MSVTNet: 基于多尺度视觉Transformer的运动想象EEG分类模型
- 1、研究背景与问题提出
-
- [1.1 脑机接口与运动想象解码](#1.1 脑机接口与运动想象解码)
- [1.2 现有方法的局限性](#1.2 现有方法的局限性)
-
- [1.2.1 传统方法:依赖神经生理先验的浅层建模](#1.2.1 传统方法:依赖神经生理先验的浅层建模)
- [1.2.2 深度学习方法:表达能力增强但结构设计仍存不足](#1.2.2 深度学习方法:表达能力增强但结构设计仍存不足)
- [1.3 MSVTNet 的提出动机](#1.3 MSVTNet 的提出动机)
- [2、MSVTNet 模型架构](#2、MSVTNet 模型架构)
-
- [2.1 输入表示](#2.1 输入表示)
- [2.2 多尺度时空卷积模块(MSST)](#2.2 多尺度时空卷积模块(MSST))
- [2.3 跨尺度全局时间编码器(CSGT)](#2.3 跨尺度全局时间编码器(CSGT))
- [2.4 辅助分支损失(ABL)](#2.4 辅助分支损失(ABL))
- [2.5 分类头与联合损失](#2.5 分类头与联合损失)
- 3、实验设计与对比基线模型
-
- [3.1 数据集介绍](#3.1 数据集介绍)
- [3.2 数据预处理流程](#3.2 数据预处理流程)
- [3.3 实验设置](#3.3 实验设置)
-
- [3.3.1 被试内实验(Subject-Dependent)](#3.3.1 被试内实验(Subject-Dependent))
- [3.3.2 跨被试实验(Subject-Independent)](#3.3.2 跨被试实验(Subject-Independent))
- [3.4 对比 Baseline 模型](#3.4 对比 Baseline 模型)
- [3.5 训练细节](#3.5 训练细节)
- [3.6 评价指标](#3.6 评价指标)
- [4. 实验结果与讨论分析](#4. 实验结果与讨论分析)
-
- [4.1 整体MI-EEG解码性能分析](#4.1 整体MI-EEG解码性能分析)
- [4.2 特征与分类结果可视化分析](#4.2 特征与分类结果可视化分析)
- [4.3 核心模块消融实验](#4.3 核心模块消融实验)
- [4.4 关键超参数与设计机制敏感性分析](#4.4 关键超参数与设计机制敏感性分析)
-
- [4.4.1 多尺度分支数(B)与滤波器数(Fb)](#4.4.1 多尺度分支数(B)与滤波器数(Fb))
- [4.4.2 Transformer 层数(L)与多头注意力头数(H)](#4.4.2 Transformer 层数(L)与多头注意力头数(H))
- [4.4.3 ABL 损失权衡因子 λ λ λ](#4.4.3 ABL 损失权衡因子 λ λ λ)
- [4.4.4 S&R 数据增强参数](#4.4.4 S&R 数据增强参数)
- [4.5 注意力机制与特征映射可视化分析](#4.5 注意力机制与特征映射可视化分析)
- [4.6 模型局限性与未来优化方向](#4.6 模型局限性与未来优化方向)
- [5. 参考文献](#5. 参考文献)
本文围绕脑机接口(BCI)中的核心问题------运动想象(MI)脑电(EEG)解码展开。由于 EEG 信号信噪比低、非平稳性强、个体差异明显,同时又包含复杂的多尺度时空特征,使得高精度解码始终具有挑战性。
传统方法依赖神经生理先验与手工特征设计,泛化能力有限;深度学习方法虽然提升了自动特征学习能力,但仍存在不足:CNN 更擅长局部特征提取,却难以建模长时依赖;Transformer 具备全局建模能力,却往往忽略不同时间尺度之间的特征交互。
为此,本文提出 MSVTNet(Multi-Scale Vision Transformer Network)。该模型结合多尺度卷积与 Transformer 结构:通过多分支卷积提取不同时间尺度的局部特征,再利用自注意力机制建模全局时序依赖,并引入辅助分支损失增强训练稳定性与特征表达能力。
在 BCIC-IV-2a、BCIC-IV-2b 和 OpenBMI 三个公开数据集上的实验表明,MSVTNet 在被试内和被试间设置下均取得了优于多种主流方法的性能表现,尤其在跨被试泛化任务中优势明显。本文将系统介绍模型结构、实验设计以及性能分析,并探讨其在实际脑机接口应用中的潜力。
该论文发表在SCI中科院二区Top期刊 IEEE JOURNAL OF BIOMEDICAL AND HEALTH INFORMATICS 上,2025年实时影响因子为 I F = 6.8 IF=6.8 IF=6.8,论文地址为《MSVTNet: Multi-Scale Vision Transformer Neural Network for EEG-Based Motor Imagery Decoding》,Github开源的模型实现代码链接为 MSVTNet-Pytorch
1、研究背景与问题提出
1.1 脑机接口与运动想象解码
脑机接口(Brain--Computer Interface, BCI)通过采集和解析大脑神经活动,实现大脑与外部设备之间的直接信息交互 [1](#1)。在众多实现路径中,基于脑电图(Electroencephalography, EEG)的运动想象(Motor Imagery, MI)解码因其非侵入性、低成本、可实时性强 等优势,成为当前研究最为活跃的方向之一,并在残疾人辅助控制、虚拟现实交互、外骨骼与机械臂控制等领域展现出广阔应用前景 [2](#2)。
然而,MI-EEG 解码仍面临一系列核心挑战:
- 信号信噪比低、非平稳性强:EEG 属于微伏级电信号,易受生理与环境噪声干扰,同时呈现明显的时变特性;
- 个体差异显著、数据规模受限:不同被试间神经模式差异较大,而高质量标注数据获取成本较高;
- 多尺度与多机制特征耦合复杂:有效解码不仅需要捕捉局部时空模式,还需建模长时序依赖关系,并考虑跨频率耦合(Cross-Frequency Coupling, CFC)等潜在神经动力学机制。
