文章目录
-
- [1. 概述](#1. 概述)
- [2. 动态数组](#2. 动态数组)
- [3. 二维数组](#3. 二维数组)
- [4. 局部性原理](#4. 局部性原理)
- [5. 越界检查](#5. 越界检查)
- [6. 习题](#6. 习题)
1. 概述
定义
在计算机科学中,数组是由一组元素(值或变量)组成的数据结构,每个元素有至少一个索引或键来标识
In computer science, an array is a data structure consisting of a collection of elements (values or variables), each identified by at least one array index or key
因为数组内的元素是连续存储的,所以数组中元素的地址,可以通过其索引计算出来,例如:
java
int[] array = {1,2,3,4,5}知道了数组的数据起始地址 B a s e A d d r e s s BaseAddress BaseAddress,就可以由公式 B a s e A d d r e s s + i ∗ s i z e BaseAddress + i * size BaseAddress+i∗size 计算出索引 i i i 元素的地址
- i i i 即索引,在 Java、C 等语言都是从 0 开始
- s i z e size size 是每个元素占用字节,例如 i n t int int 占 4 4 4, d o u b l e double double 占 8 8 8
小测试
java
byte[] array = {1,2,3,4,5}已知 array 的数据的起始地址是 0x7138f94c8,那么元素 3 的地址是什么?
答:0x7138f94c8 + 2 * 1 = 0x7138f94ca
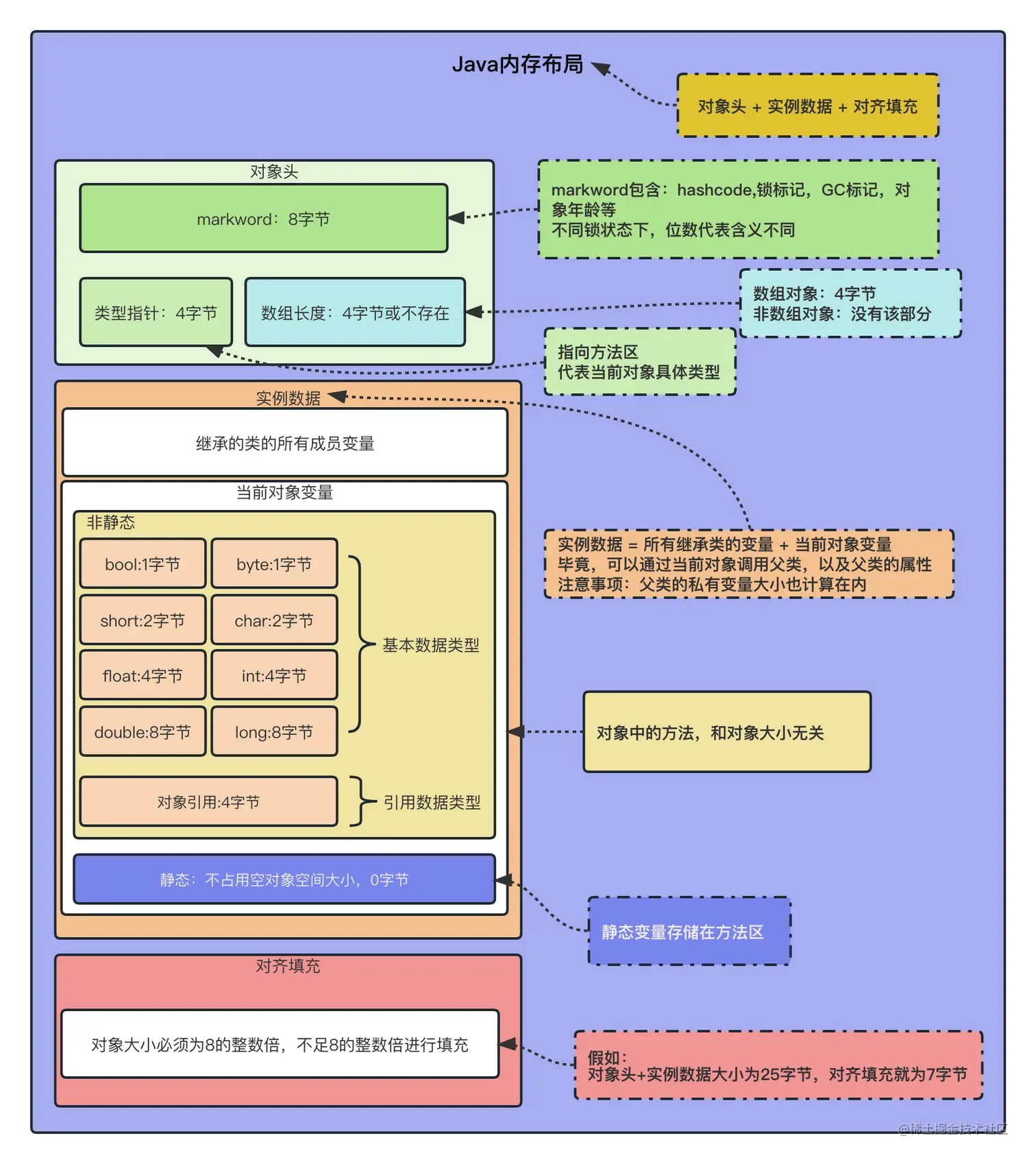
空间占用
Java 中数组结构为
- 8 字节 markword
- 4 字节 class 指针(压缩 class 指针的情况)
- 4 字节 数组大小(决定了数组最大容量是 2 32 2^{32} 232)
- 数组元素 + 对齐字节(java 中所有对象大小都是 8 字节的整数倍\^12,不足的要用对齐字节补足)
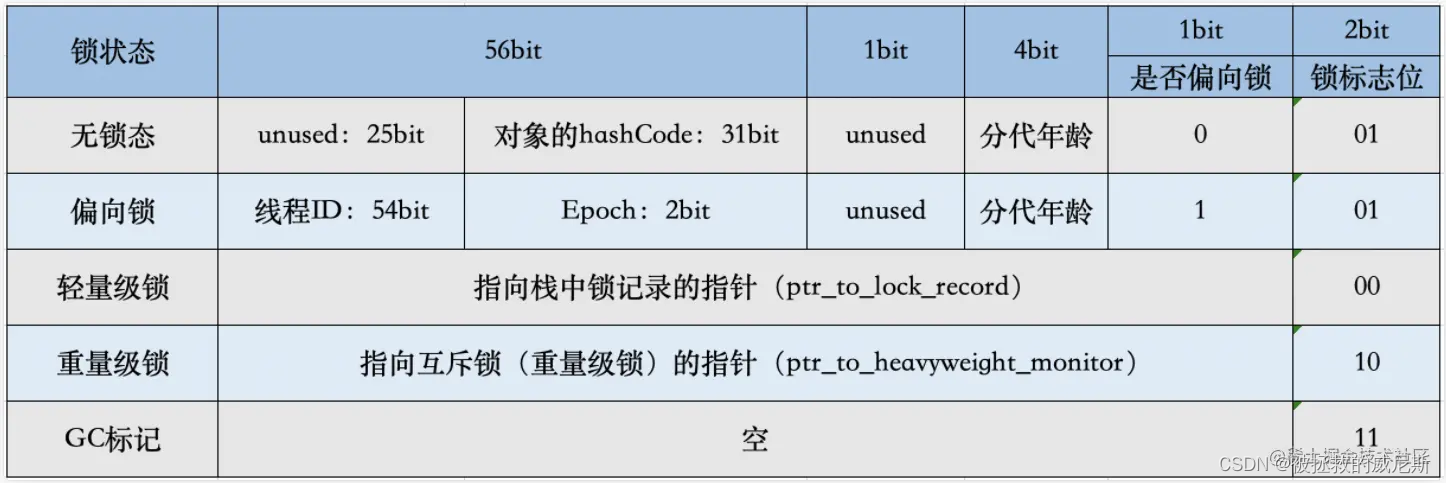
帮助回忆点 :java内存布局
帮助回忆点 : markword图解
例如
java
int[] array = {1, 2, 3, 4, 5};的大小为 40 个字节,组成如下
java
8 + 4 + 4 + 5*4 + 4(alignment)随机访问性能
即根据索引查找元素,时间复杂度是 O ( 1 ) O(1) O(1)
2. 动态数组
java 版本
java
public class DynamicArray implements Iterable<Integer> {
private int size = 0; // 逻辑大小
private int capacity = 8; // 容量
private int[] array = {};
/**
* 向最后位置 [size] 添加元素
*
* @param element 待添加元素
*/
public void addLast(int element) {
add(size, element);
}
/**
* 向 [0 .. size] 位置添加元素
*
* @param index 索引位置
* @param element 待添加元素
*/
