1. 引言
上节我们先是了解了一些 "概念相关 " 的 常识,包括:
- Prompt 和 Prompt工程都是什么?
- 高层次了解LLM的核心工作原理
- 与AI关系的最佳比喻------导演&演员
- 基础Prompt框架:CRTF、RTF、COSTAR、SPAR
- Prompt高级策略:思维链、自我修正、RAG-检索增强、工作流、COT、APE
最后还整了一个 "终极最佳Prompt清单 ",通过 "十个维度" 来检查我们编写的提示词:

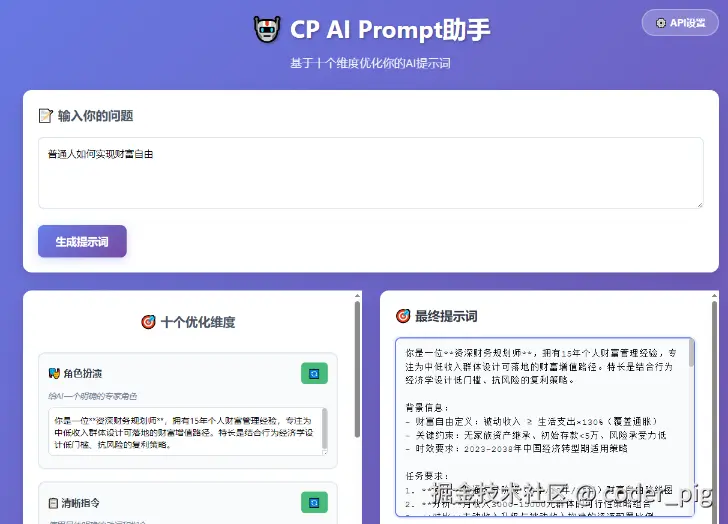
😄 然后读者要做的就是参考这些 Prompt框架 去跟AI对话,练习熟练度之余积累自己的 "词库 ",比如不同的回复风格。一种 更简单的方式 是记住上面的十要素,输入问题+让AI参照最佳实践生成提示词。示例:
python
我想让AI生成一个"显示器的推广文案",
请你给出一段符合 Prompt 最佳实践的提示词,
需包含这些要素:角色、指令、受众、目标、
上下文、语气风格、示例格式、约束、逐步思考、
鼓励反思 这十个要素。Kimi 输出结果:

😏 每次都要手敲一大坨有点麻烦,偷下懒,整个 "Prompt助手 ",直接输入问题,让AI基于最佳实践生成提示词,我们只需微调和复制,🤷♀️ 本来想搞个 小程序 的,后面了解了一下整起来有点麻烦,直接快速用 Cursor+掘金MCP 简单搭了一个:
配下 DeepSeek 的 Key 就能用,感兴趣的可以试试,工具免费,Key需要自己去DeepSeek官网申请~
上节回顾就到这,本节继续深入学习 AI,依旧是概念名词先行~
2. 概念名词
💡 Tips:简单了解下,有个大概印象就好,不用死记~
2.1. NLP-自然语言处理
2.1.1. 定义
Natural Language Processing,NLP 是计算机科学、人工智能和语言学交叉的领域,致力于研究如何让计算机处理、理解、解析、操作并生成人类语言 (自然语言)。核心任务:实体识别(NER)、情感分析、机器翻译、文本摘要、问答系统等。
2.1.2. 发展阶段
- 基于规则的NLP ::早期依赖语言学家手工编写的 复杂规则和语法树,如:定义主谓宾结构来解析句子,这种方法刚性强,泛化能力差。
- 统计NLP : 随着计算能力提升,转向使用 机器学习模型 (如N-grams, HMM, SVM) 从大规模文本数据 (语料库) 中学习语言的统计规律。
- 基于神经网络的NLP : 近年来,深度学习 (Deep Learning) 成为主流,使用 神经网络 (如RNN, LSTM) 来捕捉更复杂的长距离依赖关系。
2.2. LLM-大语言模型
2.2.1. LLM 定义
Large Language Model,LLM 是基于 深度学习 ,特别是 Transformer架构 的、参数规模极其庞大 (通常在十亿级别以上) 的 语言模型 。它们通过在 海量、多样化的文本语料 () 上进行自监督学习 (Self-supervised Learning) 进行 预训练 ,从而掌握了丰富的语言知识和世界知识。世界知识 (World Knowledge) 和一定的 推理能力 (Reasoning Ability)。世界知识 (World Knowledge) 和一定的 推理能力 (Reasoning Ability)。世界知识 (World Knowledge) 和一定的 推理能力 (Reasoning Ability)。
2.2.2. LLM 与 NLP的关系
LLM不是NLP的替代品,而是实现NLP任务的一种极其强大的现代方法论和工具。它代表了NLP领域从 "为每个任务训练一个专门模型 " 到 "一个通用大模型通过微调或提示来解决多种任务" 的范式转变。
2.2.3. 生命周期
① 预训练 (Pre-training)
- 目标:在通用、海量的文本数据 (如互联网、书籍) 上进行训练,让模型学习普适的语言规律、语法结构、语义关系和世界知识。
- 方法 :通常采用 "自监督学习 ",最核心的任务是 语言建模 (Language Modeling),即 "预测文本序列中的下一个词 (或被遮盖的词) "。如:给定 "The capital of France is",模型需要预测出"Paris"。通过 亿万次 这样的训练,模型内部的参数 (Parameters)------神经网络中的权重和偏置 被调整到能最好地捕捉这些模式。
- Transformer架构 :现代LLM的基石,其核心是 "自注意力机制" (Self-Attention Mechanism),允许模型在处理一个词时,动态地评估句子中所有其他词对它的重要性,从而高效地捕捉长距离依赖关系。
② 微调 (Fine-tuning)
- 目标 :将经过预训练的通用模型,适配到特定的下游任务或垂直领域。
- 方法 :使用一个规模小得多、但带有高质量标签的 "特定任务数据集 " 来继续训练模型。如:使用一个包含数千条 "用户评论-情感标签" 的数据集来微调通用LLM,使其成为一个 高精度的情感分析模型 。这会轻微调整模型的参数,使其 "专精" 于新任务。
③ 推理 (Inference)
- 定义 :使用训练好的模型 (预训练或微调后的) 根据新的输入 (Prompt ) 来生成输出的过程,这是 用户与模型直接交互的阶段。
- ✨ Prompt (提示词):推理阶段提供给模型的输入文本,它不仅仅是问题,更是对模型行为的指令和约束。提示词工程 (Prompt Engineering) 就是设计和优化Prompt以获得理想输出的艺术和科学。
- ✨ Tokenization (分词):基础且关键的预处理步骤,将 "原始文本字符串 " 分解成一个由模型能够理解和处理的基本单元 (词元 ) 组成的序列。语言模型无法直接处理连续的文本流,其核心计算依赖于 离散化的单元 。分词的核心目的就是:将自然语言转化为这种可计算的格式,为后续的神经网络计算奠定基础。现代LLM普遍采用 "子词分词 (Subword Tokenization)" 方案 (如BPE、WordPiece)。这种方法极其高效,它能将文本拆分为 高频词、词根、前后缀 等 "有意义的单元 ",从而有效 "平衡词典规模 " 并解决 "未登录词" (模型没见过的词) 问题。
- ✨ Token (令牌):就 "词元 ",分词处理后,构成文本序列的 "最小计算单元 ",模型"看到"和处理语言的 基本单位 。一个Token可以是一个完整的单词 (如"model"),一个有意义的子词 (如:单词running被分解为 run 和 ##ing 这两个Token),一个汉字,或一个标点符号。在模型的词汇表 (Vocabulary) 中,每个唯一的 Token 都有一个对应的ID和向量表示 (词嵌入 Embedding )。模型的所有内部计算,包括注意力机制的运作,都是基于这些Token的向量表示进行的。模型的许多关键限制和计费方式都与Token直接相关,如:模型的上下文窗口 (Context Window)------模型一次能处理的最大Token数量 和 API调用成本。