因此,如何在复杂神经动力学背景下构建兼具多尺度建模能力与全局依赖建模能力的高效解码模型,成为 MI-EEG 研究的重要课题。
1.2 现有方法的局限性
1.2.1 传统方法:依赖神经生理先验的浅层建模
传统 MI-EEG 解码方法通常依赖手工特征设计,基于神经生理学中的事件相关去同步化/同步化(Event-Related Desynchronization/Synchronization, ERD/ERS)机制进行建模 [3](#3)。
在运动想象过程中,感觉运动皮层区域的 μ \mu μ(8--13 Hz)与 β \beta β(13--30 Hz)节律通常会出现显著功率下降(ERD);而在运动结束后,相关节律功率会反弹增强(ERS)^[4](#在运动想象过程中,感觉运动皮层区域的 μ \mu μ(8–13 Hz)与 β \beta β(13–30 Hz)节律通常会出现显著功率下降(ERD);而在运动结束后,相关节律功率会反弹增强(ERS)4)^。基于这一规律,经典方法通常结合:
- 共空间模式(Common Spatial Pattern, CSP)提取判别性空间特征;
- 支持向量机(Support Vector Machine, SVM) 或 线性判别分析(Linear Discriminant Analysis, LDA) 完成分类决策。
尽管此类方法在小样本场景下具有一定稳定性,但其主要局限在于:
- 强依赖人工特征设计与频带选择;
- 难以刻画复杂的非线性神经动力学过程;
- 泛化能力有限,对跨被试场景适应性较弱。
1.2.2 深度学习方法:表达能力增强但结构设计仍存不足
近年来,深度学习方法显著提升了 MI-EEG 解码性能,但仍存在结构层面的局限性:
-
CNN 类方法
卷积神经网络能够自动学习局部时空特征,但其感受野受限,本质上偏向局部建模,难以有效捕捉长时序全局依赖关系。
-
Transformer 类方法
Transformer 通过自注意力机制建模全局依赖,在时序建模方面具有天然优势。然而,直接应用于 EEG 信号时往往忽略:
- 不同时间尺度特征之间的交互;
- 跨频率耦合等多频段神经信息;
- 与 CNN 融合时可能存在参数规模不均衡与训练不稳定问题。
-
多尺度结构设计不足
现有多分支或多尺度结构多采用简单并行拼接策略,缺乏对不同尺度特征之间交互关系的深度建模,从而限制了特征表达的充分性。
1.3 MSVTNet 的提出动机
针对上述问题,本文提出 MSVTNet(Multi-Scale Vision Transformer Neural Network),构建一种融合多尺度卷积建模与全局自注意力机制的混合架构,实现对 MI-EEG 信号的高效解码。
MSVTNet 的核心思想可以概括为三点:
- 多尺度结构化表征:通过多尺度卷积模块对 EEG 信号进行结构化建模,显式提取不同时间尺度下的判别特征,从而增强局部时频模式表达能力;
- 全局依赖建模:引入 Vision Transformer 结构,通过自注意力机制捕捉跨时间、跨通道的全局交互关系;
- 多分支联合监督机制:构建辅助分支损失函数,对不同层级特征施加约束与监督,缓解深层网络训练不稳定问题,提升特征融合质量与整体解码性能。
通过上述设计,MSVTNet 在保持局部特征建模能力的同时,进一步增强了全局信息整合能力,实现多尺度特征与全局依赖关系的协同优化,为 MI-EEG 解码提供了一种更加系统化与结构化的解决方案。
2、MSVTNet 模型架构
为同时解决 MI-EEG 解码中的多尺度建模不足与全局依赖建模能力有限的问题,MSVTNet(Multi-Scale Vision Transformer Neural Network)构建了一种 多分支卷积 + 全局 Transformer 编码 + 多分支联合监督 的混合架构。
整体结构如下图 Fig.1 所示,模型主要由四个核心模块组成:
- 多尺度时空卷积模块(Multi-Scale Spatio-Temporal Convolution, MSST)
- 跨尺度全局时间编码器(Cross-Scale Global Temporal Encoder, CSGT)
- 辅助分支损失模块(Auxiliary Branch Loss, ABL)
- 最终分类头(Classification Head, CLS)
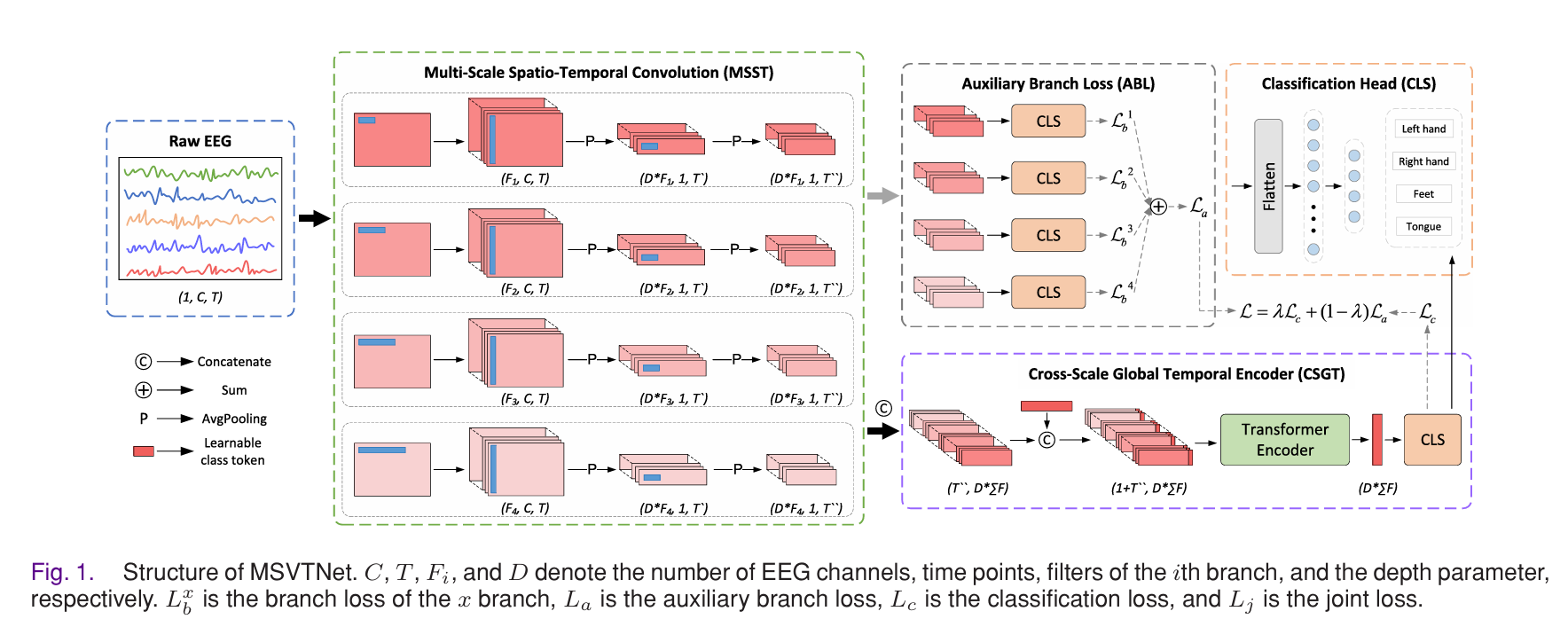
2.1 输入表示
给定原始 EEG 信号:
X ∈ R C × T (1) \mathbf{X} \in \mathbb{R}^{C \times T} \tag{1} X∈RC×T(1)
其中:
- C C C 表示 EEG 通道数
- T T T 表示时间采样点数
模型的目标是学习一个映射函数:
f θ : R C × T → R K (2) f_\theta: \mathbb{R}^{C \times T} \rightarrow \mathbb{R}^{K} \tag{2} fθ:RC×T→RK(2)
其中 K K K 为运动想象类别数。
2.2 多尺度时空卷积模块(MSST)
(1)多分支卷积建模
MSVTNet采用 多分支结构,每个分支使用不同尺度的时间卷积核,用于捕捉不同时间感受野下的判别特征。
第 i i i 个分支包含:
- 时间卷积(Temporal Convolution)
- 深度可分离空间卷积(Depthwise Spatial Convolution)
- 平均池化(AvgPooling)
设第 i i i 个分支的卷积滤波器数量为 F i F_i Fi,深度参数为 D D D,则经过时空卷积后得到特征:
Z i ∈ R D ⋅ F i × 1 × T ′ (3) \mathbf{Z}_i \in \mathbb{R}^{D \cdot F_i \times 1 \times T'} \tag{3} Zi∈RD⋅Fi×1×T′(3)