public void add(int index, int element) {
checkAndGrow();
// 添加逻辑
if (index >= 0 && index < size) {
// 向后挪动, 空出待插入位置
System.arraycopy(array, index,
array, index + 1, size - index);
}
array[index] = element;
size++;
}
private void checkAndGrow() {
// 容量检查
if (size == 0) {
array = new int[capacity];
} else if (size == capacity) {
// 进行扩容, 1.5 1.618 2
capacity += capacity >> 1;
int[] newArray = new int[capacity];
System.arraycopy(array, 0,
newArray, 0, size);
array = newArray;
}
}
/**
* 从 [0 .. size) 范围删除元素
*
* @param index 索引位置
* @return 被删除元素
*/
public int remove(int index) { // [0..size)
int removed = array[index];
if (index < size - 1) {
// 向前挪动
System.arraycopy(array, index + 1,
array, index, size - index - 1);
}
size--;
return removed;
}
/**
* 查询元素
*
* @param index 索引位置, 在 [0..size) 区间内
* @return 该索引位置的元素
*/
public int get(int index) {
return array[index];
}
/**
* 遍历方法1
*
* @param consumer 遍历要执行的操作, 入参: 每个元素
*/
public void foreach(Consumer<Integer> consumer) {
for (int i = 0; i < size; i++) {
// 提供 array[i]
// 返回 void
consumer.accept(array[i]);
}
}
/**
* 遍历方法2 - 迭代器遍历
*/
@Override
public Iterator<Integer> iterator() {
return new Iterator<Integer>() {
int i = 0;
@Override
public boolean hasNext() { // 有没有下一个元素
return i < size;
}
@Override
public Integer next() { // 返回当前元素,并移动到下一个元素
return array[i++];
}
};
}
/**
* 遍历方法3 - stream 遍历
*
* @return stream 流
*/
public IntStream stream() {
return IntStream.of(Arrays.copyOfRange(array, 0, size));
}
}- 其中 System.arraycopy 参数说明
- 第一个参数:源数组
- 第二个参数:在源数组中,被复制的数字开始复制的下标
- 第三个参数:目标数组
- 第四个参数:从目标数组中,从第几个下标开始放入复制的数据
- 第五个参数:从源数组中,一共拿几个数值放到目标数组中