- 生成策略 (Generation Strategy):模型在生成每个Token时如何选择,如:贪心搜索 -每次都选择概率最高的Token,速度快但容易陷入局部最优,内容单调。束搜索 -维护多个候选序列,选择综合概率最高的。质量较高,但计算量大。采样-引入随机性,增加输出的多样性 (如Top-K,在概率最高的K个Token中采样、Top-P,在概率总和不超过P的最小Token集合采样,目前最常用且效果最好的策略之一)。
- ✨ 幻觉 (Hallucination):指模型生成的内容看似合理,但实际上是 "事实错误、无中生有或与源文本不符 " 的现象。这是因为 LLM 是 "基于概率的文本生成器 ",其首要目标是生成语法通顺、语义连贯的文本,而非保证事实的绝对准确性。缓解方法:通过 增强检索生成(RAG) 引入外部知识源、优化Prompt、进行事实核查等。
- 参数 (Parameters):模型内部的可学习变量 (权重和偏置),其数量 (如GPT-3的1750亿) 是衡量模型规模和能力的关键指标。这些参数在训练后被固定,在推理时使用。
2.2.4. LangChain 框架
用于简化基于LLM应用程序开发的 开源框架 ,将LLM与外部数据源、计算资源和其他API连接起来的 "胶水&工具箱"。
解决的核心问题:
- 数据连接 :LLM 的知识是静态的 (截止于训练数据),LangChain 帮助LLM连接到 实时的、私有的、特定的数据库或文档。
- 状态管理 :LLM 本身是无状态的,每次调用都是独立的,LangChain 提供了 记忆 (Memory) 机制来维持多轮对话的上下文。
- 智能体 (Agents): 赋予LLM "思考-行动" 的能力,Agent 可以使用外部 工具 (Tools) (如搜索引擎、计算器、API调用),自主规划步骤来完成复杂任务。
核心组件:
- Models:封装不同LLM提供商的API (如OpenAI, Anthropic)。
- Prompts:管理和优化提示模板。
- Chains:将多个LLM调用或其他组件按顺序 (或更复杂的逻辑) 组合起来,形成一个完整的应用流程。
- Indexes:帮助LLM处理和查询私有数据,是实现 检索增强生成 (RAG) 的关键。
- Agents:允许模型动态决定使用哪些工具来与外部世界交互,以完成任务。
- Memory:为对话提供记忆功能。
2.2.5. ReAct 框架
当 LLM 与外部工具和环境交互时,它就从一个语言模型演变为一个 智能体 (Agent) ,可发展为强大的通用问题解决平台,其核心驱动力源自名为 ReAct (Reason and Act,推理与行动 ) 的创新框架。框架的本质: LLM 模仿人类解决问题的方式,在一个 "思考→行动→观察" 的闭环中迭代工作。
流程:
- 思考 (Thought): 面对一个任务,LLM 首先进行推理,将大问题分解为小步骤,并规划出下一步需要执行的具体动作,这个 "内心独白" 是其决策过程的体现。如:任务"苹果公司现在的股价是其市值的多少分之一?" → LLM思考:"我需要两个信息:1. 苹果的当前股价;2. 苹果的总市值。我需要使用工具来查询这两者。"
- 行动 (Action): LLM 选择一个合适的 工具 (Tool) -如搜索引擎、API接口、代码解释器,并生成执行该工具所需的具体指令。如:LLM 选择 Search 工具,并生成行动指令 Search("Apple Inc. current stock price")。
- 观察 (Observation):系统执行 "行动",并将从工具获得的结果作为 "观察" 反馈给 LLM。如:系统返回观察结果 "195.89 USD"。
- 循环与迭代:LM 接收到观察结果,并与初始目标进行比对,然后开始新一轮的"思考"。它会判断任务是否完成,或者基于新信息规划下一步的 "行动",如:继续搜索 "Apple Inc. market cap"。
通过这种方式,ReAct 框架赋予了 LLM 动态规划和工具使用 的能力,使其能够处理实时信息、执行精确计算、与外部世界交互,从而解决远比纯文本问答复杂得多的现实世界问题。这是通往 通用人工智能(AGI) 的重要路径。
2.2.6. 多模态LLM
Multimodal-LLM 是 传统LLM 的重要演进,它不仅能处理和理解文本信息,还能同时 感知、理解和处理多种不同类型的数据格式 (模态) ,最常见的包括 图像、音视频 等。其核心思想是将这些非文本数据 "翻译 " 成 LLM 能够理解的 "语言 ",并将其与文本信息融合在一个统一的语义空间中进行处理。这使得模型对世界的理解从抽象的符号 (文字 ) 层面,跃升到了更接近人类的、包含视觉和听觉的 多维感知 层面。训练M-LLM 需要海量、高质量的 "成对" 数据 (如"图片-描述"对),获取和标注成本极高,推理需要比纯文本 LLM 更庞大的计算资源。
核心工作原理:
① 模态编码
- 针对每一种非文本模态,使用一个专门的 编码器 (Encoder) 进行特征提取。
- 图像 :通常使用 视觉Transformer (Vision Transformer, ViT) 或类似的卷积网络,将一张图片转换成一系列高维向量,可理解为图片的 "词嵌入"。
- 音频 : 使用音频编码器 (如 Whisper 的编码器部分) 将声波转换成向量表示。
② 空间对齐/投影
- 来自不同编码器 (如图像/文本编码器) 的向量处于不同的"语义空间",无法直接比较。
- 通过一个轻量的 投影层 (Projection Layer) 或 连接器 (Connector),将非文本模态的向量 "映射" 到与 LLM 的文本词嵌入相同的语义空间中。
- 经过这一步,一张图片就被转换成了一系列特殊的"图像 Token",它们可以和 "文本 Token" 无缝拼接,如同句子中的普通单词一样被 LLM 理解。
③ 统一处理
- 将 "文本Token" 和经过对齐的 "非文本Token" 拼接成一个统一的序列,然后输入到 核心的 LLM (通常是一个预训练好的文本大模型) 中。
- LLM 的 自注意力机制 会同时处理这个混合序列,计算文本与图像、图像与图像部分之间的关联性,从而实现对多模态输入的深度理解,并生成最终的输出 (通常是文本)。
应用类型与示例:
① 多模态理解
- 输入多模态,输出文本。典型任务:视觉问答 (VQA),给模型一张图片,然后用文字提问。
- 示例:上传一张冰箱内部的照片,问 "我今晚可以用这些食材做什么菜?"