其中 T ′ T' T′ 为下采样后的时间维度。
(2)多尺度特征拼接
所有分支特征在通道维度进行拼接:
Z = Concat ( Z 1 , Z 2 , ... , Z n ) (4) \mathbf{Z} = \text{Concat}(\mathbf{Z}_1, \mathbf{Z}_2, \dots, \mathbf{Z}_n) \tag{4} Z=Concat(Z1,Z2,...,Zn)(4)
得到融合后的特征表示:
Z ∈ R D ⋅ ∑ i F i × 1 × T ′ (5) \mathbf{Z} \in \mathbb{R}^{D \cdot \sum_i F_i \times 1 \times T'} \tag{5} Z∈RD⋅∑iFi×1×T′(5)
这种设计的意义在于:
- 小卷积核 → 捕捉短时局部振荡模式
- 大卷积核 → 捕捉长时依赖节律模式
- 多尺度融合 → 提升跨频带特征表达能力
从神经生理角度看,不同时间尺度卷积等价于对不同频率成分的隐式建模,有助于刻画 μ 与 β 节律及其动态变化。
2.3 跨尺度全局时间编码器(CSGT)
卷积模块擅长提取局部结构,但难以刻画远距离时间依赖。因此,MSVTNet 引入 Transformer 结构进行全局建模。
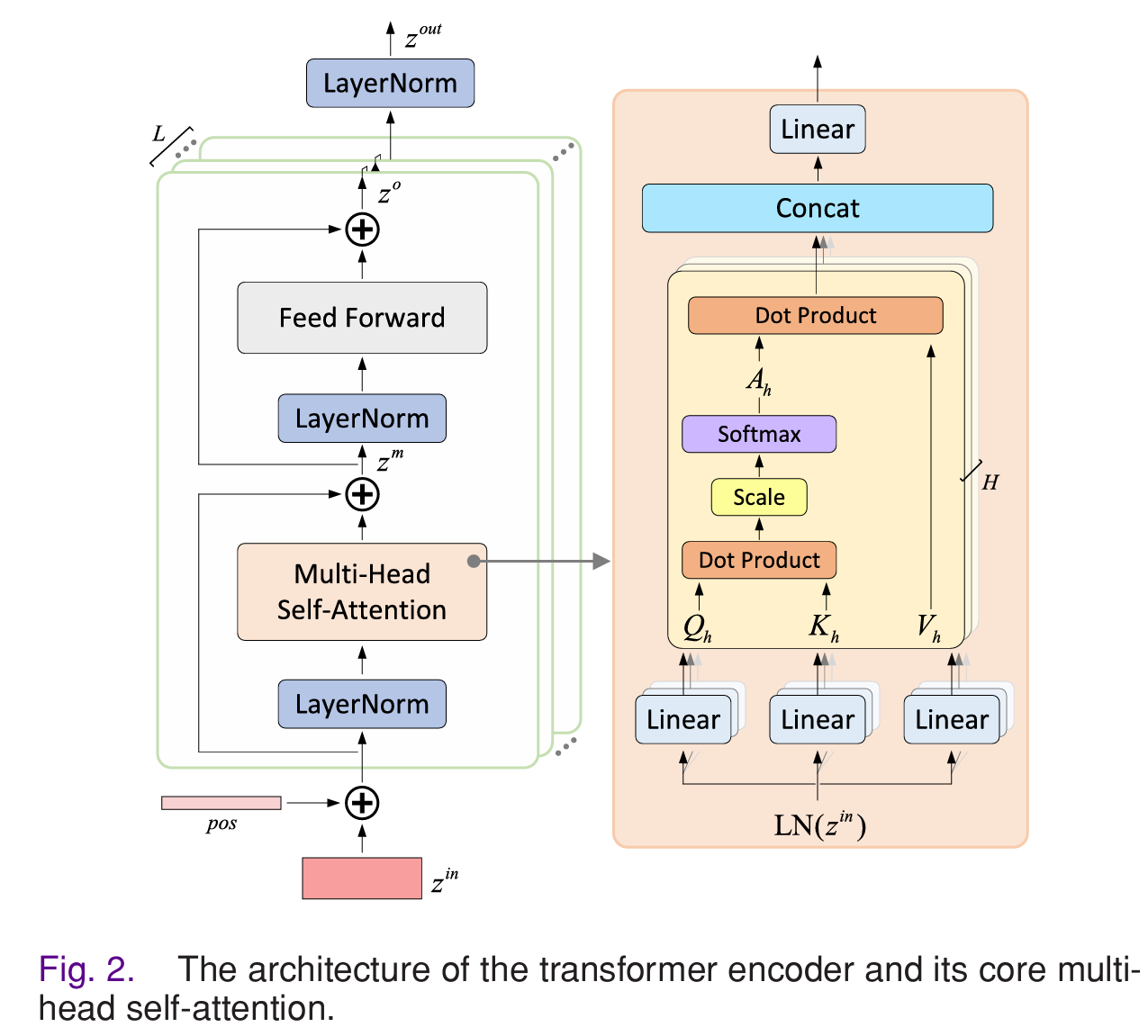
(1)序列化与嵌入
将拼接后的特征沿时间维度展开:
Z → S ∈ R T ′ × D ⋅ ∑ i F i (6) \mathbf{Z} \rightarrow \mathbf{S} \in \mathbb{R}^{T' \times D\cdot\sum_i F_i} \tag{6} Z→S∈RT′×D⋅∑iFi(6)
随后引入可学习的 class token:
S ′ = x c l s ; S (7) \mathbf{S}' = \\mathbf{x}_{cls}; \\mathbf{S} \tag{7} S′=xcls;S(7)
其中:
- x c l s ∈ R d \mathbf{x}_{cls} \in \mathbb{R}^{d} xcls∈Rd
- 序列长度变为 T ′ + 1 T' + 1 T′+1
(2)Transformer 编码
Transformer 编码器通过多头自注意力机制建模全局时间依赖:
Attention ( Q , K , V ) = Softmax ( Q K T d k ) V (8) \text{Attention}(Q,K,V)=\text{Softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \tag{8} Attention(Q,K,V)=Softmax(dk QKT)V(8)
其中:
Q = X W Q , K = X W K , V = X W V (9) Q = XW_Q,\quad K = XW_K,\quad V = XW_V \tag{9} Q=XWQ,K=XWK,V=XWV(9)
通过自注意力机制,模型能够:
- 建模远距离时间步之间的依赖关系
- 捕捉跨尺度特征交互
- 学习跨频带耦合模式
最终输出的 class token 表示:
h c l s (10) \mathbf{h}_{cls} \tag{10} hcls(10)
作为全局语义特征输入分类器。
2.4 辅助分支损失(ABL)
为了增强不同尺度特征的判别能力,并缓解深层 Transformer 训练不稳定问题,MSVTNet 在每个卷积分支后引入辅助分类器。
第 i i i 个分支损失定义为:
L b i = CrossEntropy ( y i , y ^ i ) (11) \mathcal{L}_b^i = \text{CrossEntropy}(y_i, \hat{y}_i)\tag{11} Lbi=CrossEntropy(yi,y^i)(11)
所有分支损失求和:
L a = ∑ i L b i (12) \mathcal{L}_a = \sum_i \mathcal{L}_b^i\tag{12} La=i∑Lbi(12)
这种多分支监督机制具有以下优势:
- 防止浅层特征退化
- 提升梯度传播稳定性
- 强化不同尺度特征的判别能力
2.5 分类头与联合损失
Transformer 输出的全局特征经过全连接层得到最终分类概率:
y ^ = Softmax ( W h c l s ) (13) \hat{y} = \text{Softmax}(W\mathbf{h}_{cls})\tag{13} y^=Softmax(Whcls)(13)
主分类损失为:
L c = CrossEntropy ( y , y ^ ) (14) \mathcal{L}_c = \text{CrossEntropy}(y, \hat{y})\tag{14} Lc=CrossEntropy(y,y^)(14)
最终联合损失函数为:
L = λ L c + ( 1 − λ ) L a (15) \mathcal{L} = \lambda \mathcal{L}_c + (1-\lambda)\mathcal{L}_a\tag{15} L=λLc+(1−λ)La(15)
其中:
- λ ∈ 0 , 1 \lambda \in 0,1 λ∈0,1 控制主任务与辅助任务权重,由于主任务分支为主要收敛目标,因此 λ \lambda λ 通常为0.6~0.9时最佳,论文作者后续通过敏感性分析证明了这一点。
3、实验设计与对比基线模型
为了全面评估 MSVTNet 在运动想象脑电(MI-EEG)解码任务中的性能表现与泛化能力,本文在多个公开基准数据集上进行了系统实验。实验设计覆盖被试内(Subject-Dependent, SD)与被试间(Subject-Independent, SI)两种典型脑机接口评估范式,并同时考虑 session-dependent 与 session-independent 两种划分方式,以全面分析模型在不同实际应用场景下的稳定性与鲁棒性。整体实验流程如 Fig.3 所示。