- 这些方法实现,都简化了 index 的有效性判断,假设输入的 index 都是合法的
测试代码
java
package com.itheima.datastructure.array;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Test;
import java.util.ArrayList;
import java.util.List;
import java.util.function.Consumer;
import static org.junit.jupiter.api.Assertions.*;
public class TestDynamicArray {
@Test
@DisplayName("测试添加")
public void test1() {
DynamicArray dynamicArray = new DynamicArray();
dynamicArray.addLast(1);
dynamicArray.addLast(2);
dynamicArray.addLast(3);
dynamicArray.addLast(4);
// dynamicArray.addLast(5);
dynamicArray.add(2, 5);
assertEquals(1, dynamicArray.get(0));
assertEquals(2, dynamicArray.get(1));
assertEquals(5, dynamicArray.get(2));
assertEquals(3, dynamicArray.get(3));
assertEquals(4, dynamicArray.get(4));
}
@Test
@DisplayName("测试遍历1")
public void test2() {
DynamicArray dynamicArray = new DynamicArray();
dynamicArray.addLast(1);
dynamicArray.addLast(2);
dynamicArray.addLast(3);
dynamicArray.addLast(4);
ResultCollector consumer = new ResultCollector();
dynamicArray.foreach(consumer);
consumer.test(List.of(1, 2, 3, 4));
}
static class ResultCollector implements Consumer<Integer> {
List<Integer> list = new ArrayList<>();
public void accept(Integer element) {
list.add(element);
}
public void test(List<Integer> expected) {
assertIterableEquals(expected, list);
}
}
@Test
@DisplayName("测试遍历2")
public void test3() {
DynamicArray dynamicArray = new DynamicArray();
dynamicArray.addLast(1);
dynamicArray.addLast(2);
dynamicArray.addLast(3);
dynamicArray.addLast(4);
assertIterableEquals(List.of(1, 2, 3, 4), dynamicArray);
}
@Test
@DisplayName("测试遍历3")