- 代表:😄 现在基本所有大模型都支持,说个开源 M-LLM → LLaVA。
② 多模态生成
- 输入通常是文本,输出是非文本模态。典型任务:文生图、文生音视频。
- 示例:输入提示词 "一只穿着宇航服的猫在月球上弹吉他,超现实主义风格" 模型生成对应图像。
- 代表:DALL-E 3/Midjourney 生成图片、Sora (OpenAI) 生成视频。
③ 模态间转换
- 将一种模态直接转换为另一种。如: Whisper (OpenAI) 将音频 (语音) 直接转换为文本 (文字)。
2.2.7. AIGC-人工智能生成内容
Artificial Intelligence Generated Content,指:通过训练模型自主生成文本、图像、音频、视频等多模态内容的技术。
2.2.8. AGI-通用人工智能
人工智能领域的终极愿景,又称 "强人工智能 ",指的是一种具备与人类同等智慧,甚至超越人类智慧的智能体,它是一个 "通才 ",其核心特征在于 通用性 和 适应性。
与LLM的关系:
LLM 本质上是一个极其复杂的 "概率模型 ",它通过学习海量文本的统计规律来生成最可能的下一个词。LLM擅长发现相关性,但难以进行真正的因果推理,它是在 模仿智能 ,而非拥有真正的理解、意图或意识。LLM 可能是实现 AGI 的一个必要组成部分,但可能不是全部,它可能是AGI大脑中的 "语言中枢",但一个完整的AGI还需要更强大的世界模型、持续学习能力及与物理世界交互的"身体"。
一个 "真正的AGI" 应该具备以下能力:
- 跨领域学习:能将从一个领域学到的知识和技能,灵活地应用到全新的、未曾见过的领域。
- 常识推理:拥有并能运用海量的、关于世界如何运作的背景知识 (即常识)。
- 抽象思考:能够理解和操作复杂的抽象概念,进行规划、创新和科学发现。
- 自主学习:无需人类干预,能够为自己设定目标,并主动探索和学习以实现这些目标。
3. 模型微调
"预训练模型 " 的目标是 "通用语言理解 ",尽管已经具有丰富的语言知识,但它们还缺乏 "特定领域的专业化 " (特定知识或模式),导致输出可能 "通用但不精准 "。如:模型回答法律问题时,可能遗漏关键法条,而微调后,模型能更准确地引用《民法典》条款或案例。另外,微调还能缓解预训练中的 "知识过时" 问题。
从头训练一个大模型需要海量数据和巨额计算资源 (如千亿参数模型需数千张GPU训练数周),而 "微调 " 仅需 "少量标注数据" (通常数百到数千条) 即可适配新任务。如:用1000条医疗问答数据微调LLaMA,效果可能远超用10万条通用数据从头训练的小模型。
😄 "微调 " 的目的是 "让模型更好地适配特定任务,按要求精准输出 ",常见技巧除了上节讲的 "Prompt提示词工程 " 外,还有 "推理参数调优 " 和 "上下文干预"。
3.1. 推理参数
LLM 一般会提供一些 "可调参数 ",用于控制模型生成文本的长度、随机性、多样性,以及训练过程的效率与稳定性。大多数情况下,普通用户 在使用他人训练好的大模型 (如 OpenAI、Hugging Face等公开API) 时,只能调整 "推理 " 阶段的参数。而 训练/微调阶段的超参数 (如earning_rate、batch_size、weight_decay、optimizer、warmup_steps、fp16/bf16 等) 仅在模型提供商开放「微调服务 」且获得相应权限时才可调。接着过下常见的 "推理阶段参数" ❗️
💡 Tips :😄 对大部分普通人来说,只需关注 "Temperature " 这个参数,知道 "温度越高,越爱瞎说,温度越低,越像书呆子" 就够了,其它参数基本用不到,那是做AI产品的人应该考虑的 😊。另外,不同LLM模型支持的参数不同,具体以模型对应的API调用的官网文档为准~
3.1.1. model (模型)
指定使用模型的标识符,如:deepseek-chat、deepseek-reasoner、gemini-2.5-pro、gpt-4
3.1.2. Temperature (温度)
最常用、最重要的参数之一,用于控制生成文本的 "随机性 ",,它通过 调整模型在选择下一个词时的概率分布 来实现。在模型计算出每个可能词的概率后,Temperature 会 "平滑 " 或 "锐化 " 这个概率分布,典型范围 0.0-2.0 , "低" -"尖锐 "-高概率的词语更易被选中-模型行为更具 确定性 、更保守、更重复,"高 "-"平坦 "-低概率的词语也有机会被选中-模型行为更具 创造性、更多样化,但也可能出现不合逻辑或奇怪的组合。
使用建议
- 0.1-0.2 → 高度确定性,对答案准确性要求极高、且不希望出现任何随机性,如:配置、代码片段生成。
- 0.3-0.6 → 低度随机性,在保持较高一致性的同时可引入少量多样化表达,如:技术文档撰写、客观性报告、风格较为严谨的文本生成。
- 0.7-1.0 → 中等随机性,生成更加灵活、富有创造性,如:创意写作(小说、诗歌)、市场文案与广告标语、自由式对话与聊天。
- 1.1-1.5 → 高随机性,显著增强多样性与意外性,但可能出现不连贯或偏题内容,建议仅在高度创意或探索性需求下使用,如:脑暴思路收集、内容灵感触发。
- >1.5 → 极高随机性,生成结果几乎完全无规律 (胡言乱语),仅供极端实验或娱乐目的。
3.1.3. Top-P 核心采样
另一种控制 "随机性" 的方法,相比 Temperature 更智能、更灵活。它从一个动态的、概率最高的 "候选词核心集 " 中进行抽样,而不是考虑所有可能的词。模型会将所有可能的下一个词 "按概率从高到低排序 ",然后累加它们的概率,直到总和达到 p 这个阈值。模型将只从这个概率累加起来达到 p 的词集合中进行抽样。如:top_p = 0.9,模型会选择概率最高的词,直到它们的累积概率超过90%,然后,模型会从这个集合中 (根据它们的相对概率) 随机选择一个词。典型范围 0.0-1.0
注意事项
- top_p 的优势在于它的候选集大小是动态的,如果模型非常确定下一个词是什么 (如:"I think therefore I __" 后大概率是 "am"),那么候选集可能只有1-2个词。如果模型不确定 (如:一个开放式问题的开头),候选集可能会很大,从而允许更多样化的输出。
- top_p = 1.0 意味着模型会考虑所有词。
- 大多数API文档都建议只调整 Temperature 或 Top-P 中的一个,而不是同时调整两个,一起调可能会产生不可预测的结果。一种常见的做法是设置 top_p = 0.9 或 0.95,然后只调整 Temperature。
3.1.4. Top-K 采样
最简单的抽样控制方法 ,限制模型在生成下一个词时 只考虑 k 个最有可能的选项 (选出概率最高的k个词,概率分布进行抽样,忽略其它词)。典型范围 整数,如1、10、50
注意事项
- Top-K 不具备适应性,在某些情况下,可能只有少数几个好选择,但一个大的 k 值会强行引入不好的选项。而在另一些情况下,可能有许多好选择,但一个小的 k 值会限制模型的创造力。
- Top-K 现在用得相对较少 ,Top-P 通常比 Top-K 效果更好,因为它能根据上下文动态调整候选集的大小。
3.1.5. Max Tokens
max_length/max_new_tokens ,用于设置 模型生成的最大长度 (单位Token)。这是控制成本和延迟的关键参数,Token数量直接关系到API调用费用。设置太短,可能导致回答不完整,设置太长,可能会增加不必要的成本和等待时间,也可能导致模型在完成任务后继续 "胡说八道"。一个好的实践是根据你的任务需求,估算一个合理的长度上限。某些模型还支持 min_length,强制至少生成指定长度 token,避免生成过短文本。
3.1.6. stop_sequences (提前终止)
提供一个或多个字符串序列,当模型生成这些序列时,会立即停止输出,可用于 精确控制输出的结束点。如:构建一个问答Bot时,可以将 stop="\\nUser:", "Q:" 设置为停止序列,以防止模型自己编造下一个用户的问题。注:停止序列本身不会出现在最终的输出中
3.1.7. frequency_penalty (频率惩罚)