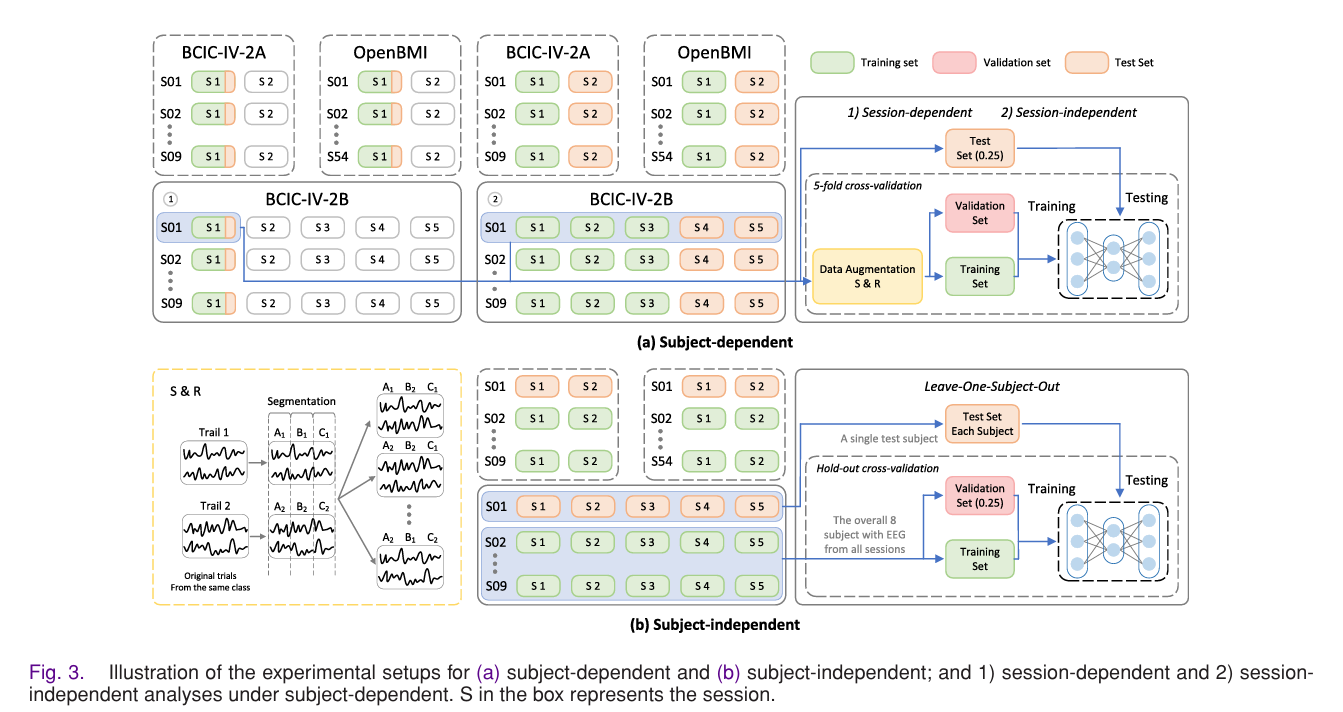
本章将从数据集构成、数据预处理流程、对比基线模型选择、实验划分策略以及训练细节等方面进行详细说明。
3.1 数据集介绍
本文选用三个具有代表性的公开 MI-EEG 数据集,分别覆盖四分类、二分类、小通道场景与大规模跨被试场景,以确保实验结论的普适性。
- BCI Competition IV-2A :MI-EEG 领域最常用的四分类 benchmark 数据集。
-- 被试数量 :9 名健康被试
-- 采样率 :250 Hz,可覆盖运动想象相关的 α \alpha α(8-12Hz) 与 β \beta β(13-30Hz) 频段
-- EEG 通道数 :22导,主要覆盖感觉运动皮层(Sensorimotor Cortex)及其周边区域 ,即中央区(Central Region)、顶叶(Parietal Lobe)和部分额叶(Frontal Lobe)
-- 类别数 :4 类(左手、右手、双脚、舌头)
-- Session数:每名被试包含 2 个独立 session
每个 trial 包含提示阶段与运动想象阶段。该数据集类别均衡,信号质量较高,是评估模型多类别判别能力与跨 session 稳定性的经典基准。
- BCI Competition IV-2B :二分类运动想象数据集,设置更加贴近轻量级 BCI 场景。
-- 被试数量 :9 名健康被试
-- 采样率 :250 Hz ,覆盖运动想象相关的 α \alpha α 与 β \beta β 频段
-- EEG 通道数 :3(C3、Cz、C4)。
-- 类别数 :2 类(左手 vs 右手)
-- Session数目:每名被试包含 5 个 session
该数据集通道数极少,更依赖模型对时间维度与跨尺度特征的深度建模能力,是验证模型结构表达能力的重要测试场景。
之所以可降到3个通道,主要基于对侧主导:想象左手运动,会导致右侧大脑半球的感觉运动皮层(主要是C4附近区域)出现能量下降(ERD);想象右手运动,则会导致左侧半球(主要是C3附近区域)出现ERD。而脚部和舌头运动:想象脚部运动,通常会引起中央中线区域(Cz附近)的ERD;而想象舌头运动,则会引起更靠近外侧裂的下部区域产生响应。
- OpenBMI :数据集规模更大,适用于跨被试泛化能力评估。
-- 被试数量 :54 名健康被试
-- 采样率 :1000 Hz,算法分析时统一下采样至 250 Hz
-- EEG 通道数 :62导,覆盖全脑区域,包括顶叶、额叶、枕叶、颞叶、中央区五大脑区,但作者仅挑选20个覆盖运动中枢区域相关的电极进行算法分析,即 FC-5/3/1/2/4/6, C-5/3/1/z/2/4/6 与CP5/3/1/z/2/4/6 (根据10-20电极系统)
-- 分类数目:2 类(左手 vs 右手)
由于被试数量较多,该数据集能够更真实地反映模型在实际应用中的跨个体迁移能力。
3.2 数据预处理流程
为保证不同数据集之间的可比性,所有数据统一进行如下预处理步骤:
- 频带滤波 :
-- 对原始 EEG 信号进行8-30Hz带通滤波
-- 该频段覆盖 μ(8--13 Hz)与 β(13--30 Hz)节律,是运动想象过程中 ERD/ERS 现象最显著的频带区域。通过频带限制可以有效降低低频漂移与高频肌电干扰的影响,提高信噪比。
- 时间窗口截取
-- 从运动提示开始后选取固定时间窗进行建模,通常选取0.5~4.5s
-- 该时间段内包含最显著的运动想象神经响应。统一时间窗口能够保证不同 trial 之间具有一致的时长。
- 标准化处理
-- 对每个 trial 进行 Z-score 标准化:
X ′ = X − μ σ (16) X' = \frac{X - \mu}{\sigma}\tag{16} X′=σX−μ(16)
其中 μ \mu μ 与 σ \sigma σ 为该 trial 的均值与标准差。该步骤能够减弱不同被试间电极阻抗差异与幅值尺度差异,提高模型泛化能力。
- 数据增强(Segmentation & Recombination, S&R)
-- 在被试内实验中,采用分段重组策略进行数据增强:
-- 将同类 trial 划分为若干时间段;
-- 在保持类别一致前提下随机重组;
-- 构造新的训练样本。
该方法在不破坏类别标签的情况下提升样本多样性,有助于缓解小样本过拟合问题。
3.3 实验设置
为全面评估模型性能,本文设计两种核心实验范式。
3.3.1 被试内实验(Subject-Dependent)
在每名被试内部构建训练与测试数据。
-
Session-dependent :
同一 session 内采用 5-fold 交叉验证。
-
Session-independent :
一个 session 用于训练,另一个 session 用于测试。
训练集内部随机划分 25% 作为验证集。该设置用于评估模型在单个被试上的稳定性与跨 session 泛化能力。
3.3.2 跨被试实验(Subject-Independent)
采用 Leave-One-Subject-Out(LOSO)策略:
- 每次选择 1 名被试作为测试集;
- 其余被试作为训练集;
- 训练集中划分 25% 作为验证集。
该实验范式更加贴近真实 BCI 应用场景,是衡量模型跨个体泛化能力的关键指标。
3.4 对比 Baseline 模型
为验证 MSVTNet 的结构优势,本文选取多种代表性方法作为对比。
- 传统方法: FBCSP-SVM [5](#5)
用于验证深度模型相对于经典空间滤波方法的优势。
- CNN 类模型 : ShallowConvNet[6](#6)、EEGNet[7](#7)、FBCNet[8](#8)、LightConvNet[9](#9)、IFNet[10](#10)
CNN 类模型擅长局部时空特征提取,是当前 MI-EEG 解码主流结构。
- Transformer 类模型 :EEG-Conformer[11](#11)