public void test4() {
DynamicArray dynamicArray = new DynamicArray();
dynamicArray.addLast(1);
dynamicArray.addLast(2);
dynamicArray.addLast(3);
dynamicArray.addLast(4);
assertArrayEquals(new int[]{1, 2, 3, 4},
dynamicArray.stream().toArray());
}
@Test
@DisplayName("测试删除")
public void test5() {
DynamicArray dynamicArray = new DynamicArray();
dynamicArray.addLast(1);
dynamicArray.addLast(2);
dynamicArray.addLast(3);
dynamicArray.addLast(4);
dynamicArray.addLast(5);
int removed = dynamicArray.remove(4);
assertEquals(5, removed);
assertIterableEquals(List.of(1, 2, 3, 4), dynamicArray);
}
@Test
@DisplayName("测试扩容")
public void test6() {
DynamicArray dynamicArray = new DynamicArray();
for (int i = 0; i < 9; i++) {
dynamicArray.addLast(i + 1);
}
assertIterableEquals(
List.of(1, 2, 3, 4, 5, 6, 7, 8, 9),
dynamicArray
);
}
}插入或删除性能
头部位置,时间复杂度是 O ( n ) O(n) O(n)
中间位置,时间复杂度是 O ( n ) O(n) O(n)
尾部位置,时间复杂度是 O ( 1 ) O(1) O(1)(均摊来说)
3. 二维数组
java
int[][] array = {
{11, 12, 13, 14, 15},
{21, 22, 23, 24, 25},
{31, 32, 33, 34, 35},
};内存图如下
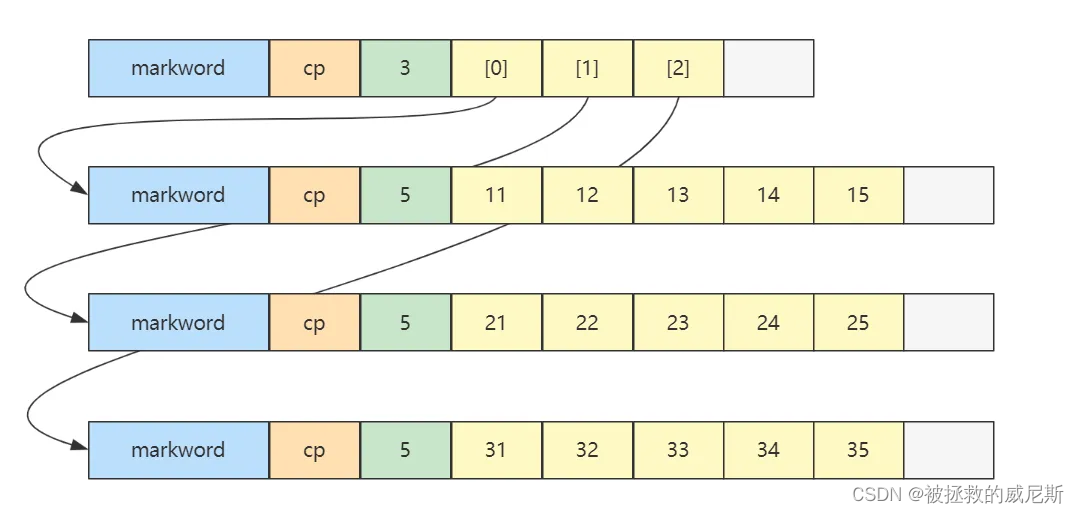
- 二维数组占 32 个字节,其中 array0,array1,array2 三个元素分别保存了指向三个一维数组的引用
- 三个一维数组各占 40 个字节
- 它们在内层布局上是连续的
更一般的,对一个二维数组 A r r a y m n Arraymn Arraymn
- m m m 是外层数组的长度,可以看作 row 行
- n n n 是内层数组的长度,可以看作 column 列
- 当访问 A r r a y i j Arrayij Arrayij, 0 ≤ i < m , 0 ≤ j < n 0\leq i \lt m, 0\leq j \lt n 0≤i<m,0≤j<n时,就相当于
- 先找到第 i i i 个内层数组(行)
- 再找到此内层数组中第 j j j 个元素(列)
小测试
Java 环境下(不考虑类指针和引用压缩,此为默认情况),有下面的二维数组
java
byte[][] array = {
{11, 12, 13, 14, 15},
{21, 22, 23, 24, 25},
{31, 32, 33, 34, 35},
};已知 array 对象起始地址是 0x1000,那么 23 这个元素的地址是什么?