根据词元在文本中的出现频率进行惩罚,出现次数越多,惩罚越重,常用语 "降低模型重复使用相同词语 " 的倾向,鼓励多样化的用词。典型范围 -2.0-2.0 ,正值会惩罚重复,值越大,越倾向于使用新词,负值会鼓励重复,值越负,越倾向于重复使用用过的词。默认0,无惩罚/奖励,行为完全由其自身的概率模型决定。当你发现模型反复说同样的话时,可以适当调高此参数。
3.1.8. presence_penalty (存在惩罚)
对 "文本中已出现过的词元 " 进行一次性惩罚,不论其出现次数,常用于 "鼓励模型引入新的话题和概念" ,提升文本的广度,防止模型过早重复已出现的词元。典型范围0.0-2.0 ,当你希望模型的回答话题更广泛,而不是在一个主题上深挖时,可以调高此参数。参数选择:小幅度 (1.1-1.5) 用于轻度抑制,大幅度 (1.5--2.0) 用于严格去重。
3.1.9. repetition_penalty (重复惩罚)
直接惩罚 "上下文中已出现过的词元" ,降低其再次被生成的概率,这是一个强力去重工具,常用于 "防止模型陷入循环或生成高度重复的语句 "。典型范围 1.0 - 2.0 ,值为 1.0 表示无惩罚,大于 1.0 的值会惩罚重复,值越大,惩罚越强,生成的文本越不容易重复,过高的值 (如 > 1.5) 可能会损害文本的连贯性。
3.1.10. num_return_sequences (返回序列数量)
指定对同一个输入提示,一次性生成并返回多少个不同的答案,常用于 "需要多个备选方案或进行创意发散 " 的场景。典型取值 为 正整数,默认值为 1。当你希望比较模型的多种回答风格、为一个问题生成多个不同角度的答案,或者在多个生成结果中手动筛选出最满意的一个时,可调高此参数 (如设置为 3 或 5)。注意:设置 num_return_sequences=N 会使计算量和生成时间约等于原来的 N 倍。
3.1.11. stream
是否采用流式输出 ,为 true 表示 "边生成边返回 ",常用于交互式场景,为 false 则全部生成完再一次性返回,
3.1.12. echo
是否将 prompt 一并返回,便于对比输入输出。
3.1.13. seed
随机种子,保证在通用参数下可复现输出。
3.2. 参数微调
3.2.1. openai 库
😶 LLM厂商 基本都采用 Chat 服务免费 (部分功能收费) + API 调用收费 的打法:
- 前者面向 "普通终端用户 ",专注于对话场景,封装了上下文管理、工具调用等复杂逻辑,用户仅需关注对话内容,只能玩玩 "Prompt工程"。
- 后者则面向 "开发者 ",提供标准化的HTTP接口,开发者可将 LLM能力 集成到各种自定义应用中,对参数设置、消息结构有更高的自由度。
💁♂️ 不同LLM厂商的API接口端点大同小异 (为了便于移植,大多兼容 OpenAI ),这里 DeepSeek 为例:
🤡 官网注册个账号,充点钱 (最少10块),申请一个key,就可以开耍了,官方 cURL 调用接口示例:
bash
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <DeepSeek API Key>" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'Windows 下的终端 (CMD) 不支持 \ 换行,且双引号需转义,单引号会被视为普通字符,需将命令改为单行或用 ^ 转义换行 (不推荐,容易出错),这里直接单行:
bash
curl https://api.deepseek.com/chat/completions -H "Content-Type: application/json" -H "Authorization: Bearer 你的真实API密钥" -d "{ "model": "deepseek-chat", "messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Hello."}], "stream": false }"返回结果示例:

😄 也可以用 Postman 、Apifox 这类 API测试工具 来模拟请求,看了下 python 、nodejs 调用示例,都是用的 openai 库。这个库封装了对 OpenAI 各类服务的完整调用细节,包括请求构造、认证、错误重试、流式响应、函数调用、类型提示等,可以不用 "造轮子 ",当然,你想自己用 HTTP请求库 手撕也可以🤷♀️。openai 库封装核心功能如下:
① 统一API接口 → 通过单一命名空间调用多种服务
- 聊天/Completion:openai.ChatCompletion.create()、openai.Completion.create()
- 文本嵌入:openai.Embedding.create()
- 图像生成:openai.Image.create()
- 音频转录与翻译:openai.Audio.transcribe() / openai.Audio.translate()
- 内容审核:openai.Moderation.create()
② 请求设置与认证
- 自动读取环境变量 OPENAI_API_KEY ,或在代码中全局设置 openai.api_key
- 可配置超时 openai.api_request_timeout、重试次数 openai.max_retries
③ 错误与重试机制
- openai.api_request_timeout、openai.max_retries 可配置请求超时与最大重试次数。
- 1.x 版本,构造客户端时可传入 timeout 参数,每次调用也可使用 client.with_options(timeout=...) 覆盖。
- 对 5xx 错误、网络超时等场景自动重试,将 HTTP 状态码与错误信息映射为 OpenAIError、RateLimitError、Timeout 等异常类,便于统一捕获处理。
④ 流式输出支持
支持对大模型输出启用 stream=True,内置事件迭代接口,简化实时展示与处理。
⑤ Function Calling
自动根据函数定义生成 JSON Schema,模型可决策何时调用本地函数,并返回结构化参数。
⑥ 请求/响应钩子
支持全局或单次调用注入钩子 (hooks 参数),可在请求前后执行自定义逻辑,用于日志记录、监控埋点等
⑦ 多端点与厂商兼容
支持自定义 API Base,通过修改 openai.api_base、openai.api_type,可接入 Azure OpenAI、Google Gemini、Anthropic Claude、Mistral 等兼容端点。
3.2.2. DeepSeek API 微调示例
这里以Python为例,pip install openai 装下库,CV《DeepSeek API 文档-对话补全》的Python实现,然后编辑器有这样的 "警告":

原因:
OpenAI 新版 Python SDK 对参数类型做了更严格的类型注解,要求传入 messages 参数的每个元素都是 ChatCompletion*MessageParam 类型,而不是普通的dict。😄 类型检查工具 报的警告而已,旧的 "纯dict" 写法是兼容的,实际运行没啥问题。
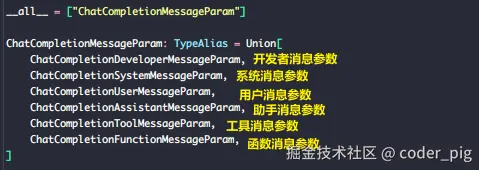
试了下,发现尽管区分了消息类型,role 参数还是必传的 🤷♀️,我选择更简洁的清晰的dict形式~
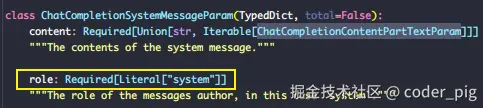
messages-不同的消息类型:
python
# 1. Developer Message - 开发者消息
{"role": "developer-固化模型行为的内部指令",
"content": "开发者向模型传递的指令或提示,支持字符串或细分文本片段"}
# 2. System Message - 系统消息
{"role": "system-用于告诉模型整体对话场景或背景",
"content": "设定AI的角色定位、能力范围和回答风格的指令"}
# 3. User Message - 用户消息
{"role": "user-用户的问题或指令",
"content": "用户提出的问题、任务需求或对话输入内容"}
# 4. Assistant Message - 助手消息
{"role": "assistant-用于在一次调用中包含前文的助手回复,以便模型能接续对话",