ViT-based EEG 模型, 用于评估纯自注意力结构在 EEG 解码中的表现,并对比 MSVTNet 的"卷积 + Transformer"混合设计优势。
3.5 训练细节
为保证公平性,所有深度模型采用统一训练策略:
- 优化器:Adam
- 初始学习率 : 1 × 10 − 3 1 \times 10^{-3} 1×10−3
- Batch Size:64
- 训练轮数:300 epochs
- 学习率调度:Cosine Annealing
- 损失函数:Cross-Entropy Loss
对于 MSVTNet,采用联合交叉熵损失函数(Joint-CrossEntropyLoss):
L = λ L c + ( 1 − λ ) L a (15) \mathcal{L} = \lambda \mathcal{L}_c + (1-\lambda)\mathcal{L}_a\tag{15} L=λLc+(1−λ)La(15)
- λ \lambda λ 在 0.5--0.8 之间调节
- 使用 Early Stopping 防止过拟合
所有实验在相同硬件环境下重复多次,结果取平均值以减少随机波动影响。
3.6 评价指标
模型性能通过以下指标进行评估:
- 分类准确率(Accuracy)
- Cohen's Kappa 系数
κ = p o − p e 1 − p e (17) \kappa = \frac{p_o - p_e}{1 - p_e} \tag{17} κ=1−pepo−pe(17)
其中:
- p o p_o po 为观测准确率
- p e p_e pe 为随机一致概率
Kappa 能够在类别不平衡场景下提供更加客观的性能评估。
4. 实验结果与讨论分析
本文实验围绕 MSVTNet 在运动想象 EEG 解码任务中的性能展开多维度验证,通过整体解码性能对比、特征区分性可视化、核心模块消融实验、超参数敏感性分析及关键设计机制验证,深入剖析模型的优势、核心模块的有效性及超参数的最优配置,同时解释实验现象背后的原因,为模型设计的合理性提供实证支撑。
4.1 整体MI-EEG解码性能分析
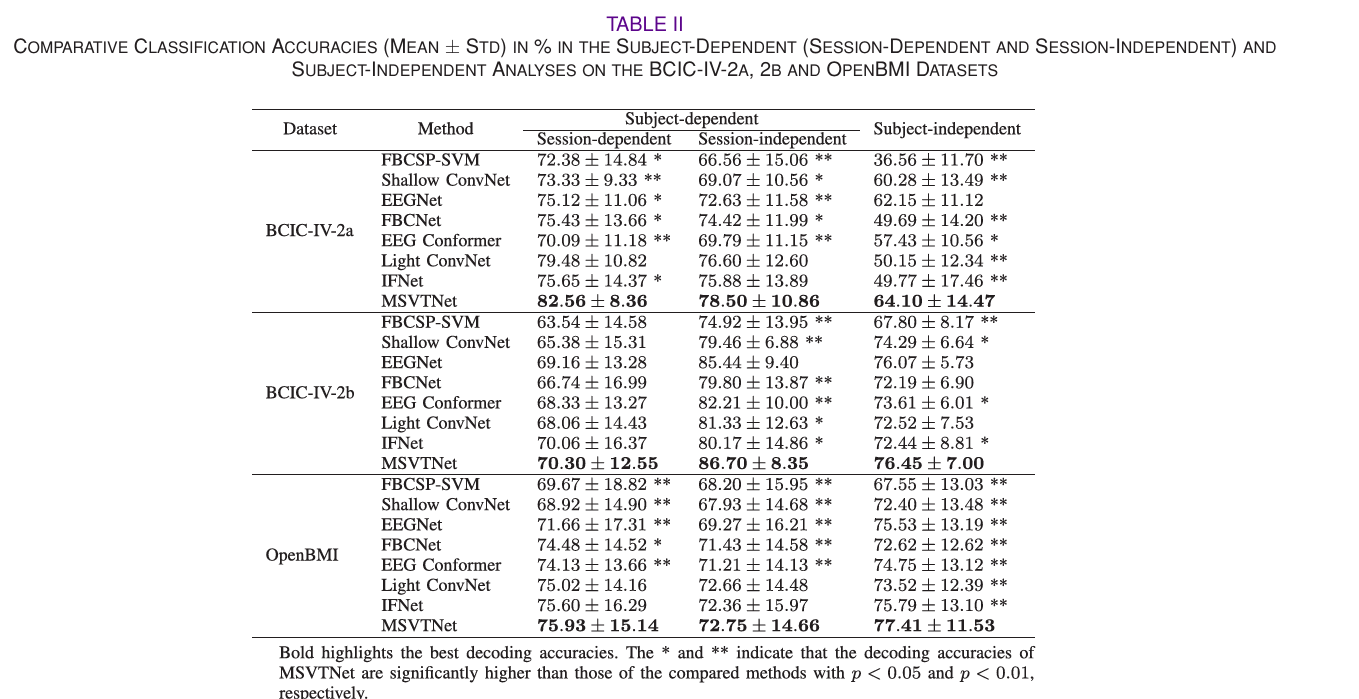
-
Subject-Dependent实验:Session内与跨Session均保持高精度
- 在Session-Dependent分析中,MSVTNet 在 BCIC-IV-2a 上达到 82.56% 的解码精度,相较于次优的 Light ConvNet 提升 3.08%,且标准差仅 8.36%,远低于其他模型,体现了对单受试者同一Session EEG 信号的强拟合与特征提取能力;
- 在更具挑战性的Session-Independent分析中,MSVTNet 在 BCIC-IV-2b 上实现 86.70% 的精度,超越 EEGNet 1.26%,同时在 OpenBMI 数据集上对所有对比模型实现统计显著性提升 ( p < 0.01 p<0.01 p<0.01),证明模型能有效克服同受试者不同时段的 EEG 信号非平稳性问题。
-
Subject-Independent实验:泛化能力显著优于基线
- Subject-Independent分析(受试者独立分析)是检验模型实际应用价值的核心指标,MSVTNet 在该实验中表现尤为突出:在 BCIC-IV-2a 上达到 64.10% 的精度,超越经典深度学习模型 EEGNet 1.95%;
- 在大样本量的 OpenBMI 数据集上精度达 77.41%,是所有模型中唯一突破 77% 的方法,且显著优于所有对比模型( p < 0.01 p<0.01 p<0.01)。同时,在 OpenBMI 数据集中,MSVTNet 实现了解码精度超 70% 的受试者数量达 38 名,远高于次优的 IFNet(33 名),充分证明模型能学习到跨受试者的通用运动想象 EEG 特征,解决了传统模型泛化能力不足的痛点。
-
不同数据集适配性:兼顾少通道、多类别、大样本场景
- MSVTNet 在不同特性的数据集上均表现优异,在仅 3 个通道的 BCIC-IV-2b 上,突破了通道数不足导致的特征稀缺问题;
- 在 4 类运动想象任务的 BCIC-IV-2a 上,解决了多类别任务的特征混淆问题;在 54 名受试者的 OpenBMI 上,克服了大样本下的个体差异问题。这一特性证明 MSVTNet 的多尺度特征提取与跨尺度全局时序建模机制,能适配不同场景的 MI-EEG 解码需求。
- 此外,实验中观察到 BCIC-IV-2b 数据集的会话相关分析精度普遍偏低,这一现象源于该实验仅使用无反馈的第 1 会话作为训练 / 测试集,数据量少且缺乏反馈带来的信号稳定性,而 MSVTNet 仍在该场景下取得 70.30% 的精度,为所有模型最优,进一步体现了模型的鲁棒性。
4.2 特征与分类结果可视化分析
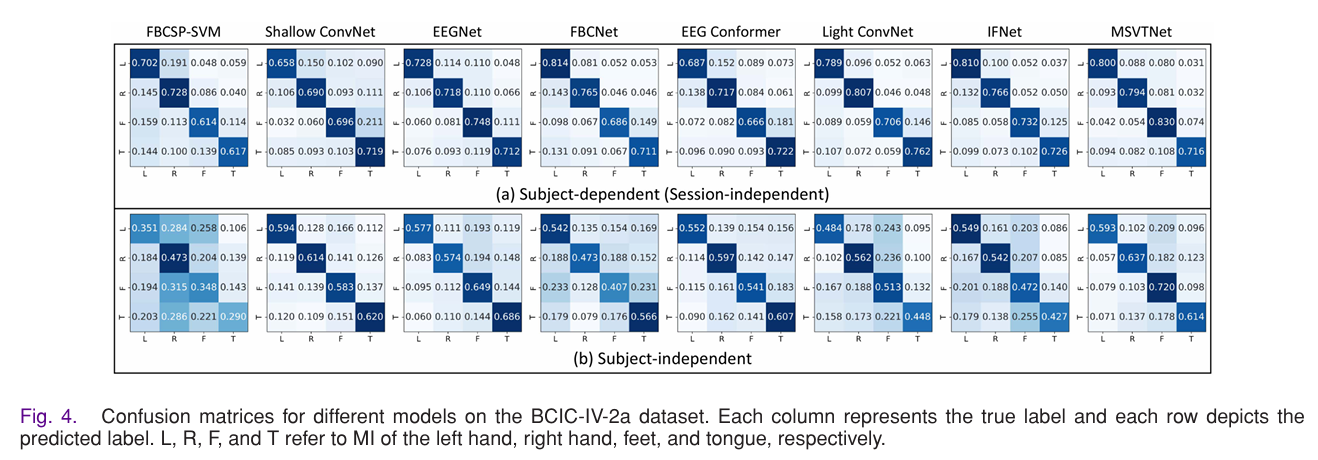
为直观验证 MSVTNet 的特征提取能力,本次实验通过混淆矩阵和t-SNE 特征可视化两种方式,分析模型对不同运动想象类别的分类能力及特征区分性,结果如下:
- 混淆矩阵:类别分类更均衡,难分任务精度显著提升
- 以 BCIC-IV-2a 数据集为例,MSVTNet 在会话独立和受试者独立分析中,均实现了四类运动想象任务(左手、右手、双脚、舌头)的均衡分类。其中,双脚运动想象作为传统模型的难分任务,MSVTNet 的解码精度得到显著提升;
- 在Subject-Independent分析中,右手和双脚任务的分类精度为所有模型最高,解决了传统模型对非手部运动想象任务特征捕捉不足的问题。这一结果证明,MSVTNet 的多尺度特征提取机制能捕捉到不同肢体运动想象对应的独特脑电特征,减少类别间的特征混淆。
- t-SNE 特征可视化:特征区分性更强,类内聚合性更优