答:
- 起始地址 0x1000
- 外层数组大小:16字节对象头 + 3元素 * 每个引用4字节 + 4 对齐字节 = 32 = 0x20
- 第一个内层数组大小:16字节对象头 + 5元素 * 每个byte1字节 + 3 对齐字节 = 24 = 0x18
- 第二个内层数组,16字节对象头 = 0x10,待查找元素索引为 2
- 最后结果 = 0x1000 + 0x20 + 0x18 + 0x10 + 2*1 = 0x104a
4. 局部性原理
这里只讨论空间局部性
- cpu 读取内存(速度慢)数据后,会将其放入高速缓存(速度快)当中,如果后来的计算再用到此数据,在缓存中能读到的话,就不必读内存了
- 缓存的最小存储单位是缓存行(cache line),一般是 64 bytes,一次读的数据少了不划算啊,因此最少读 64 bytes 填满一个缓存行,因此读入某个数据时也会读取其临近的数据,这就是所谓空间局部性
对效率的影响
比较下面 ij 和 ji 两个方法的执行效率
java
int rows = 1000000;
int columns = 14;
int[][] a = new int[rows][columns];
StopWatch sw = new StopWatch();
sw.start("ij");
ij(a, rows, columns);
sw.stop();
sw.start("ji");
ji(a, rows, columns);
sw.stop();
System.out.println(sw.prettyPrint());ij 方法
java
public static void ij(int[][] a, int rows, int columns) {
long sum = 0L;
for (int i = 0; i < rows; i++) {
for (int j = 0; j < columns; j++) {
sum += a[i][j];
}
}
System.out.println(sum);
}ji 方法
java
public static void ji(int[][] a, int rows, int columns) {
long sum = 0L;
for (int j = 0; j < columns; j++) {
for (int i = 0; i < rows; i++) {
sum += a[i][j];
}
}
System.out.println(sum);
}执行结果
java
0
0
StopWatch '': running time = 96283300 ns
---------------------------------------------
ns % Task name
---------------------------------------------