"content": "模型已生成并发送给用户的消息内容"}
# 5. Tool Message - 工具消息
{"role": "tool-外部工具返回执行结果的角色",
"tool_call_id": "关联的工具调用唯一标识符",
"content": "工具执行后返回的结果数据或状态信息"}
# 6. Function Message - 函数消息 (已弃用)
{"role": "function-函数调用返回结果的角色",
"name": "被调用的函数名称标识",
"content": "函数执行返回的结果数据 (建议使用tool类型替代) "}model -必须,指定使用的模型 ID,可选值:deepseek-chat , deepseek-reasoner ,后者不支持这些参数:temperature、top_p、presence_penalty、frequency_penalty、logprobs、top_logprobs,为了兼容已有件,设置前四个不会报错,也不生效,后两者设置了会报错 ❗️❗️❗️ 快速梳理下 DeepSeek 支持的参数,先是 "请求参数":
① 控制创意:
- temperature:控制输出的随机性,值越高越随机/有创造性,值越低越确定/集中。范围 0, 2,默认 1,建议不要与 top_p 同时修改。
- top_p:控制输出的范围,模型仅从概率总和达到 top_p 值的词汇中进行采样,如 0.1 表示只考虑概率最高的 10% 的词。范围 0, 1,默认 1,建议不要与 temperature 同时修改。
② 控制长度和重复
- max_tokens:限制单次请求生成的最大 token 数量,输入+输出总长度受模型上下文限制。范围 1, 8192,默认 4096。
- stop:设置一个或多个停止词/短语,当模型生成到这些词时会立刻停止。格式为单个字符串或最多 16 个字符串的列表。
- frequency_penalty:根据 token 在已有文本中的出现频率来惩罚新 token,正值可降低模型重复相同内容的可能性。范围 -2.0, 2.0,默认 0。
- presence_penalty:根据 token 是否已在已有文本中出现来惩罚新 token (出现一次即惩罚),正值可增加模型谈论新主题的可能性。范围 -2.0, 2.0,默认 0。
③ 控制格式与输出方式
- response_format:强制模型按指定格式输出,常用设置为 {"type": "json_object"} 来启用 JSON 模式。注意:使用 JSON 模式时,必须在 prompt 中也指示模型生成 JSON。
- stream:是否以流式(SSE)返回数据,true 时结果会分块实时返回,实现打字机效果。默认 false。
- stream_options:流式输出的附加选项 (仅在 stream: true 时生效),如设置 include_usage: true 可在流结束时获取 token 使用量统计。
④ 工具调用-Function Calling
- tools:定义一个或多个可供模型调用的工具列表 (目前仅支持函数),需提供函数的 name, description, parameters。
- tool_choice:控制模型如何调用工具,可选值:none (不调用)、auto (模型自行决定)、required (必须调用),或指定一个特定函数来强制调用。
⑤ 概率信息
- logprobs:是否返回每个输出 token 的对数概率,值为 true 或 false。
- top_logprobs:返回每个输出位置上概率最高的 N 个 token 及其对数概率,范围 0, 20 的整数,使用此参数时 logprobs 必须为 true。
然后是 "响应参数":
① 核心/元数据信息
- id: 本次对话的唯一标识符 (string) 。
- created: 创建对话时的 Unix 时间戳,单位为秒 (integer) 。
- model: 生成本次回复所使用的模型 ID (string) 。
- object: 对象类型,其值固定为 chat.completion (string) 。
- system_fingerprint: 代表模型运行的后端配置指纹,可用于追踪和复现结果 (string) 。
② 模型生成结果 (choices)
这是一个列表 (object\[\]) ,包含了模型生成的回复,🤡 DeepSeek 不支持设置n参数-一次生成多个回答,所以只会有一个元素,单个结果 (choice对象) 的内部结构 :
finish_reason: 模型停止生成的原因 (string)
- stop: 自然完成或遇到 stop 序列。
- length: 达到 max_tokens 或上下文长度限制。
- tool_calls: 模型决定调用一个或多个工具。
- content_filter: 内容因安全策略被过滤。
- insufficient_system_resource: 系统资源不足导致中断。
index: 该回复在 choices 列表中的索引,从 0 开始 (integer)
message (消息对象): 模型生成的核心消息内容:
- role: 消息的角色,固定为 assistant (string) 。
- content: 模型生成的消息文本内容,即AI的回答 (string, nullable) 。
- tool_calls: 模型要求调用的工具列表 (object\[\]) 。每个 tool_call 包含:
-
- id: 工具调用的唯一 ID。
- type: 工具类型,固定为 function。
- function : 包含 name (函数名) 和 arguments (JSON 格式的参数字符串) 的对象。注意: 模型生成的 arguments 不一定是有效的JSON,使用前需验证。
- reasoning_content: 仅 deepseek-reasoner 模型返回,包含最终答案前的思维链推理内容 (string, nullable) 。
logprobs (对数概率信息) : 包含 token 概率信息的对象,仅在请求中设置 logprobs: true 时返回 (object, nullable) 。包含一个 content 列表,包含每个输出 token 的详细信息。每个元素:
- token: 输出的 token 字符串。
- logprob: 该 token 的对数概率。
- bytes: 该 token 的 UTF-8 字节表示。
- top_logprobs: 一个列表,包含在该位置概率最高的 N 个 token 及其对数概率 (仅在请求中设置了 top_logprobs 时返回) 。
③ 用量统计信息 (usage)
- prompt_tokens: 用户输入 (prompt) 所消耗的 token 数 (integer) 。
- completion_tokens: 模型生成 (completion) 所消耗的 token 数 (integer) 。
- total_tokens: 本次请求的总 token 数 (prompt_tokens + completion_tokens) (integer) 。
- prompt_cache_hit_tokens: 用户输入中,命中上下文缓存的 token 数 (integer) 。
- prompt_cache_miss_tokens: 用户输入中,未命中上下文缓存的 token 数 (integer) 。
- completion_tokens_details : 回复 token 的详细信息 (object) ,reasoning_tokens: 推理模型产生的思维链 token 数量。
🙋♂️ API 了解的差不多了,上代码,用一样的提示词,设置不同的 "推理参数",然后对比下生成效果:
python
from openai import OpenAI
# 创建 OpenAI 客户端实例
client = OpenAI(api_key="sk-xxx", base_url="https://api.deepseek.com")
question = "为一款名为'晨光'的新咖啡品牌,构思一句宣传标语,提供5条的示例"
def get_response(prompt, temperature, top_p, frequency_penalty=0.0):