- 对模型分类层前的特征进行 t-SNE 二维可视化,结果显示:相较于 Shallow ConvNet、EEGNet 等无注意力机制的模型,MSVTNet 与其他 Transformer 类模型(EEG Conformer、Light ConvNet)的特征分离度更高 ;而且 MSVTNet 在所有模型中实现了类间距离最大、类内距离最小的特征分布,其特征点在二维空间中形成清晰的聚类,无明显的类别重叠。
- 同时,对 MSVTNet 不同模块的特征可视化发现,从原始 EEG 到 MSST 模块、再到 CSGT 模块,特征的区分性逐步提升,证明模型的多尺度特征提取与跨尺度全局时序编码,能持续挖掘更具判别性的 EEG 特征,为最终分类提供坚实基础。

4.3 核心模块消融实验
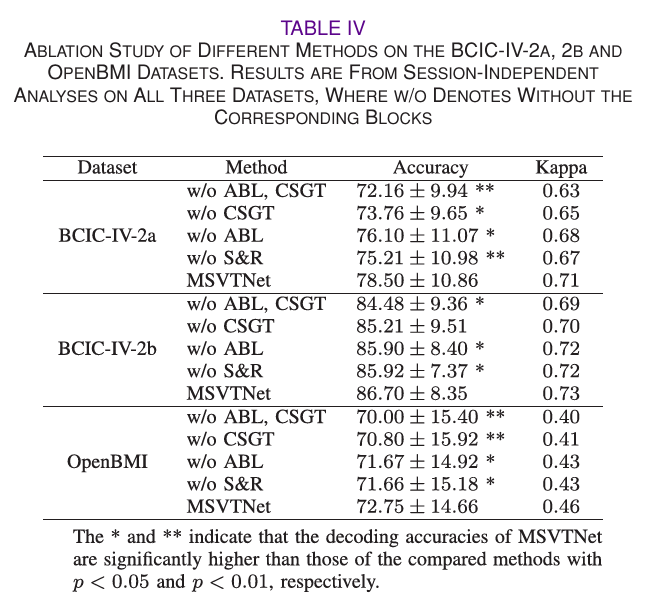
MSVTNet 的核心设计为MSST 多尺度时空卷积模块、CSGT 跨尺度全局时序编码模块和ABL 辅助分支损失模块,同时实验中采用S&R 分段重构数据增强策略。为验证各模块的必要性,本次实验在三大数据集的会话独立分析中开展消融实验,核心结论如下:
1. ABL 模块:解决 CNN 与 Transformer 参数失衡,提升特征质量
- 移除 ABL 模块后,MSVTNet 在 BCIC-IV-2a、BCIC-IV-2b、OpenBMI 上的精度分别降至 76.10%、85.90%、71.67%,均实现统计显著性下降(p<0.05)。
- 这一结果证明,ABL 的中间监督机制能有效约束 MSST 模块的特征提取过程,避免因 Transformer 模块的参数占比过高导致的 CNN 特征学习不足,同时增强各尺度分支的特征提取能力,为后续的跨尺度建模提供高质量的局部特征。
2. CSGT 模块:捕捉跨尺度全局时序特征,弥补 CNN 局部性缺陷
- 移除 CSGT 模块(直接将 MSVTNet 特征送入分类器)后,模型在 BCIC-IV-2a 和 OpenBMI 上的精度分别降至 73.76%、70.80%,显著性下降( p < 0.01 p<0.01 p<0.01),在 BCIC-IV-2b 上也有小幅下降。
- 这一结果验证了 CSGT 模块的核心价值:
CNN 提取的局部时空特征缺乏跨尺度交互和长时序依赖,而 CSGT 通过 Transformer 的多头自注意力机制,能捕捉不同尺度特征间的交叉频率耦合关系,以及 EEG 信号的长时序全局相关性,将局部特征升级为更具判别性的全局特征。
3. ABL+CSGT 联合移除:性能下降最显著,模块协同性强
- 同时移除 ABL 和 CSGT 模块后,模型在三大数据集上的精度均为消融实验最低,且在 BCIC-IV-2a 上与单独移除 CSGT 模块存在显著性差异( p < 0.01 p<0.01 p<0.01)。
- 这证明 MSST、CSGT、ABL 三个模块并非简单的叠加,而是存在强协同性:MSST 提供多尺度局部特征,ABL 保证局部特征质量,CSGT 对高质量的局部特征进行跨尺度全局编码,三者形成 "特征提取 - 特征约束 - 特征升级" 的完整链路。
4. S&R 数据增强:小样本下有效抑制过拟合
- 移除 S&R 数据增强后,模型在三大数据集上的精度均出现显著性下降,证明该策略能有效解决 MI-EEG 数据量稀缺的问题
- S&R 通过对 EEG 信号的时序分段与随机重构,丰富训练数据的多样性,抑制模型过拟合,提升模型的泛化能力。
4.4 关键超参数与设计机制敏感性分析
为确定 MSVTNet 的最优配置,本次实验围绕多尺度分支数、Transformer 层数 / 头数、ABL 损失权衡因子 λ、S&R 数据增强参数四大核心设计,开展敏感性分析,明确各参数的影响规律与最优值:
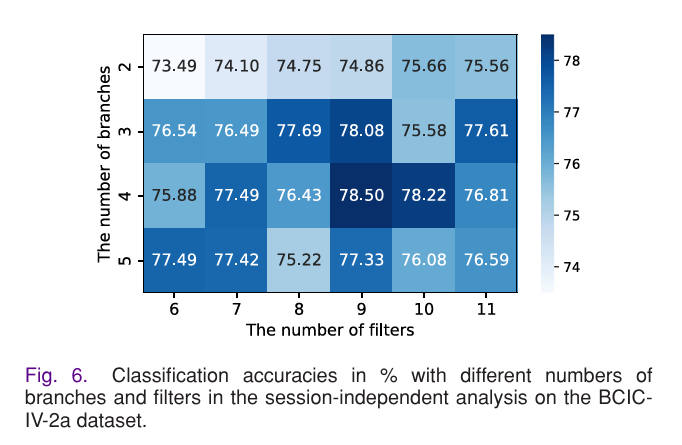
4.4.1 多尺度分支数(B)与滤波器数(Fb)
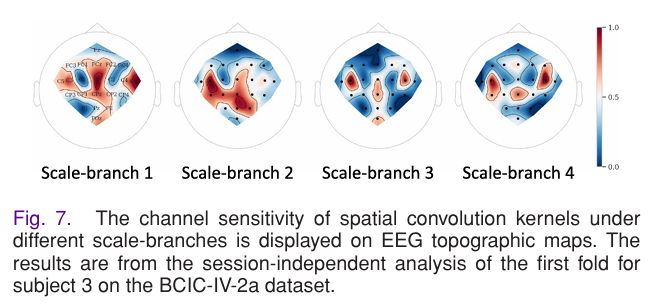
MSST 模块的分支数直接决定多尺度特征的覆盖范围,实验测试了 2-5 个分支的配置,结果显示:4 个分支为最优配置(卷积核尺寸 15、31、63、125),搭配 9 个滤波器时,模型在 BCIC-IV-2a 上达到 78.50% 的精度。当分支数少于 4 时,模型无法捕捉到足够的多尺度频率特征;当分支数增至 5 时,引入了冗余特征,导致模型过拟合,精度反而下降。同时,对不同分支的空间卷积核权重进行脑电拓扑图可视化,发现 4 个分支能分别激活运动皮层的不同区域,对应不同肢体运动想象的 ERD/S 特征,证明多尺度分支的设计与脑电生理特征高度契合。
4.4.2 Transformer 层数(L)与多头注意力头数(H)
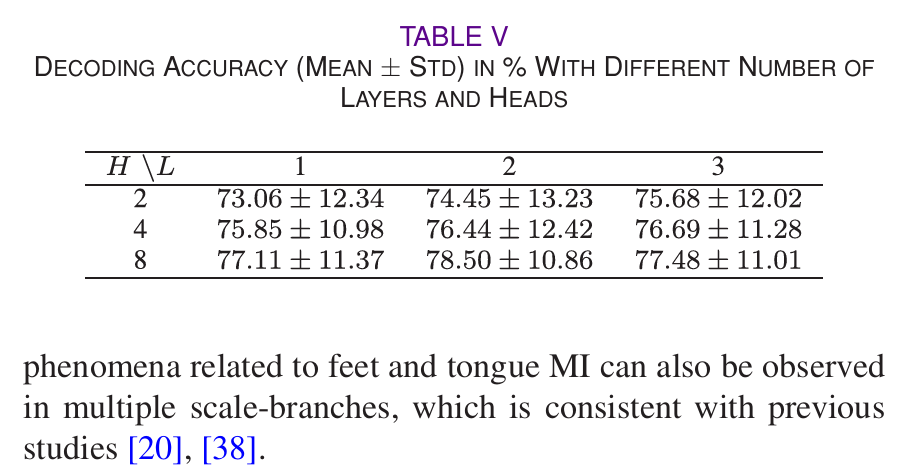
CSGT 模块的 Transformer 层数和注意力头数,决定了全局特征的编码能力,实验结果显示:
- 层数 L=2 为最优:L=2 时模型在 BCIC-IV-2a 上精度达 78.50%,L 增至 3 时,参数过多导致过拟合,精度下降;在Subject-Independent实验分析中,为进一步提升泛化能力,将 L 调至 1,配合 dropout 率调整,有效避免了过拟合。
- 头数 H=8 为最优 :H=8(即 B×D,分支数 × 深度参数)时,各注意力头能捕捉不同尺度的特征交互关系,相较于 H=2、4,精度实现显著性提升。这证明多头注意力的头数与多尺度分支数匹配时,能最大化跨尺度特征的建模能力。
4.4.3 ABL 损失权衡因子 λ λ λ
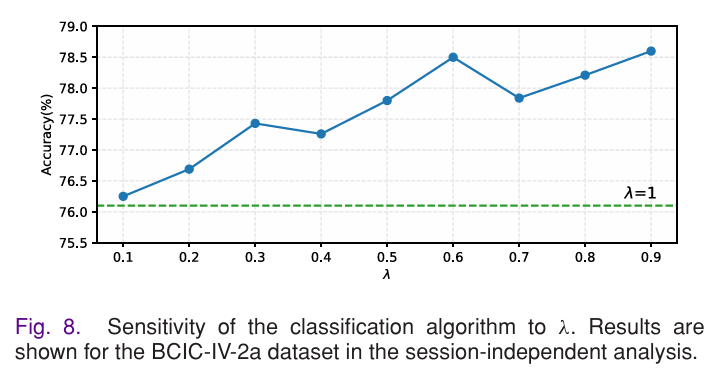
权衡因子 λ 决定了分类损失( L c Lc Lc)与辅助分支损失( L a La La)的权重分配,实验测试了 λ 从 0.1 到 1.0 的取值,结果显示:
- λ=0.6 为最优值,高于0.6或低于0.6均无显著提升或下降。
- 当 λ<0.6 时,辅助分支损失占比过高,模型过度关注局部特征,忽略全局分类目标;
- 当 λ>0.6 时,辅助分支损失占比过低,无法有效约束 MSST 模块的特征提取;