016196200 017% ij
080087100 083% ji可以看到 ij 的效率比 ji 快很多,为什么呢?
- 缓存是有限的,当新数据来了后,一些旧的缓存行数据就会被覆盖
- 如果不能充分利用缓存的数据,就会造成效率低下
以 ji 执行为例,第一次内循环要读入 0 , 0 0,0 0,0 这条数据,由于局部性原理,读入 0 , 0 0,0 0,0 的同时也读入了 0 , 1 . . . 0 , 13 0,1 ... 0,13 0,1...0,13,如图所示
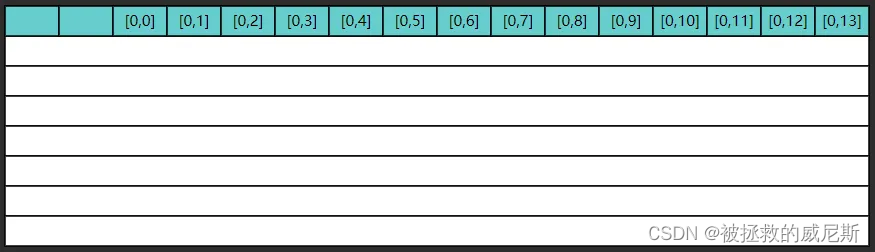
但很遗憾,第二次内循环要的是 1 , 0 1,0 1,0 这条数据,缓存中没有,于是再读入了下图的数据
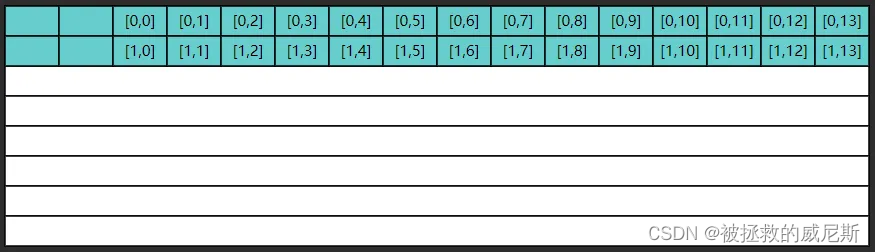
这显然是一种浪费,因为 0 , 1 . . . 0 , 13 0,1 ... 0,13 0,1...0,13 包括 1 , 1 . . . 1 , 13 1,1 ... 1,13 1,1...1,13 这些数据虽然读入了缓存,却没有及时用上,而缓存的大小是有限的,等执行到第九次内循环时
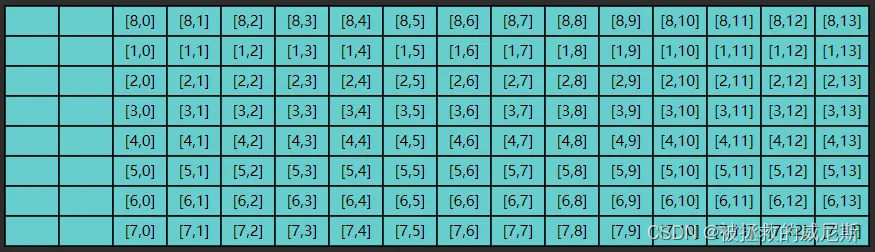
缓存的第一行数据已经被新的数据 8 , 0 . . . 8 , 13 8,0 ... 8,13 8,0...8,13 覆盖掉了,以后如果再想读,比如 0 , 1 0,1 0,1,又得到内存去读了
同理可以分析 ij 函数则能充分利用局部性原理加载到的缓存数据
举一反三
- I/O 读写时同样可以体现局部性原理
- 数组可以充分利用局部性原理,那么链表呢?
答:链表不行,因为链表的元素并非相邻存储
5. 越界检查
java 中对数组元素的读写都有越界检查,类似于下面的代码
java
bool is_within_bounds(int index) const
{
return 0 <= index && index < length();
}- 代码位置:
openjdk\src\hotspot\share\oops\arrayOop.hpp
只不过此检查代码,不需要由程序员自己来调用,JVM 会帮我们调用
6. 习题
E01. 合并有序数组 - 对应 Leetcode 88
将数组内两个区间内的有序元素合并
例
java
[1, 5, 6, 2, 4, 10, 11]可以视作两个有序区间
java
[1, 5, 6] 和 [2, 4, 10, 11]合并后,结果仍存储于原有空间
java
[1, 2, 4, 5, 6, 10, 11]方法1
递归
- 每次递归把更小的元素复制到结果数组
java
merge(left=[1,5,6],right=[2,4,10,11],a2=[]){