"""一个通用的函数来调用API并打印结果"""
try:
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是一位品牌营销专家。"},
{"role": "user", "content": prompt}
],
temperature=temperature,
top_p=top_p,
frequency_penalty=frequency_penalty,
)
return response.choices[0].message.content
except Exception as e:
return f"调用API时出错: {e}"
if __name__ == '__main__':
# --- 场景一:扮演"创意大师" ---
# 高温(胆子大)、高top_p(选项多)、轻微频率惩罚(避免重复)
# 标语更具创意、用词新颖、表达方式多样化,可能出现意想不到的组合
print("--- 场景一:创意大师模式 (高 Temperature, 高 Top_p) ---")
creative_slogan = get_response(
prompt=question,
temperature=0.9,
top_p=0.8,
frequency_penalty=0.5
)
print(f"创意标语:\n{creative_slogan}\n")
# --- 场景二:扮演"严谨学者" ---
# 低温(胆子小)、低top_p(选项少),确保输出最稳妥、最常见的表达
# 标语更规范、用词常见、表达方式传统稳妥,输出结果相对可预测
print("--- 场景二:严谨学者模式 (低 Temperature, 低 Top_p) ---")
factual_slogan = get_response(
prompt=question,
temperature=0.1,
top_p=0.5
)
print(f"严谨标语:\n{factual_slogan}\n")DeepSeek 返回内容:

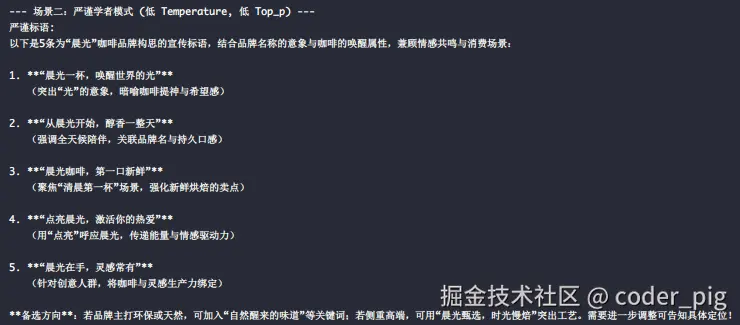
🤔 你更喜欢哪一种呢?这里只是简单的使用展示,实际场景中,推理参数的配置需要反复调试、测试和权衡。
3.3. 上下文干预
🤔 两个核心干预手段 → "定制messages数组 " 和 "RAG架构-注入外部知识",一一讲解~
3.3.1. messages 数组
大部分 LLM 模型的 API调用 ,模型并没有 "真正的记忆 ",它每一次的生成,都是基于 "你当前这次请求所提供的全部上下文 ",也就是 messages 数组 里的所有内容。😏 所以,将期望的上下文和提示直接注入模型,就可以引导模型生成符合预期的回答。几种常见玩法示例 (基于DeepSeek API):
① 添加系统信息
在 messages 的最前面加一条 role: "system" 的消息,用于设定助手的行为、风格和角色定位。
python
[
{"role": "system", "content": "你是一个严谨的财务分析师,回答时请引用数据并保持简洁。"},
{"role": "user", "content": "请分析这份财报的盈利能力。"}
]② Few-Shot
在真正的用户提问之前,先插入若干人---机对话示例,展现目标格式或答题思路。相当于教模型如何回答:
python
[
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": "如何写一封正式的商务邮件?"},
{"role": "assistant", "content": "尊敬的XXX,\n...(示例答复)"},
{"role": "user", "content": "帮我写一封给合作伙伴的邀请函。"}
]③ 对话前缀续写 (Perfix)
就强制模型以给定的前缀内容开头,用于精细控制输出的开头格式或术语。DeepSeek 中可通过设置 prefix 参数为 true 实现。
python
messages=[
{"role":"system", "content":"请以报告体裁回答,下文开头必须出现"报告摘要:""},
{"role":"assistant", "content":"报告摘要:", "prefix": true},
{"role":"user", "content":"请说明本季度销售情况。"}
]
# 生成内容必以"报告摘要:"开头,确保输出格式完全符合要求④ 链式思考
使用 deepseek-reasoner 模型,可同时获取 思维链 (reasoning_content) 和 最终答案 (content),在多轮对话中,对思维链进行人工修正或二次筛选,进而干预最终输出。
python
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=[...],
max_tokens=2048 # 限制思维链长度
)
print(response.choices[0].message.reasoning_content) # 推理过程
print(response.choices[0].message.content) # 最终结论3.3.2. RAG-增强检索
"语义搜索 " → 通过 "语义理解 " 而非简单的关键词匹配来实现 "精准检索 ",而构建能够 "实时检索相关信息 " 并输入LLM的系统,解决 "幻觉现象 ",生成有事实依据的答案的技术,就是 RAG 。DeepSeek API 本身并不内置 检索增强 模块 (有些LLM厂商会内置,比如 OpenAI 就有),需要用户自行构建一个 RAG系统 (图来源于《图解大模型:生成式AI原理与实战》一书),分为两个阶段:
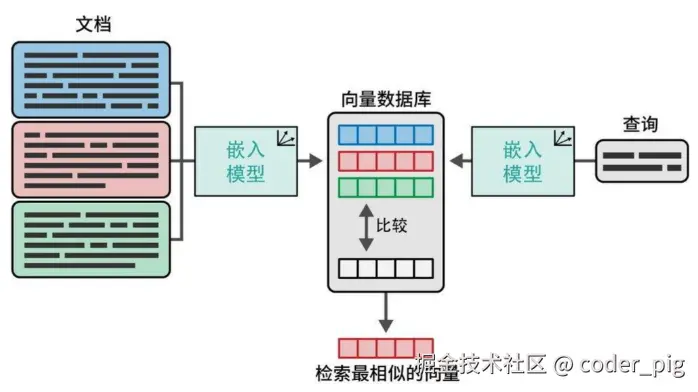
阶段一:离线处理 (知识库的准备) ,只需要做一次,或在知识库更新时才需要做。
① 加载和切分文档
- 将私有知识 (如 PDFs、Markdown、Word 文档、网站内容等) 加载进来。
- 由于 LLM 的上下文窗口有限,您不能把一篇几十页的文档一次性塞进去。
- 因此,需要将文档切分成更小的、有意义的文本块 (Chunks),如:按段落、或固定长度来切分。
② 创建文本嵌入
- 对于每一个文本块,您需要使用一个 文本嵌入模型 (Embedding Model) 将其转换成一个 向量 (一串数字)。这个向量可以被认为是文本块在多维空间中的 "语义坐标"。
- DeepSeek 提供了开源的高性能的文本嵌入模型 → deepseek-text-embedding-v2,可用它实现这一步。
③ 存储到向量数据库
- 将所有的文本块及其对应的向量存储到一个专门的数据库中,常见的 "向量数据库":ChromaDB (适合本地开发)、FAISS (Facebook 开源库)、Pinecone、Milvus、Qdrant 等。
阶段二:在线查询,每次用户与您的 RAG 应用交互时都会发生。
① 检索相关文档
- 当用户提出一个问题时(如 "公司去年的报销政策是什么"),首先,同样使用那个 嵌入模型 将用户的问题也转换成一个向量。
- 然后,拿着这个 "问题向量 " 去向量数据库中进行相似度搜索,找出与问题最相关的几个文本块 (Chunks)。
② 构建 Prompt
- 现在手里有的两样东西:用户的原始问题 + 从知识库中检索到的、最相关的几个文本块。
- 接下来要做的就是将这两者组合成一个 "结构化的Prompt"。
③ 生成答案
- 将这个精心构建的 Prompt 发给 LLM,模型根据您提供的上下文 (检索到的知识) 来回答用户的原始问题。
- 而不是依赖其内部的、可能过时或不相关的知识。
😄 自己折腾一个 RAG系统 肯定是不现实的,找 "托管式RAG/知识库平台 " 才是正路,这类平台的核心价值就是将 RAG 中最复杂的部分 → "文档处理、切分、嵌入、存储、检索 ",封装成一个 "简单的服务",让我们只需专注于业务逻辑和与LLM的交互。问一波AI:

直接 Coze(扣子) ,这个我熟啊,采集我写过的文章,搞个 "个人知识库RAG ",看到知识库那里支持导入 "公众号",立马试试:
扫码授权完却一直失败,后面才发现下面也有一行 "小字",🙂 白开心了...