- 当 λ=1 时,模型无 ABL 约束,精度降至最低 。这一结果明确了中间监督与最终分类的最优权重比,实现了局部特征质量与全局分类性能的平衡。
4.4.4 S&R 数据增强参数
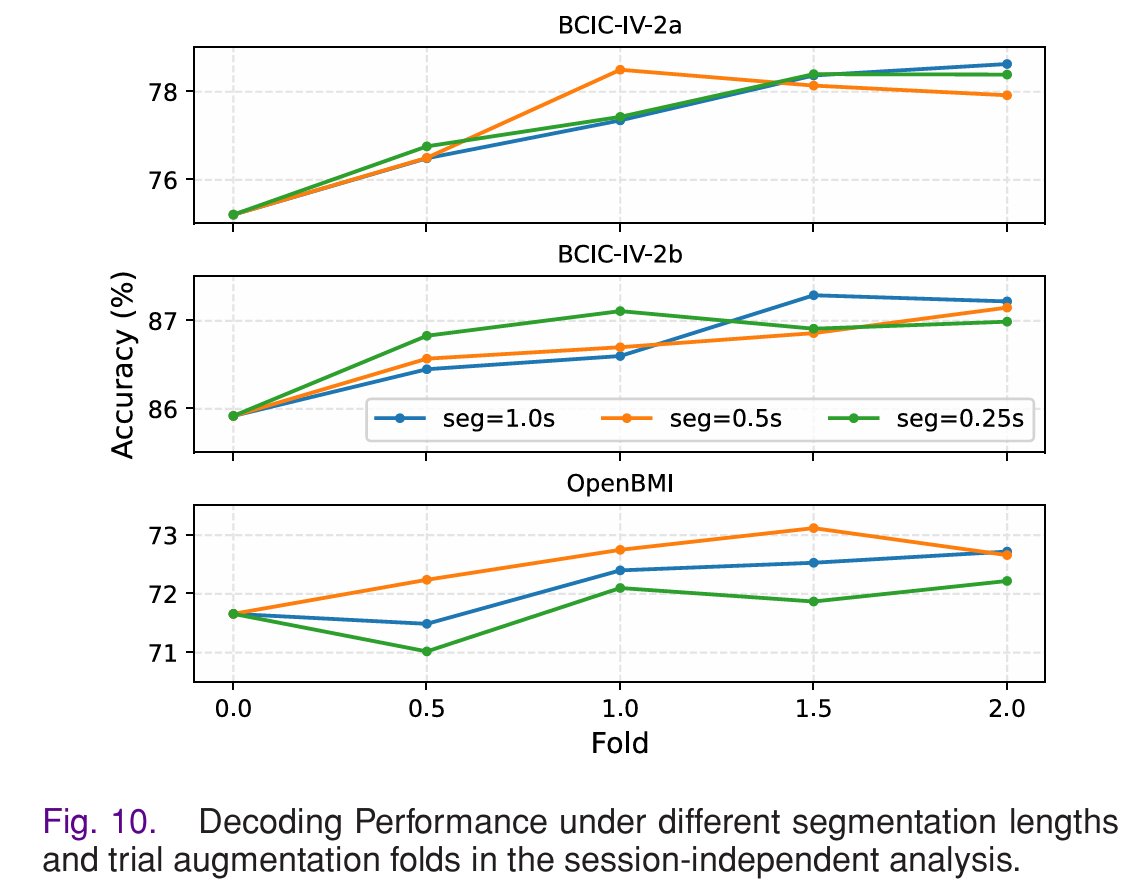
实验测试了不同分段长度(0.25s、0.5s、1.0s)和增强倍数(0-2 倍)对模型性能的影响,结果显示:
- 分段长度 0.5s、增强 1 倍为最优配置。
- 增强倍数从 0 增至 1 时,模型精度显著提升
- 但增至 2 倍时,精度无明显提升且训练时间大幅增加;
- 分段长度在 BCIC-IV-2a/2b 上无显著差异,在 OpenBMI 上 0.5s 分段的性能最优。
- 这证明数据增强并非倍数越高越好,适度的增强能在不引入噪声的前提下,提升模型的泛化能力。
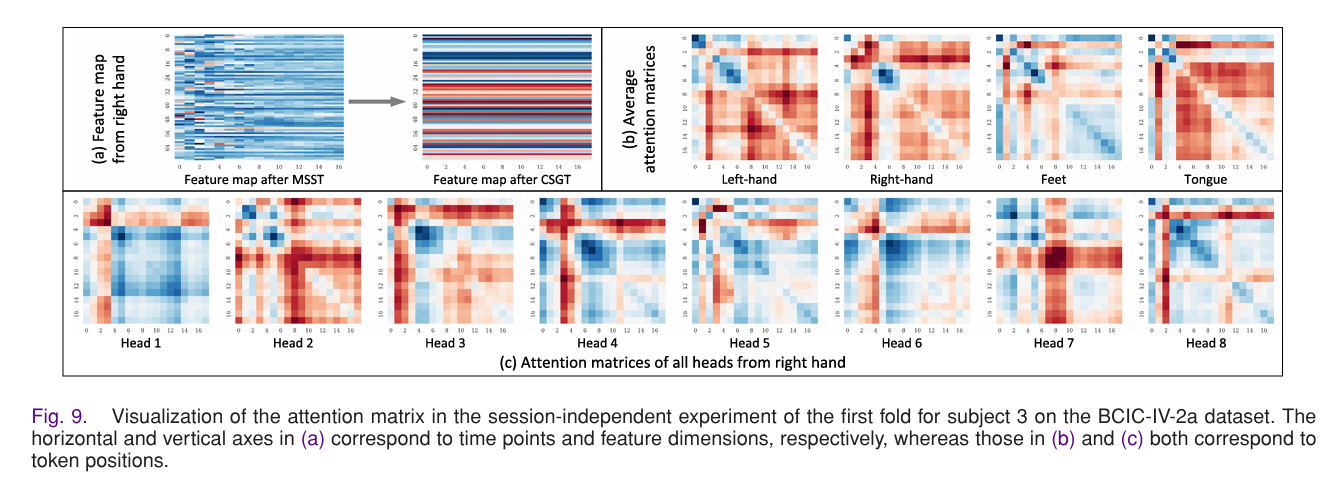
4.5 注意力机制与特征映射可视化分析
为深入理解 MSVTNet 的特征学习机制,本次实验对MSST 与 CSGT 模块的特征映射、CSGT 模块的注意力矩阵进行可视化,揭示模型的特征学习规律:
-
特征映射:从局部到全局的特征升级
- MSST 模块的输出特征映射呈现明显的局部性,仅在特定时间点和特征维度有激活;
- 而 CSGT 模块的输出特征映射呈现全局性,激活区域覆盖更多的时间点和特征维度,且激活区域与运动想象的生理特征高度匹配。这证明 CSGT 模块能对 MSST 的局部特征进行全局编码,挖掘特征间的潜在关联,提升特征的判别性。
-
注意力矩阵:聚焦关键时间点,捕捉跨尺度时序依赖
对 CSGT 模块的注意力矩阵可视化发现两大规律:
一是模型显著关注刺激出现后约 500ms 的特征(即受试者从看到提示到执行运动想象的反应时间),这与运动想象的脑电生理规律高度一致;- 二是不同注意力头聚焦于不同的时间点和尺度特征,能捕捉到多尺度、跨时序的特征依赖关系,丰富了模型的特征分析维度。
- 同时,四类运动想象任务的注意力矩阵存在明显差异,证明模型能学习到不同任务的独特时序特征。
4.6 模型局限性与未来优化方向
尽管 MSVTNet 在运动想象 EEG 解码的受试者相关、受试者独立实验中均实现了 SOTA 性能,且在实际验证中展现出超越通用 EEG 分类模型 EEG-Conformer 的解码能力,在运动想象、注意力识别两大领域均表现优异,具备成为新一代通用 EEG 分类模型的潜力,但当前模型仍存在部分局限性,同时结合其架构优势与实际应用需求,可从多维度开展后续优化工作,进一步挖掘模型的性能潜力与应用价值。
从模型当前的应用与性能边界来看,首要局限性为任务适配的精细化程度不足 ,本次实验仅验证了粗粒度的肢体运动想象(左手、右手、双脚、舌头)解码能力,而实际 BCI 系统的落地应用,需要对精细运动想象任务(如手腕抓握力度渐变、手指屈伸等单肢体细分动作)进行精准解码,当前模型尚未针对这类细粒度任务做特征提取与建模的优化;其次是数据增强策略的创新性不足 ,实验中采用的分段重构(S&R)为传统数据增强方法,在 MI-EEG 小样本场景下的特征扩充效果存在上限,难以满足模型对多样化训练数据的需求;最后是EEG 信号空间分辨率的利用不足,受体积传导效应和采集设备的物理限制,头皮 EEG 信号的空间分辨率较低,模型直接基于原始头皮 EEG 建模,无法捕捉到脑皮层更精细的神经活动特征,一定程度上限制了特征挖掘的深度。
结合 MSVTNet 的核心架构优势 ------ 多尺度卷积的特征丰富度、Transformer 的全局特征捕捉能力、多分支联合损失的训练稳定性,以及参数量远低于 EEG-Conformer 的部署优势,同时针对现有局限性,制定以下未来优化方向:
-
适配精细运动想象解码任务:基于现有多尺度时空卷积(MSST)模块,优化卷积核尺度与分支设计,针对精细运动想象的 EEG 特征特点,增加细粒度特征提取分支,同时调整跨尺度全局时序编码(CSGT)模块的注意力机制,使其能捕捉到细粒度运动想象对应的微弱神经活动特征,提升模型对细分肢体动作的解码精度;
-
引入先进的深度学习数据增强策略:摒弃传统的 S&R 方法,引入基于生成对抗网络(GAN)、扩散模型的深度学习数据增强技术,在小样本场景下生成更贴合真实生理特征的 MI-EEG 数据,丰富训练数据的多样性,进一步提升模型的泛化能力,同时结合模型的小参数量优势,保证数据增强后的训练效率;
-
融合脑电源成像提升空间特征利用:结合脑电源成像(ESI)技术,将头皮 EEG 信号转换为脑皮层源信号,提升 EEG 信号的空间分辨率,再将其输入 MSVTNet 进行特征建模,充分挖掘脑皮层的空间神经活动特征,弥补当前模型对空间特征利用的不足,进一步提升解码性能;
-
推进通用 EEG 分类模型的适配与验证 :基于 MSVTNet 在运动想象优异表现,进一步拓展验证场景,将模型应用于注意力识别、情绪识别、睡眠分期等典型 EEG 分类任务,针对不同任务的 EEG 特征特点做轻量化的模块适
配与超参数调优,同时依托其小参数量的部署优势,优化模型的推理速度,推动其成为高性能、易部署的通用 EEG 分类模型;
-
强化端侧硬件的适配与轻量化部署:结合 MSVTNet 参数量远低于 EEG-Conformer 的优势,进一步通过模型剪枝、量化、知识蒸馏等轻量化技术,压缩模型体积与推理耗时,使其更好地适配嵌入式、可穿戴等资源受限的端侧硬件环境,实现 BCI 系统的便携化、实时化部署,推动模型从实验室研究走向实际工程应用。
5. 参考文献
-
McFarland D J, Wolpaw J R. Brain-computer interfaces for communication and controlJ. Communications of the ACM, 2011, 54(5): 60-66. https://dl.acm.org/doi/abs/10.1145/1941487.1941506 ↩︎