merge(left=[5,6],right=[2,4,10,11],a2=[1]){
merge(left=[5,6],right=[4,10,11],a2=[1,2]){
merge(left=[5,6],right=[10,11],a2=[1,2,4]){
merge(left=[6],right=[10,11],a2=[1,2,4,5]){
merge(left=[],right=[10,11],a2=[1,2,4,5,6]){
// 拷贝10,11
}
}
}
}
}
}代码
java
public static void merge(int[] a1, int i, int iEnd, int j, int jEnd,
int[] a2, int k) {
if (i > iEnd) {
System.arraycopy(a1, j, a2, k, jEnd - j + 1);
return;
}
if (j > jEnd) {
System.arraycopy(a1, i, a2, k, iEnd - i + 1);
return;
}
if (a1[i] < a1[j]) {
a2[k] = a1[i];
merge(a1, i + 1, iEnd, j, jEnd, a2, k + 1);
} else {
a2[k] = a1[j];
merge(a1, i, iEnd, j + 1, jEnd, a2, k + 1);
}
}测试
java
int[] a1 = {1, 5, 6, 2, 4, 10, 11};
int[] a2 = new int[a1.length];
merge(a1, 0, 2, 3, 6, a2, 0);解析:该方法用于实现归并排序算法中的"合并"步骤。其功能是将两个已排序的子数组a1[i...iEnd]和a1[j...jEnd]合并成一个有序的大数组,并将结果存储在a2中从下标k开始的位置。下面是该函数的详细工作流程:
- 基本情况检查:
- 首先检查第一个子数组是否已经全部处理完毕(即
i > iEnd),如果是,则将第二个子数组a1[j...jEnd]的剩余部分直接复制到结果数组a2的相应位置(从下标k开始)。 - 然后检查第二个子数组是否已经全部处理完毕(即
j > jEnd),如果是,则将第一个子数组a1[i...iEnd]的剩余部分直接复制到结果数组a2的相应位置(从下标k开始)。
- 首先检查第一个子数组是否已经全部处理完毕(即
- 选择较小元素:
- 如果上述两个基本情况都不满足,函数会比较
a1[i]和a1[j]的值。 - 如果
a1[i]小于a1[j],则将a1[i]复制到结果数组a2的当前下标k处,并对第一个子数组的下一个元素进行递归调用(即将i加1),同时结果数组的下标k也加1,继续比较。 - 否则,如果
