------------------------|------------------------------------------------------------------------------------|
|  |
|  |
|
DALL·E3使用起来非常简单。打开 ChatGPT,只要是ChatGPT Plus的订阅者,就可以聊天并提出请求。若需要一点灵感,甚至可以尝试不同的想法和风格的建议。若不是ChatGPT Plus的订阅者,仍然可以查看DALL·E 2,它有更多的编辑选项。

当然还可以尝试通过Bing Chat或Microsoft Image Creator去感受DALL·E3。
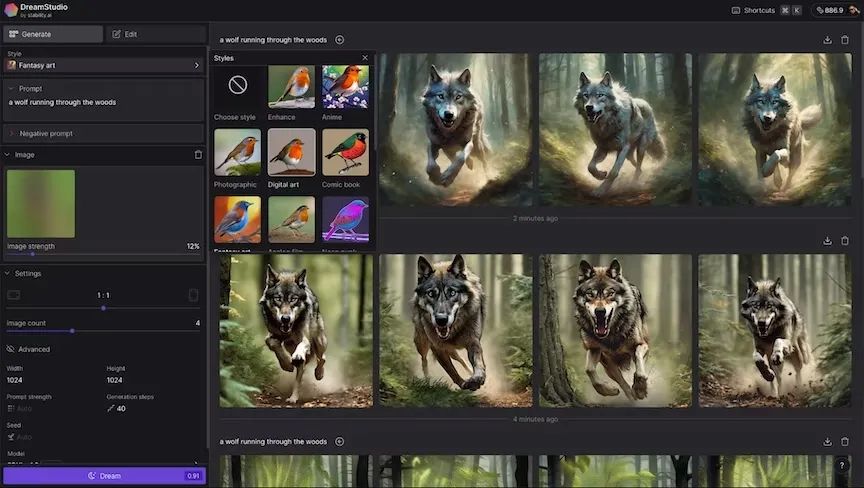
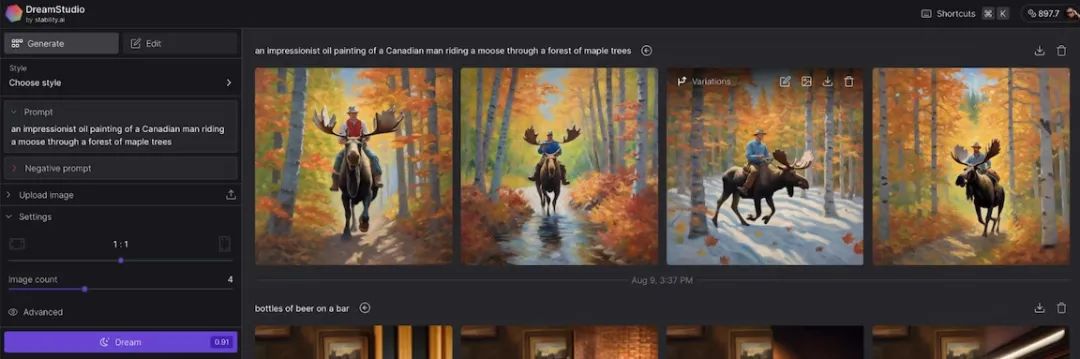
开箱即用方面,Stable Diffusion的用户友好性稍差,这里还有更多读者不知道的复杂的选项。例如:可以选择一种样式(增强、动漫、摄影、数字艺术、漫画书、奇幻艺术、模拟电影、霓虹朋克、等距、低多边形、折纸、线条艺术、工艺粘土、电影、3D模型或像素艺术)。还有两个提示框:一个用于常规提示,另一个用于否定提示,即不希望在图像中看到的内容。您甚至可以将图像用作提示的一部分。当然,安装和训练定制化的Stable Diffusion是完全不同的事情,并且需要更多的技术知识。
"对于SD3 Medium(20 亿个参数),我们建议使用16GB的GPU VRAM以获得更高的速度,但 VRAM 较低的人仍然可以使用至少5GB的GPU VRAM运行它,"。该公司补充说:"SD3具有模块化结构,允许它与所有3个文本编码器、3个文本编码器的较小版本或仅与其中的一个子集一起使用。大部分VRAM用于文本编码器。也有可能在CPU中运行最大的文本编码器,即T5-XXL。
Stable Diffusion(在除 Clipdrop 之外的每次迭代中)为用户提供更多选项和控制。正如上面提到的,可以设置步数、初始种子和提示强度,并且可以进行否定提示,所有这些都在 DreamStudio Web 应用程序中完成。若想构建一个基于特定数据(例如自己的脸部、徽标或其他任何东西)进行定制训练的生成式 AI,使用Stable Diffusion更容易做到。后续小编将带来两者之间的技术差异的专题报道。