-
Schalk G, Mellinger J. A practical guide to brain--computer interfacing with BCI2000: General-purpose software for brain-computer interface research, data acquisition, stimulus presentation, and brain monitoringM. Springer Science & Business Media, 2010.<books.google.com> ↩︎
-
Toro C, Deuschl G, Thatcher R, et al. Event-related desynchronization and movement-related cortical potentials on the ECoG and EEGJ. Electroencephalography and Clinical Neurophysiology/Evoked Potentials Section, 1994, 93(5): 380-389.https://www.sciencedirect.com/science/article/abs/pii/0168559794901260 ↩︎
-
Lotte F, Guan C. Regularizing common spatial patterns to improve BCI designs: unified theory and new algorithmsJ. IEEE Transactions on biomedical Engineering, 2010, 58(2): 355-362.https://ieeexplore.ieee.org/abstract/document/5593210/ ↩︎
-
Ang K K, Chin Z Y, Zhang H, et al. Filter bank common spatial pattern (FBCSP) in brain-computer interfaceC//2008 IEEE international joint conference on neural networks (IEEE world congress on computational intelligence). IEEE, 2008: 2390-2397. https://ieeexplore.ieee.org/abstract/document/5165082 ↩︎
-
Schirrmeister R T, Springenberg J T, Fiederer L D J, et al. Deep learning with convolutional neural networks for EEG decoding and visualizationJ. Human brain mapping, 2017, 38(11): 5391-5420. https://onlinelibrary.wiley.com/doi/full/10.1002/hbm.23730 ↩︎
-
Lawhern V J, Solon A J, Waytowich N R, et al. EEGNet: A compact convolutional neural network for EEG-based brain-computer interfacesJ. Journal of Neural Engineering, 2018, 15(5): 056013. https://iopscience.iop.org/article/10.1088/1741-2552/aace8c ↩︎
-
Mane R, Chew E, Chua K, et al. FBCNet: A multi-view convolutional neural network for brain-computer interfaceJ. arXiv preprint arXiv:2104.01233, 2021. https://arxiv.org/abs/2104.01233 ↩︎
-
Ma X, Chen W, Pei Z, et al. A temporal dependency learning CNN with attention mechanism for MI-EEG decodingJ. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 2023, 31: 3188-3200.https://ieeexplore.ieee.org/abstract/document/10196350 ↩︎
-
Wang J, Yao L, Wang Y. IFNet: An interactive frequency convolutional neural network for enhancing motor imagery decoding from EEGJ. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 2023, 31: 1900-1911. https://ieeexplore.ieee.org/abstract/document/10070810/ ↩︎
-
Song Y, Zheng Q, Liu B, et al. EEG conformer: Convolutional transformer for EEG decoding and visualizationJ. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 2022, 31: 710-719. https://ieeexplore.ieee.org/abstract/document/9991178 ↩︎