a1[j]小于等于a1[i],则将a1[j]复制到结果数组a2的当前下标k处,并对第二个子数组的下一个元素进行递归调用(即将j加1),同时结果数组的下标k也加1,继续比较。
- 如果上述两个基本情况都不满足,函数会比较
- 递归合并:
- 通过上述选择和递归调用的过程,函数不断地将较小的元素加入到结果数组中,直至某一个子数组的所有元素都被处理完,此时根据基本情况检查的逻辑,直接将另一个子数组的剩余部分复制到结果数组中。
- 终止条件:
- 当两个子数组的所有元素都已经被处理(即递归到达叶子节点,两个子数组都为空),实际上不需要显式处理,因为之前的递归调用已经完成了所有元素的合并。
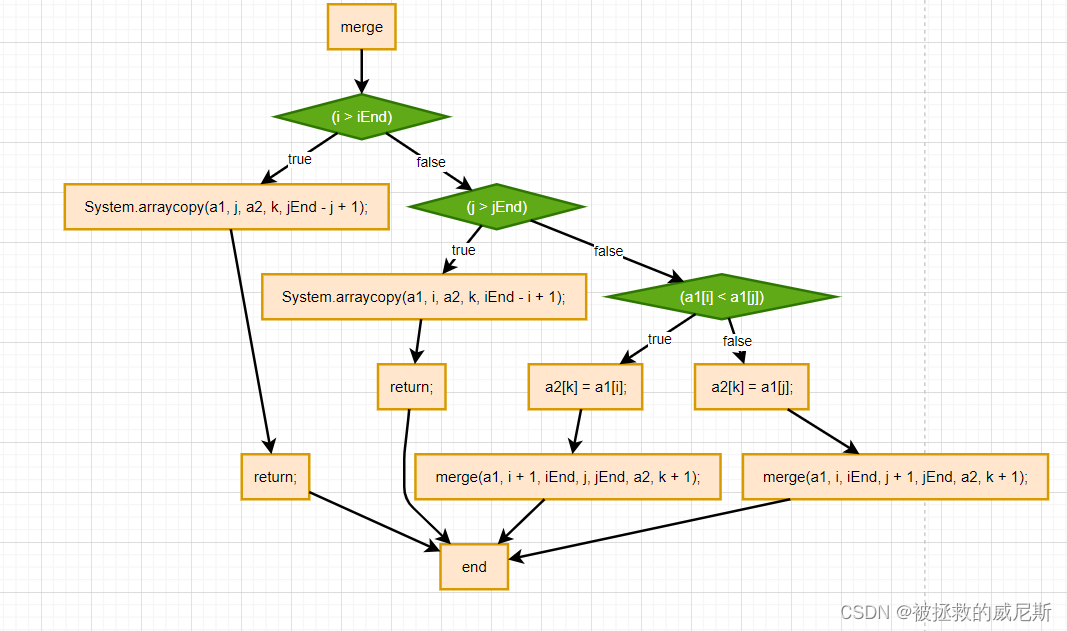
总结来说,这个merge函数通过递归地比较并选择两个有序数组中的最小元素来逐步构建一个更大的有序数组,是归并排序算法核心步骤的具体实现。
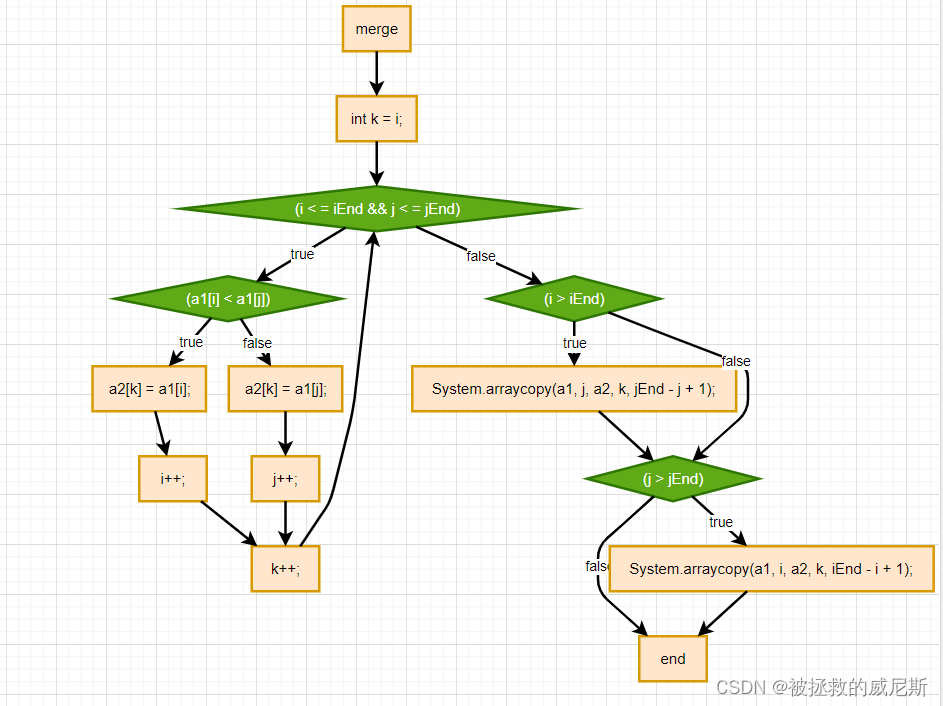
方法2
代码
java
public static void merge(int[] a1, int i, int iEnd,
int j, int jEnd,
int[] a2) {
int k = i;
while (i <= iEnd && j <= jEnd) {
if (a1[i] < a1[j]) {
a2[k] = a1[i];
i++;
} else {
a2[k] = a1[j];
j++;
}
k++;
}
if (i > iEnd) {
System.arraycopy(a1, j, a2, k, jEnd - j + 1);
}
if (j > jEnd) {
System.arraycopy(a1, i, a2, k, iEnd - i + 1);
}
}测试
java
int[] a1 = {1, 5, 6, 2, 4, 10, 11};
int[] a2 = new int[a3.length];
merge(a1, 0, 2, 3, 6, a2);该方法实现了合并两个有序数组的功能。它将数组a1中从位置i到位置iEnd的元素和从位置j到位置jEnd的元素合并到数组a2中,并保持合并后的数组有序。具体实现过程如下:
- 初始化变量
k为i,用于表示合并后数组a2的当前位置。 - 当i小于等于
iEnd且j小于等于jEnd时,进行循环。 - 如果
a1[i]小于a1[j],则将a1[i]赋值给a2[k],并将i增加1;否则将a1[j]赋值给a2[k],并将j增加1。 - 将
k增加1。 - 如果i大于
iEnd,说明数组a1中从位置i开始的元素已经全部合并到a2中,此时将数组a1中从位置j开始剩余的元素复制到a2中,从位置k开始。 - 如果j大于
jEnd,说明数组a1中从位置j开始的元素已经全部合并到a2中,此时将数组a1中从位置i开始剩余的元素复制到a2中,从位置k开始。