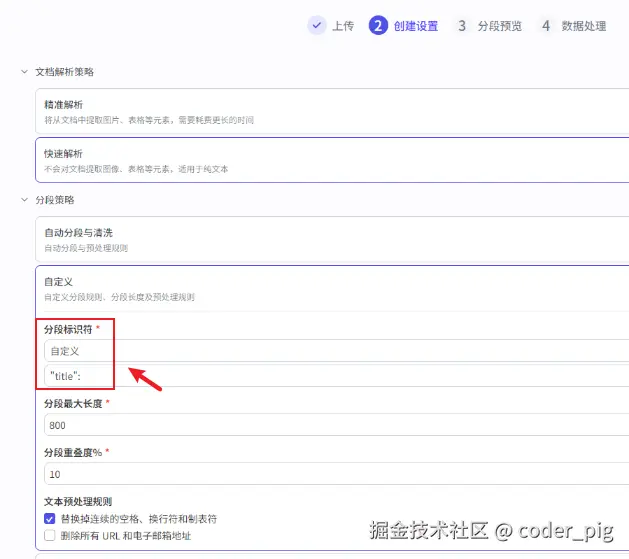
没法直接搞到公号的文章列表,那就导 "掘金 " 的文章吧,试了下:在线数据 → 自动采集 → 添加方式-批量添加 ,主页URL、API接口 (貌似不支持POST) 都不行,直接让AI写个py脚本批量爬取一波,生成一个文章列表的json文件 (包含标题、概述、文章URL) 改为txt文件后,本地内容 导入下文件:

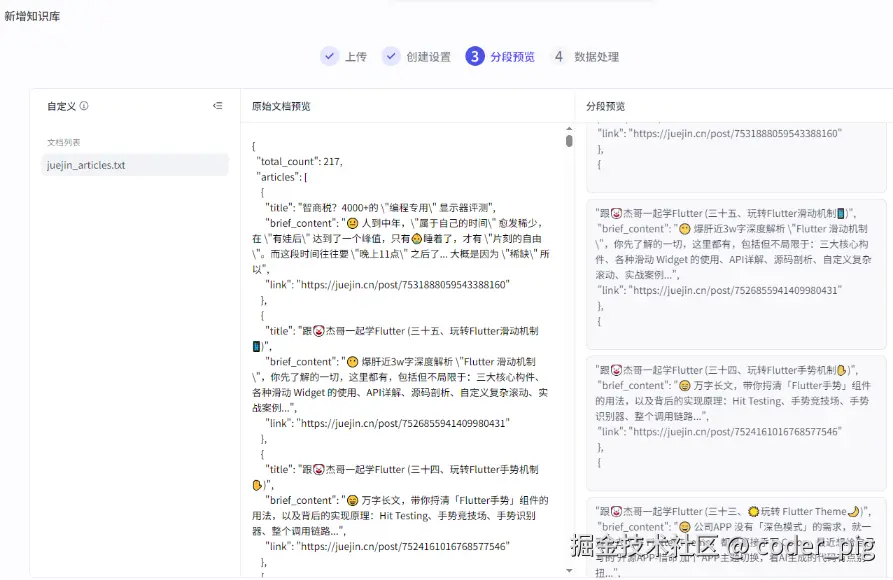
自定义下分段规则,这里直接以 "title" : 作为标识符:
预览看着还行:
然后 "扣子API " 不支持调 "知识库 ",起个 "工作流":
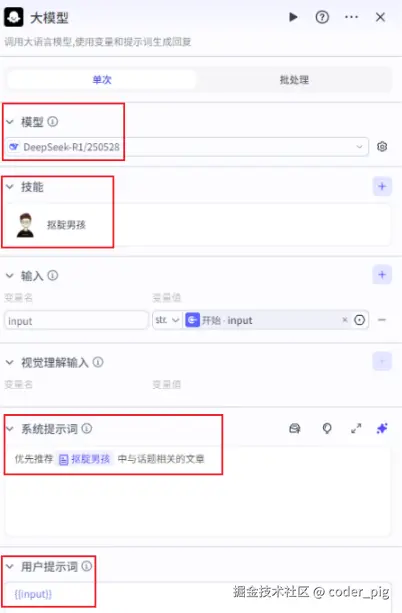
直接拖一个 LLM节点 :模型选 DeepSeek-R1 ,技能配下前面创建的 "知识库 ",系统提示词添加下 约束 ,优先推荐知识库中与话题相关的文章,结果节点把 output 和 reasoning_content 直接返回,测试下问题:"如何学习Xposed插件开发?"
