随着自动驾驶技术的不断发展,基于摄像头的感知系统已成为关键,而Bird's Eye View (BEV)大模型在其中发挥着重要作用。BEV大模型是一种将摄像头捕捉到的2D图像转换为自上而下视角的3D感知的技术,使得车辆能够更好地理解周围环境。
BEV大模型通过提升环境感知能力、增强决策和规划、降低硬件依赖以及推动技术创新,显著加速了自动驾驶汽车的发展进程。
本文分享不同视角的BEV的最新研究论文研究,旨在为学习BEV、端到端的学员分享一些内容参考。
mer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
BEVFormer是一种基于多相机图像的自动驾驶视觉感知新方法。该方法利用Transformer和时序结构生成鸟瞰视图(BEV)特征,支持多种自动驾驶感知任务。BEVFormer通过空间和时间查询与空间和时间空间进行交互,聚合时空信息,从而获得更强大的表示能力。在nuScenes测试集上,该方法达到了新的技术水平,超越了以前的最优方法,并与激光雷达基准方法的性能相当。

完整论文下载,BEVForme
CenterNet: Keypoint Triplets for Object Detection
本文提出了一种名为CenterNet的高效物体检测方法,该方法基于关键点三元组而非传统的关键点对进行物体检测,从而提高了检测的精度和召回率。CenterNet在CornerNet这一代表性的一阶段关键点检测器的基础上构建,并设计了两个定制模块:级联角点池化和中心池化,以丰富从左上角和右下角收集的信息。这种方法通过探索每个裁剪区域内的视觉模式,以最小的成本提高了物体检测的准确性。

完整资料下载:CenterNet
BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation
本文提出了BEVFusion,一个高效且通用的多任务多传感器融合框架,用于自动驾驶系统。该框架打破了传统的点级融合方式,将多模态特征统一在共享的鸟瞰视图(BEV)表示空间中,从而很好地保留了几何和语义信息。通过优化BEV池化,解决了视图转换中的关键效率瓶颈,降低了延迟。BEVFusion具有任务无关性,几乎无需架构更改即可支持不同的3D感知任务。在nuScenes数据集上,BEVFusion在3D目标检测和BEV地图分割任务上均达到了新的先进水平,同时降低了计算成本。

完整资料下载,BEVFusion
LSS: Lift, Splat, Shoot: Representing Scenes from Bird's-Eye View with Lifting and Splattering
这篇文档的主题是通过隐含地将任意相机支架的图像导出到3D空间来编码图像,来自NVIDIA多伦多vector研究所的Jonah Philion和Sja Fidler。他们提出了一种新的端到端架构,可以从任意数量的相机获取图像数据,直接提取场景的 bird's-eye-view 表示,并将其用于 motion planning。该架构的核心思想是" lift"每个图像 individual 地将其特征面提取到每个相机的凸包上,然后"splat"所有凸包到一个栅格化的 bird's-eye-view 网格上。通过训练整个相机支架,我们提供了证据表明,我们的模型不仅可以表示图像,还可以将所有相机的预测融合到一个单一的连贯表示中,同时 robust 到校准误差。在标准 bird's-eye-view 任务中,例如物体分割和地图分割,我们的模型优于所有基准线和先前工作。为了学习用于 motion planning 密集表示的DenseRepresentations,我们表明,我们的模型表示的表示可以用于解释端到端 motion planning,通过" shooting" 模板轨迹到 bird's-eyeview 成本矩阵中。

完整资料下载:LSS
PETR: Position Embedding Transformation for Multi-View 3D Object Detection
本文提出了一个名为PETR的多视角3D目标检测框架。PETR通过编码3D坐标信息到图像特征中,生成3D位置感知特征。目标查询可以直接与这些特征进行交互,执行端到端的3D目标检测。PETR在标准nuScenes数据集上达到了领先水平,排名第一。该方法简单但强大,为未来研究提供了基线。重点内容:1. PETR用于多视角3D目标检测。2. 通过编码3D坐标信息到图像特征中,生成3D位置感知特征。3. 目标查询直接与3D位置感知特征交互,进行端到端的目标检测。4. PETR在nuScenes数据集上表现优秀,提供简单而强大的基线。
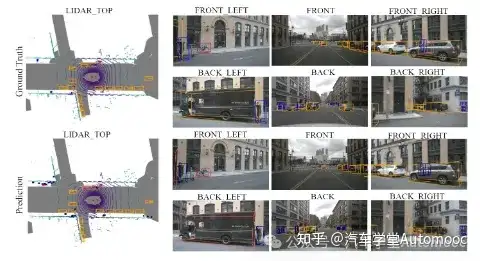
完整资料下载:PETR
BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
本文提出了一种高效的3D目标检测范式BEVDet,通过优化数据增强和非极大值抑制策略,实现了在鸟瞰视角下的高性能检测,为自主驾驶中的环境感知提供了新的解决方案。
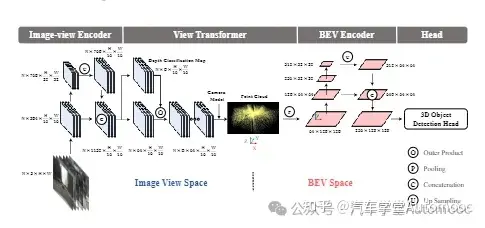
完整资料下载:BEVDet
MotionNet: Joint Perception and Motion Prediction for Autonomous Driving Based on Bird's Eye View Maps
主要介绍了一个用于自动驾驶的跟踪与3D物体轨迹检测预测系统,该系统包括3D边界框、运动预测、MotionNet规划以及基于LiDAR点云的BEV地图(包含运动和类别信息)。特别地,提到了一个名为MotionNet的模型,该模型能够联合执行从3D点云中感知和预测运动的任务。MotionNet以LiDAR扫描序列作为输入,输出鸟瞰图(BEV)地图。此外,还讨论了不同时空卷积方法以及BEV地图中二进制体素分辨率对模型性能的影响。总结来说,该内容描述了一个用于自动驾驶的3D物体检测和轨迹预测系统,重点介绍了其中的MotionNet模型及其性能优化方法。

完整资料下载:MotionNet
Cross-View Transformers for Real-Time Map-View Semantic Segmentation
Cross-view Transformers是一种高效的基于注意力的模型,用于从多个摄像头进行地图视角的语义分割。该模型通过相机感知的跨视角嵌入注意力机制,隐式地学习从单个相机视角到规范地图视角的映射。每个相机使用依赖于其内在和外在校准的位置嵌入,使Transformer能够在不显式进行几何建模的情况下学习不同视角之间的映射。该架构包括每个视角的卷积图像编码器和跨视角Transformer层,以推断地图视角的语义分割。该模型简单、易于并行化,并实时运行。在nuScenes数据集上,该架构的性能达到了业界领先水平,且推理速度提高了4倍。

完整资料下载:Cross-View
Self-Supervised Pillar Motion Learning for Autonomous Driving
本文提出了一种自监督的支柱运动学习方法,用于自动驾驶中的运动行为理解。该方法利用点云和配对相机图像中的免费监督信号进行纯自监督运动估计,无需大量标注的自驾驶场景训练数据。模型通过结构一致性增强和跨传感器运动正则化实现自监督。实验表明,该方法与监督方法相比具有竞争力。

完整资料下载:Self-Supervised
内容来源:汽车学堂Automooc