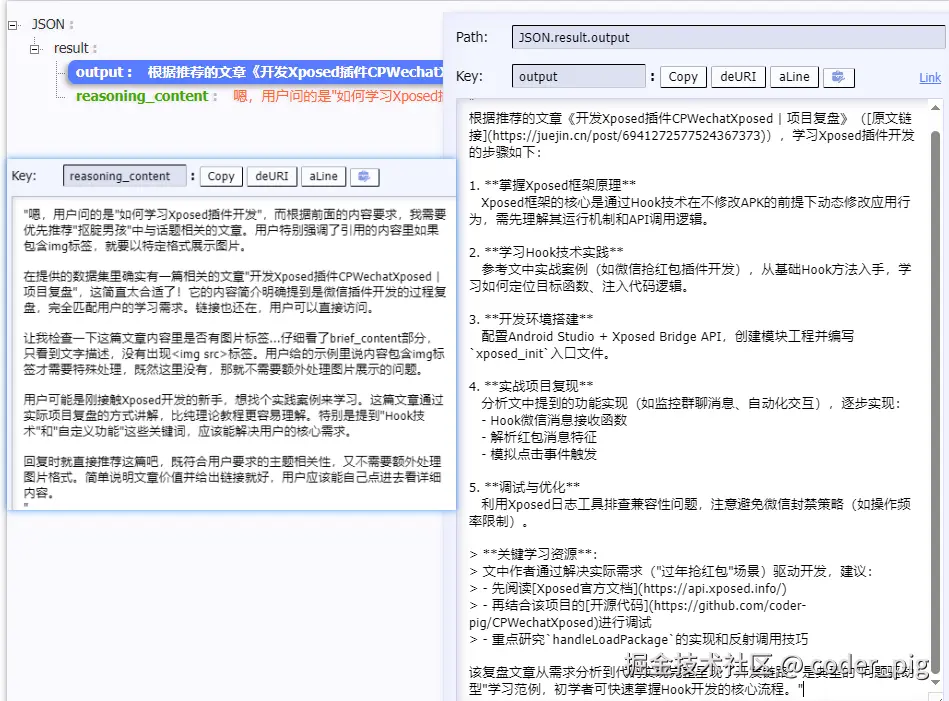
输出结果:
👏 Nice ,借助 Coze ,轻松实现了 RAG 功能,接着发布 工作流 ,就能通过 API调用 进行 增强搜索 了,让AI优化下系统提示词,更精确一点:
python
你是一个文章列表筛选与提取的 API 程序。
你的任务是:分析我提供的{{抠腚男孩}}并根据 {{input}},从中筛选出所有相关的文章,最后以指定的 JSON 格式返回。
# JSON 输出结构:
{
"status": "success",
"query": "用户的原始问题",
"results": [
{
"title": "文章标题",
"brief_content": "文章的简要内容",
"link": "文章的链接"
}
]
}
# 任务指令:
1. **筛选而非生成**:你的核心任务是筛选。仔细阅读{{input}},然后遍历{{抠腚男孩}}中的每一篇文章。
2. **判断标准**:只要一篇文章的 `title` 或 `brief_content` 与{{input}}相关,就应该被包含在最终的 `results` 列表中。
3. **完整返回**:返回所有符合条件的文章对象,确保 `title`, `brief_content`, `link` 字段完整且与原文一致。
4. **无结果处理**:如果在{{抠腚男孩}}中没有找到任何相关的文章,请返回如下 JSON:
{
"status": "not_found",
"query": "用户的原始问题",
"results": []
}
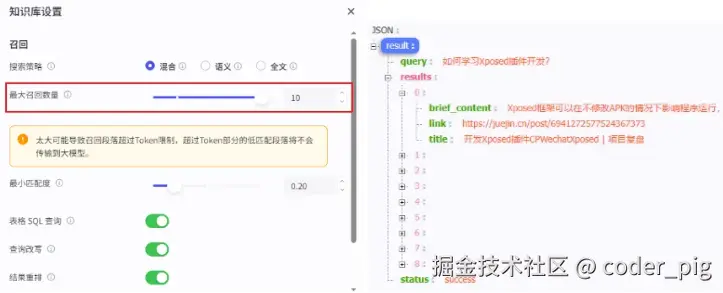
5. **严格遵守格式**:你的整个响应体只能是指定的 JSON 对象,不能有任何解释性文字。知识库设置-召回数量,搞大一点,不然可能只召回一条,我的数据比较小,直接拉满10:
知识库里没有的问题也试试看:
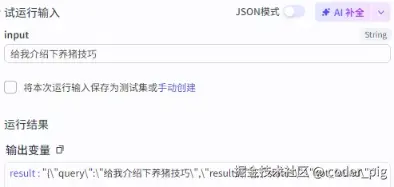
接着直接写个调工作流的方法,并定义工具描述:
python
# 提示词
system_prompt = """你是一位技术博客助手,擅长Android开发、Python、设计模式等技术领域。
当你收到来自'call_coze_workflow'工具的返回结果时,这些结果包含来自'coder-pig'技术博客的相关文章信息。请按照以下步骤处理:
1. 首先分析工具返回的JSON结果,提取文章标题、链接和相关内容
2. 根据这些文章内容回答用户的问题
3. 引用格式:在回答中明确引用文章段落,并在段落后注明[文章标题](文章链接)
4. 优先使用工具返回的文章内容来回答问题
如果工具返回的结果不足以回答问题,或返回内容为空,请坦诚说明,然后基于你的知识提供一般性建议。
回答应该结构清晰,重点突出,并确保所有引用准确可追溯。"""
def call_coze_workflow(query):
"""调用扣子(Coze)运行工作流API"""
url = "https://api.coze.cn/v1/workflow/run"
headers = {
"Authorization": "Bearer key",
"Content-Type": "application/json"
}
data = {
"workflow_id": "7533196746580312083",
"parameters": {
"input": "如何系统学习Python?"
}
}
try:
response = requests.post(url, headers=headers, json=data)
response.raise_for_status()
return response.json()
except Exception as e:
print(f"调用Coze API时出错: {e}")
return {
"status": "error",
"message": str(e),
"query": query,
"results": []
}
# 定义工具描述
coze_tool_description = {
"type": "function",
"function": {
"name": "call_coze_workflow",
"description": "调用扣子(Coze)知识库搜索工作流,查询相关文章信息",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "用户的查询问题"
}
},
"required": ["query"]
}
}
}
# 调 DeepSeek 时调RAG工具
def get_response_with_tools(prompt, temperature=0.7, top_p=0.8, frequency_penalty=0.0):
"""使用工具调用API并打印结果"""
try:
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是一位技术博客助手,可以使用扣子知识库查询相关资料。"},
{"role": "user", "content": prompt}
],
temperature=temperature,
top_p=top_p,
frequency_penalty=frequency_penalty,
tools=[coze_tool_description],
tool_choice="auto"
)
message = response.choices[0].message
# 检查是否有工具调用
if hasattr(message, 'tool_calls') and message.tool_calls:
# 处理工具调用
tool_calls = message.tool_calls
for tool_call in tool_calls:
if tool_call.function.name == "call_coze_workflow":
arguments = json.loads(tool_call.function.arguments)
query = arguments.get("query")
# 调用Coze工作流
coze_result = call_coze_workflow(query)
# 将工具结果发送回DeepSeek
second_response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt},
message.model_dump(),
{
"role": "tool",
"tool_call_id": tool_call.id,
"name": "call_coze_workflow",
"content": json.dumps(coze_result)
}
],
temperature=temperature,
top_p=top_p,
frequency_penalty=frequency_penalty
)
return second_response.choices[0].message.content
return message.content
except Exception as e:
return f"调用API时出错: {e}"静待片刻:
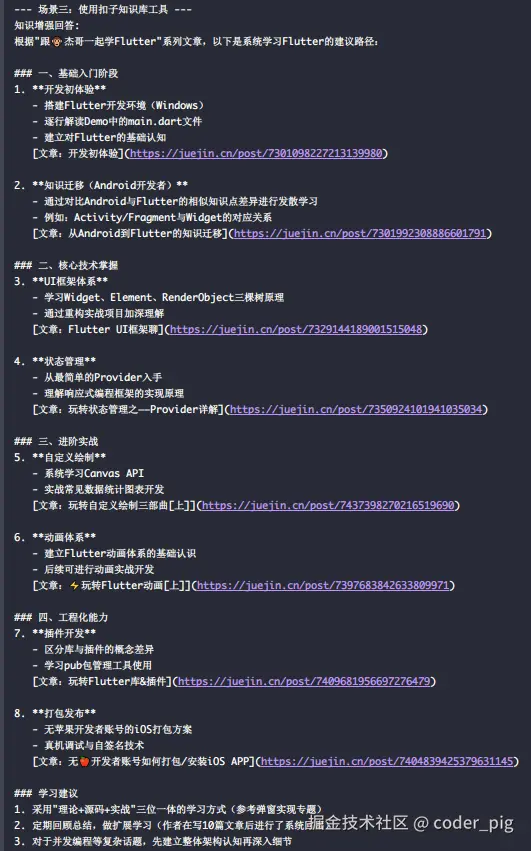
👍 有 RAG 加持,AI生成效果非常符合预期:

预训练/微调 阶段的模型微调,需要自己部署 LLM,后面再试试,篇幅有点长了,本节就先到这吧~